Yellowbrick 是一个新的 Python 库,它扩展了 Scikit-Learn API,将可视化合并到机器学习工作流程中。
Yellowbrick需要依赖诸多第三方库,包括Scikit-Learn,Matplotlib,Numpy等等。
Yellowbrick 是一个开源的纯 Python 项目,它通过可视化分析和诊断工具扩展了 Scikit-Learn。Yellowbrick API 还包装了 matplotlib 以创建可发布的图形和交互式数据探索,同时仍然允许开发人员对图形进行细粒度控制。对于用户来说,Yellowbrick 可以帮助评估机器学习模型的性能、稳定性和预测价值,并协助诊断整个机器学习工作流程中的问题。
最近,大部分工作流程已通过网格搜索方法、标准化 API 和基于 GUI 的应用程序实现自动化。然而,在实践中,人类的直觉和指导可以比详尽的搜索更有效地磨练质量模型。通过可视化模型选择过程,数据科学家可以转向最终的、可解释的模型,并避免陷阱。
Yellowbrick 库是一个用于机器学习的诊断可视化平台,允许数据科学家引导模型选择过程。Yellowbrick 使用新的核心对象扩展了 Scikit-Learn API:可视化工具。可视化工具允许视觉模型作为 Scikit-Learn Pipeline 流程的一部分进行拟合和转换,从而在整个高维数据转换过程中提供视觉诊断。
机器学习可视化将帮助我们了解机器学习结果并知道应该采取哪些行动来改进模型。这就是 Yellowbrick 使命。
Yellowbrick让我们可以更轻松地完成下面任务:
1.选择功能
2.调整超参数
3.解释模型的得分
4.可视化文本数据
安装
要安装 Yellowbrick 库,最简单的方法是使用pip以下命令:
pip install yellowbrick使用Yellowbrick
Yellowbrick API 专门设计用于与 Scikit-Learn 完美配合。以下是 Scikit-Learn 和 Yellowbrick 的典型工作流程示例:
Yellowbrick的教程目录如下,参考网址:
https://pythonhosted.org/yellowbrick/examples/examples.html

下图是Yellowbrick的visualizer模块流程图
特征可视化
在此示例中,我们看到 Rank2D 如何使用特定指标或算法对数据集中的每个特征进行成对比较,然后以左下三角图的形式返回它们的排名:
from yellowbrick.features import Rank2Dvisualizer = Rank2D(features=features, algorithm='covariance')visualizer.fit(X, y) # Fit the data to the visualizervisualizer.transform(X) # Transform the datavisualizer.poof() # Draw/show/poof the data
