前言:Hello大家好,我是小哥谈。注意力机制是近年来深度学习领域内的研究热点,可以帮助模型更好地关注重要的特征,从而提高模型的性能。注意力机制可被应用于模型的不同层级,以便更好地捕捉图像中的细节和特征,这种模型在计算资源有限的情况下,可以实现更好的性能和效率。本文就给大家讲解如何在YOLOv5模型中添加SE注意力机制。🌈
![]() 前期回顾:
前期回顾:
YOLOv5算法改进(1)— 如何去改进YOLOv5算法
目录
🚀1.什么是注意力机制?
🚀2.SE注意力机制原理
💥💥2.1 方法介绍
💥💥2.2 网络结构
🚀3.添加SE注意力机制的方法
💥💥步骤1:在common.py中添加SE模块
💥💥步骤2:在yolo.py文件中加入类名
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:修改yolov5s_SE.yaml文件
💥💥步骤5:验证是否加入成功
💥💥步骤6:修改train.py中的'--cfg'默认参数

🚀1.什么是注意力机制?
注意力机制(Attention Mechanism)源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息。上述机制通常被称为注意力机制。人类视网膜不同的部位具有不同程度的信息处理能力,即敏锐度(Acuity),只有视网膜中央凹部位具有最强的敏锐度。为了合理利用有限的视觉信息处理资源,人类需要选择视觉区域中的特定部分,然后集中关注它。例如,人们在阅读时,通常只有少量要被读取的词会被关注和处理。🌴
综上,注意力机制主要有两个方面:决定需要关注输入的哪部分;分配有限的信息处理资源给重要的部分。📚
作用:♨️♨️♨️
- 提高模型的准确性:注意力机制可以帮助模型更好地关注重要的信息,从而提高模型的准确性。
- 模型解释性更强:注意力机制可以让模型更好地解释其决策过程,从而提高模型的可解释性。
- 可以处理不定长的序列数据:注意力机制可以处理不定长的序列数据,比如文本数据、语音数据等。
不足:♨️♨️♨️
- 计算量大:注意力机制需要计算每个位置的权重,因此计算量较大,训练时间较长。
- 可能出现过拟合:如果注意力机制的权重过于复杂,可能会导致过拟合的问题。
