【BASH】回顾与知识点梳理 三十八
- 三十八. 源码概念及简单编译
- 38.1 开放源码的软件安装与升级简介
- 什么是开放源码、编译程序与可执行文件
- 什么是函式库
- 什么是 make 与 configure
- 什么是 Tarball 的软件
- 如何安装与升级软件
- 38.2 使用传统程序语言进行编译的简单范例
- 单一程序:印出 Hello World
- 编辑程序代码,亦即原始码
- 开始编译与测试执行
- 主、子程序链接:子程序的编译
- 撰写所需要的主、子程序
- 进行程序的编译与链接 (Link)
- 呼叫外部函式库:加入连结的函式库
- 编译时加入额外函式库连结的方式:
- gcc 的简易用法 (编译、参数与链结)
该系列目录 --> 【BASH】回顾与知识点梳理(目录)
三十八. 源码概念及简单编译
在这一章当中,我们将藉由 Linux 操作系统里面的执行文件,来理解什么是可执行的程序,以及了解什么是编译程序。另外,与程序息息相关的函式库 (library) 的信息也需要了解一番!不过,在这个章节当中,鸟哥并不是要你成为一个开放源码的程序设计师, 而是希望你可以了解如何将开放源码的程序设计、加入函式库的原理、透过编译而成为可以执行 的 binary program,最后该执行档可被我们所使用的一连串过程!
了解上面的咚咚有什么好处呢?因为在 Linux 的世界里面,由于客制化的关系,有时候我们需要自行安装软件在自己的Linux 系统上面,所以如果你有简单的程序编译概念,那么将很容易进行软件的安装。 甚至在发生软件编译过程中的错误时,你也可以自行作一些简易的修订呢!而最传统的软件安装过程, 自然就是由原始码编译而来的啰!所以,在这里我们将介绍最原始的软件管理方式:使用 Tarball 来安装与升级管理我们的软件喔!
38.1 开放源码的软件安装与升级简介
在 Windows 系统上面的软件都是一模一样的,也就是说,你『无法修改该软件的源代码』,因此, 万一你想要增加或者减少该软件的某些功能时,大概只能求助于当初发行该软件的厂商了!
Linux 上面的软件几乎都是经过 GPL 的授权,所以每个软件几乎均提供源代码, 并且你可以自行修改该程序代码,以符合你个人的需求呢!很棒吧!这就是开放源码的优点啰!不过,到底什么是开放源码? 这些程序代码是什么咚咚?又 Linux 上面可以执行的相关软件文件与开放源码之间是如何转换的?不同版本的 Linux 之间能不能使用同一个执行档?或者是该执行档需要由源代码的部分重新进行转换? 这些都是需要厘清观念的。底下我们先就源代码与可执行文件来进行说明。
什么是开放源码、编译程序与可执行文件
我们说过,在 Linux 系统上面,一个文件能不能被执行看的是有没有可执行的那个权限 (具有 x permission),不过,Linux 系统上真正认识的可执行文件其实是二进制文件 ( binary program),例如 /usr/bin/passwd, /bin/touch 这些个文件即为二进制程序代码。
或许你会说 shell scripts 不是也可以执行吗?其实 shell scripts 只是利用 shell (例如 bash) 这支程序的功能进行一些判断式,而最终执行的除了 bash 提供的功能外,仍是呼叫一些已经编译好的二进制程序来执行的呢!
[root@node-135 backups]# file /bin/bash
/bin/bash: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=94b20c7f7a0529512f63bae145b524890ceae5a5, stripped
[root@node-135 backups]# file /etc/init.d/network
/etc/init.d/network: Bourne-Again shell script, ASCII text executable
看到了吧!如果是 binary 而且是可以执行的时候,他就会显示执行文件类别 (ELF 64-bit LSB executable), 同时会说明是否使用动态函式库 (shared libs),而如果是一般的 script ,那他就会显示出 text executables 之类的字样!
ELF (Executable and Linkable Format) 是unix和类unix系统下得标准文件格式,包括常见地可执行文件,目标文件,库文件,coredump文件类型。它有三种不同的类型:
- 可重定位的目标文件(Relocatable,或者Object File)
- 可执行文件(Executable)
- 共享库(Shared Object,或者Shared Library)
详细参考:https://blog.51cto.com/u_8238263/6026378
LSB(全称:Linux Standards Base),LSB是一套核心标准,它保证了LINUX发行版同LINUX应用程序之间的良好结合,制定了应用程序与运行环境之间的二进制接口。
具体地说,它是:一个二进制接口规范,是指应用程序在系统间迁移时不用重新编译,保证应用程序在所有经过认证的LINUX发行版上都具有兼容性。
事实上,network 的数据显示出 Bourne-Again … 那一行,是因为你的 scripts 上面第一行有宣告 #!/bin/bash 的缘故,如果你将 script 的第一行拿掉,那么不管 /etc/init.d/network 的权限为何,他其实显示的是 ASCII 文本文件的信息喔!
