阅读导航
- 前言
- 一、什么是调试器
- 二、详解 GDB - 调试器
- 1.使用前提
- 2.经常使用的命令
- 3.使用小技巧
- 三、项目自动化构建工具 - make/Makefile
- 1. make命令
- ⭕语法
- ⭕常用选项
- ⭕常用操作
- ⭕make命令的工作原理
- ⭕make命令的优势:
- 2.Makefile文件
- ⭕Makefile的基本结构
- ⭕Makefile文件中常用的指令和语法
- ⭕Makefile的约定和惯例
- ⭕Makefile的工作原理
- 总结
- 温馨提示
前言
前面我们讲了C语言的基础知识,也了解了一些数据结构,并且讲了有关C++的一些知识,也学习了一些Linux的基本操作,也了解并学习了有关Linux开发工具vim 、gcc/g++ 使用、yum工具以及git 命令行提交代码也相信大家都掌握的不错,今天博主带大家了解一下 —— Linux系统下的调试器-gdb、项目自动化构建工具-make/Makefile, 下面话不多说坐稳扶好咱们要开车了!!!😍
一、什么是调试器
调试器是一种工具,用于帮助开发人员诊断和修复程序中的错误。它可以让你逐行执行代码,观察变量的值,并提供有关程序执行流程的详细信息。
✅一些常见的调试器包括:
- GDB(GNU调试器):适用于C和C++等编程语言,可在命令行界面下使用。
- LLDB(LLVM调试器):一款用于C、C++、Objective-C 和 Swift 的开源调试器,兼容多种平台。
- Visual Studio Debugger:适用于Windows平台的调试器,可与Microsoft Visual Studio集成使用。
- PyCharm Debugger:专为Python开发的调试器,可在PyCharm集成开发环境中使用。
- Xcode Debugger:适用于苹果开发者的调试器,可在Mac和iOS设备上调试应用程序。
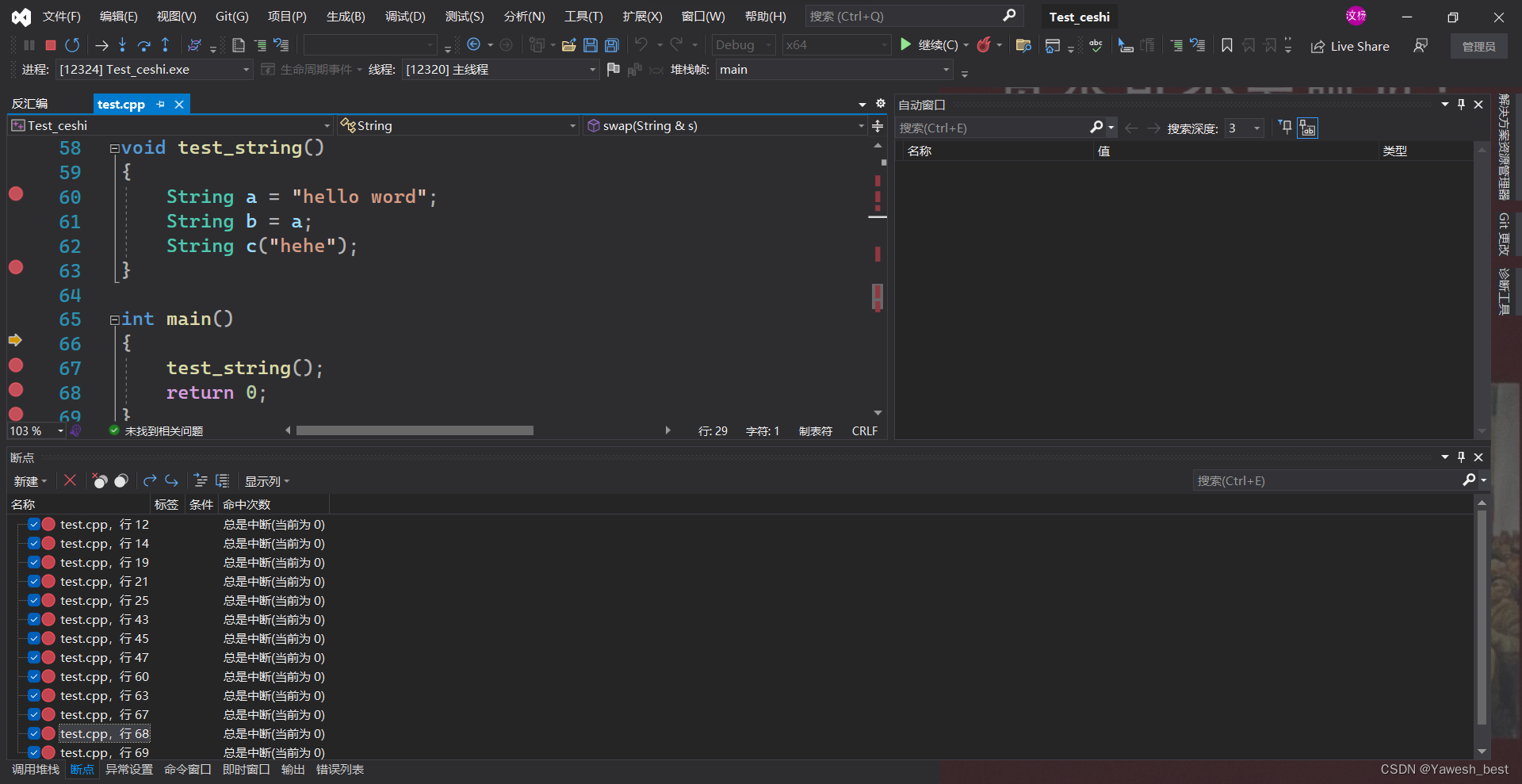
⭕VS下的调试环境
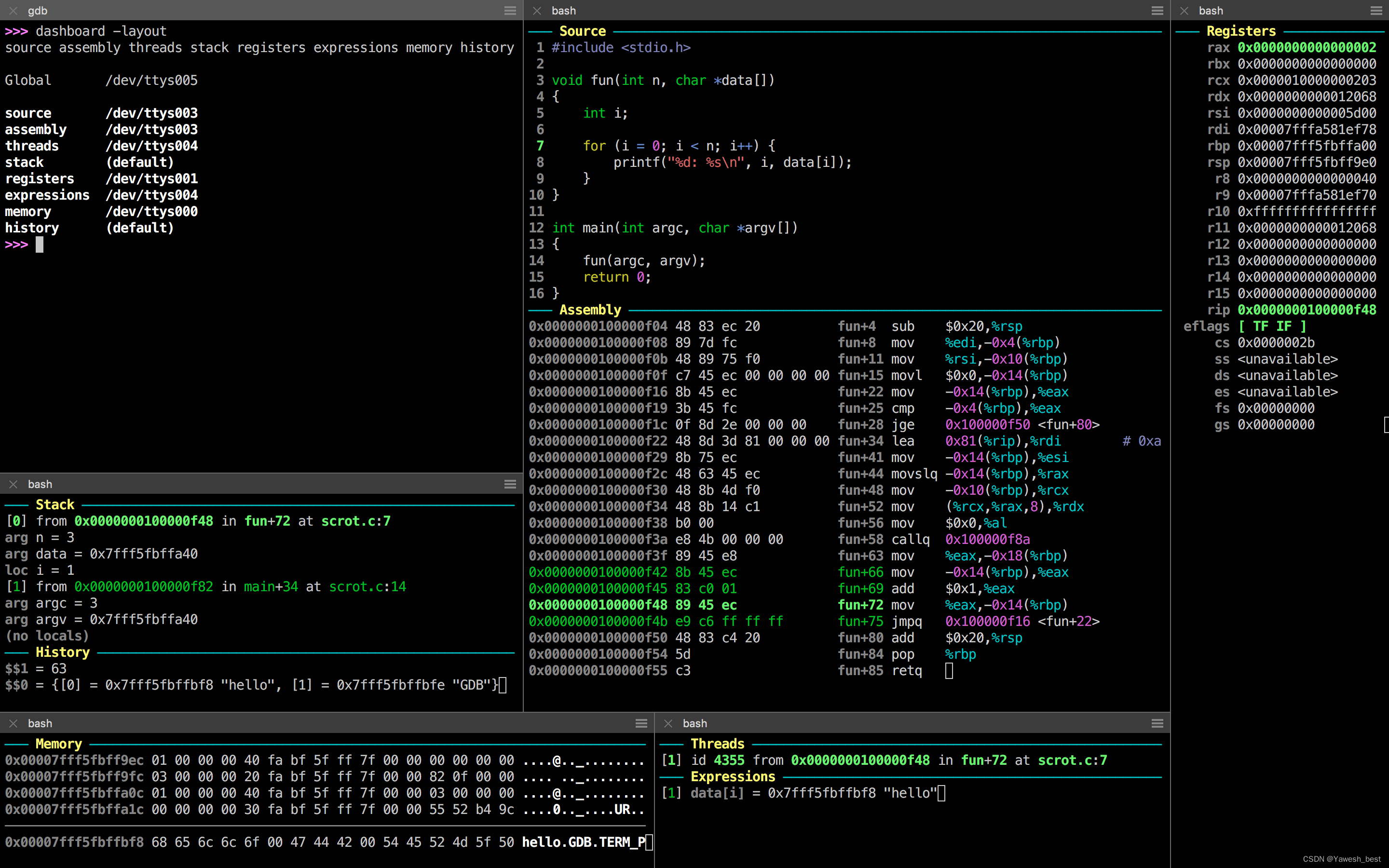
⭕GDB命令行模式的调试
✅调试器的一般使用步骤如下:
- 启动调试器,并将程序加载到调试器中。
- 设置断点,这样程序会在断点处暂停执行。
