编译 max compute-spark
git clone https://github.com/aliyun/MaxCompute-Spark
cd spark-3.x
mvn clean package -DskipTests
在 target 目录下生成 以下两个文件。
spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar
spark-examples_2.12-1.0.0-SNAPSHOT.jar
2. DataWorks 上传资源
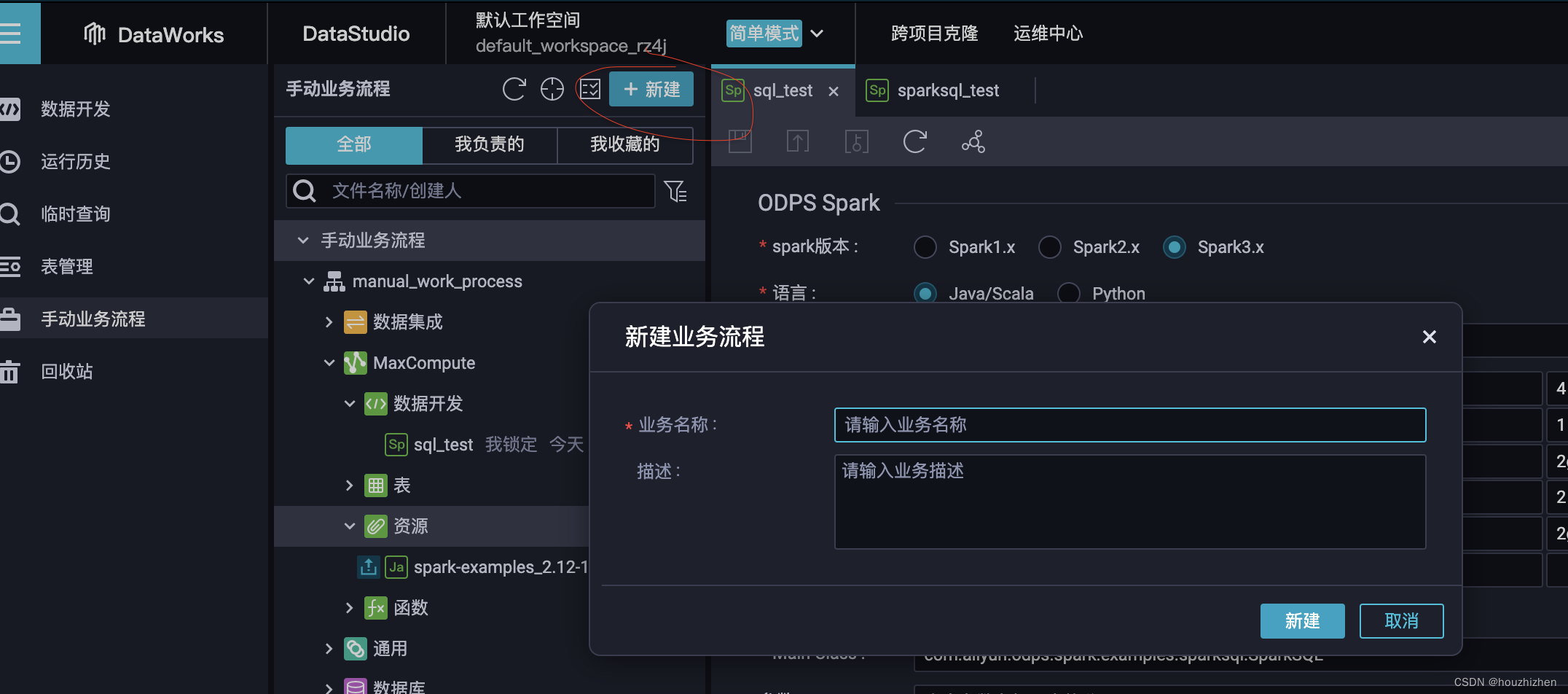
