文本挖掘与贝叶斯网络方法识别化学品安全风险因素
- 1. Introduction
- 现实意义
- 理论意义
- 提出方法,目标
- 2. 材料与方法
- 2.1 数据集
- 2.2 数据预处理
- 2.3 关键字提取
- 2.3.1 TF-IDF
- 2.3.2 改进的BM25——BM25W
- BM25
- BM25W
- 2.3.3 关键词的产生(相关系数)
- 2.4 关联规则分析
- 2.5 贝叶斯网络分析
1. Introduction
本研究旨在提出一种改进的文本挖掘方法来分析大量的化学品事故报告。设计了一个建立和更新分词词库的工作流。关联规则挖掘和贝叶斯网络分析的结果能够清晰地揭示安全风险因素之间的相互关系。本研究的方法可以快速有效地从事件报告中提取关键信息,为管理者提供新的见解和建议。
现实意义
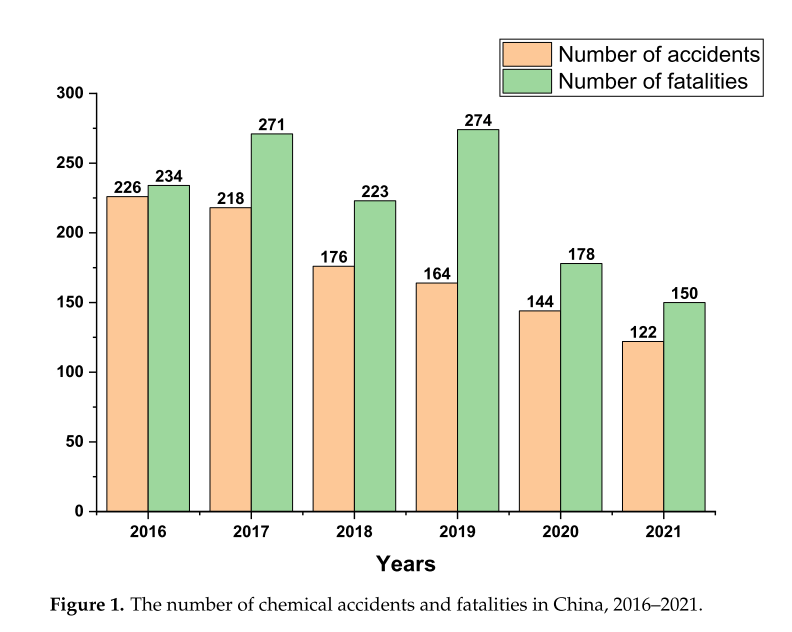
图1显示了2016年至2021年全国每年发生的化学品事故及死亡人数。化工事故1050起,死亡1330人,化工安全生产形势依然十分严峻。因此,在保证化工产品稳定供应的同时,提高安全生产水平具有重要的现实意义。
约80%的事故发生是由人为引起的,因此识别事故因素,挖掘内在联系,是很有必要的一件事。
理论意义
之前的化学事故研究更多的致力于安全评价方法,而不是分析原因;现有的分析方法是基于专家经验和依赖于人为的过程,以致分析不全面。此外,该化学品的事故报告也没有统一的标准格式,报告的内容是高度非结构化的。计算机无法直接处理这类信息,同时人为过程是耗时的,且会存在差错的过程。因此,需要一种自动安全风险识别方法来解决处理大型文本数据集的挑战。
一种常见的聚类方法是潜在Dirichlet分配(LDA)。LDA方法有助于有效地提高文本分类任务,这在许多高级专家和智能系统中是必不可少的,特别是在标记文本稀缺的情况下。Zhong等人[23]利用LDA模型生成的34类主题,为建筑行业的各种事故建立了深度学习(DL)和TM的框架,分析事故危害。Chen等人[24]构建了利益相关者分类体系,并利用LDA模型完成话题聚类,揭示了舆论场中利益相关者的话题焦点和演化路径。但是,他们检索的结果是以文字的形式来表示相应的信息,具有很高的不确定性。特别是在事故报告等大型文本中,一些词频很高的词并未指明具体的危险因素,但仍被提取为关键词。根据语料库和提取目的的不同,传统的文本挖掘已经不能有效识别安全风险因素,需要改进。
提出方法,目标
鉴于文本挖掘在化工安全研究中的应用较少,本文创造性地将文本挖掘、关联规则挖掘和贝叶斯网络相结合,应用于化工事故分析。
首先,在数据预处理中分别构建和更新域词典、同义词词典和中断词词典。然后我们改进了关键字提取方法,提出了BM25W模型。利用距离公式和社会技术系统对相关系数进行归一化处理,识别出安全风险因子。