- 逐行执行代码,观察变量的值和程序的行为。
- 使用调试器提供的命令和功能来检查程序状态、查找错误并进行修复。
- 在逐步执行代码时,可以观察程序的执行流程和控制流的变化。
- 跟踪程序执行流程,查找潜在的逻辑错误和异常。
二、详解 GDB - 调试器
1.使用前提
在使用GDB调试器之前,你需要满足以下前提条件:
-
安装GDB:首先,你需要在你的计算机上安装GDB调试器。GDB是一个开源工具,可以从GNU项目的官方网站上下载并安装,也可以运行以下命令来安装GDB调试器:
sudo apt install gdb这将下载并安装GDB及其相关的依赖项。
-
编译可执行文件:GDB是用于调试可执行文件的工具,因此你需要先编译你的程序,并生成可执行文件。你可以使用适合你的编程语言的编译器来完成这个步骤。
-
了解编译选项:为了能够在GDB中正确地调试你的程序,你需要使用适当的编译选项来生成可调试的可执行文件。对于大多数编译器,你可以使用
-g选项来生成调试信息。例如,对于GCC编译器,你可以使用以下命令来编译带有调试信息的可执行文件:$ gcc -g your_program.c -o your_program这将生成一个名为
your_program的可执行文件,其中包含调试信息,可以在GDB中使用。
2.经常使用的命令
-
run:运行程序。 -
break:设置断点。例如,break main在程序的main函数处设置断点。 -
next:执行下一行代码。 -
step:进入函数调用并逐行执行函数内部的代码。 -
continue:继续执行程序,直到下一个断点或程序结束。 -
print:打印变量的值。例如,print x将打印变量x的值。 -
backtrace:查看调用栈,即程序执行到当前位置的函数调用序列。 -
set:修改变量的值。例如,set x = 10将把变量x的值设置为10。 -
watch:监视表达式的值。当表达式的值发生变化时,程序会暂停执行并显示相关信息。 -
info breakpoints:查看当前设置的断点信息。 -
delete:删除断点。例如,delete 1将删除编号为1的断点。 -
quit:退出GDB调试器。 -
info locals:查看当前函数的局部变量。 -
