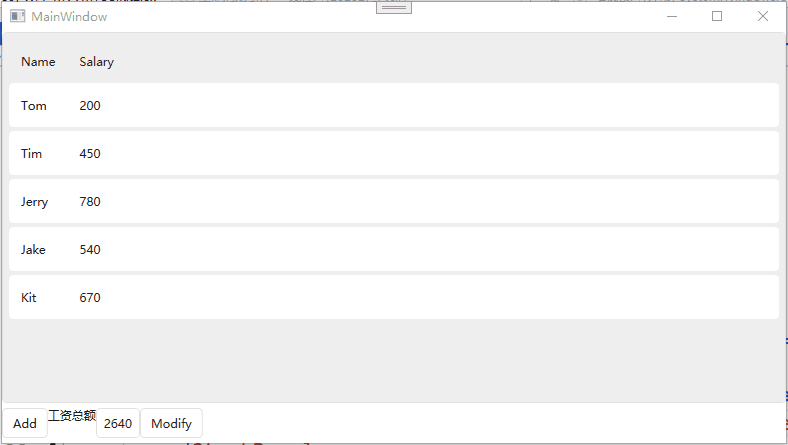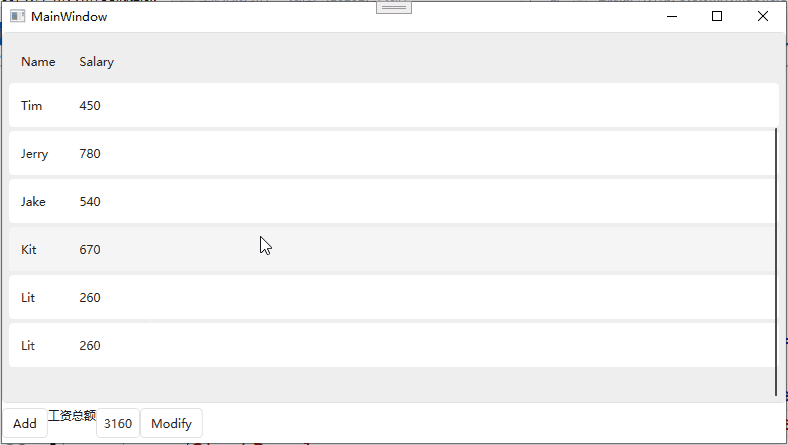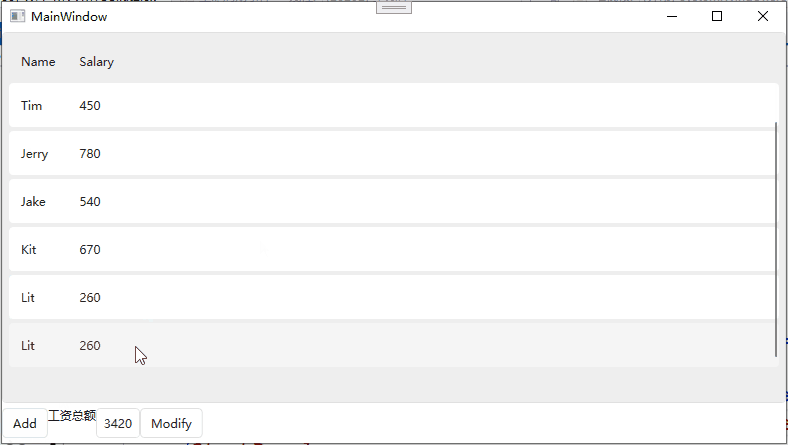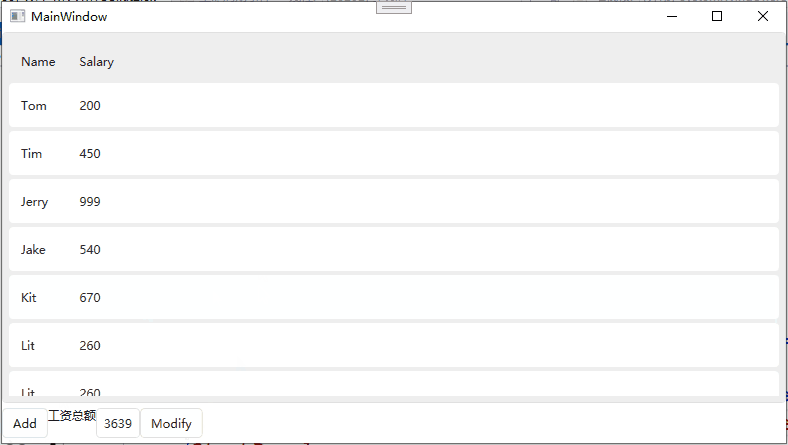
文本处理器:三剑客:grep查找sed awk
shell正则表达式由一类特殊字符以及文本字符所编写的一种模式,处理文本当中的内容,其中的一些字符不表示字符的字面含义表示一种控制或者通配的功能
通配符:匹配文件名和目录名,不能匹配文件的内容
正则表达式:命令结果,文本内容都可以进行匹配
通配符:
*匹配任意一个或者多个字符
?匹配任意一个字符
[] 匹配范围内任意单个字符[0-9]
正则表达式:
1、基本正则表达式
2、扩展正则表达式
区别仅限于写法上的区别,其他的没有任何区别
基本正则:
字符匹配,元字符
“.”匹配任意的单个字符,可以是一个汉字
\表示转义符 .就是一个点
()表示分组的意思 \(\)就是一个括号
[]匹配指定范围内的任意单个字符

