本章既是一个目前所学的很多技能的概括,也是一个更多标准库功能的探索。我们将构建一个与文件和命令行输入/输出交互的命令行工具来练习现在一些你已经掌握的 Rust 技能。
Rust 的运行速度、安全性、单二进制文件输出和跨平台支持使其成为创建命令行程序的绝佳选择,所以我们的项目将创建一个我们自己版本的经典命令行工具:grep。grep 是 “Globally search a Regular Expression and Print.” 的首字母缩写。grep 最简单的使用场景是在特定文件中搜索指定字符串。为此,grep 获取一个文件名和一个字符串作为参数,接着读取文件并找到其中包含字符串参数的行,然后打印出这些行。
在这个过程中,我们会展示如何让我们的命令行工具利用很多命令行工具中用到的终端功能。读取环境变量来使得用户可以配置工具的行为。打印到标准错误控制流(stderr) 而不是标准输出(stdout),例如这样用户可以选择将成功输出重定向到文件中的同时仍然在屏幕上显示错误信息。
12.1 接受命令参数行
一如既往使用cargo new 新建一个项目,我们称之为minigrep 以便与可能已经安装在系统上的grep 工具相区别。
第一个任务是让 minigrep 能够接受两个命令行参数:文件名和要搜索的字符串。也就是说我们希望能够使用 cargo run、要搜索的字符串和被搜索的文件的路径来运行程序,像这样:
cargo run searchstring example-filename.txt
读取参数值
为了确保 minigrep 能够获取传递给它的命令行参数的值,我们需要一个 Rust 标准库提供的函数,也就是 std::env::args。这个函数返回一个传递给程序的命令行参数的 迭代器(iterator)。但是现在只需理解迭代器的两个细节:迭代器生成一系列的值,可以在迭代器上调用 collect 方法将其转换为一个集合,比如包含所有迭代器产生元素的 vector。
use std::env;fn main() {let args : Vec<String> = env::args().collect();println!("{:?}", args);
}
首先使用 use 语句来将 std::env 模块引入作用域以便可以使用它的 args 函数。注意 std::env::args 函数被嵌套进了两层模块中。
注意
std::env::args在其任何参数包含无效 Unicode 字符时会 panic。如果你需要接受包含无效 Unicode 字符的参数,使用std::env::args_os代替。这个函数返回OsString值而不是String值。这里出于简单考虑使用了std::env::args,因为OsString值每个平台都不一样而且比String值处理起来更为复杂。
在 main 函数的第一行,我们调用了 env::args,并立即使用 collect 来创建了一个包含迭代器所有值的 vector。collect 可以被用来创建很多类型的集合,所以这里显式注明 args 的类型来指定我们需要一个字符串 vector。虽然在 Rust 中我们很少会需要注明类型,然而 collect 是一个经常需要注明类型的函数,因为 Rust 不能推断出你想要什么类型的集合。
最后,我们使用调试格式 :? 打印出 vector。让我们尝试分别用两种方式(不包含参数和包含参数)运行代码:

注意 vector 的第一个值是 "target/debug/minigrep",它是我们二进制文件的名称。这与 C 中的参数列表的行为相匹配,让程序使用在执行时调用它们的名称。如果要在消息中打印它或者根据用于调用程序的命令行别名更改程序的行为,通常可以方便地访问程序名称,不过考虑到本章的目的,我们将忽略它并只保存所需的两个参数。
将参数值保存进变量
打印出参数 vector 中的值展示了程序可以访问指定为命令行参数的值。现在需要将这两个参数的值保存进变量这样就可以在程序的余下部分使用这些值了。
use std::env;fn main() {let args : Vec<String> = env::args().collect();let query = &args[1]; // 索引0是文件名,所以从1开始?let file_name = &args[2];println!("Searching for {}", query);println!("In file {}", file_name);
}
结果
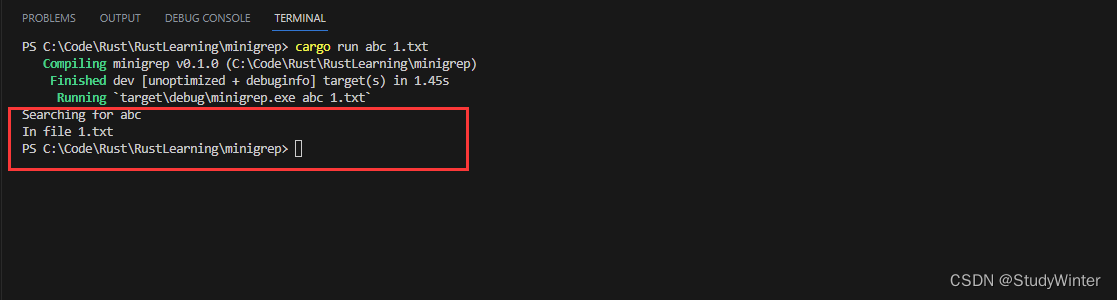
正如之前打印出 vector 时所所看到的,程序的名称占据了 vector 的第一个值 args[0],所以我们从索引 1 开始。minigrep 获取的第一个参数是需要搜索的字符串,所以将其将第一个参数的引用存放在变量 query 中。第二个参数将是文件名,所以将第二个参数的引用放入变量 filename 中。
12.2 读取文件
现在我们要增加读取由 filename 命令行参数指定的文件的功能。首先,需要一个用来测试的示例文件:用来确保 minigrep 正常工作的最好的文件是拥有多行少量文本且有一些重复单词的文件。
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
创建完这个文件之后,修改代码:
use std::env;
