11. 亿级访问量数据处理
11.1 场景表述
- 手机APP用户登录信息,一天用户登录ID或设备ID
- 电商或者美团平台,一个商品对应的评论
- 文章对应的评论
- APP上有打卡信息
- 网站上访问量统计
- 统计新增用户第二天还留存
- 商品评论的排序
- 月活统计
- 统计独立访客(Unique Vistitor UV)量
11.2 集合的统计模式
四种统计模式:聚合统计、排序统计、二值状态统计、基数统计
11.2.1 聚合统计
多个集合的交集、差集、并集
set集合,来存储所有登录系统的用户 user:id
set集合,来存储当日新增用户信息 user:id :20211222
假设系统是2021年12月22日上线,统计当天用户
sadd user:id :20211222 1001 1002 1003 1004 1005
统计总用户量
sunionstore user:id user:id user:id :20211222
第2天12月23日上线用户
sadd user:id :20211223 1001 1003 1006 1007
统计当日新增用户
sdiffstore user:new user:id :20211223 user:id
统计第一天登录,第二天还在的用户
sinterstore user:save user:id :20211222 user:id :20211223
统计第一天登录,第二天流失的用户
sdiffstore user:rem user:id : 20211222 user:id :20211223
11.2.2排序统计
List、Set 、Hash 、ZSet四种集合中,List和Zset是属于有序的集合
一种使用List,通过lpush加入
一种使用Zset,按分数权重处理
11.2.3 二值状态统计