既然 Linux 操作系统真正认识的其实是 binary program,那么我们是如何做出这样的一支 binary 的程序呢?首先,我们必须要写程序,用什么东西写程序?就是一般的字处理器啊!鸟哥都喜欢使用 vim 来进行程序的撰写,写完的程序就是所谓的源代码啰! 这个程序代码文件其实就是一般的纯文本档。 在完成这个原始码文件的编写之后,再来就是要将这个文件『编译』成为操作系统看的懂得 binary program 啰!而要编译自然就需要『编译程序』来动作, 经过编译程序的编译与连结之后,就会产生一支可以执行的 binary program 啰。
举个例子来说,在 Linux 上面最标准的程序语言为 C ,所以我使用 C 的语法进行源代码的书写,写完之后,以 Linux 上标准的 C 语言编译程序 gcc 这支程序来编译,就可以制作一支可以执行的binary program 啰。整个的流程有点像这样:
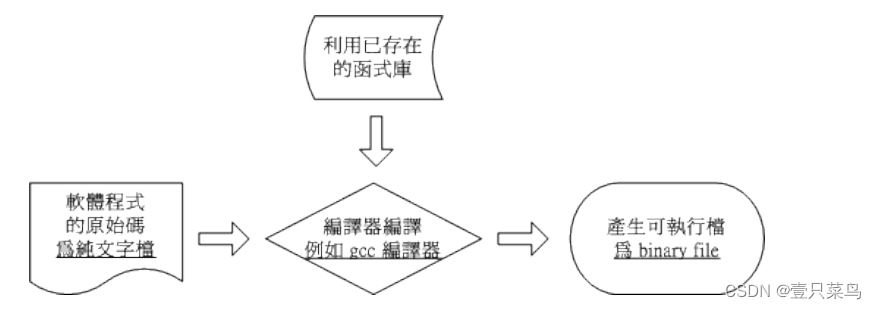
事实上,在编译的过程当中还会产生所谓的目标文件 (Object file),这些文件是以 *.o 的扩展名样式存在的!至于 C 语言的原始码文件通常以 *.c 作为扩展名。此外,有的时候,我们会在程序当中『引用、呼叫』 其他的外部子程序,或者是利用其他软件提供的『函数功能』,这个时候,我们就必须要在编译的过程当中, 将该函式库给他加进去,如此一来,编译程序就可以将所有的程序代码与函式库作一个连结 (Link) 以产生正确的执行档啰
总之,我们可以这么说:
- 开放源码:就是程序代码,写给人类看的程序语言,但机器并不认识,所以无法执行;
- 编译程序:将程序代码转译成为机器看的懂得语言,就类似翻译者的角色;
- 可执行文件:经过编译程序变成二进制程序后,机器看的懂所以可以执行的文件。
什么是函式库
什么是函式库呢?先举个例子来说:我们的 Linux 系统上通常已经提供一个可以进行身份验证的模块, 就是在前面章节中提到的 PAM 模块。这个 PAM 提供的功能可以让很多的程序在被执行的时候,除了可以验证用户登入的信息外, 还可以将身份确认的数据记录在登录档里面,以方便系统管理员的追踪!
既然有这么好用的功能,那如果我要编写具有身份认证功能的程序时,直接引用该 PAM 的功能就好啦,如此一来,我就不需要重新设计认证机制啰!也就是说,只要在我写的程序代码里面,设定去呼叫 PAM 的函式功能,我的程序就可以利用 Linux 原本就有的身份认证的程序咯!除此之外,其实我们的 Linux 核心也提供了相当多的函式库来给硬件开发者利用喔。
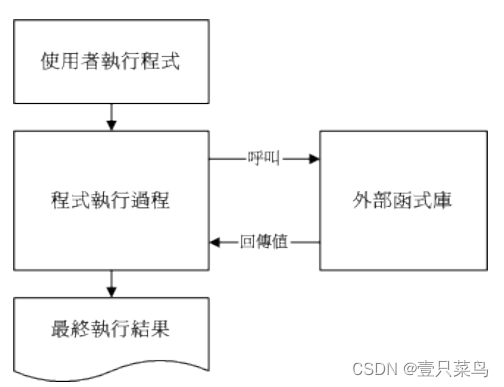
简单理解:函式库:就类似子程序的角色,可以被呼叫来执行的一段功能函数。
什么是 make 与 configure
事实上,使用类似 gcc 的编译程序来进行编译的过程并不简单,因为一套软件并不会仅有一支程序,而是有一堆程序代码文件。所以除了每个主程序与子程序均需要写上一笔编译过程的指令外,还需要写上最终的链接程序。 程序代码小的时候还好,如果是类似 WWW 服务器软件 (例如 Apache) ,或者是类似核心的原始码,动则数百 MBytes 的数据量,编译指令会写到疯掉~这个时候,我们就可以使用 make 这个指令的相关功能来进行编译过程的指令简化了!