use std::fs;fn main() {let args: Vec<String> = env::args().collect();let query = &args[1];let filename = &args[2];println!("Searching for {}", query);println!("In file {}", filename);println!("In file {}", filename);let contents = fs::read_to_string(filename).expect("Something went wrong reading the file");println!("With text:\n{}", contents);
}
结果
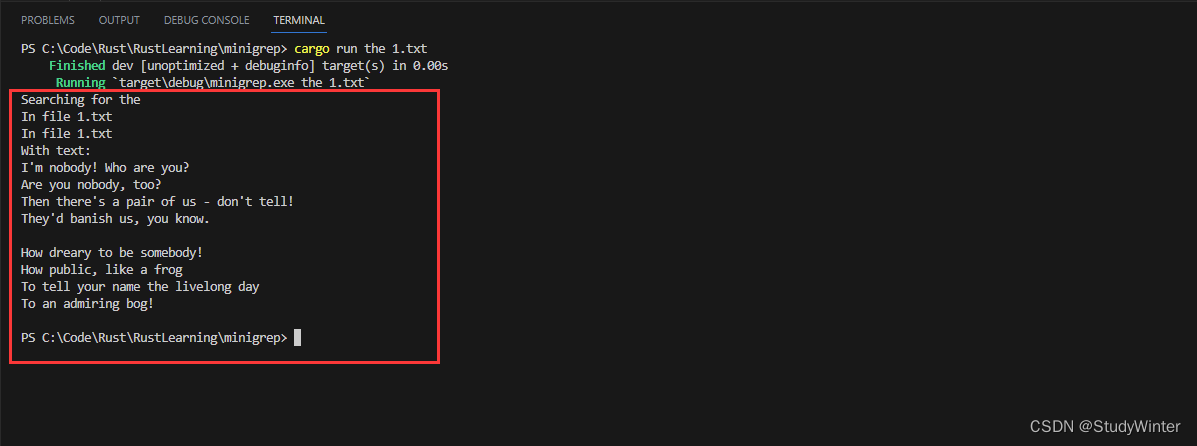
首先,我们增加了一个 use 语句来引入标准库中的相关部分:我们需要 std::fs 来处理文件。
在 main 中新增了一行语句:fs::read_to_string 接受 filename,打开文件,接着返回包含其内容的 Result<String>。
在这些代码之后,我们再次增加了临时的 println! 打印出读取文件之后 contents 的值,这样就可以检查目前为止的程序能否工作。
12.3 重构改进模块性和错误处理
为了改善我们的程序这里有四个问题需要修复,而且他们都与程序的组织方式和如何处理潜在错误有关。
第一,main 现在进行了两个任务:它解析了参数并打开了文件。对于一个这样的小函数,这并不是一个大问题。然而如果 main 中的功能持续增加,main 函数处理的独立任务也会增加。当函数承担了更多责任,它就更难以推导,更难以测试,并且更难以在不破坏其他部分的情况下做出修改。最好能分离出功能以便每个函数就负责一个任务。
这同时也关系到第二个问题:search 和 filename 是程序中的配置变量,而像 contents 则用来执行程序逻辑。随着 main 函数的增长,就需要引入更多的变量到作用域中,而当作用域中有更多的变量时,将更难以追踪每个变量的目的。最好能将配置变量组织进一个结构,这样就能使他们的目的更明确了。
第三个问题是如果打开文件失败我们使用 expect 来打印出错误信息,不过这个错误信息只是说 file not found。除了缺少文件之外还有很多可以导致打开文件失败的方式:例如,文件可能存在,不过可能没有打开它的权限。如果我们现在就出于这种情况,打印出的 file not found 错误信息就给了用户错误的建议!
第四,我们不停地使用 expect 来处理不同的错误,如果用户没有指定足够的参数来运行程序,他们会从 Rust 得到 index out of bounds 错误,而这并不能明确地解释问题。如果所有的错误处理都位于一处,这样将来的维护者在需要修改错误处理逻辑时就只需要考虑这一处代码。将所有的错误处理都放在一处也有助于确保我们打印的错误信息对终端用户来说是有意义的。
二进制项目的关注分离
这些过程有如下步骤:
- 将程序拆分成 main.rs 和 lib.rs 并将程序的逻辑放入 lib.rs 中。
- 当命令行解析逻辑比较小时,可以保留在 main.rs 中。
- 当命令行解析开始变得复杂时,也同样将其从 main.rs 提取到 lib.rs 中。
经过这些过程之后保留在 main 函数中的责任应该被限制为:
- 使用参数值调用命令行解析逻辑
- 设置任何其他的配置
- 调用 lib.rs 中的
run函数 - 如果
run返回错误,则处理这个错误
提取参数解析器
首先,我们将解析参数的功能提取到一个 main 将会调用的函数中,为将命令行解析逻辑移动到 src/lib.rs 中做准备。示例中展示了新 main 函数的开头,它调用了新函数 parse_config。目前它仍将定义在 src/main.rs 中:
use std::env;
use std::fs;fn main() {let args: Vec<String> = env::args().collect();let (query, filename) = parse_config(&args);}fn parse_config(args: &[String]) -> (&str, &str) {let query = &args[1];let filename = &args[2];(query, filename)
}
我们仍然将命令行参数收集进一个 vector,不过不同于在 main 函数中将索引 1 的参数值赋值给变量 query 和将索引 2 的值赋值给变量 filename,我们将整个 vector 传递给 parse_config 函数。接着 parse_config 函数将包含决定哪个参数该放入哪个变量的逻辑,并将这些值返回到 main。仍然在 main 中创建变量 query 和 filename,不过 main 不再负责处理命令行参数与变量如何对应。
组合配置值
现在函数返回一个元组,不过立刻又将元组拆成了独立的部分。这是一个我们可能没有进行正确抽象的信号。
另一个表明还有改进空间的迹象是 parse_config 名称的 config 部分,它暗示了我们返回的两个值是相关的并都是一个配置值的一部分。目前除了将这两个值组合进元组之外并没有表达这个数据结构的意义:我们可以将这两个值放入一个结构体并给每个字段一个有意义的名字。这会让未来的维护者更容易理解不同的值如何相互关联以及他们的目的。
use std::env;
use std::fs;fn main() {let args: Vec<String> = env::args().collect();let config = parse_config(&args);println!("Searching for {}", config.query);println!("In file {}", config.filename);println!("In file {}", config.filename);let contents = fs::read_to_string(config.filename).expect("Something went wrong reading the file");println!("With text:\n{}", contents);