统计疫苗接种人数(没有接种0 接种1)、打卡(没有打卡0 打卡1)、签到。
bit位 1byte=8bit
redis提供一种扩展数据类型 bitmap。
- 常用命令
- setbit
- getbit
- bitcount
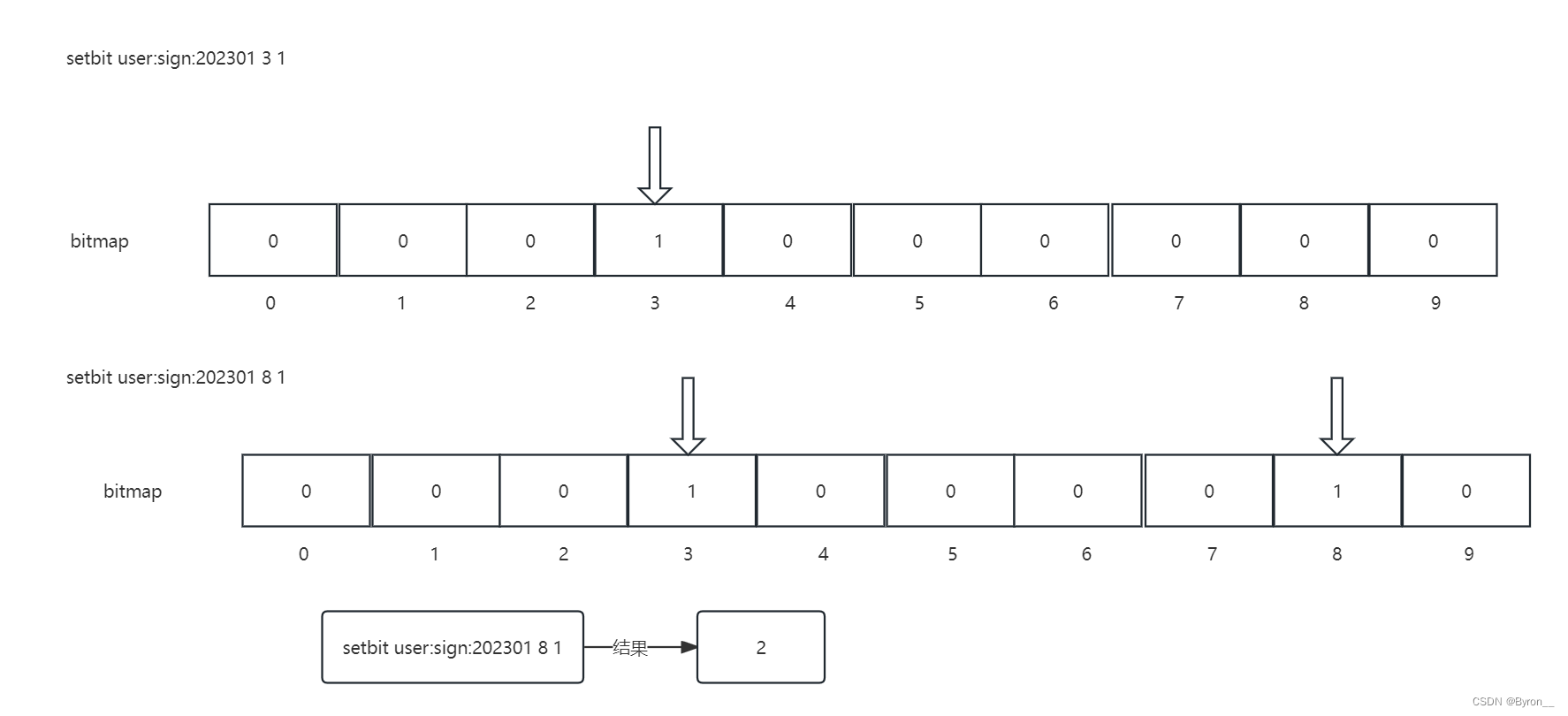
统计一下,2023年1月前10天上班打卡情况 0为未打卡,1为打卡
setbit user:sign:202301 1
setbit user:sign:202301 1 0
setbit user:sign:202301 2 1
setbit user:sign:202301 3 0
...
setbit user:sign:202301 8 1
setbit user:sign:202301 9 0
getbit user:sign:202301 1 //0 获取第二天是否打卡
bitcount user:sign:202301 //5 获取打卡成功的天数
bitcount user:sign:202301 0 1 // 后面可以跟两个参数 统计从第0个字节开始,到第1个字节结束的数据 第二个数据为-1时表示统计所有数据
bitmap表示的是字节位置存储的对应的数据
其保存过程为:
使用它进行统计大数据时极度节省内存
- 存储1亿用户一天信息约使用12m的内存
- 但使用字符串保存时,1亿用户大概使用800M内存
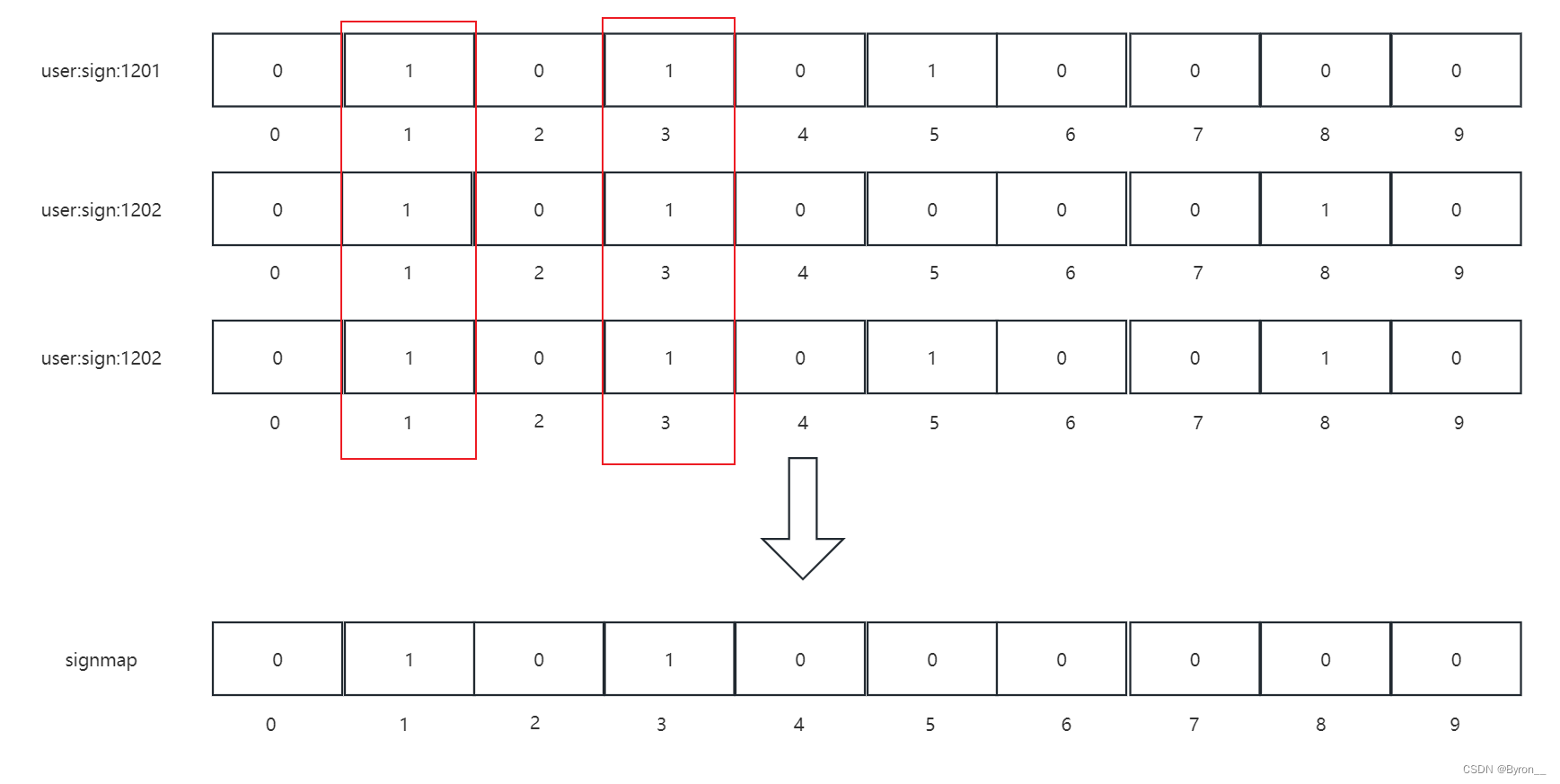
假如有一个场景是需要3天当中都签到的用户,就是对bitmap进行与运算
bitop and signmap user:sign:1201 user:sign:1202 user:sign:1203
使用以上命令把三天同时登录的用户都存入到signmap数组当中
11.2.4 基数统计
统计一个集合中不重复的元素个数,例如统计网页的UV