info registers:查看CPU寄存器的值。 -
display:设置自动显示变量的值。例如,display x将在每次程序暂停时显示变量x的值。 -
finish:执行当前函数的剩余部分,并返回到调用该函数的地方。 -
up:在调用栈中向上移动一帧,查看调用当前函数的上一层函数。 -
down:在调用栈中向下移动一帧,返回到当前函数调用的函数。 -
info threads:查看程序中的线程信息。 -
thread <thread-id>:切换到指定的线程。 -
set pagination off:关闭分页功能,以便在显示大量输出时不会暂停。 -
record:启用记录功能,可以回放程序的执行过程。 -
info functions:列出程序中定义的所有函数。 -
info sources:显示当前已加载的源文件列表。 -
run <arguments>:运行程序并传递命令行参数。 -
set args <arguments>:设置程序运行时的命令行参数。 -
set environment <variable=value>:设置程序运行时的环境变量。 -
display /f <format> <expression>:以指定的格式显示表达式的值。例如,display /x $eax以十六进制格式显示$eax寄存器的值。 -
info break:显示所有断点的信息,包括编号、位置和条件。 -
disable <breakpoint-number>:禁用指定编号的断点。 -
enable <breakpoint-number>:启用指定编号的断点。 -
catch <exception>:捕捉指定的异常,当发生该异常时程序会暂停。 -
watch <expression>:在表达式的值发生变化时暂停程序。 -
set logging on:打开日志记录功能,将GDB会话输出保存到日志文件中。
3.使用小技巧
⭕你可以只输入命令的首字母来执行GDB调试器命令。GDB支持命令的缩写,只要输入命令的唯一识别首字母即可。例如,你可以输入b代替break,n代替next,s代替step等。这样可以更快地输入命令并提高你的工作效率。然而,如果有多个命令以相同的首字母开头,GDB可能无法确定你要执行的是哪个命令,此时你需要输入更多的字符以区分命令。