}// 抽象成结构体
struct Config {query: String,filename: String,
}fn parse_config(args: &[String]) -> Config {let query = args[1].clone();let filename = args[2].clone();Config{query, filename}
}新定义的结构体 Config 中包含字段 query 和 filename。 parse_config 的签名表明它现在返回一个 Config 值。在之前的 parse_config 函数体中,我们返回了引用 args 中 String 值的字符串 slice,现在我们定义 Config 来包含拥有所有权的 String 值。main 中的 args 变量是参数值的所有者并只允许 parse_config 函数借用他们,这意味着如果 Config 尝试获取 args 中值的所有权将违反 Rust 的借用规则。
还有许多不同的方式可以处理 String 的数据,而最简单但有些不太高效的方式是调用这些值的 clone 方法。这会生成 Config 实例可以拥有的数据的完整拷贝,不过会比储存字符串数据的引用消耗更多的时间和内存。不过拷贝数据使得代码显得更加直白因为无需管理引用的生命周期,所以在这种情况下牺牲一小部分性能来换取简洁性的取舍是值得的。
使用clone的权衡取舍
由于其运行时消耗,许多 Rustacean 之间有一个趋势是倾向于避免使用clone来解决所有权问题。在关于迭代器的第十三章中,我们将会学习如何更有效率的处理这种情况,不过现在,复制一些字符串来取得进展是没有问题的,因为只会进行一次这样的拷贝,而且文件名和要搜索的字符串都比较短。在第一轮编写时拥有一个可以工作但有点低效的程序要比尝试过度优化代码更好一些。随着你对 Rust 更加熟练,将能更轻松的直奔合适的方法,不过现在调用clone是完全可以接受的。
创建一个Config 的构造函数
还可以将 parse_config 从一个普通函数变为一个叫做 new 的与结构体关联的函数。做出这个改变使得代码更符合习惯:可以像标准库中的 String 调用 String::new 来创建一个该类型的实例那样,将 parse_config 变为一个与 Config 关联的 new 函数。
use std::env;
use std::fs;fn main() {let args: Vec<String> = env::args().collect();let config = Config::new(&args);println!("Searching for {}", config.query);println!("In file {}", config.filename);println!("In file {}", config.filename);let contents = fs::read_to_string(config.filename).expect("Something went wrong reading the file");println!("With text:\n{}", contents);
}// 抽象成结构体
struct Config {query: String,filename: String,
}// 构造函数
impl Config {fn new(args: &[String]) -> Config {let query = args[1].clone();let filename = args[2].clone();Config{query, filename}}
}这里将 main 中调用 parse_config 的地方更新为调用 Config::new。我们将 parse_config 的名字改为 new 并将其移动到 impl 块中,这使得 new 函数与 Config 相关联。再次尝试编译并确保它可以工作。
修复错误处理
现在我们开始修复错误处理。回忆一下之前提到过如果 args vector 包含少于 3 个项并尝试访问 vector 中索引 1 或索引 2 的值会造成程序 panic。尝试不带任何参数运行程序;这将看起来像这样:
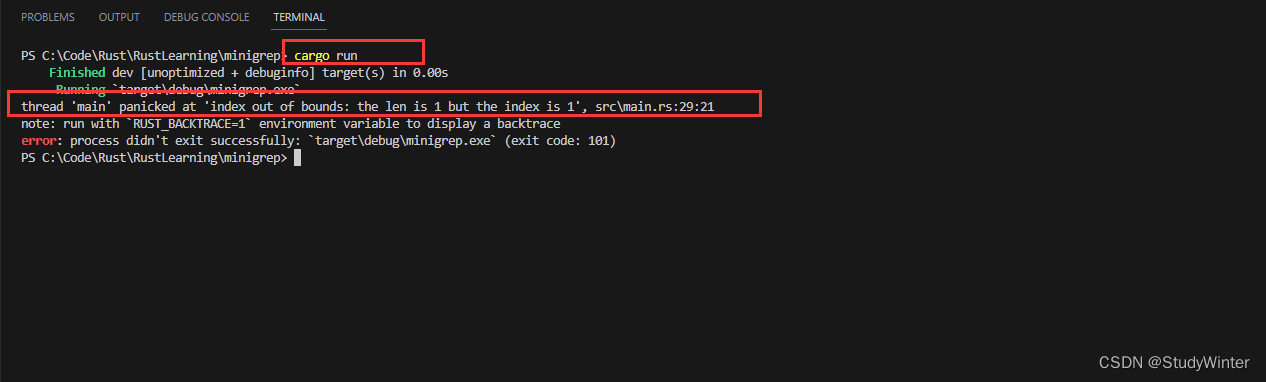
改善错误信息
在 new 函数中增加了一个检查在访问索引 1 和 2 之前检查 slice 是否足够长。如果 slice 不够长,我们使用一个更好的错误信息 panic 而不是 index out of bounds 信息:
// 构造函数
impl Config {fn new(args: &[String]) -> Config {if args.len() < 3 {panic!("not enough arguments");}let query = args[1].clone();let filename = args[2].clone();Config{query, filename}}
}有了 new 中这几行额外的代码,再次不带任何参数运行程序并看看现在错误看起来像什么:
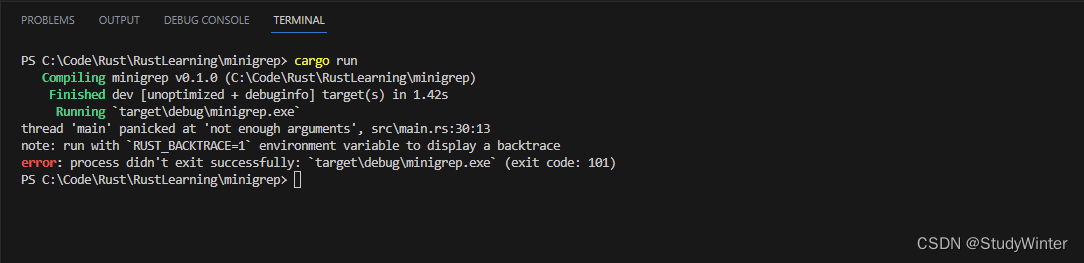
从new中返回Result而不是调用panic!