然后,利用关联规则挖掘方法找到安全风险因素之间的强关联规则,并发现关键原因之间的关联。
最后,基于关联规则挖掘结果进行贝叶斯网络分析,找出化学品事故的重要因素、关键原因路径、高频因素和高度集中因素。并对这些结果进行了理论分析。
本研究不同于以往的知识驱动或模型驱动的研究,以数据驱动的方式分析文本数据的直接不可见模式和复杂关联。我们的目标是通过提供强有力的自动分析事故原因和优化安全策略来减少事故数量。
2. 材料与方法
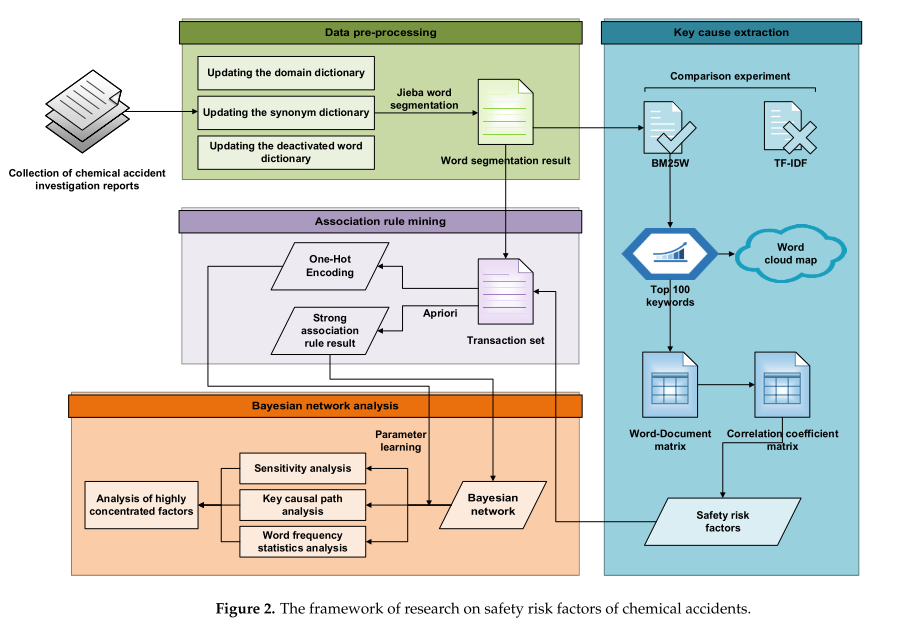
本研究主要包括数据预处理、关键原因提取、关联规则挖掘和贝叶斯网络分析四个部分,如图2所示。这四部分将在接下来的章节中逐一介绍
2.1 数据集
化工生产领域的事故调查报告是本文分析的原始语料库。这些报告是由安全管理领域的专家在事故发生后通过研究和分析来撰写的。获取事故调查报告的来源有很多。Esmaseili et al.[25]获得了美国国家职业安全与健康研究所(NIOSH)的事故报告,Rodrigues et al.[26]获得并分析了欧洲航空安全局(EASA)的事故报告,其他一些学者[27-29]也分别从相关官员那里获得了所需的数据。
中国的“化工企业生产安全事故报告和调查制度”规定,对涉及人员伤亡的事故,必须进行完整、准确、及时的记录和保存,任何单位和个人不得隐瞒。事故报告的内容应包括事故的原因、损失、责任、纠正措施等。与其他国家一样,中国也有专门的安全生产管理部门,即中华人民共和国应急管理部(https://www.mem.gov.cn/(2022年8月2日访问))和全国各省市应急管理部门。为保证数据来源的可靠性,共下载2011年至2022年上半年化工、危险化学品事故调查报告665份。
之后,我们对数据进行过滤,剔除不符合要求的数据,在化工生产领域留下330份事故调查报告。上述事故的级别和类型也被计算在内,如图3和4所示。
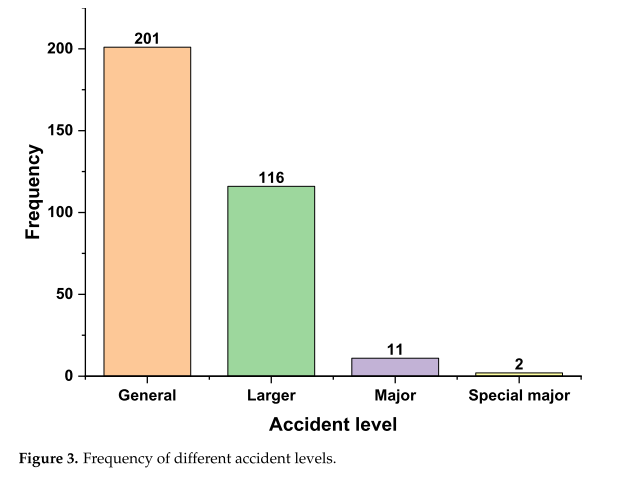
从图3可以看出,绝大多数事故是一般事故和较大事故。虽然这些事故造成的伤亡或损失的数量很少,但它们经常发生,而且仍然是非常严重的。
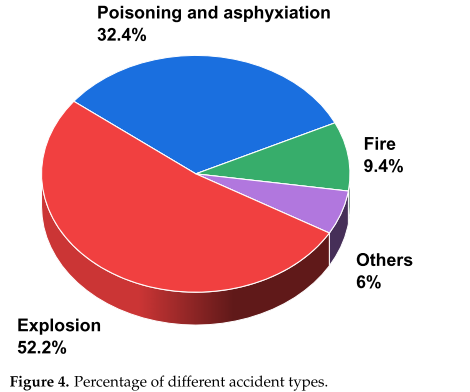
从图4可以看出,超过一半的事故类型是爆炸,其次是中毒和窒息。这是因为大多数化工生产领域涉及易燃易爆或有毒有害气体,容易造成混合气体爆炸或人中毒、窒息。
2.2 数据预处理
数据预处理是一个非常重要但繁琐的过程,因为原始语料库中含有大量不规则或无意义的词。最重要的任务之一是将原始中文文本分割成类似于用空格分隔的英文文本的格式,以便进行下一步的文本挖掘分析。
本研究中使用的文本分割工具是python3中的Jieba分割工具。我们观察到,化学品生产事故的原因一般由名词和动词或简单名词组成。因此,本研究仅选取普通名词、机构名、其他专名、普通动词、动名词进行分词。通过这种方式,Jieba在分词时自动排除了剩下的词汇分词结果。JiebaWSS分词系统包含三种词典,即领域词典、同义词词典和断词词典。