在 DataWorks 手动业务流程,点击【新建】,输入业务名称后,在下面【资源】中创建jar 资源 spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar。
在手动业务流程而不是数据开发中创建业务名称,是因为在数据开发中创建的是定时任务,需要有触发依赖条件等。
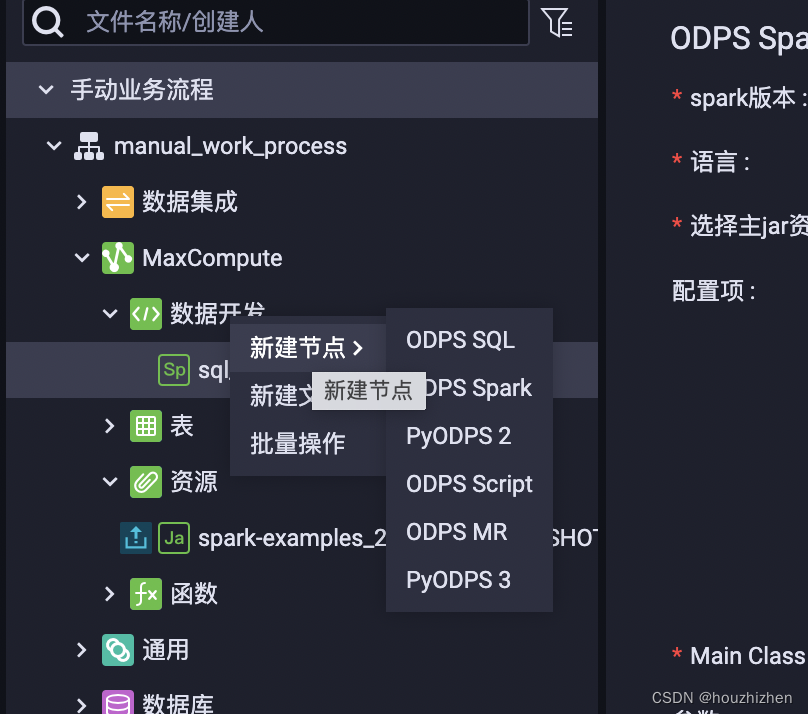
3. 创建 Spark 任务
点击【数据开发】,新建节点,选择【ODPS Spark】
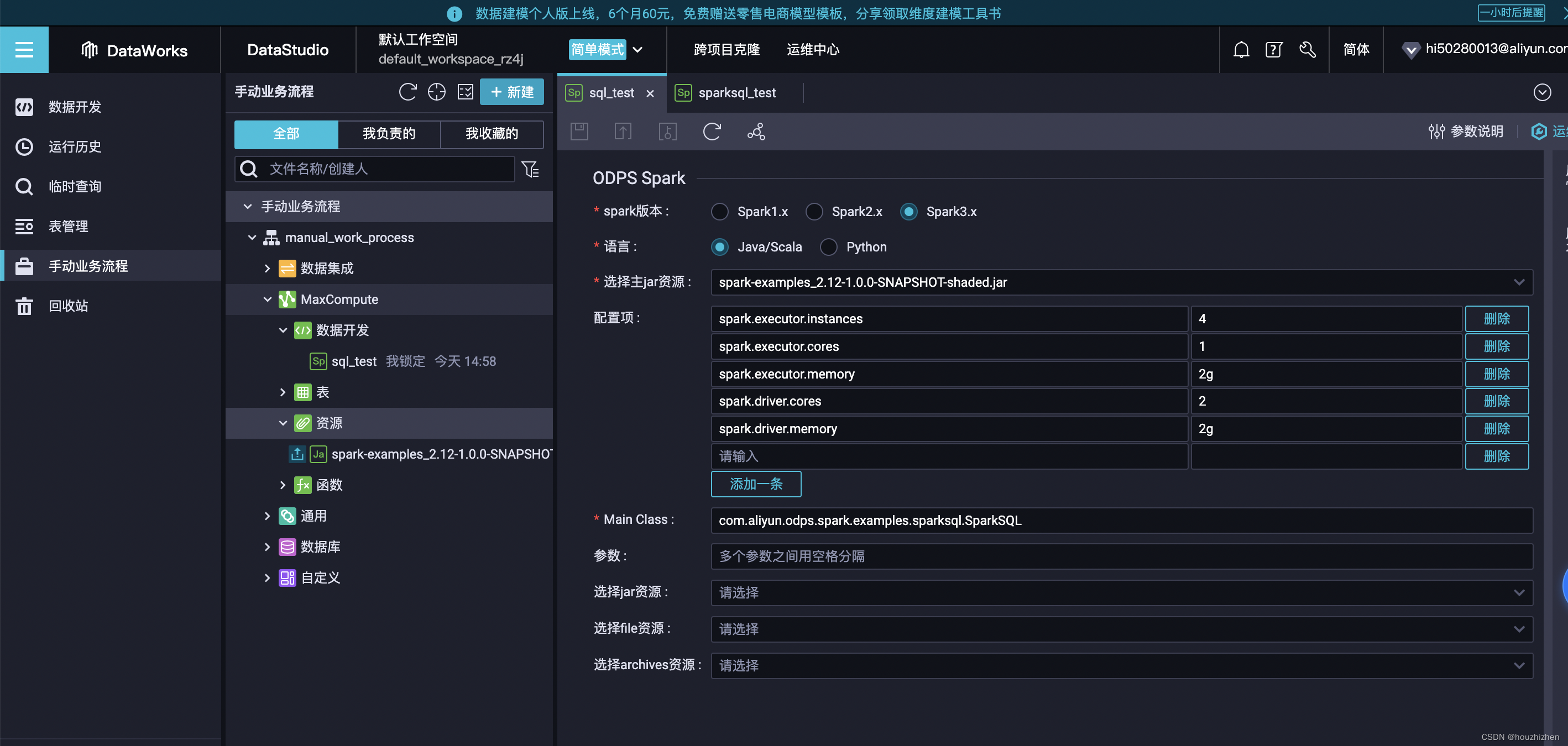
3.1 输入以下内容
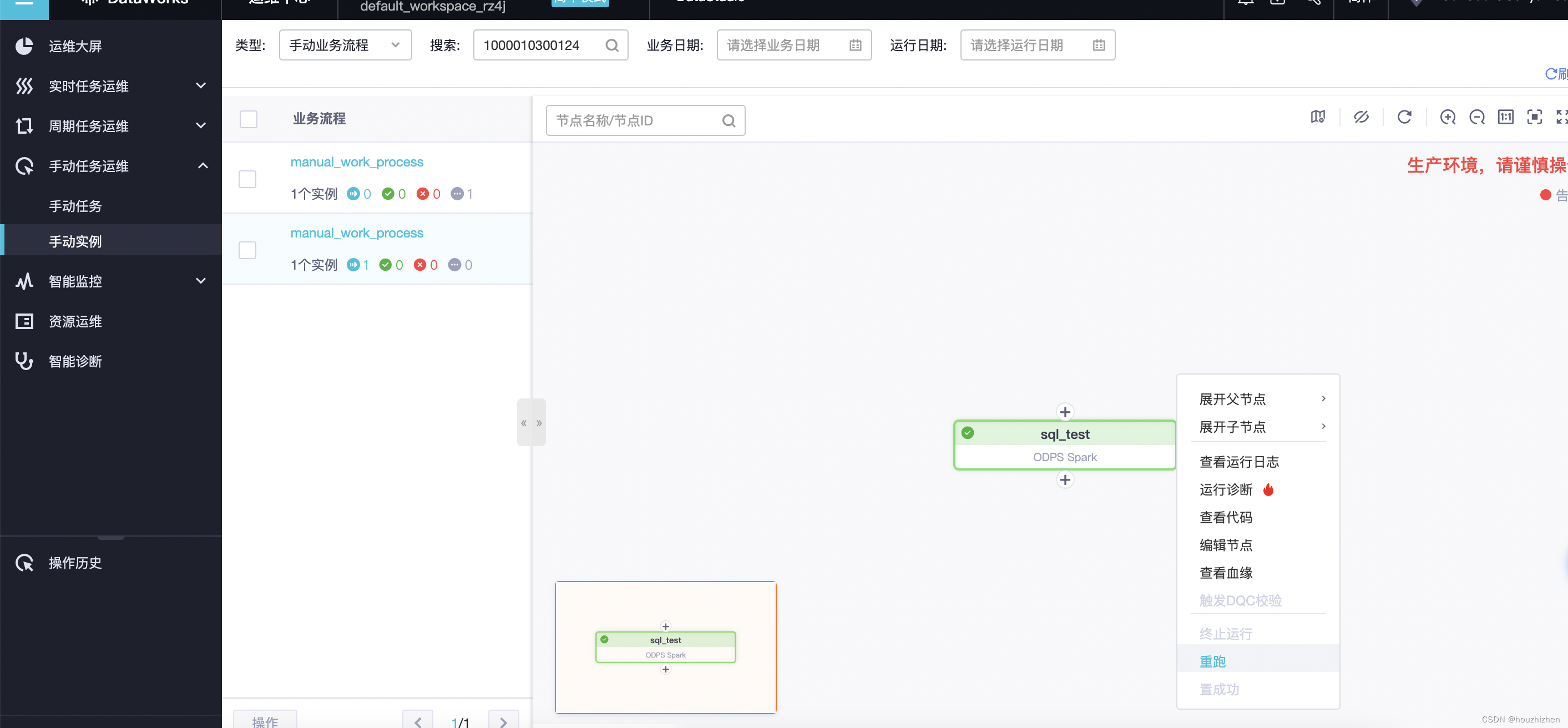
