处理类别数据
- 🌱简要理解处理类别数据的重要性
- ☘️类别数据的分类
- ☘️方便研究——用pandas创建包含多种特征的数据集
- 🍀映射有序特征
- 🍀标称特征标签编码
- 🍀标称特征的独热编码
- 🌱独热编码的优缺点
🌱简要理解处理类别数据的重要性
在【机器学习4】构建良好的训练数据集——数据预处理(一)处理缺失值及异常值这一篇文章中,主要说明热数据预处理的重要性以及如何处理缺失值及异常值这些数值特征。然而,在现实生活中遇到的数据集往往不仅仅只会包含
数值型特征,还会包含一个或者多个类别特征,比如说性别分为男和女,比如说我们之前经常用的数据集——鸢尾花数据集,分为山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)等等等等,学会如何处理类别数据,将此量化,将会对之后进一步的数据分析带来更大的益处。
许多机器学习库都要求将类别标签编码为
整数值。尽管Scikit-Learn中大多数分类器或者估计器可以在内部将类别标签转换为整数,但给分类器提供整数数组的形式的类别标签在实践中被认为是一种很好的做法,可以从技术上避免很多问题。
☘️类别数据的分类
当谈到类别数据时,我们首先需要将此区分为
有序(ordinal)特征和标称(nominal)特征。
有序特征可以理解为可以排序的类别值。例如说,颜色,浅蓝->蓝->蓝绿->深蓝,再比如说,不抽烟与抽烟,这些特征都可以定义为有序特征。
相比之下,标称特征是没有任何意义的排序。比如说,性别,男和女,再比如说,颜色蓝色绿色和红色,如果给这些特征排序,是没有意义的,所以一般把性别、颜色等等看作是标称特征。
☘️方便研究——用pandas创建包含多种特征的数据集
为了后面更方便的
举例说明,我们先用pandas创建一个新的DataFrame数据集,让这个数据集包含标称特征,有序特征和数值特征。
import pandas as pd
df=pd.DataFrame([['green','M','10.1','class2'],['red','L',13.5,'class1'],['blue','XL',15.3,'class2']])
df.columns=['color','size','price','classlabel']
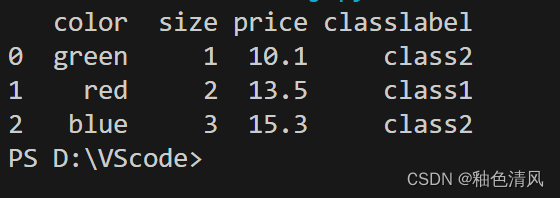
df
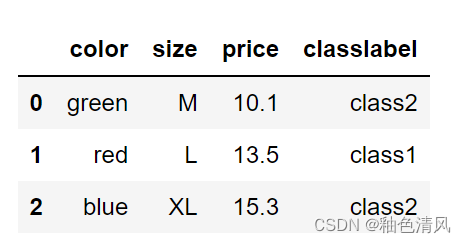
新创建的DataFrame包含color这个标称特征,size有序特征,price数值特征,还有类别标签classlabel。
🍀映射有序特征
为了确保机器学习算法可以正确理解有序特征,需要将类别字符串转化为整数。因为没有现成的函数可以到处类别特征标签的正确顺序,所以我们需要自己手动来定义一个
映射关系。
在上面创建的数据框中,size为有序特征,我们根据生活经验和实际情况,将其合理地映射为数值即可。
比如将M映射为1,L映射为2,XL映射为3.