[^]取反,指定范围之外的
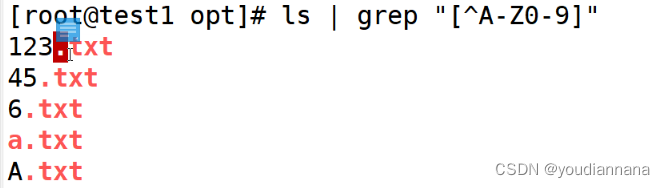
[[:space:]]包含空格,tab键也算,换行的空格,回车的空格
[[:blank:]]空白字符(空格和tab键(制表符))


通配符不能完全匹配大小写,真正的大小写,在正则表达式中
正则表达式中表示次数的表达式
*表示匹配前面的字符任意次,0次也行,无数次也行,有多少我匹配多少,没有也行,贪婪模式
.*匹配任意长度的字符,至少要有一次,不包括0次
\?匹配前面的字符0次或者一次,可有可无
\ +匹配前面的字符至{少一次,最多无数次

\ {n \ } #匹配前面的字符=n次 n次必须要连续出现 \ {m,n \ } #匹配前面的字符至少m次,至多n次 \ {,n \ } #匹配前面的字符至多n次,<=n 只要在范围内都算,除非没有 \ {n, \ } #匹配前面的字符至少n次





位置锚定:
^:以什么为开头,在模式的左侧
^r
$:以什么结尾,在模式的右侧
r$
^root$:用于匹配整行,而且整行中只有一个root
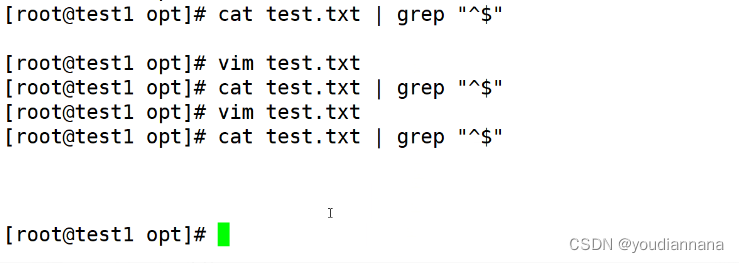
^$:匹配空行
词首锚定:<或者\b
词尾锚定:>或者\b
\b的位置

\ <root \ >匹配整个单词
分组:
()

\ | 表示逻辑或

扩展正则:
\全部去掉