我们可以选择返回一个 Result 值,它在成功时会包含一个 Config 的实例,而在错误时会描述问题。当 Config::new 与 main 交流时,可以使用 Result 类型来表明这里存在问题。接着修改 main 将 Err 成员转换为对用户更友好的错误,而不是 panic! 调用产生的关于 thread 'main' 和 RUST_BACKTRACE 的文本。
use std::env;
use std::fs;
use std::process;fn main() {let args: Vec<String> = env::args().collect();// 这诡异的写法let config = Config::new(&args).unwrap_or_else(|err| {println!("Problem parsing arguments: {}", err);process::exit(1);});println!("Searching for {}", config.query);println!("In file {}", config.filename);println!("In file {}", config.filename);let contents = fs::read_to_string(config.filename).expect("Something went wrong reading the file");println!("With text:\n{}", contents);
}// 抽象成结构体
struct Config {query: String,filename: String,
}// 构造函数,这里返回值有变化
impl Config {fn new(args: &[String]) -> Result<Config, &'static str> {if args.len() < 3 {return Err("not enough arguments");}let query = args[1].clone();let filename = args[2].clone();Ok(Config{query, filename})}
}
现在 new 函数返回一个 Result,在成功时带有一个 Config 实例而在出现错误时带有一个 &'static str。回忆一下第十章 “静态生命周期” 中讲到 &'static str 是字符串字面值的类型,也是目前的错误信息。
new 函数体中有两处修改:当没有足够参数时不再调用 panic!,而是返回 Err 值。同时我们将 Config 返回值包装进 Ok 成员中。这些修改使得函数符合其新的类型签名。
通过让 Config::new 返回一个 Err 值,这就允许 main 函数处理 new 函数返回的 Result 值并在出现错误的情况更明确的结束进程。
在上面的示例中,使用了一个之前没有涉及到的方法:unwrap_or_else,它定义于标准库的 Result<T, E> 上。使用 unwrap_or_else 可以进行一些自定义的非 panic! 的错误处理。当 Result 是 Ok 时,这个方法的行为类似于 unwrap:它返回 Ok 内部封装的值。然而,当其值是 Err 时,该方法会调用一个 闭包(closure),也就是一个我们定义的作为参数传递给 unwrap_or_else 的匿名函数。
新增了一个 use 行来从标准库中导入 process。在错误的情况闭包中将被运行的代码只有两行:我们打印出了 err 值,接着调用了 std::process::exit。process::exit 会立即停止程序并将传递给它的数字作为退出状态码。
写法太诡异了
从main提取逻辑
目前我们只进行小的增量式的提取函数的改进。我们仍将在 src/main.rs 中定义这个函数:
fn main() {let args: Vec<String> = env::args().collect();// 这诡异的写法let config = Config::new(&args).unwrap_or_else(|err| {println!("Problem parsing arguments: {}", err);process::exit(1);});println!("Searching for {}", config.query);println!("In file {}", config.filename);run(config);}fn run(config: Config) {let contents = fs::read_to_string(config.filename).expect("Something went wrong reading the file");println!("With text:\n{}", contents);
}// ...从run函数中返回错误
进一步以一种对用户友好的方式统一 main 中的错误处理。
use std::error::Error;// --snip--fn run(config: Config) -> Result<(), Box<dyn Error>> {let contents = fs::read_to_string(config.filename)?;println!("With text:\n{}", contents);Ok(())
}