-
领域词典:虽然JiebaWSS提供了一个词典,包含了大部分常用的词(如反应器、管道等)用于切分词,但也有很多行业专用词无法识别,如蒸馏塔、中间操作室、蒸汽阀、气体检测器等。当涉及到这些词时,JiebaWSS可以将整个专有词分割成两个或多个词。这需要事先将这些特定于行业的单词集成到域字典中,并将字典添加到JiebaWSS中。
-
同义词词典:事故调查报告中的同义词很多,大量的同义词会使分词结果过于离散。我们可以用一个词来替换所有的同义词;例如,管道、管道、蒸汽管道、压力管道等,都可以用管道代替
-
停止词词典:事故调查报告中还含有大量无意义的词、数字和符号,如“我们”、“实际上”、“exactly”、“3”、“6”、“,”。“!”等等。这些词对于本研究的分析没有实际意义,可以添加到停止词词典中进行排除。
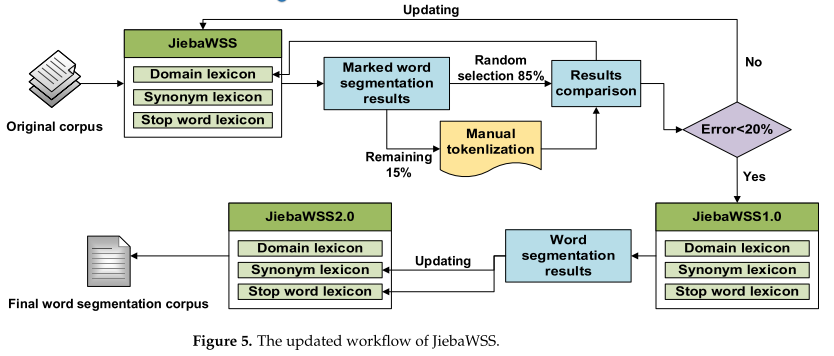
这三种词汇对分词结果有着直接的影响,而分词结果又对后续的分析产生了层叠效应。因此,有必要对这三个词汇进行更新,形成一个与本研究一致的JiebaWSS。本研究借鉴了esmaiili、Hallowell和Xu等人的词汇开发思想,设计了一种词汇更新方法。图5显示了该方法的工作流。
2.3 关键字提取
原语料库拆分结果的内容非常大,难以对事故进行直接的关键原因分析。关键词是能够表达文献关键内容的词,计算机系统中常用来引用论文的内容特点,进行信息检索,系统收集供读者查阅。
2.3.1 TF-IDF
关键词抽取是文本挖掘领域的一个分支,是文本检索、文档比较、摘要生成、文档分类、聚类[32]等文本挖掘研究的基础。传统的关键字提取方法主要有词频TF (word frequency)和词频逆文档频率TF- idf (word frequency - inverse document frequency)两种,使用简单方便。TF认为一个单词出现的频率越高,它对文档的贡献就越大。然而,对于事故调查报告来说,并不是简单地假设一个表示安全风险因素的词在文件中出现的频率越高,这个词就越重要。由于每一份事故调查报告的长度不同,一些不重要的词可能会在较长的文件中重复出现。为了减少高频的影响,TF-IDF在TF后乘以IDF,如式(2)所示。
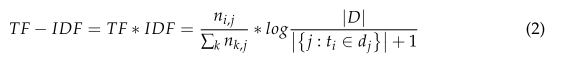
其中nij为单词ti在文档dj中出现的次数;
∑k nk,j表示文档dj中所有单词出现次数之和;
**|D|**表示整个语料库中的文档总数;
{j: ti∈dj}表示包含单词ti的文档数量。