拥有更多的功能并不总是等同于更好的模型。模型具有的特征越多,模型对方差引起的误差越敏感。因此,我们希望选择生成有效模型所需的最少特征。
消除特征的常见方法是消除对模型最不重要的特征。然后我们重新评估模型在交叉验证期间是否确实表现更好。
特征重要性非常适合此任务,因为它可以帮助我们可视化模型特征的相对重要性。
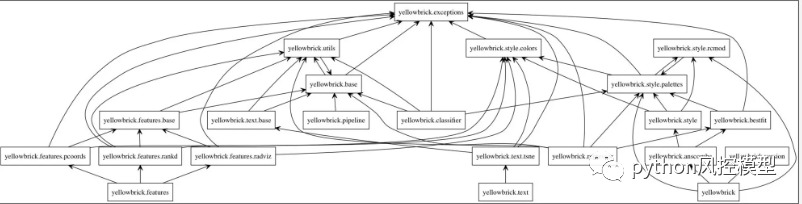
from yellowbrick.model_selection import FeatureImportancesviz = FeatureImportances(model)viz.fit(X, y)viz.show()
看来光是 DecisionTreeClassifier 最重要的特征,其次是 CO2、温度。
考虑到我们的数据中没有太多特征,我们不会消除湿度。但如果我们的模型中有很多特征,我们应该消除对模型不重要的特征,以防止由于方差而产生错误。
下图是其他yellowbrick特征可视化的例子
模型可视化
在此示例中,我们实例化一个 Scikit-Learn 分类器,然后使用 Yellowbrick 的 ROCAUC 类来可视化分类器的敏感性和特异性之间的权衡:
from sklearn.svm import LinearSVCfrom yellowbrick.classifier import ROCAUCmodel = LinearSVC()model.fit(X,y)visualizer = ROCAUC(model)visualizer.score(X,y)visualizer.poof()
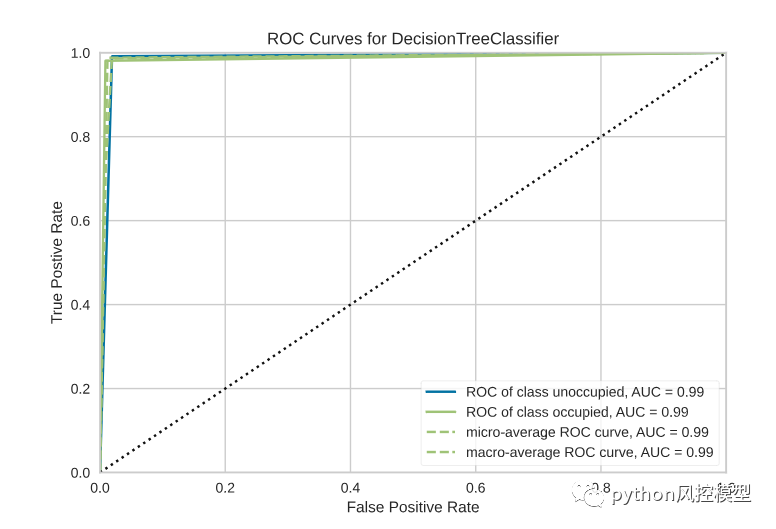
可视化数据
排名特点
数据中每对特征的相关性如何?特征的二维排序利用一次考虑特征对的排序算法。我们使用皮尔逊相关性进行评分来检测共线性关系。
from yellowbrick.features import Rank2Dvisualizer = Rank2D(algorithm='pearson')visualizer.fit(X, y)visualizer.transform(X)visualizer.show()
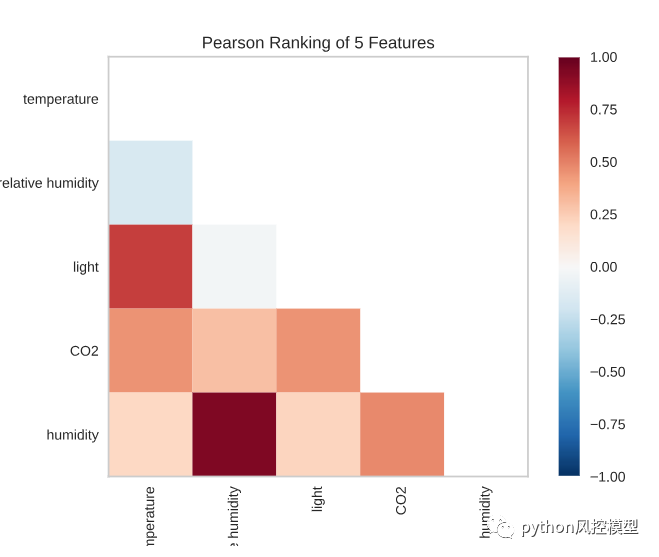
根据数据,湿度与相对湿度密切相关。光与温度密切相关。这是有道理的,因为这些功能通常是齐头并进的。
类别平衡
分类模型面临的最大挑战之一是训练数据中类别的不平衡。对于不平衡的类别,我们的高 f1 分数可能不是一个好的评估分数,因为分类器可以简单地猜出所有大多数类别获得高分。
因此,可视化类别的分布非常重要。我们可以利用ClassBalance条形图来可视化类别的分布。
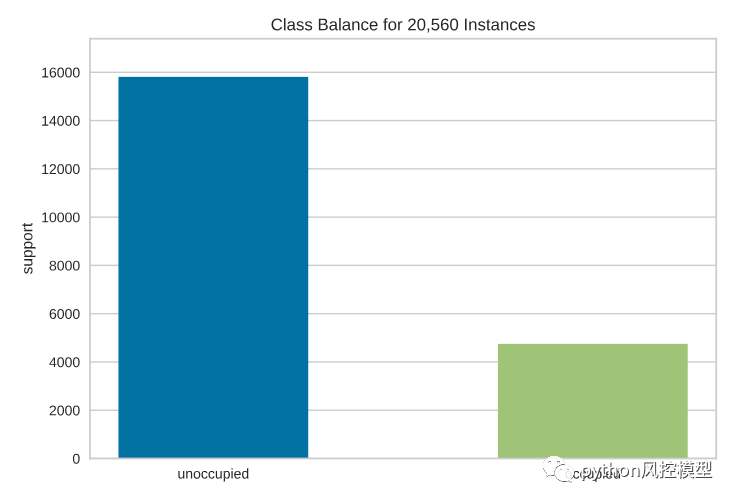
看起来未占用的数据比已占用的数据多得多。知道了这一点,我们可以利用多种技术来处理类别不平衡,例如分层抽样、加权以获得更多信息的结果。
可视化模型的结果
现在我们回到这个问题:98% 的 f1 分数到底意味着什么?f1 分数的增加是否会为您的公司带来更多利润?