这里我们做出了三个明显的修改。首先,将 run 函数的返回类型变为 Result<(), Box<dyn Error>>。之前这个函数返回 unit 类型 (),现在它仍然保持作为 Ok 时的返回值。
第二个改变是去掉了 expect 调用并替换为第九章讲到的 ?。不同于遇到错误就 panic!,? 会从函数中返回错误值并让调用者来处理它。
第三个修改是现在成功时这个函数会返回一个 Ok 值。因为 run 函数签名中声明成功类型返回值是 (),这意味着需要将 unit 类型值包装进 Ok 值中。Ok(()) 一开始看起来有点奇怪,不过这样使用 () 是表明我们调用 run 只是为了它的副作用的惯用方式;它并没有返回什么有意义的值。
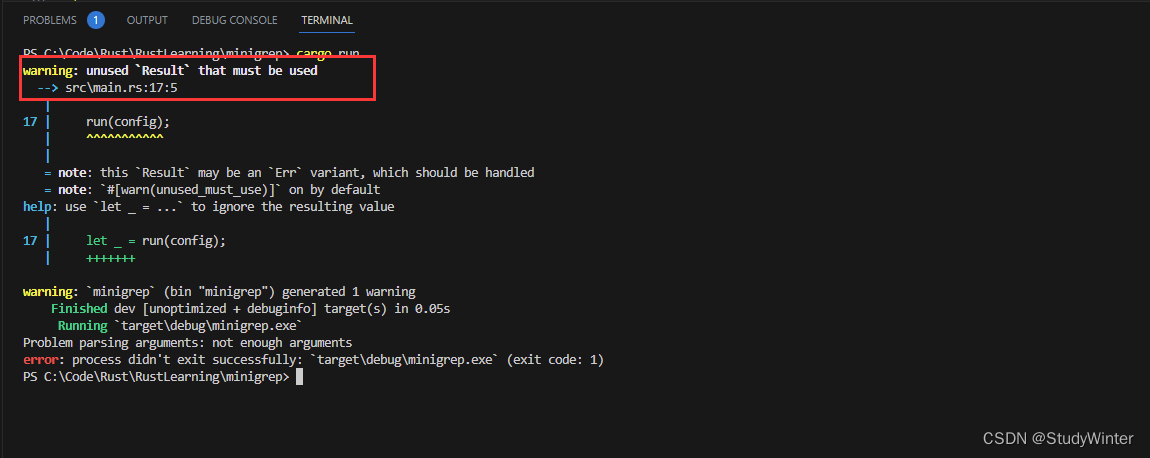
Rust 提示我们的代码忽略了 Result 值,它可能表明这里存在一个错误。虽然我们没有检查这里是否有一个错误,而编译器提醒我们这里应该有一些错误处理代码!现在就让我们修正这个问题。
处理main 中run返回的错误
fn main() {// --snip--println!("Searching for {}", config.query);println!("In file {}", config.filename);if let Err(e) = run(config) {println!("Application error: {}", e);process::exit(1);}
}
我们使用 if let 来检查 run 是否返回一个 Err 值,不同于 unwrap_or_else,并在出错时调用 process::exit(1)。run 并不返回像 Config::new 返回的 Config 实例那样需要 unwrap 的值。因为 run 在成功时返回 (),而我们只关心检测错误,所以并不需要 unwrap_or_else 来返回未封装的值,因为它只会是 ()。
将代码拆分到库crate
让我们将所有不是 main 函数的代码从 src/main.rs 移动到新文件 src/lib.rs 中:
run函数定义- 相关的
use语句 Config的定义Config::new函数定义
lib.rs
use std::fs;
use std::error::Error;// 结构体
pub struct Config {pub query: String,pub filename: String,
}// 构造函数,这里返回值有变化
impl Config {pub fn new(args: &[String]) -> Result<Config, &'static str> {if args.len() < 3 {return Err("not enough arguments");}let query = args[1].clone();let filename = args[2].clone();Ok(Config{query, filename})}
}// run函数
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {let contents = fs::read_to_string(config.filename)?;println!("With text:\n{}", contents);Ok(())
}
main.rs
use std::env;
use std::process;
use minigrep::Config;fn main() {let args: Vec<String> = env::args().collect();// 这诡异的写法let config = Config::new(&args).unwrap_or_else(|err| {println!("Problem parsing arguments: {}", err);process::exit(1);});// 注意run的引用方式if let Err(e) = minigrep::run(config) {println!("Application error: {}", e);process::exit(1);}
}
这里使用了公有的 pub 关键字:在 Config、其字段和其 new 方法,以及 run 函数上。现在我们有了一个拥有可以测试的公有 API 的库 crate 了。
为了将库 crate 引入二进制 crate,我们使用了 use minigrep。接着 use minigrep::Config 将 Config 类型引入作用域,并使用 crate 名称作为 run 函数的前缀。通过这些重构,所有功能应该能够联系在一起并运行了。运行 cargo run 来确保一切都正确的衔接在一起。
13.4 采用测试驱动开发完善库的功能
在这一部分,我们将遵循测试驱动开发(Test Driven Development, TDD)的模式来逐步增加 minigrep 的搜索逻辑。这是一个软件开发技术,它遵循如下步骤:
- 编写一个会失败的测试,并运行它以确保其因为你期望的原因失败。
- 编写或修改刚好足够的代码来使得新的测试通过。
- 重构刚刚增加或修改的代码,并确保测试仍然能通过。
- 从步骤 1 开始重复!
这只是众多编写软件的方法之一,不过 TDD 有助于驱动代码的设计。在编写能使测试通过的代码之前编写测试有助于在开发过程中保持高测试覆盖率。
编写失败测试