- 可能需要更多的数据:注意力机制需要更多的数据来训练和优化,否则可能会出现欠拟合的问题。
🚀2.SE注意力机制原理
💥💥2.1 方法介绍
SENet是由Momenta和牛津大学的胡杰等人提出的一种新的网络结构,目标是通过显式的建模卷积特征通道之间的相互依赖关系来提高网络的表示能力。在2017年最后一届 ImageNet 比赛classification任务上获得第一名。SENet网络的创新点在于关注channel之间的关系,希望模型可以自动学习到不同channel特征的重要程度。为此,SENet提出了Squeeze-and-Excitation (SE)模块。🌴
SE模块首先对卷积得到的特征图进行Squeeze操作,得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,也得到不同channel的权重,最后乘以原来的特征图得到最终特征。本质上,SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。另外一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中。🌻
优点:
可以通过学习自适应的通道权重,使得模型更加关注有用的通道信息。
缺点:
只考虑了通道维度上的注意力,无法捕捉空间维度上的注意力,适用于通道数较多的场景,但对于通道数较少的情况可能不如其他注意力机制。
说明:♨️♨️♨️
论文地址:Squeeze-and-Excitation Networks
代码地址:GitHub - hujie-frank/SENet: Squeeze-and-Excitation Networks
💥💥2.2 网络结构
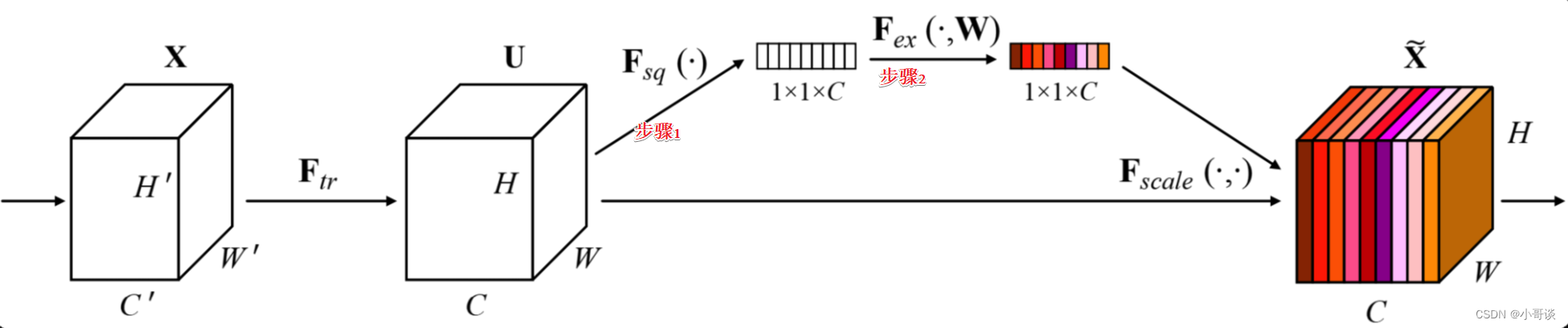
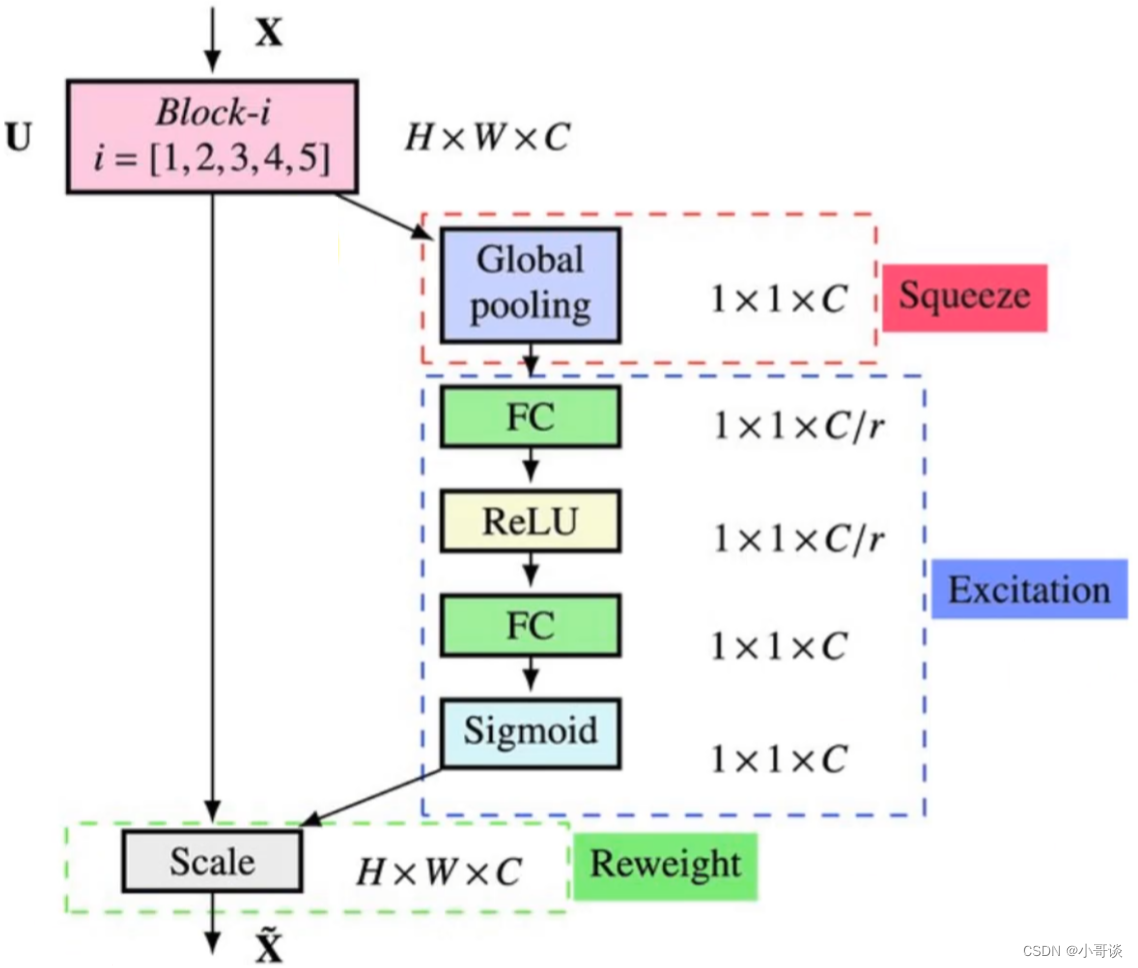
如下图所示,为SENet结构图。
步骤1:squeeze操作,将各通道的全局空间特征作为该通道的表示,形成一个通道描述符;
步骤2:excitation操作,学习对各通道的依赖程度,并根据依赖程度的不同对特征图进行调整,调整后的特征图就是SE block的输出。
🚀3.添加SE注意力机制的方法