但是TF- idf忽略了文档长度,其中单词ti的临界度得分仍然与词频TF线性相关。例如,如果一个1000字的文档有100字的a,而另一个5000字的文档有100字的a,那么很明显,单词a在这两个文档中的重要性是不同的。单词在长文档中的频率通常更高,这最终导致TF-IDF临界性评分仍然过于有利于长文档。为了改善这一问题,研究者提出了BM25模型[33],如式(3)所示。
2.3.2 改进的BM25——BM25W
BM25
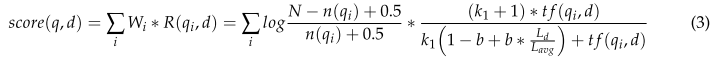
其中N为语料库中的文档总数; **n(qi)**是包含“qi”字的文献数量;
tf(qi, d)是文档d中qi出现的频率; Ld是文档的长度;
Lavg是整个语料库中所有文档的平均长度; k1和b是可自由调节的超参数;
一般情况下k1∈[1.2,2.0],b = 0.75。R(qi, d)对t f(qi, d)的函数是一个饱和递增函数,使得文档词频的增长与关键字得分的增长呈非线性相关。因此,本研究提出了一些基于BM25模型的改进,并用于关键词的提取。
BM25W
TF-IDF和BM25都考虑了单词和文档之间的关系,但没有考虑单词本身的语义对关键字提取的影响。对于表示安全风险因素的词语,一方面,我们一般认为词语越长,表示的信息越清晰、越专业,如device、safety device、safety interlock device[34,35]。特别是,我们希望能够提取出能够更清楚地表明安全风险因素的词语。另一方面,之前的领域词典的专有词都是由领域专家从文档中仔细检查和选择的,因此它们的语义表示更加清晰和专门化。因此,本文根据单词本身的语义对BM25模型进行加权。
首先,根据单词长度计算权重的公式如式(4)所示。
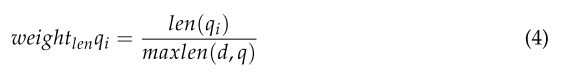
其中len(qi)表示单词qi的长度,maxlen(d, q)表示文档d中最长单词的长度。
其次,基于领域字典的权值计算公式如式(5)所示
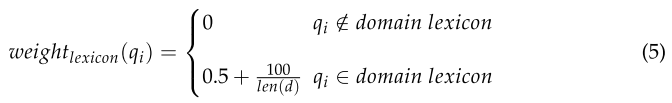
式(5)表示如果单词qi若不在领域词典中,则权重为0;否则,基础值设为0.5,再将文档d分词结果中每100个单词与单词个数的比值相加,将这两个权重的总和作为基于单词语义的权重,计算BM25模型的加权得分,如式(6)所示。
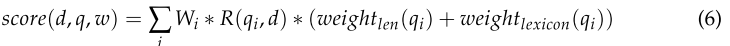
与式(3)对比:
在本研究中,这个新的模型称为BM25W,用于关键字提取。
2.3.3 关键词的产生(相关系数)
由于所提取的关键词只是单一的名词或动词,不能完全反映事故发生的原因,如专用设备、有毒有害气体、监督管理等。这是因为这些词可能有一些语义重复,或者可能没有具体反映一个隐藏的问题[36]。这些关键字需要标准化。**本研究首先将所有特征词通过计算机向量化为word-document matrix (TDM),如式(7)所示。**TDM是一个m x n的二维稀疏矩阵。