去掉 src/lib.rs 和 src/main.rs 中用于检查程序行为的 println! 语句,因为不再真正需要他们了。加入测试。测试函数指定了 search 函数期望拥有的行为:它会获取一个需要查询的字符串和用来查询的文本,并只会返回包含请求的文本行。
文件名: src/lib.rs
#[cfg(test)]
mod tests {use super::*;#[test]fn one_result() {let query = "duct";let contents = "\
Rust:
safe, fast, productive.
Pick three.";assert_eq!(vec!["safe, fast, productive."],search(query, contents));}
}这里选择使用 "duct" 作为这个测试中需要搜索的字符串。用来搜索的文本有三行,其中只有一行包含 "duct"。我们断言 search 函数的返回值只包含期望的那一行。
我们还不能运行这个测试并看到它失败,因为它甚至都还不能编译:search 函数还不存在呢!我们将增加足够的代码来使其能够编译:一个总是会返回空 vector 的 search 函数定义
文件名: src/lib.rs
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {vec![]
}注意需要在 search 的签名中定义一个显式生命周期 'a 并用于 contents 参数和返回值。回忆一下第十章中讲到生命周期参数指定哪个参数的生命周期与返回值的生命周期相关联。在这个例子中,我们表明返回的 vector 中应该包含引用参数 contents(而不是参数query) slice 的字符串 slice。
换句话说,我们告诉 Rust 函数 search 返回的数据将与 search 函数中的参数 contents 的数据存在的一样久。这是非常重要的!为了使这个引用有效那么 被 slice 引用的数据也需要保持有效;如果编译器认为我们是在创建 query 而不是 contents 的字符串 slice,那么安全检查将是不正确的。

编写使测试通过的代码
目前测试之所以会失败是因为我们总是返回一个空的 vector。为了修复并实现 search,我们的程序需要遵循如下步骤:
- 遍历内容的每一行文本。
- 查看这一行是否包含要搜索的字符串。
- 如果有,将这一行加入列表返回值中。
- 如果没有,什么也不做。
- 返回匹配到的结果列表
让我们一步一步的来,从遍历每行开始。
使用lines方法遍历每—行
Rust有一个有助于一行一行遍历字符串的方法,出于方便它被命名为lines,它如示例这样工作。注意这还不能编译:
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {for line in contents.lines() {// do something}
}lines 方法返回一个迭代器。
用查询宁符串搜索每一行
接下来将会增加检查当前行是否包含查询字符串的功能。幸运的是,字符串类型为此也有一个叫做
contains的实用方法!如示例所示在search函数中加入contains方法调用。注意这仍然不能编译:
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {for line in contents.lines() {if line.contains(query) {// }}
}存储匹配的行
我们还需要一个方法来存储包含查询字符串的行。为此可以在 for 循环之前创建一个可变的 vector 并调用 push 方法在 vector 中存放一个 line。在 for 循环之后,返回这个 vector
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {let mut results = Vec::new();for line in contents.lines() {if line.contains(query) {results.push(line)}}results
}现在 search 函数应该返回只包含 query 的那些行,而测试应该会通过。让我们运行测试:
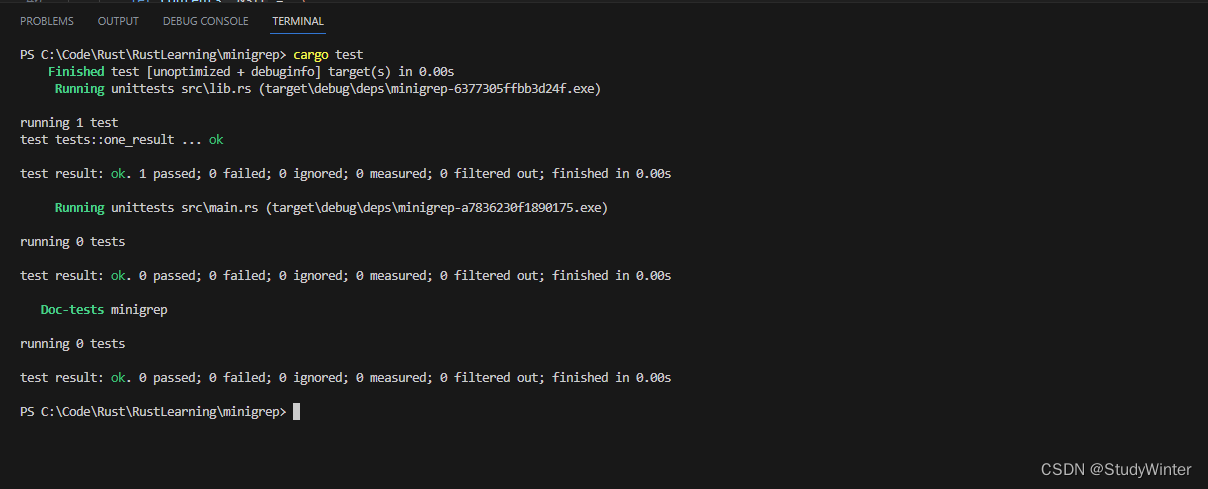
到此为止,我们可以考虑一下重构 search 的实现并时刻保持测试通过来保持其功能不变的机会了。search 函数中的代码并不坏,不过并没有利用迭代器的一些实用功能。
在run函数中使用search函数
现在 search 函数是可以工作并测试通过了的,我们需要实际在 run 函数中调用 search。需要将 config.query 值和 run 从文件中读取的 contents 传递给 search 函数。接着 run 会打印出 search 返回的每一行:
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {let contents = fs::read_to_string(config.filename)?;for line in search(&config.query, &contents) {println!("{}", line);}Ok(())
}
这里仍然使用了 for 循环获取了 search 返回的每一行并打印出来。
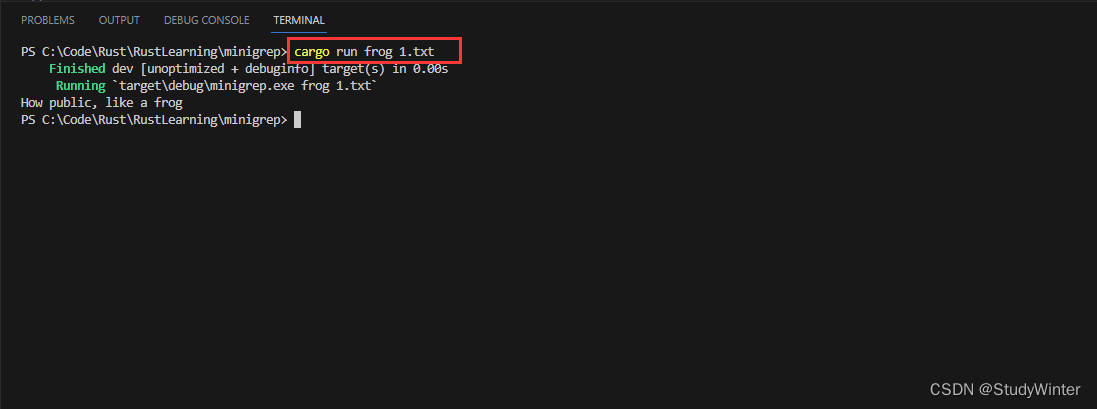
OK了
13.5 处理环境变量