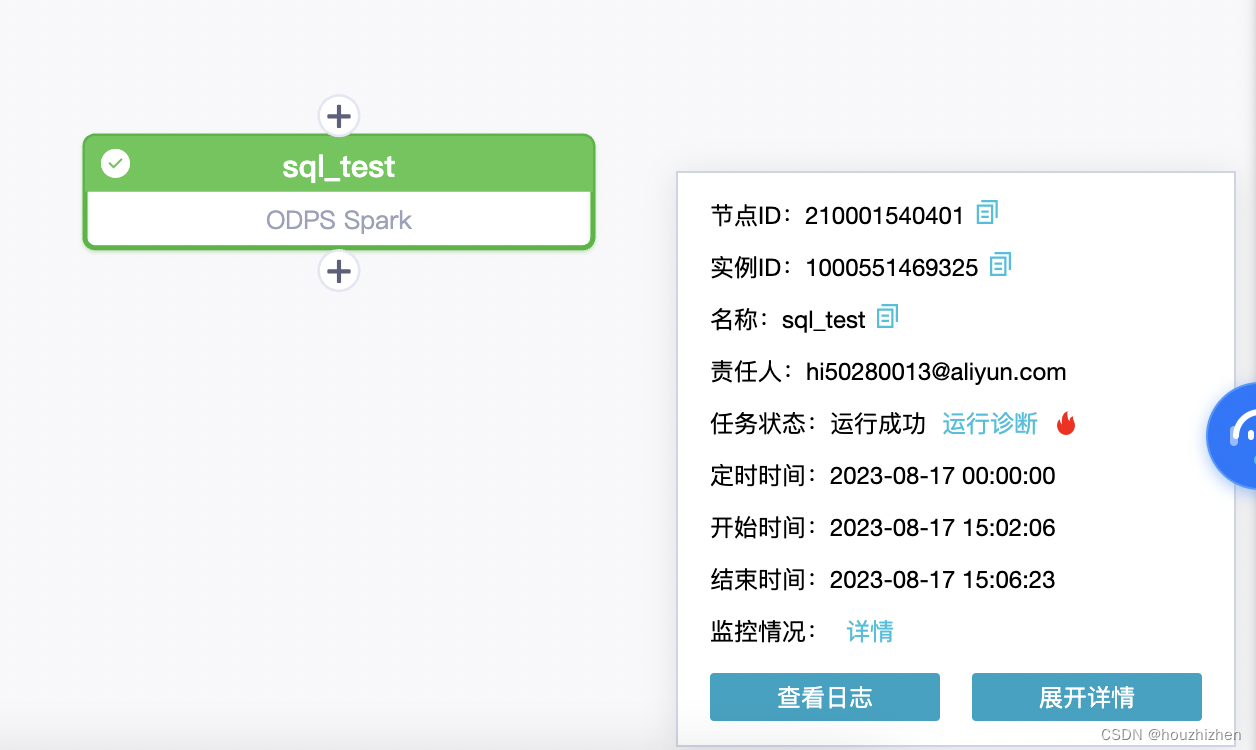
点击任务【在运维中心查看】
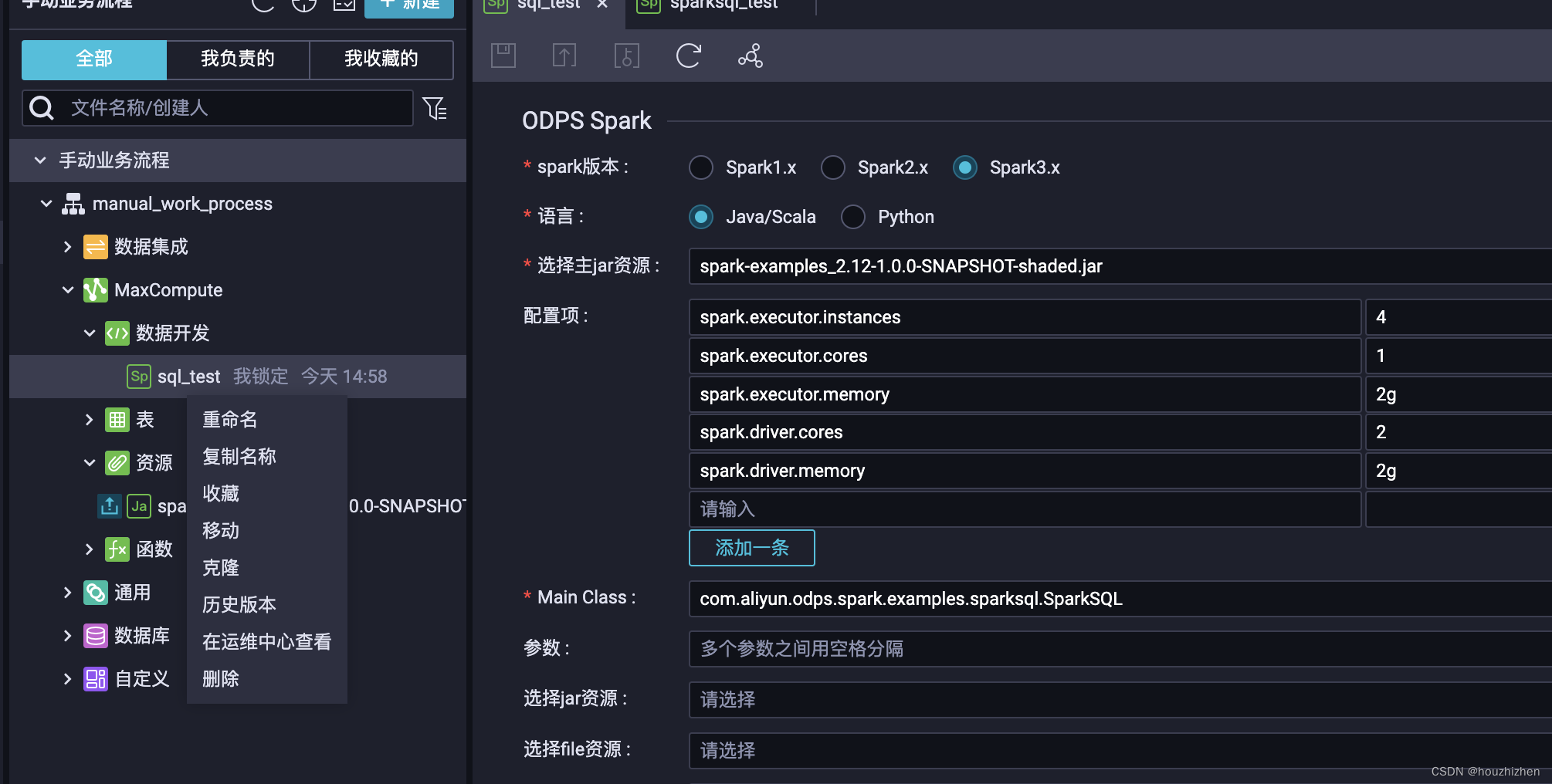
点击一个业务流程,出现任务在页面中,点击【重跑】。
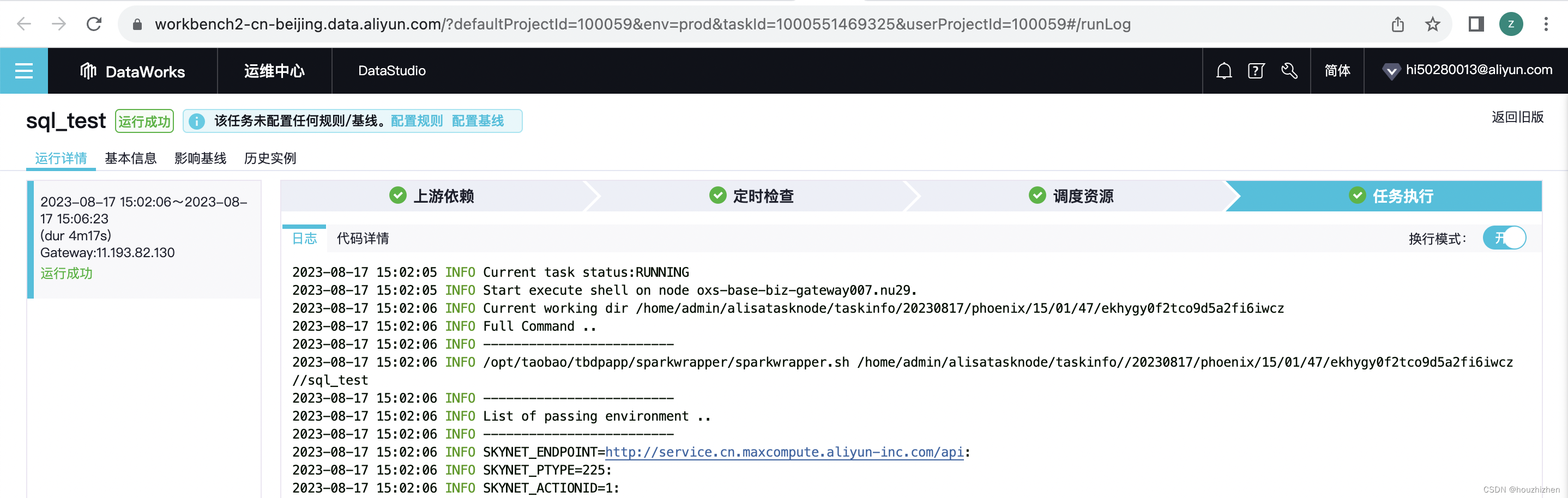