💥💥步骤1:在common.py中添加SE模块
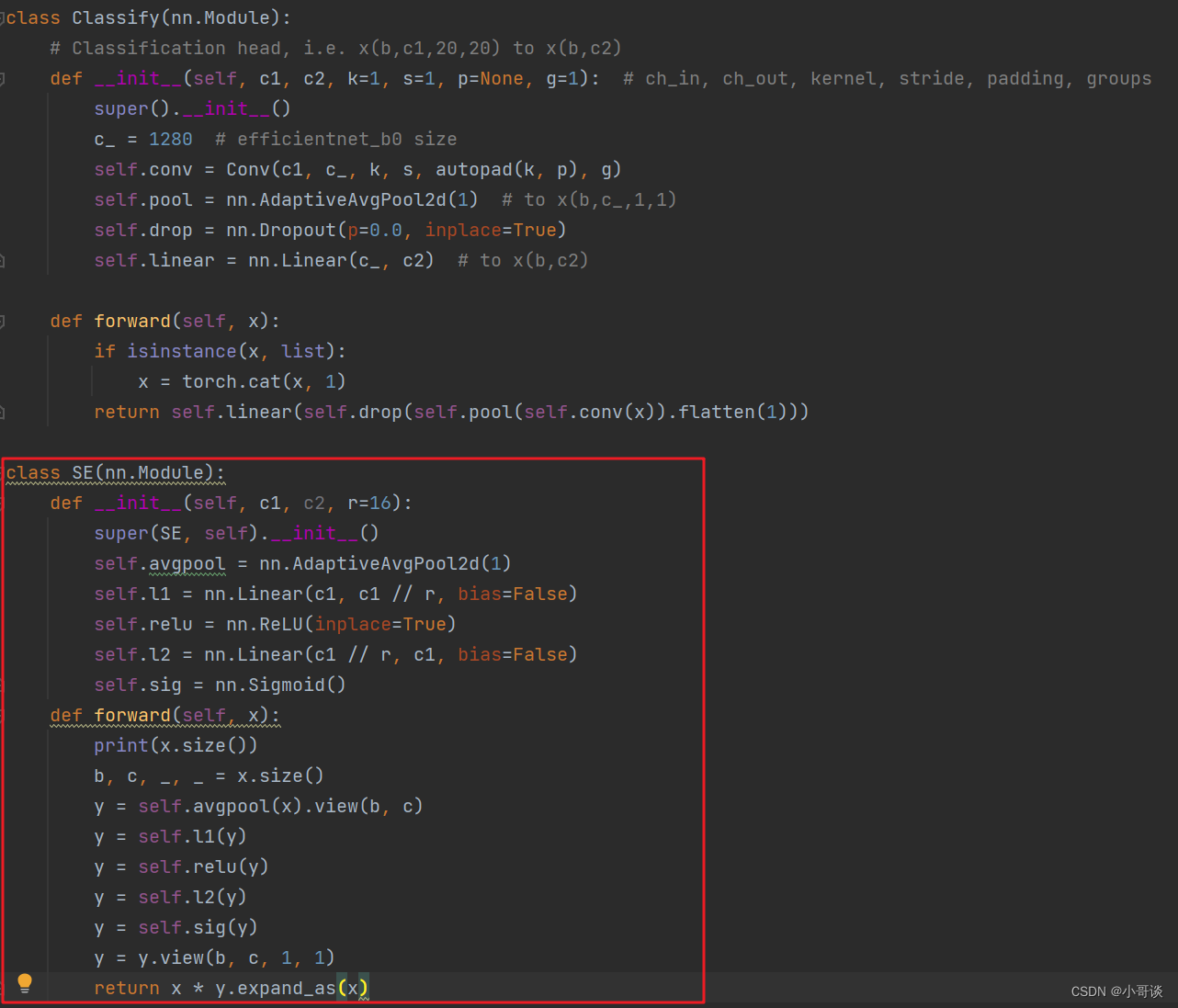
将下面的SE模块的代码复制粘贴到common.py文件的末尾。
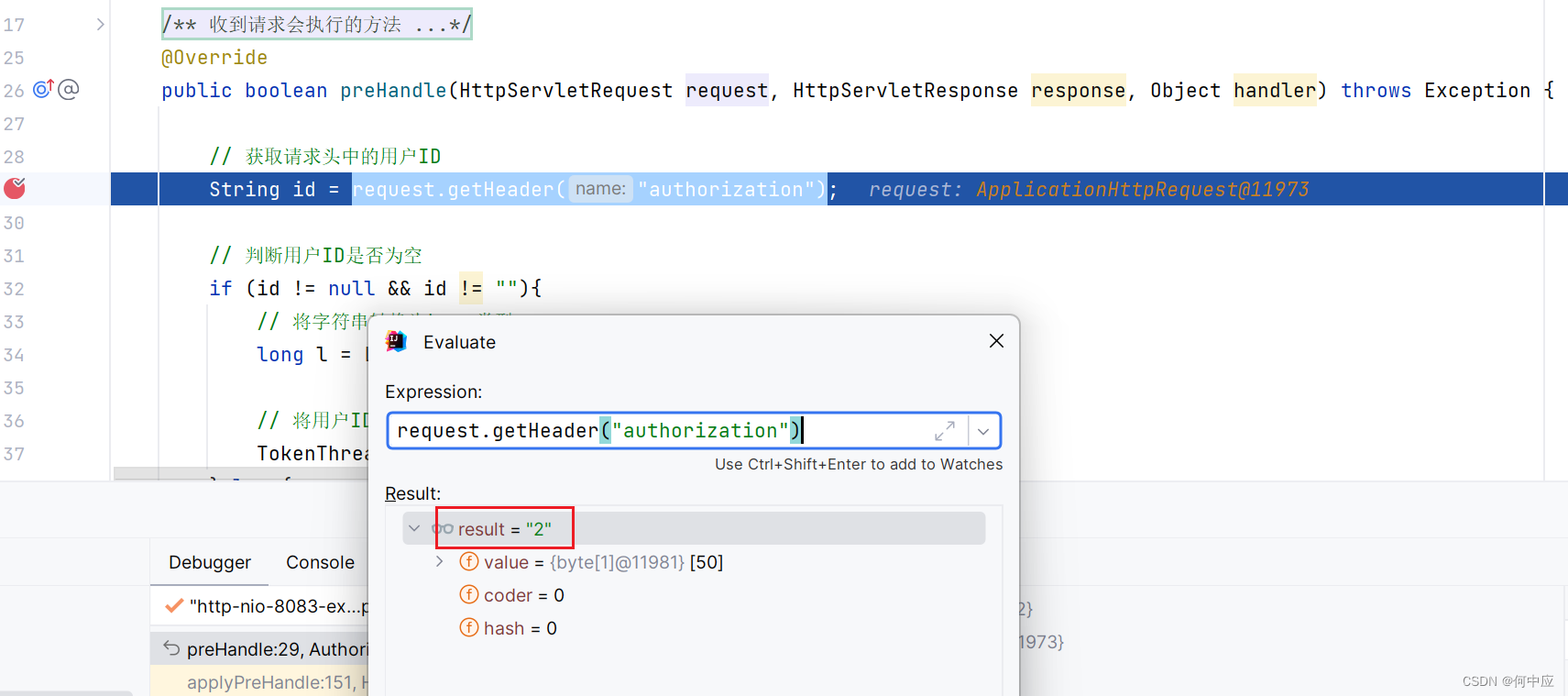
class SE(nn.Module):def __init__(self, c1, c2, r=16):super(SE, self).__init__()self.avgpool = nn.AdaptiveAvgPool2d(1)self.l1 = nn.Linear(c1, c1 // r, bias=False)self.relu = nn.ReLU(inplace=True)self.l2 = nn.Linear(c1 // r, c1, bias=False)self.sig = nn.Sigmoid()def forward(self, x):print(x.size())b, c, _, _ = x.size()y = self.avgpool(x).view(b, c)y = self.l1(y)y = self.relu(y)y = self.l2(y)y = self.sig(y)y = y.view(b, c, 1, 1)return x * y.expand_as(x)复制粘贴后,如下图所示:
💥💥步骤2:在yolo.py文件中加入类名
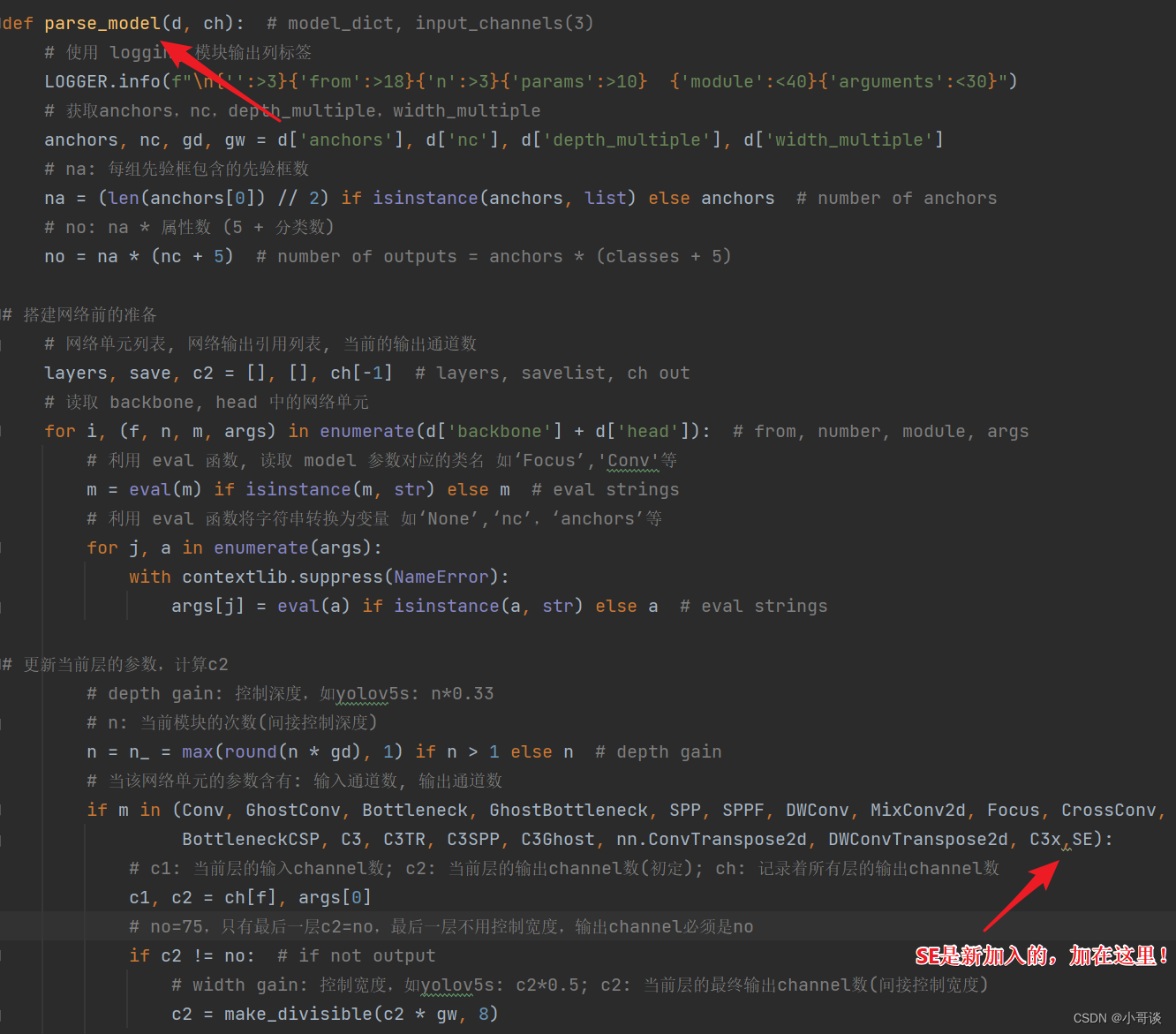
首先在yolo.py文件中找到parse_model函数,然后将SE添加到这个注册表里。
💥💥步骤3:创建自定义yaml文件
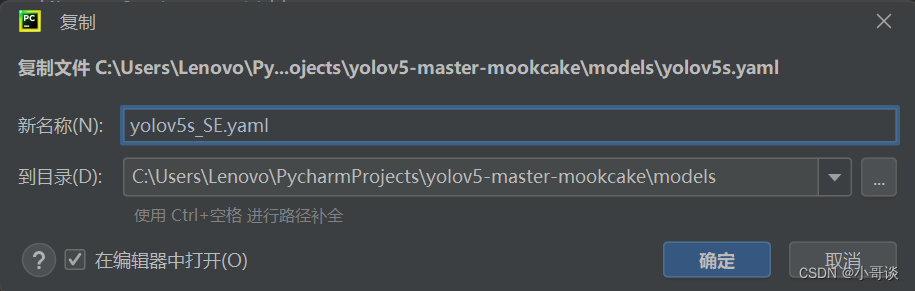
在models文件夹中复制yolov5s.yaml,粘贴并命名为yolov5s_SE.yaml。
💥💥步骤4:修改yolov5s_SE.yaml文件
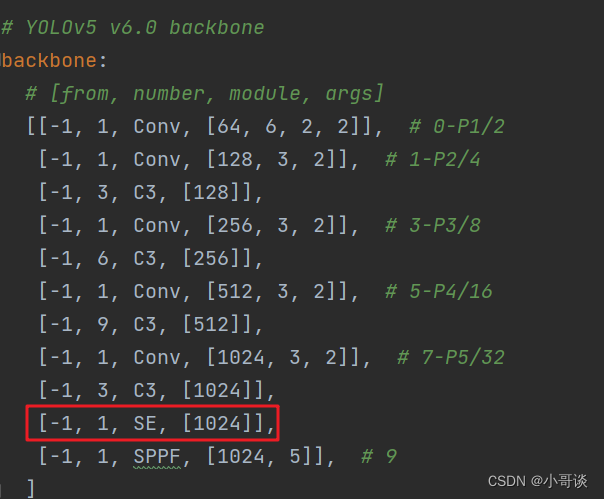
本步骤是修改yolov5s_SE.yaml,将SE添加到我们想添加的位置。在这里,我将[-1,1,SE,[1024]]添加到SPPF的上一层,即下图中所示位置。