将增加一个额外的功能来改进 minigrep:用户可以通过设置环境变量来设置搜索是否是大小写敏感的 。当然,我们也可以将其设计为一个命令行参数并要求用户每次需要时都加上它,不过在这里我们将使用环境变量。这允许用户设置环境变量一次之后在整个终端会话中所有的搜索都将是大小写不敏感的。
编写一个大小写不敏感search函数的失败测试
希望增加一个新函数 search_case_insensitive,并将会在设置了环境变量时调用它。这里将继续遵循 TDD 过程,其第一步是再次编写一个失败测试。我们将为新的大小写不敏感搜索函数新增一个测试函数,并将老的测试函数从 one_result 改名为 case_sensitive 来更清楚的表明这两个测试的区别
文件名: src/lib.rs
#[cfg(test)]
mod tests {use super::*;#[test]fn case_sensitive() {let query = "duct";let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";assert_eq!(vec!["safe, fast, productive."],search(query, contents));}// 这里是新加的#[test]fn case_insensitive() {let query = "rUsT";let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";assert_eq!(vec!["Rust:", "Trust me."],search_case_insensitive(query, contents));}
}
注意我们也改变了老测试中 contents 的值。还新增了一个含有文本 "Duct tape." 的行,它有一个大写的 D,这在大小写敏感搜索时不应该匹配 "duct"。我们修改这个测试以确保不会意外破坏已经实现的大小写敏感搜索功能;这个测试现在应该能通过并在处理大小写不敏感搜索时应该能一直通过。
大小写 不敏感 搜索的新测试使用 "rUsT" 作为其查询字符串。在我们将要增加的 search_case_insensitive 函数中,"rUsT" 查询应该包含带有一个大写 R 的 "Rust:" 还有 "Trust me." 这两行,即便他们与查询的大小写都不同。这个测试现在会编译失败因为还没有定义 search_case_insensitive 函数。
实现search_case_insensitive函数
search_case_insensitive 函数,将与 search 函数基本相同。唯一的区别是它会将 query 变量和每一 line 都变为小写,这样不管输入参数是大写还是小写,在检查该行是否包含查询字符串时都会是小写。
pub fn search_case_insensitive<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {let query = query.to_lowercase();let mut results = Vec::new();for line in contents.lines() {if line.to_lowercase().contains(&query) {results.push(line);}}results
}首先我们将 query 字符串转换为小写,并将其覆盖到同名的变量中。对查询字符串调用 to_lowercase 是必需的,这样不管用户的查询是 "rust"、"RUST"、"Rust" 或者 "rUsT",我们都将其当作 "rust" 处理并对大小写不敏感。
注意 query 现在是一个 String 而不是字符串 slice,因为调用 to_lowercase 是在创建新数据,而不是引用现有数据。如果查询字符串是 "rUsT",这个字符串 slice 并不包含可供我们使用的小写的 u 或 t,所以必需分配一个包含 "rust" 的新 String。现在当我们将 query 作为一个参数传递给 contains 方法时,需要增加一个 & 因为 contains 的签名被定义为获取一个字符串 slice。
接下来在检查每个 line 是否包含 search 之前增加了一个 to_lowercase 调用将他们都变为小写。现在我们将 line 和 query 都转换成了小写,这样就可以不管查询的大小写进行匹配了。
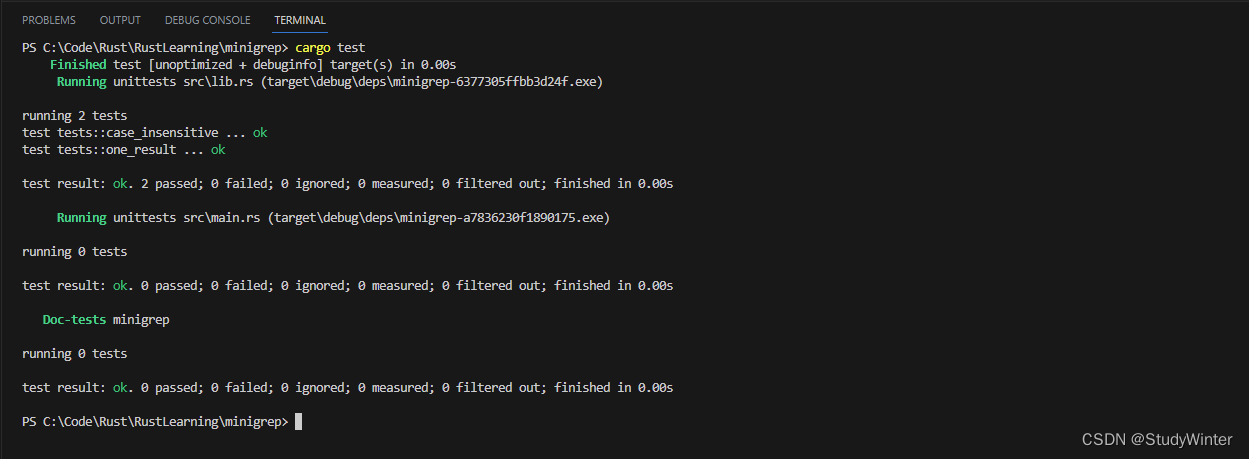
好的!现在,让我们在 run 函数中实际调用新 search_case_insensitive 函数。首先,我们将在 Config 结构体中增加一个配置项来切换大小写敏感和大小写不敏感搜索。增加这些字段会导致编译错误,因为我们还没有在任何地方初始化这些字段:
pub struct Config {pub query: String,pub filename: String,pub case_sensitive: bool,
}这里增加了 case_sensitive 字符来存放一个布尔值。接着我们需要 run 函数检查 case_sensitive 字段的值并使用它来决定是否调用 search 函数或 search_case_insensitive 函数,如示例所示。注意这还不能编译:
文件名: src/lib.rs