点击【查看运行日志】,进入以下界面。url:https://workbench2-cn-beijing.data.aliyun.com/?defaultProjectId=100059&env=prod&taskId=1000551469325&userProjectId=100059#/runLog
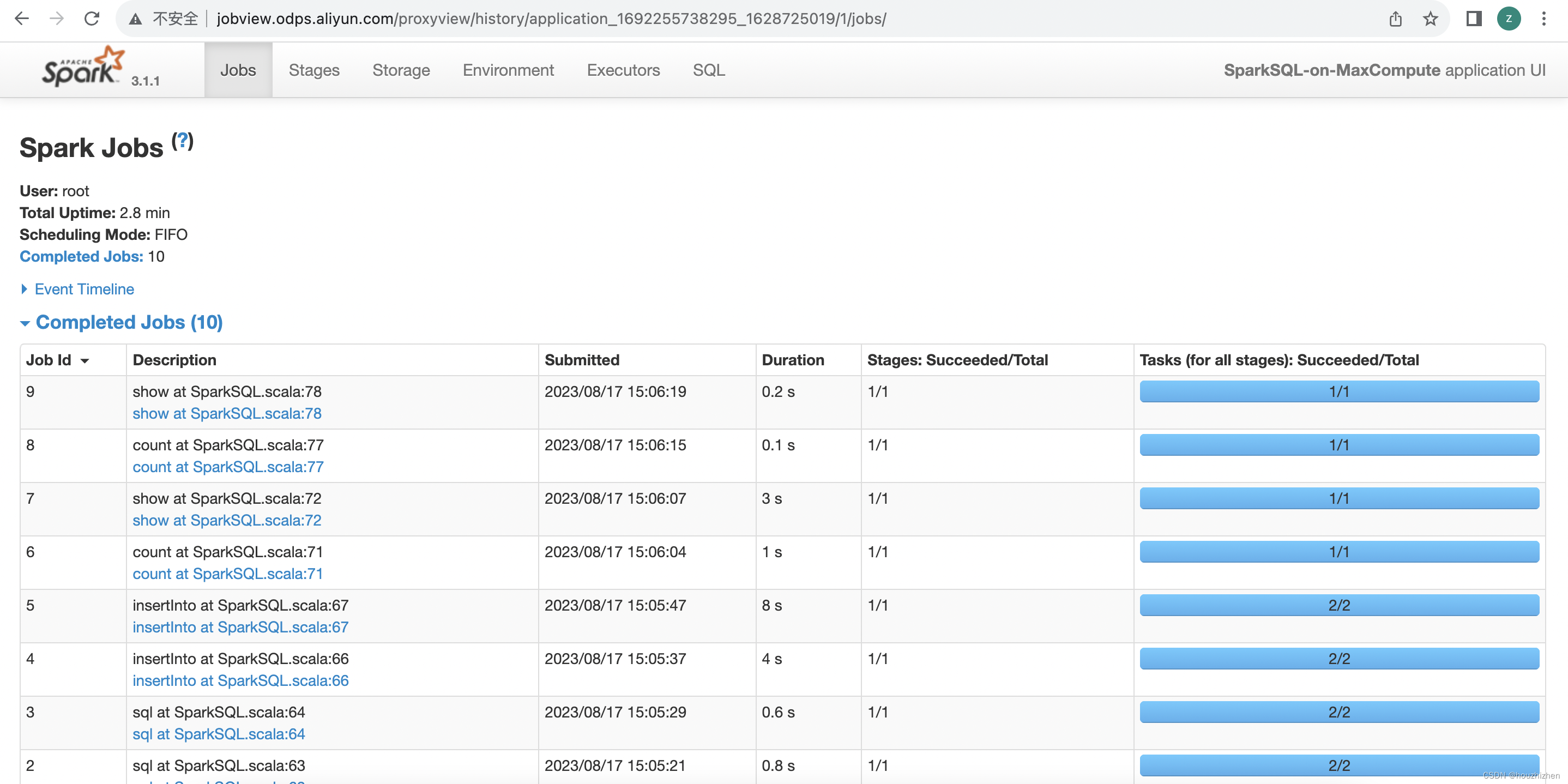
下面有 application url,点击进入 spark ui
Spark Executors 信息
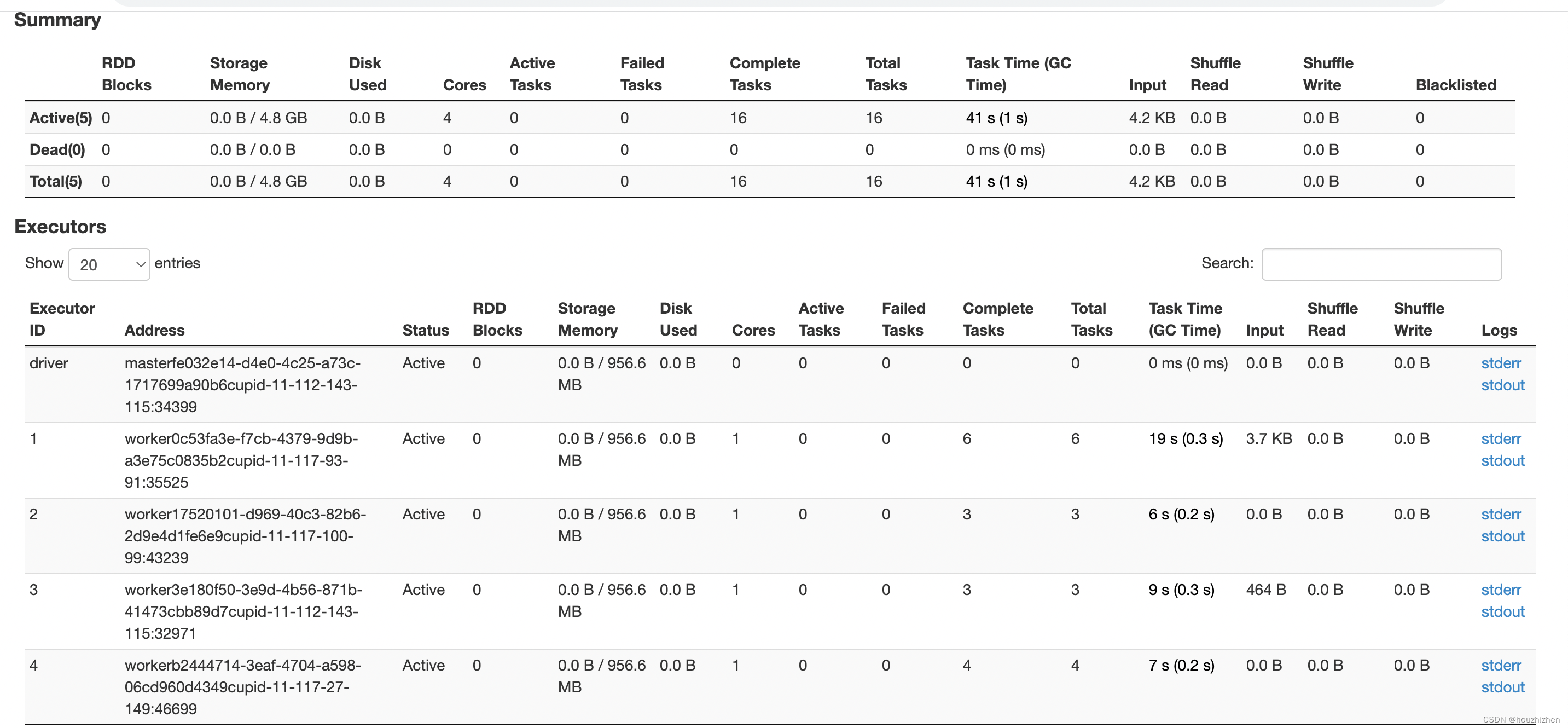
【任务】鼠标点击以下,可以看到如下内容。








![rocketMq启动broker报错找不到或无法加载主类 Files\Java\jdk1.8.0_171\lib\dt.jar;C:\Program]](https://img-blog.csdnimg.cn/0961fa78d7b34300a7ec1cc93908d7f7.png)