说明:♨️♨️♨️
注意力机制可以加在Backbone、Neck、Head等部分,常见的有两种:一种是在主干的SPPF前面添加一层;二是将Backbone中的C3全部替换。不同的位置效果可能不同,需要我们去反复测试。
这里需要注意一个问题,当在网络中添加新的层之后,那么该层网络后面的层的编号会发生变化。原本Detect指定的是[17,20,23]层,所以,我们在添加了SE模块之后,也要对这里进行修改,即原来的17层,变成18层,原来的20层,变成21层,原来的23层,变成24层;所以这里需要改为[18,21,24],具体如下图所示:
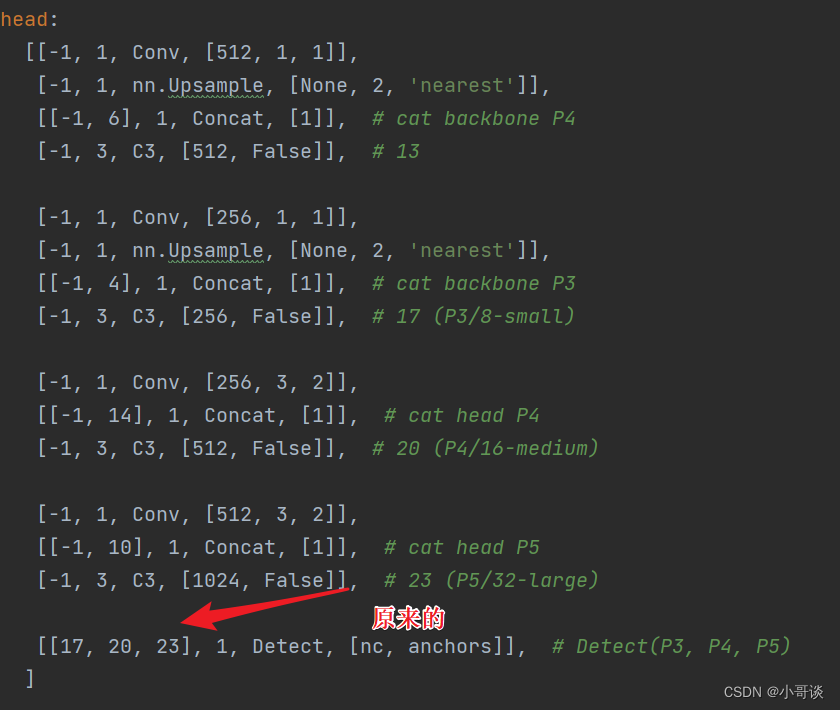
修改之后变为:
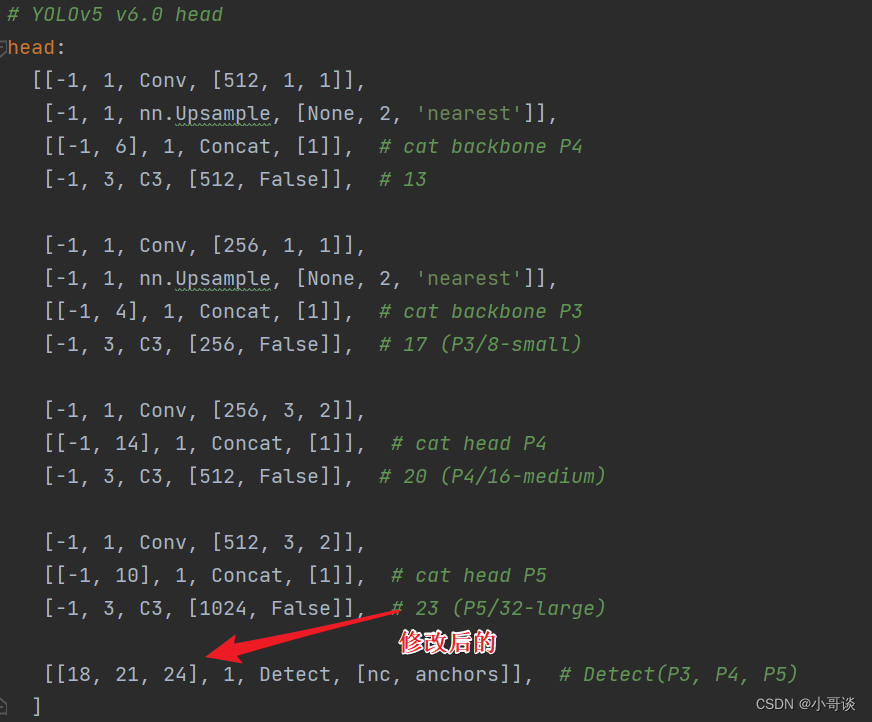
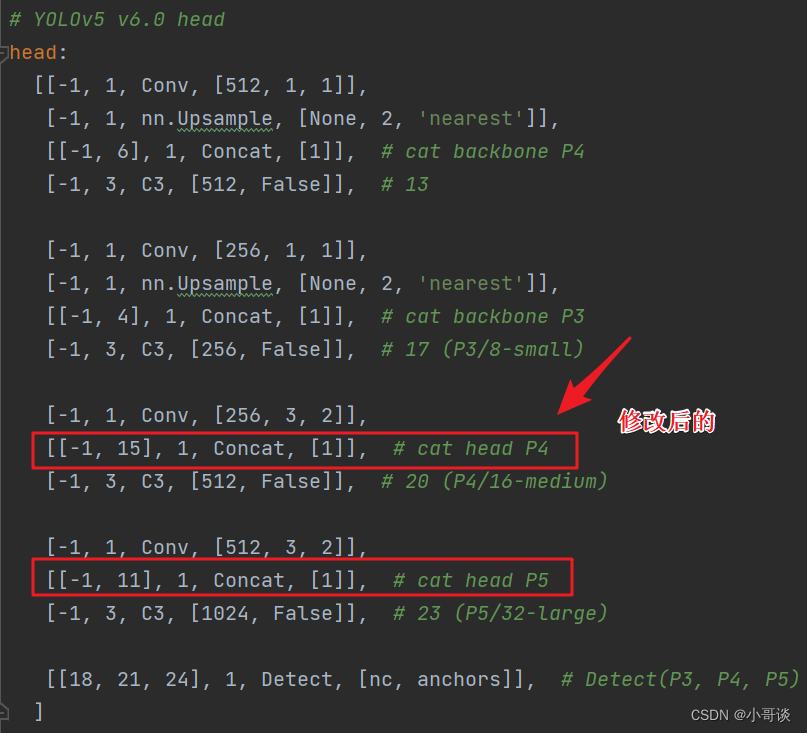
同样的,Concat的系数也要修改,这样才能保持原来的网络结构不会发生特别大的改变,我们刚才把SE加到了第9层,所以第9层之后的编号都需要加1,这里我们把后面两个Concat的系数分别由[-1,14],[-1,10]改为[-1,15],[-1,11]。具体如下图所示。