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {let contents = fs::read_to_string(config.filename)?;let results = if config.case_sensitive {search(&config.query, &contents)} else {search_case_insensitive(&config.query, &contents)};for line in results {println!("{}", line);}Ok(())
}
最后需要实际检查环境变量。处理环境变量的函数位于标准库的 env 模块中,所以我们需要在 src/lib.rs 的开头增加一个 use std::env; 行将这个模块引入作用域中。接着在 Config::new 中使用 env 模块的 var 方法来检查一个叫做 CASE_INSENSITIVE 的环境变量。文件名: src/lib.rs
use std::env;// --snip--impl Config {pub fn new(args: &[String]) -> Result<Config, &'static str> {if args.len() < 3 {return Err("not enough arguments");}let query = args[1].clone();let filename = args[2].clone();let case_sensitive = env::var("CASE_INSENSITIVE").is_err();Ok(Config { query, filename, case_sensitive })}
}这里创建了一个新变量 case_sensitive。为了设置它的值,需要调用 env::var 函数并传递我们需要寻找的环境变量名称,CASE_INSENSITIVE。env::var 返回一个 Result,它在环境变量被设置时返回包含其值的 Ok 成员,并在环境变量未被设置时返回 Err 成员。
我们使用 Result 的 is_err 方法来检查其是否是一个 error(也就是环境变量未被设置的情况),这也就意味着我们 需要 进行一个大小写敏感搜索。如果CASE_INSENSITIVE 环境变量被设置为任何值,is_err 会返回 false 并将进行大小写不敏感搜索。我们并不关心环境变量所设置的 值,只关心它是否被设置了,所以检查 is_err 而不是 unwrap、expect 或任何我们已经见过的 Result 的方法。

看起来程序仍然能够工作!现在将 CASE_INSENSITIVE 设置为 1 并仍使用相同的查询 to。
如果你使用 PowerShell,则需要用两个命令来设置环境变量并运行程序:
$ $env:CASE_INSENSITIVE=1
$ cargo run to poem.txt
13.6 将错误信息输出到标准错误而不是标准输出
检查错误应该写入何处
首先,让我们观察一下目前 minigrep 打印的所有内容是如何被写入标准输出的,包括那些应该被写入标准错误的错误信息。可以通过将标准输出流重定向到一个文件同时有意产生一个错误来做到这一点。我们没有重定向标准错误流,所以任何发送到标准错误的内容将会继续显示在屏幕上。
命令行程序被期望将错误信息发送到标准错误流,这样即便选择将标准输出流重定向到文件中时仍然能看到错误信息。目前我们的程序并不符合期望;相反我们将看到它将错误信息输出保存到了文件中。
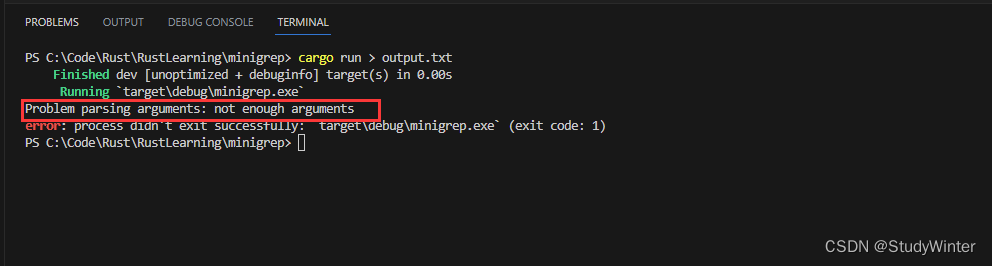
我们通过 > 和文件名 output.txt 来运行程序,我们期望重定向标准输出流到该文件中。在这里,我们没有传递任何参数,所以会产生一个错误:
$ cargo run > output.txt
结果

将错误打印到标准错误
标准库提供了 eprintln! 宏来打印到标准错误流,所以将两个调用 println! 打印错误信息的位置替换为 eprintln!:
fn main() {let args: Vec<String> = env::args().collect();let config = Config::new(&args).unwrap_or_else(|err| {eprintln!("Problem parsing arguments: {}", err);process::exit(1);});if let Err(e) = minigrep::run(config) {eprintln!("Application error: {}", e);process::exit(1);}
}
再次尝试用同样的方式运行程序,不使用任何参数并通过 > 重定向标准输出:
现在我们看到了屏幕上的错误信息,同时 output.txt 里什么也没有,这正是命令行程序所期望的行为。
如果使用不会造成错误的参数再次运行程序,不过仍然将标准输出重定向到一个文件,像这样:
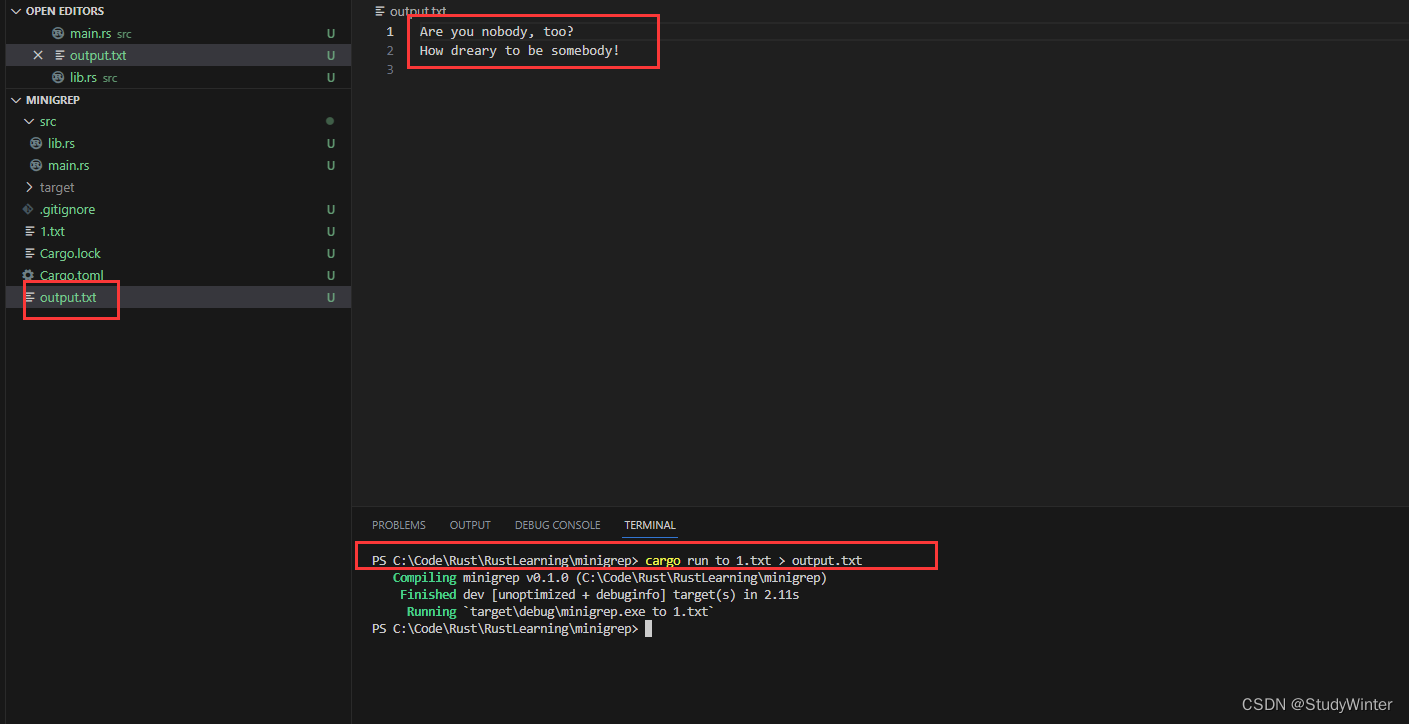
$ cargo run to poem.txt > output.txt
我们并不会在终端看到任何输出,同时 output.txt 将会包含其结果:
文件名: output.txt
Are you nobody, too?
How dreary to be somebody!结果
参考:一个 I/O 项目:构建命令行程序 - Rust 程序设计语言 简体中文版 (bootcss.com)