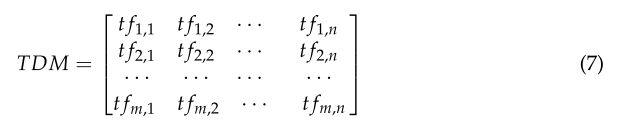
每一行表示一个文档dj, j∈m;每列表示一个特征词ti, i ∈ n;
t fm,n表示特征词tn在文件dm中的出现次数
通过这种方式,可以将高度非结构化的事件报告转换为结构化的数值类型数据。然后利用TDM计算特征项之间的相关系数,如式(8)所示。
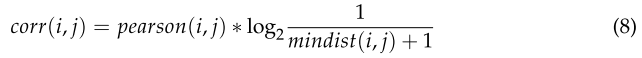
pearson(i, j):特征词i、j的皮尔逊相关系数;
mindist(i, j) :指代在所有文档中两个词之间的最短距离;
如果两个特性术语同时出现在文档中,但位置相距很远,那么很明显,在表示隐藏的问题时,这两个特性术语并不相关。TDM只表示特征词数量在整个语料库空间中的分布,而不反映特征词在文档中的位置关系。因此,本研究采用log2 {1/ mindist(i,j)+1} 作为两个特征项的距离权重,与Pearson相关系数相乘作为最终的相关系数。
2.4 关联规则分析
关联规则挖掘首先是由Agrawal在超市购物篮分析中提出的,它是一种研究数据库中项目集之间潜在相互关系的方法。它是目前数据挖掘领域最活跃的研究方向之一。关联规则可以从大量的事故数据中发现导致事故发生的不确定因素的关联特征,从而识别出因素之间的因果关系,帮助管理者进行决策。
因此,本研究在通过文本挖掘识别安全风险因素的基础上,采用关联规则挖掘的方法,获得安全风险因素之间的强关联规则,为后续的化学品安全风险因素分析和贝叶斯网络结构的构建奠定了基础。关联规则挖掘定义如下::
设:I = {i1, i2,…,in}是一个由n个称为items的二进制属性组成的集合,D = {t1, t2,…, tn}是一组称为数据库的事务。D中的每个事务都有一个唯一的事务ID,和包含I中项的一个子集。一条规则被描述为X⇒Y(由x可推得y),其中X, Y⊆I。
每条规则都由两个不同的项集组成,也称为项集X和Y,其中X称为先行项或左手边项(left-hand-side;LHS), Y称为后件项或右手边项(right-hand-side;RHS)。**为了从所有可能的集合规则中选择感兴趣的规则,使用了对不同意义和兴趣度量的约束。**最著名的约束是支持度和置信度的最小阈值。
-
设X是一个项目集,X⇒Y是一个关联规则,T是一个给定数据库的事务集。
-
支持度表明项目集在数据集中出现的频率,随着数据集的增长,项目集的先决条件变得更有限制性,而不是更具包容性。
-
X对T的支持定义为事务t在包含项目集X的数据集中所占的比例,计算方法如下:
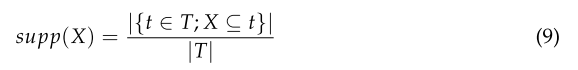
-
置信度表示该规则被发现为正确的频率,表示为:
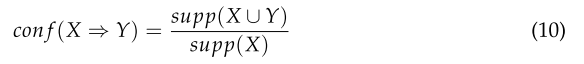