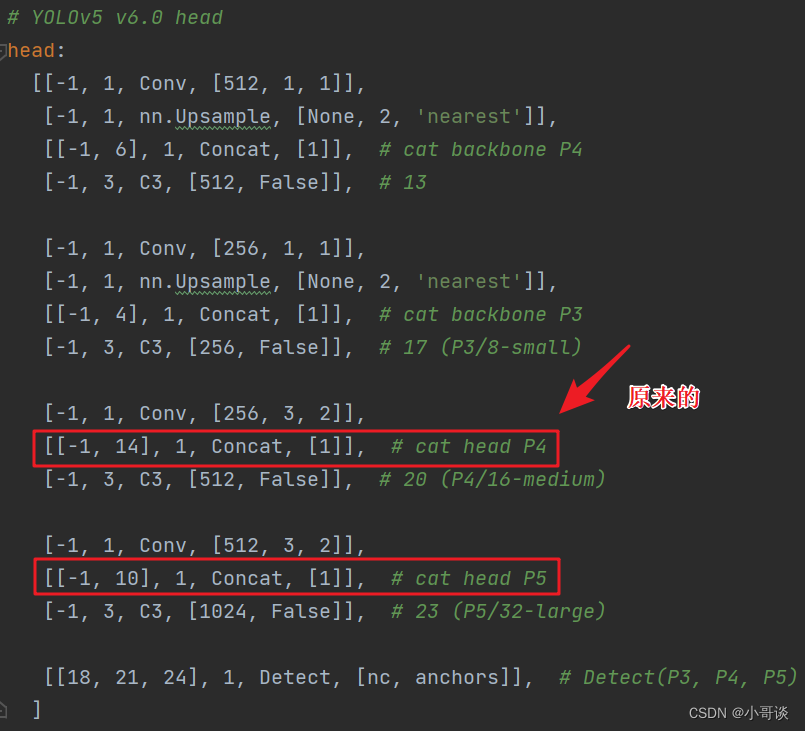
修改后即变为:
💥💥步骤5:验证是否加入成功
在yolo.py文件里,将配置改为我们刚才自定义的yolov5s_SE.yaml。
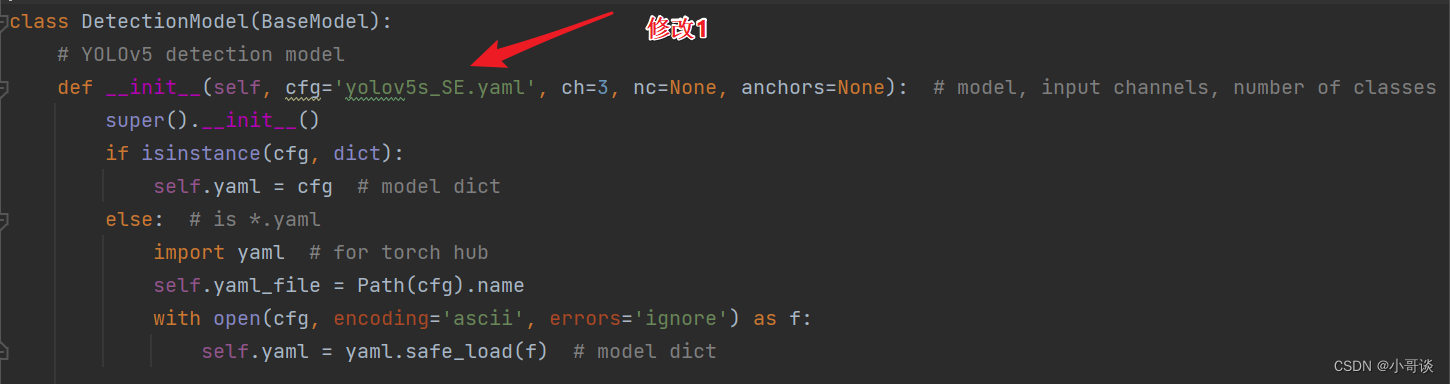
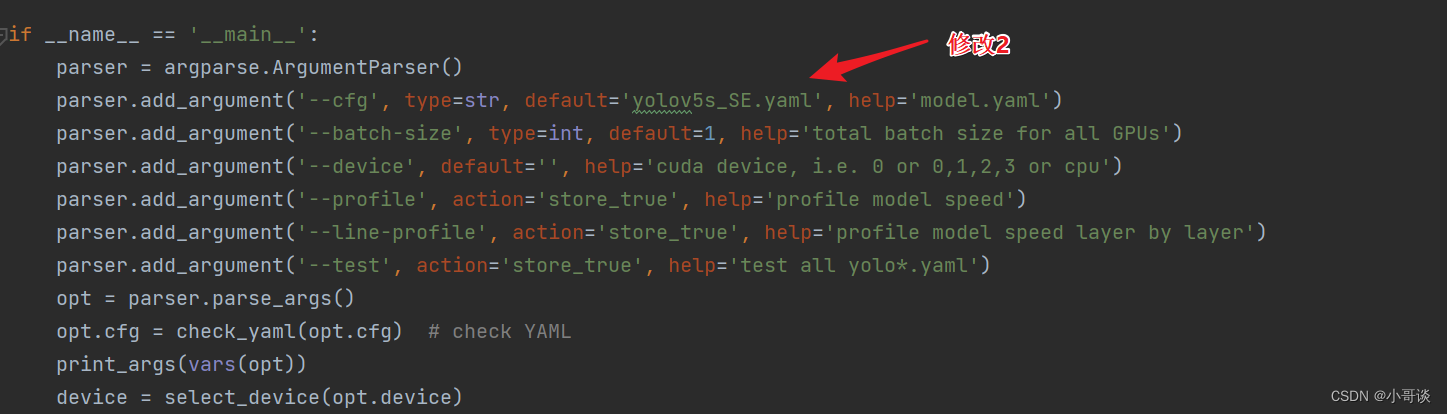
然后运行yolo.py,得到结果。
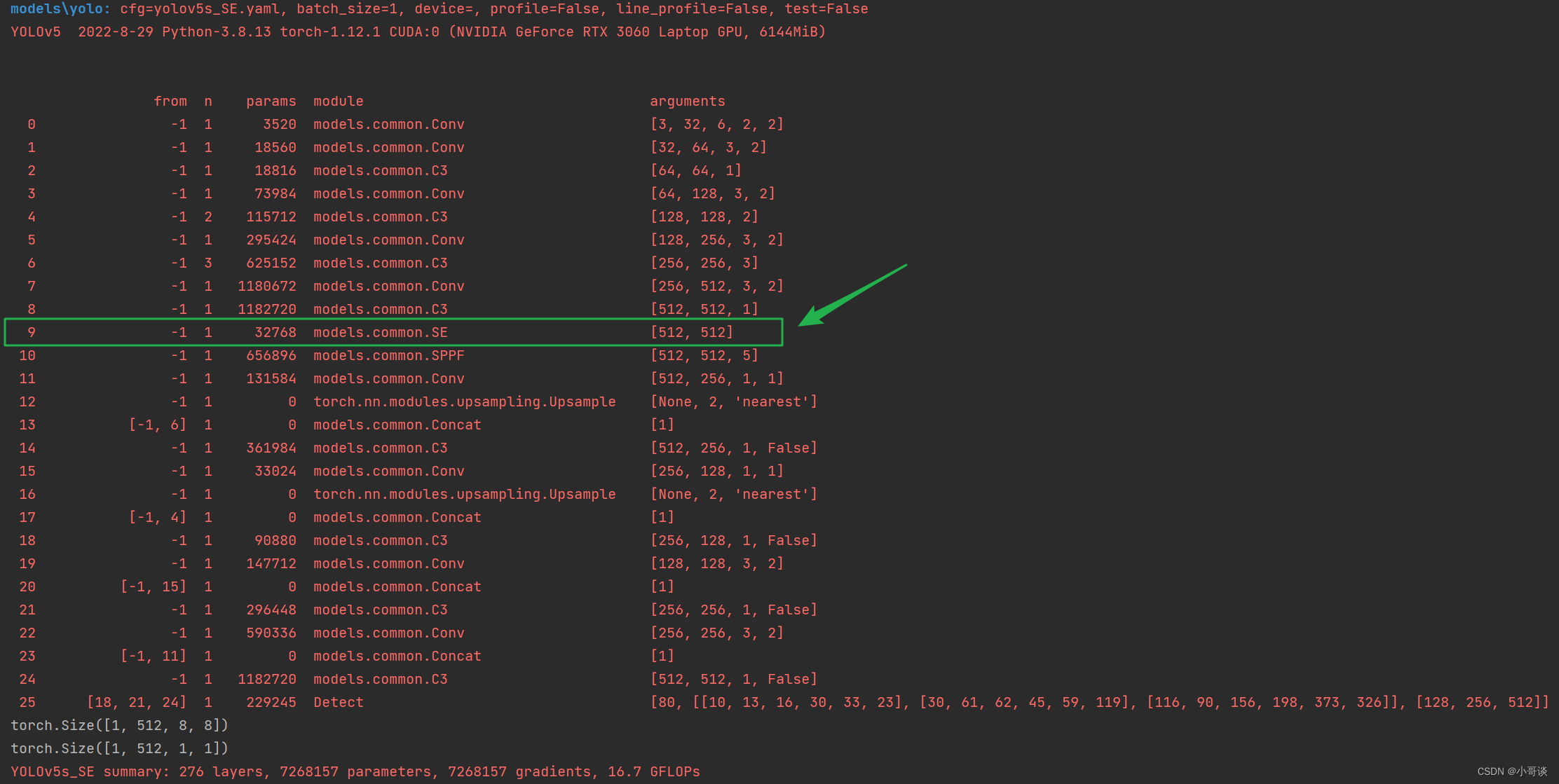
找到了SE模块,说明我们添加成功了。🎉🎉🎉
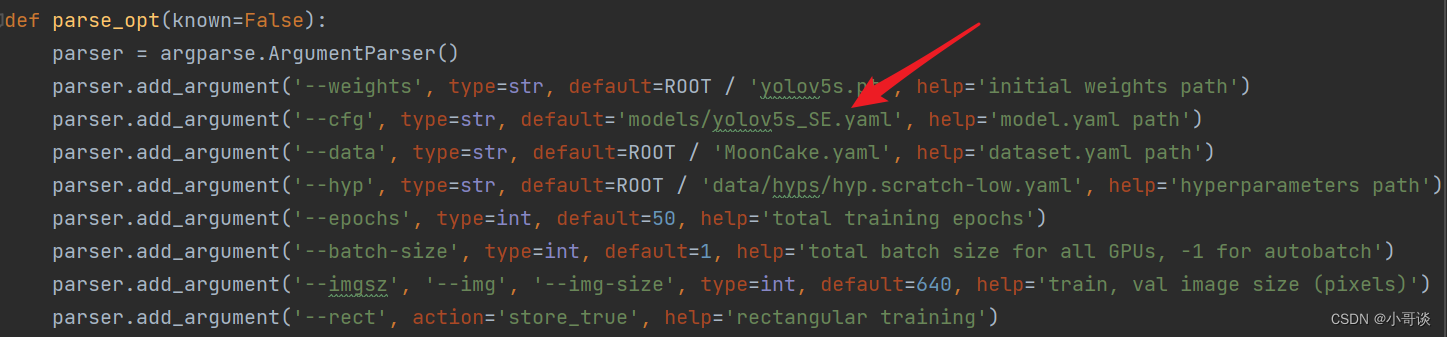
💥💥步骤6:修改train.py中的'--cfg'默认参数
在train.py文件中找到parse_opt函数,然后将第二行'--cfg'的default改为'models/yolov5s_SE.yaml',然后就可以开始进行训练了。🎈🎈🎈