⭕当你在GDB调试器中按下回车键时,它会执行上一条命令。这对于重复执行相同的命令非常方便,特别是当你需要多次执行相同的调试操作时。只需按下回车键即可重复执行上一条命令,无需重新输入。这可以提高你的工作效率并简化调试过程。
三、项目自动化构建工具 - make/Makefile
1. make命令
make是一个常用的构建工具,它在Linux系统中广泛使用。它的主要功能是根据指定的规则和依赖关系自动化构建和编译工程项目。
⭕语法
make命令的基本语法:
make [选项] [目标]
⭕常用选项
-f <文件>或--file=<文件>:指定使用的makefile文件,默认为Makefile。-C <目录>或--directory=<目录>:切换到指定的目录后执行make命令。-n或--just-print:仅打印出要执行的命令而不实际执行。-B或--always-make:无条件重新构建所有目标。-j <并行数>或--jobs=<并行数>:指定并行执行的任务数。
⭕常用操作
make:使用默认的makefile文件执行构建,默认构建第一个目标。make <目标>:指定构建的目标。make clean:清理构建产生的中间文件和目标文件。make install:安装构建生成的文件到系统目录。make distclean:执行完全清理,将构建的文件和中间文件都删除。
⭕make命令的工作原理
make命令会检查makefile文件,找到要构建的目标及其依赖关系。- 如果目标不存在或比其依赖项的修改时间要旧,则需要重新构建该目标。
- 根据
makefile文件中定义的规则和命令,执行构建操作。
⭕make命令的优势:
- 自动化构建:根据规则和依赖关系,只编译需要更新的文件,提高构建效率。
- 并行构建:使用
-j选项可以指定并行执行的任务数,加快构建速度。 - 依赖关系管理:通过定义依赖关系,确保被修改的文件及其相关文件被正确地重新构建。
2.Makefile文件
Makefile是一种用于构建和管理项目的配置文件,在Linux系统中广泛使用。它定义了项目中的目标、依赖关系以及构建命令等信息。
⭕Makefile的基本结构
一个典型的Makefile文件包含了一系列规则和命令,每个规则由以下几个部分组成:
<目标>: <依赖关系><命令1><命令2>...