- 第一种,使用set或者hash来完成统计
- sadd page1:uv u1001 u1002 u1003
- scard page1:uv
存在的问题:如果数据量非常大,且页面多,访问人数非常多,造成内存紧张
-
第二种,Redis提供了HyperLogLog(hll)
- HyperLogLog是用于统计基数的一种数据集合类型。优点在于当集合元素非常多,使用hll所需要的空间是固定且很小,使用12kb内存,可以存储2^64个元素的基数。缺点在于统计规则是基于概率完成的。会有0.81%左右的误差。如果统计1000万次,实际上可以是1100万 或900万人。
-
命令
pfadd page1:uv u1001 u1002 u1003添加数据pfcount page1:uv统计数据pfadd page2:uv u1001 u1004添加数据pfmerge page:uv page1:uv page2:uv合并数据pfcount page:uv统计数据
11.2.5小结
| 数据类型 | 聚合统计 | 排序统计 | 二值状态统计 | 基数统计 |
|---|---|---|---|---|
| set | 支持差集、交集、并集 | 不支持 | 不支持 | 支持精确统计,数据量大时占用内存较大 |
| zset | 支持差集、交集、并集 | 支持 | 不支持 | 支持精确统计,数据量大时占用内存较大 |
| hash | 不支持 | 不支持 | 不支持 | 支持精确统计,数据量大时占用内存较大 |
| list | 不支持 | 支持 | 不支持 | 不支持 |
| bitmap | 与、或、异或运算 | 不支持 | 支持 | 支持精确统计,数据量大时占用内存较大 |
| hyperloglog | 不支持 | 不支持 | 不支持 | 支持,采用概率算法,大数据量时,节省内存,但不精确 |