-
X⇒Y对一组交易T的置信值是包含X的交易中同时包含Y的交易所占的比例。如果conf (X⇒Y)的值等于1,则X⇒Y的规则是不可避免的。
关联规则需要同时满足最小支持度和最小置信度。在大多数情况下,关联规则的生成分为两个独立的步骤:
第一步应用最小支持阈值来查找数据库中的所有频繁项目集,
第二步应用最小置信约束来获取这些频繁项目集以形成规则。
-
安全风险因子最初并没有出现在文献中,而是通过标准化关键词得到的。因此,当一对关键字和非关键特征项同时出现在一个文档中,且距离不大于10时,我们认为这两个词归一化的安全风险因子在本文档中也存在。这样就可以得到关联规则挖掘所需的事务集,即上述事务数据集。
传统的关联规则挖掘算法主要有Apriori算法和FP-growth算法。
Apriori算法对事务数据库进行多次扫描,每次使用候选频繁集生成频繁集;
而FP-growth算法采用树形结构直接获取频繁集,不生成候选频繁集,大大减少了事务数据库的扫描次数,提高了算法的效率。
因此,FP-growth只能用于挖掘单维布尔关联规则。但由于安全风险因素之间的因果关系错综复杂,且多集关联规则数量众多,因此本研究采用Apriori算法进行关联规则挖掘。
2.5 贝叶斯网络分析
贝叶斯网络又称置信网络,是贝叶斯的延伸,是目前不确定知识表示和推理领域最有效的理论模型之一。自1988年Pearl提出贝叶斯网络以来,贝叶斯网络已成为近年来的研究热点。贝叶斯网络是由表示变量的节点和连接这些节点的有向边组成的有向无环图(DAG),如图6所示。
当事件A的发生影响到事件B的发生时,有如下关系(条件概率):

式(11)称为贝叶斯公式,其中P(A)和P(B)分别为事件A和事件B的先验概率;P(A|B)为后验概率(条件概率),即事件A发生时事件B发生的概率;P(B|A)表示似然概率,表示假设结果发生时,对原因发生的可能性的描述。对于任意随机变量,其联合概率可由各自的局部条件概率分布相乘得到,如式(12)所示。
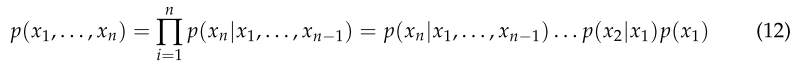
本文构建和分析化工事故因果关系网络的目的是通过定量分析明确化工安全生产系统的关键风险因素,从而提出更有针对性的事故预防策略。因此,本研究基于关联规则挖掘的结果构建了贝叶斯网络结构,并将事务集转化为One-Hot Encoding,用于贝叶斯网络的参数学习。然后对安全风险因素进行敏感性、关键原因路径和频次统计分析。
本研究采用GeNIe4.0软件进行贝叶斯网络分析。GeNIe Modeler是一个用于构建图形决策理论模型的开发环境。由于它们的通用性和可靠性,GeNIe和SMILE已经非常受欢迎,并成为学术界的事实上的标准,同时也受到许多政府、军事和商业用户的欢迎,而且GeNIe已经在许多教学、研究和商业环境[45]中进行了广泛的测试。