<目标>:表示需要构建的文件或目标。它可以是一个可执行文件、库文件、中间文件等。Makefile中可以定义多个目标,每个目标对应一个规则。<依赖关系>:表示目标所依赖的文件或其他目标。当依赖关系中的文件被修改时,相关的目标需要被重新构建。<命令>:构建目标所执行的命令。可以是编译源代码、链接、复制文件等操作。
⭕Makefile文件中常用的指令和语法
$(变量名):使用变量。可以定义和使用变量来简化Makefile中的重复代码。=或:=:变量赋值。使用=表示简单赋值,使用:=表示延迟赋值(变量的值在首次使用时确定,之后不再改变)。#:注释符号,用于注释说明。@:静默模式。在命令前添加@符号,表示执行命令时不打印命令本身。if...endif:条件判断语句。根据条件判断是否执行命令。for...endfor:循环语句。可以遍历列表中的元素执行命令。
Makefile文件中常用的内置变量:
CC:C 编译器的名称。默认为cc。CFLAGS:C 编译器的选项。如-Wall表示打开所有警告。LDFLAGS:链接器的选项。如-lm表示链接数学库。CPPFLAGS:预处理器的选项。如-I添加头文件搜索路径。
⭕Makefile的约定和惯例
clean:一般会定义一个clean目标,用于清理生成的目标文件和中间文件。all:一般会定义一个all目标,用于构建项目的所有目标。.PHONY:声明一些伪目标,表示目标不对应任何实际的文件。常用于定义用于执行命令而非产生具体文件的目标。
⭕Makefile的工作原理
- 当执行
make命令时,它会读取当前目录下的Makefile文件。 Makefile文件中定义的依赖关系和构建规则会被解析,并根据修改时间和依赖关系确定需要重新构建的目标。- 根据规则执行构建命令,生成目标文件。
✅这里给出一个简单的例子来说明Makefile的使用。假设我们有一个 C 语言项目,包含两个源文件:main.c 和 helper.c,它们需要分别编译成目标文件,并链接为可执行文件。
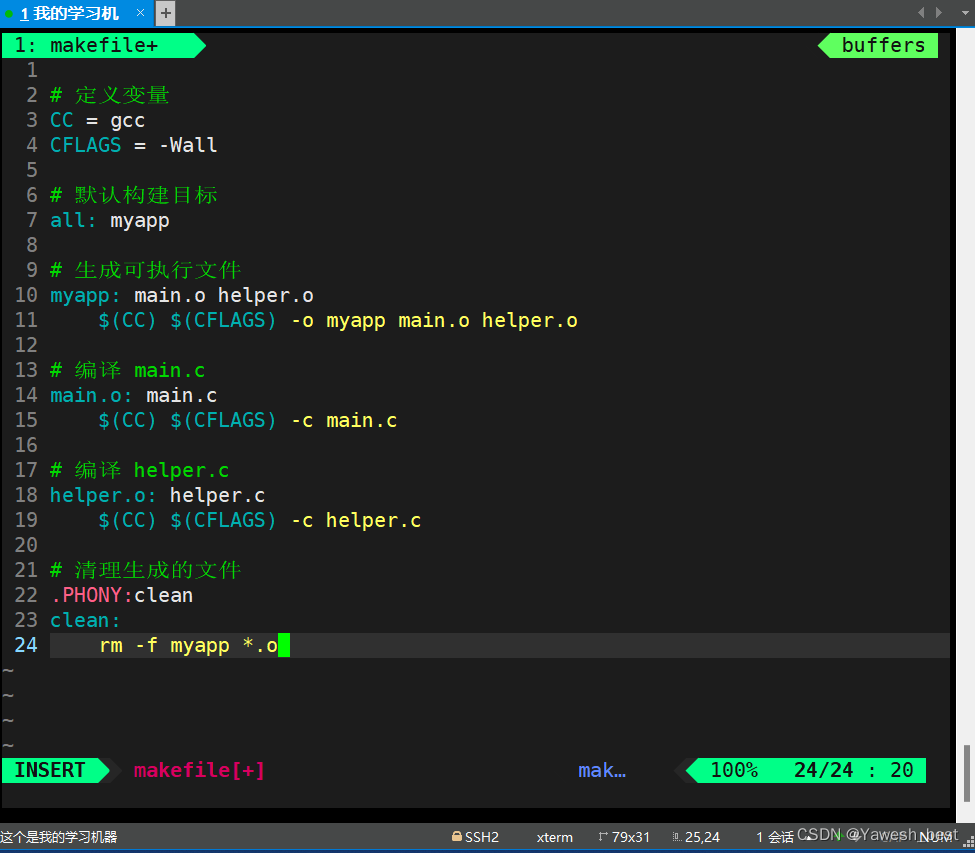
在这个例子中,我们首先定义了变量 CC 和 CFLAGS,分别表示使用的 C 编译器和编译器选项。
然后,我们定义了默认的构建目标 all,它依赖于目标文件 myapp。
