传送门
Spring Cloud Alibaba系列之nacos:(1)安装
Spring Cloud Alibaba系列之nacos:(2)单机模式支持mysql
Spring Cloud Alibaba系列之nacos:(3)服务注册发现
Spring Cloud 系列之OpenFeign:(4)集成OpenFeign
Spring Cloud 系列之OpenFeign:(5)OpenFeign的高级用法
Spring Cloud 系列之OpenFeign:(6)OpenFeign的链路追踪
关于链路追踪
在前面一节Spring Cloud 系列之OpenFeign:(6)OpenFeign的链路追踪中,通过MDC实现了一个简易的链路追踪服务:
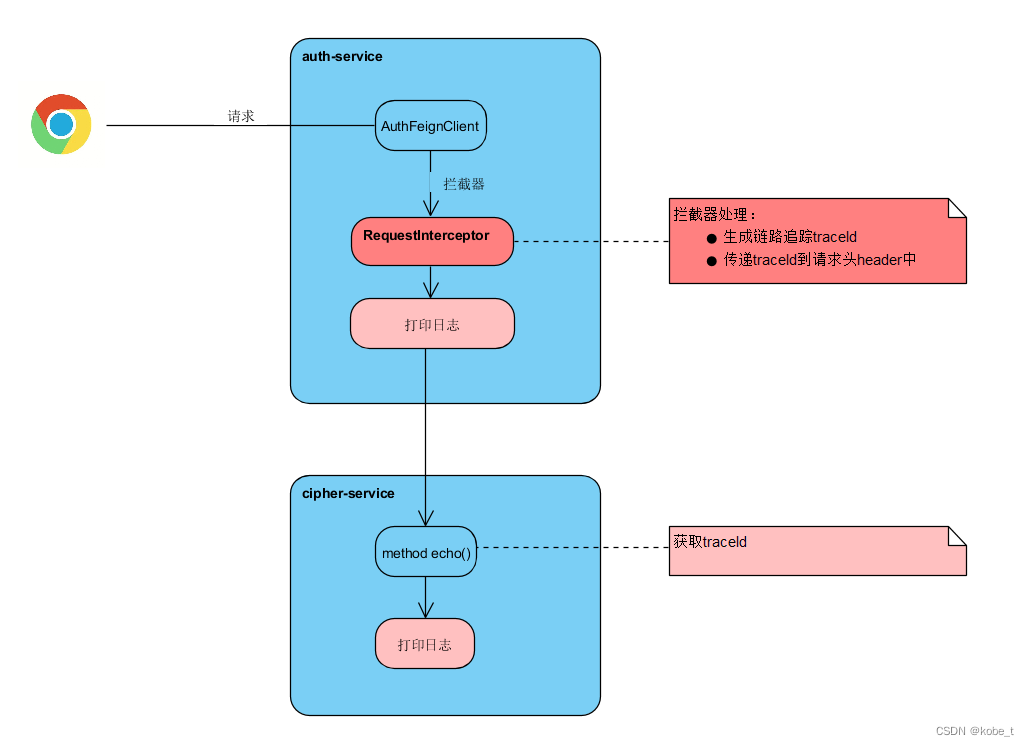
里面对于链接追踪没有过多的讨论,所以这里还是要先对它是什么,有什么作用,常用实现方式再做一次探讨!
为什么需要链路追踪
链路追踪这个名词也是17年初的时候才接触,当时入职一家做互联网金融的公司(以前都是在传统软件公司做企业级金融系统开发)。公司据说不久前融资了一笔钱,招兵买马准备大干一场。那时候公司在推行微服务,框架就是Spring Cloud套件,也就接触了zipkin这个概念,当时很经过一番名词轰炸,还是带来了不小的震撼:微服务,Springboot,注册中心Eureka,配置中心Config,网关Zuul,断路器,负载Ribbon,以及链路追踪的Sleuth(Springboot3已经被Micrometer Tracing项目取代)甚至是JAVA8的Lambda,还入手了一本翟永超的《Spring Cloud微服务实战》。
被名词轰炸的一个背后原因是在开发toB系统的那些年,系统基本都是单体的,所有的功能都在一个项目代码里面,包括前端/后端(那时候也不流行前后端分离):
- 银行/机构的大部分管理系统(甚至核心系统)都是内网专线,即所谓的私部署,不像toC这样面对互联网开放
- toB的系统并发虽然业务相对复杂,但并发不高,对分布式没有强烈的需求
- 最后一点,不一味追求新技术,稳定成熟才是首要考虑需求
在单体系统时代出了问题或者要排查问题,基本在本系统排查就够了,一般不超出关联上下游2-3个系统:
- 查询本系统的相关日志即可,排查比较方便,内容项也不多:应用日志/数据库
- 或者人肉联系上下游系统相关负责人去查下,范围也不扩大
但是在分布式系统架构下,这个方式就有点困难了:
- 随着系统的调用链路变长依赖系统增多,查询日志就显得不那么容易了:几个十几个系统要逐个排查日志,可能每个系统的日志规范还不一样,中间要是哪个漏了还查不出来,难以定位
- 微服务架构下,多半组织架构也不一样了:会按照微服务来划分不同的开发团队,沟通成本几何增加,要是每个问题都人肉拉群处理,那很快就大家不用干活了
所以分布式系统架构对于统一的服务调用请求追踪就显示很有必要了:一个链路追踪需要达到至少2方面的要求:
- 从调用过程角度看:从客户端发起请求开始,记录请求流经的每一个服务,直到向客户端返回响应为止
- 从记录过程角度看:能够记录具体调用了哪些服务,以及调用的顺序、开始时点、执行时长等信息