Yellowbrick 提供了多种工具,可用于可视化分类问题的结果。其中一些您可能听说过或没有听说过,这对于解释您的模型非常有帮助。
混淆矩阵
空缺类别中错误预测的百分比是多少?占领阶层中错误预测的百分比是多少?混淆矩阵帮助我们回答这个问题。
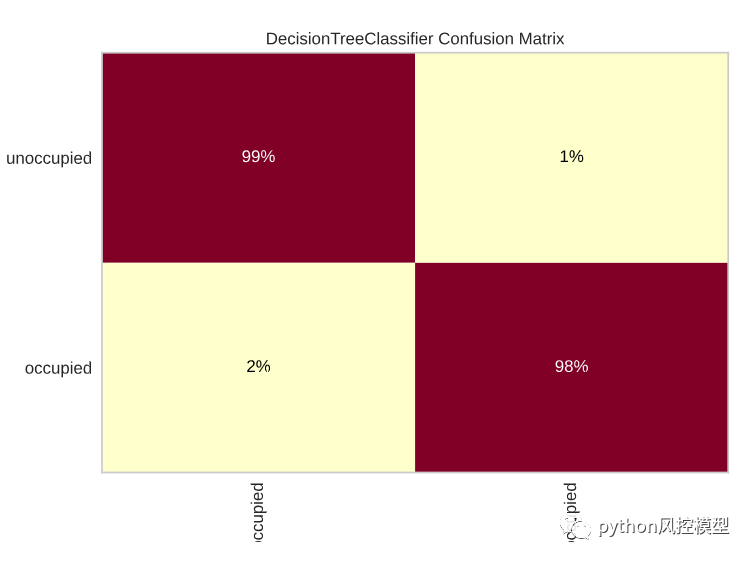
看起来占领阶层的错误预测比例更高;因此,我们可以尝试增加占用类中正确预测的数量来提高分数。
这是yellowbrick其它模型得分可视化例子。
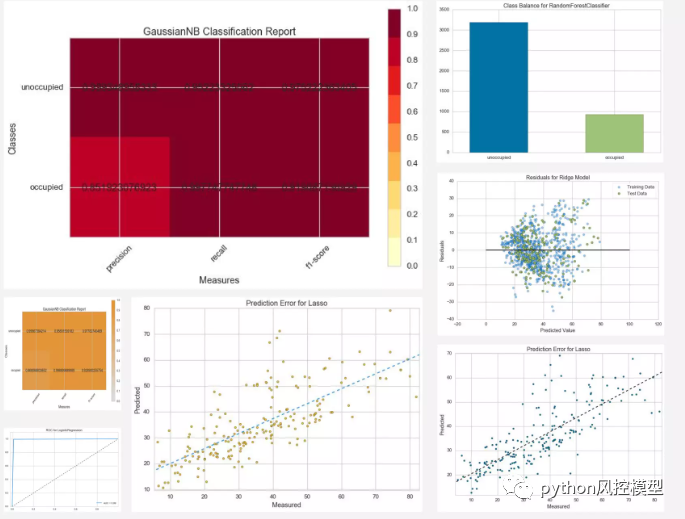
我们如何改进模型?