myapp 目标表示生成可执行文件myapp,它依赖于对象文件 main.o 和 helper.o。该规则包含了链接命令,将这两个目标文件链接为可执行文件。
main.o 和 helper.o 目标分别表示编译 main.c 和 helper.c,它们都依赖于对应的源文件。这些规则包含了编译命令,将源文件编译为目标文件。
最后,我们定义了一个 clean 目标,用于清理生成的可执行文件和目标文件。
使用 make 命令执行这个 Makefile 文件时,它会自动根据依赖关系进行构建。例如,如果修改了 main.c,那么只会重新编译 main.o 和 myapp,而不需要重新编译 helper.o。
通过这样的 Makefile 文件,我们可以方便地构建和管理项目,简化了编译和链接操作。
总结
本文介绍了调试器和自动化构建工具的基本概念和使用方法。调试器是一种帮助程序员诊断和修复程序错误的工具,常用的调试器是GDB,它提供了设置断点、单步执行、查看变量值等功能。自动化构建工具是一种用于管理项目构建的工具,常用的工具是make,它通过makefile文件定义构建规则和依赖关系,可以自动化执行编译、链接等操作。通过使用调试器和自动化构建工具,程序员可以更高效地调试和构建项目,提高开发效率和代码质量。
温馨提示
感谢您对博主文章的关注与支持!在阅读本篇文章的同时,我们想提醒您留下您宝贵的意见和反馈。如果您喜欢这篇文章,可以点赞、评论和分享给您的同学,这将对我提供巨大的鼓励和支持。另外,我计划在未来的更新中持续探讨与本文相关的内容。我会为您带来更多关于Linux以及C++编程技术问题的深入解析、应用案例和趣味玩法等。请继续关注博主的更新,不要错过任何精彩内容!
再次感谢您的支持和关注。我们期待与您建立更紧密的互动,共同探索Linux、C++、算法和编程的奥秘。祝您生活愉快,排便顺畅!







![[保研/考研机试] KY43 全排列 北京大学复试上机题 C++实现](https://img-blog.csdnimg.cn/e247ca364de844d08aac166c17b3086b.png)

![[保研/考研机试] 杨辉三角形 西北工业大学复试上机题 C++实现](https://img-blog.csdnimg.cn/8bb3bd8896b44b76ba106363166112ab.png)