我们可以使用pandas中的
map方法将原数据框中的size这一列数据进行替换,将此替换为数值类型。
df['size']=df['size'].map({'M':1,'L':2,'XL':3})
df
🍀标称特征标签编码
对于有序特征,可以使用有序特征映射的方法,将类别字符串转化为整数。对于标称特征,它的类别是
无序的,因此把某个特定的字符串转化为哪一个数字并不重要。一般简单地从0开始枚举标签。对于我们创建的数据框,颜色(color)和类别(classlabel)这两列的数据是无序的,因此是标称特征列。我们对这两列分别从0开始
枚举类别标签。
对于颜色(color)这一列,我们让green映射为0,red映射为1,blue映射为2.对于类别标签(classlabel)这一列,我们将classlabel1映射为1,classlabel2映射为2。
同样地,我们依然采用映射字典将类别标签转换为整数。
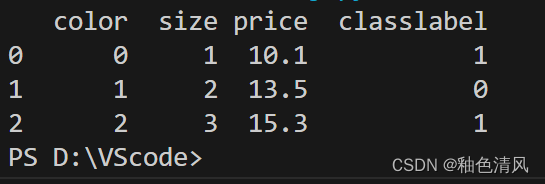
df['color']=df['color'].map({'green':0,'red':1,'blue':2})
df['classlabel']=df['classlabel'].map({'class1':0,'class2':1})
字典映射是一种简单的映射。因为
Scikit-Learn中的分类器将类别标签看作是无法排序的类别数据。所以可以使用LabelEncoder将字符型标签类别转换为整型类别标签。
调用Scikit-Learn中的LabelEncoder类实现上述工作:
from sklearn.preprocessing import LabelEncoder
class_le=LabelEncoder()
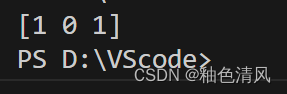
y=class_le.fit_transform(df['classlabel'].values)
print(y)
x=class_le.fit_transform(df['color'].values)
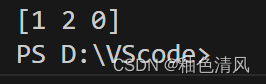
可以看到,分类器将blue转换为0,green转换为1,red转换为2。
fit_transform方法相当于先后调用
fit方法和transform方法。可以使用inverse_transform方法将整数类别标签转换回其他原始字符串表示形式:
class_le.inverse_transfrom(y)
🍀标称特征的独热编码
我们对于有序特征的映射,其数字是有大小意义的。然而,对于离散特征的取值之间没有意义的特征比如颜色,它们本身red、blue、green它们三者本身没有大小比较或者层次上递进的意义,然而我们采用映射的方法,将此映射为0,1,2三个整数,但整数之间又存在大小的比较。那么分类器在处理类别数据时,就会假设red大于green大于blue。
为了解决这个问题,一种常见的方法是独热编码(one-hot encoding).
独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用
N位状态寄存器来对N个状态进行编码,每个状态都有他独立的寄存器位,并且在任意时候,其中只有一位有效。
可以这样理解,对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征,比如,如成绩这个特征有好,中,差变成one-hot就是100, 010,001
再比如说,关于病人对于病人的既往史研究调查,有冠心病、高血压、糖尿病、哮喘、和其他,我们可以利用独热编码,将冠心病编码为10000,高血压编码为01000,糖尿病编码为00100,哮喘编码为00010,其他编码为00001。将同时患有冠心病和糖尿病的编码为10100,将同时患有高血压和其他疾病的编码为01001…
这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。
这样做的好处主要有:
①解决了分类器不好处理属性数据的问题
②在一定程度上也起到了扩充特征的作用
下面,我们将color特征转换为三个新特征:blue、green和blue。然后使用二进制来表示颜色。例如,可以编码blue=1,green=0,red=0.
为了执行此转换,可以使用Scikit-Learn中的preprocessing模块中的OneHotEncoder方法:
from sklearn.preprocessing import OneHotEncoder
X=df[['color','size','price']].values
color_ohe=OneHotEncoder()
array=color_ohe.fit_transform(X[:,0].reshape(-1,1)).toarray()
print(array)
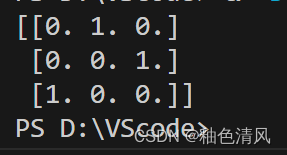
在上面代码中,仅将OneHotEncoder应用于一个列X[:,0],如果想要有选择地变换数组中的某些列,可以使用ColumnTransformer方法。
from sklearn.compose import ColumnTransformer
X=df[['color','size','price']].values
c_transf=ColumnTransformer([('onehot',OneHotEncoder(),[0]),('nothing','passthrough',[1,2])])
array=c_transf.fit_transform(X).astype(float)
print(array)
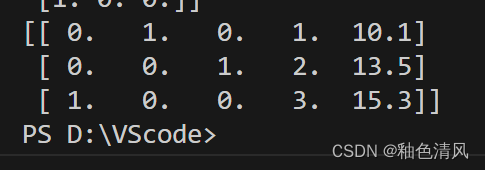
🌱独热编码的优缺点
优点: 独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
缺点: 当类别的数量很多时,会导致稀疏矩阵问题,特征空间会变得非常大。在这种情况下,一般可以用PCA来减少维度。而且One Hot Encoding+PCA这种组合在实际中也非常有用。
并且在某些应用中,可能并不需要将所有分类都作为分开的一个特征,此时独热编码可能不是最优选择。
![rocketMq启动broker报错找不到或无法加载主类 Files\Java\jdk1.8.0_171\lib\dt.jar;C:\Program]](https://img-blog.csdnimg.cn/0961fa78d7b34300a7ec1cc93908d7f7.png)