现在我们了解了模型的性能,我们如何改进模型呢?为了改进我们的模型,我们可能想要
-
防止我们的模型拟合不足或过度拟合
-
找到对估算器来说最重要的特征
我们将探索 Yellowbrick 提供的工具来帮助我们弄清楚如何改进我们的模型
验证曲线
一个模型可以有许多超参数。我们可以选择准确预测训练数据的超参数。找到最佳超参数的好方法是通过网格搜索选择这些参数的组合。
但我们如何知道这些超参数也能准确预测测试数据呢?绘制单个超参数对训练和测试数据的影响非常有用,以确定估计器对于某些超参数值是否欠拟合或过拟合。
验证曲线可以帮助我们找到最佳点,低于或高于此超参数的值将导致数据拟合不足或过度拟合。
from yellowbrick.model_selection import validation_curveviz = validation_curve(model, X, y, param_name="max_depth",param_range=np.arange(1, 11), cv=10, scoring="f1",)
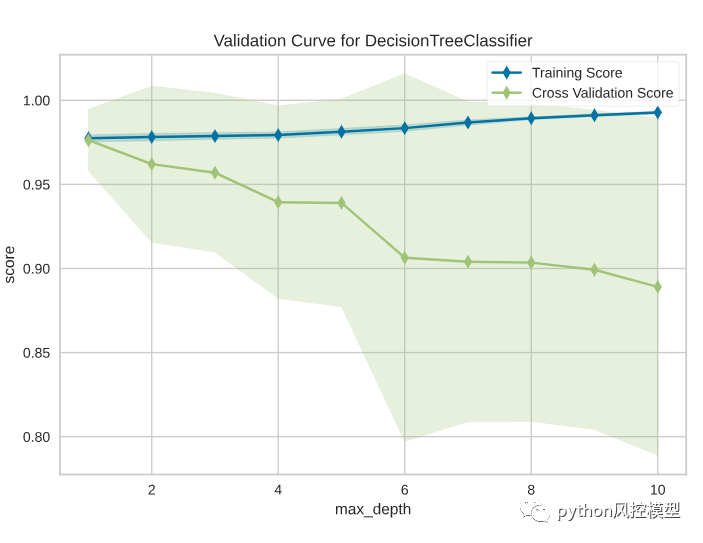
从图中我们可以看出,虽然最大深度数越高,训练得分越高,但交叉验证得分也越低。这是有道理的,因为决策树越深,就越容易过度拟合。
因此,最佳点将是交叉验证分数不降低的地方,即 1。
学习曲线
更多的数据会带来更好的模型性能吗?并非总是如此,估计器可能对方差引起的误差更敏感。这就是学习曲线有用的时候。
学习 曲线显示了具有不同数量训练样本的估计器的训练分数与交叉验证测试分数之间的关系。
from yellowbrick.model_selection import LearningCurvefrom sklearn.model_selection import StratifiedKFold#Create the learning curve visualizercv = StratifiedKFold(n_splits=12)sizes = np.linspace(0.3, 1.0, 10)visualizer = LearningCurve(model, cv=cv, scoring='f1', train_sizes=sizes,)visualizer.fit(X, y) # Fit the data to the visualizervisualizer.show() # Finalize and render the figure
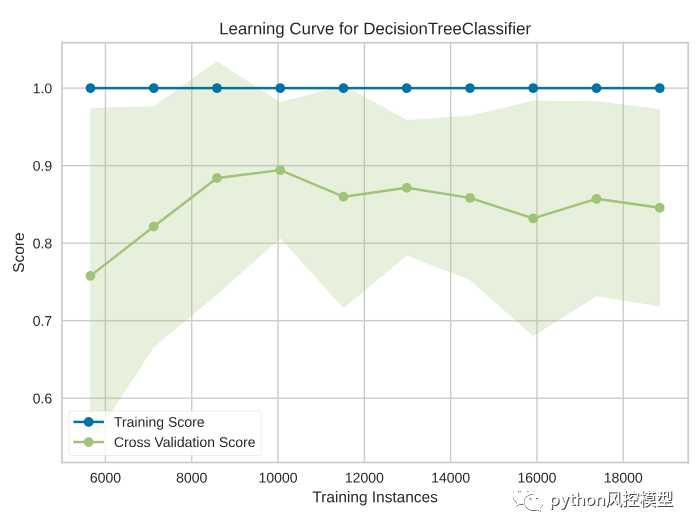
从图中我们可以看到,大约 8700 个训练实例的数量导致了最佳的 f1 分数。训练实例数量越多,f1 分数越低。
Yellowbrick使用还有很多,不局限上述介绍。下图是Yellowbrick展示随着模型搜索空间变大,时间以指数级增长。
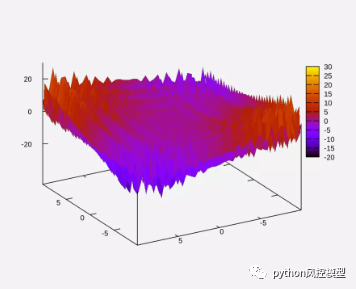
下图是Yellowbrick展示超参空间搜索


结论
恭喜!您刚刚学习了如何创建绘图来帮助您解释模型的结果。能够了解您的机器学习结果将使您更容易找到提高其性能的后续步骤。欢迎大家收藏CSDN学院课程《从0到1 Python数据科学之旅》,课程有大量数据科学建模实际案例,大家记得收藏课程。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。