当执行 make 时,make 会在当时的目录下搜寻 Makefile (or makefile) 这个文本文件,而 Makefile 里面则记录了原始码如何编译的详细信息! make 会自动的判别原始码是否经过变动了,而自动更新执行档,是软件工程师相当好用的一个辅助工具呢!
咦!make 是一支程序,会去找 Makefile ,那 Makefile 怎么写? 通常软件开发商都会写一支侦测程序来侦测用户的作业环境, 以及该作业环境是否有软件开发商所需要的其他功能,该侦测程序侦测完毕后,就会主动的建立这个 Makefile 的规则文件啦!通常这支侦测程序的文件名为configure或者是config。
一般来说,侦测程序会侦测的数据大约有底下这些:
- 是否有适合的编译程序可以编译本软件的程序代码;
- 是否已经存在本软件所需要的函式库,或其他需要的相依软件;
- 操作系统平台是否适合本软件,包括 Linux 的核心版本;
- 核心的表头定义档 (header include) 是否存在 (驱动程序必须要的侦测)。
至于 make 与 configure 运作流程的相关性,我们可以使用底下的图示来示意一下啊! 下图中,妳要进行的任务其实只有两个,一个是执行 configure 来建立 Makefile , 这个步骤一定要成功!成功之后再以 make 来呼叫所需要的数据来编译即可!非常简单!
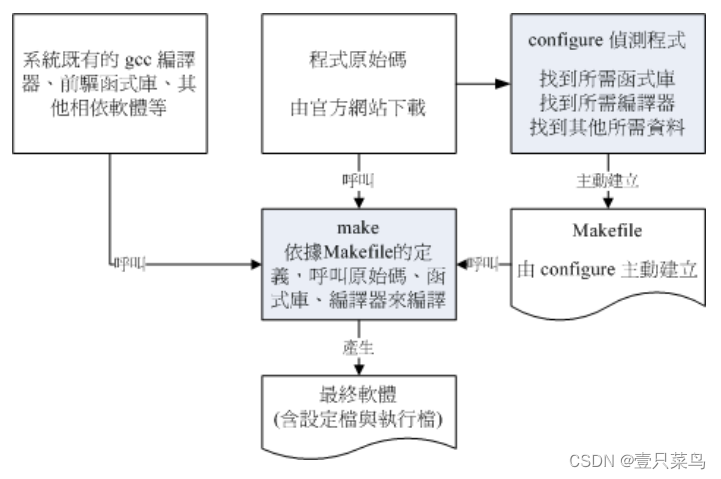
由于不同的 Linux distribution 的函式库文件所放置的路径,或者是函式库的档名订定, 或者是预设安装的编译程序,以及核心的版本都不相同,因此理论上,你无法在 CentOS 7.x 上面编译出 binary program 后,还将他拿到 SuSE 上面执行,这个动作通常是不可能成功的! 因为呼叫的目标函式库位置可能不同 , 核心版本更不可能相同!所以能够执行的情况是微乎其微!所以同一套软件要在不同的平台上面执行时,必须要重复编译!所以才需要原始码嘛!了解乎!
什么是 Tarball 的软件
如果能够将这些原始码透过文件的打包与压缩技术来将文件的数量与容量减小, 不但让用户容易下载,软件开发商的网站带宽也能够节省很多很多啊!这就是 Tarball 文件的由来啰!
所谓的 Tarball 文件,其实就是将软件的所有原始码文件先以 tar 打包,然后再以压缩技术来压缩,通常最常见的就是以 gzip 来压缩了。因为利用了 tar 与 gzip 的功能,所以 tarball 文件一般的扩展名就会写成 *.tar.gz 或者是简写为 *.tgz 啰!不过,近来由于 bzip2 与 xz 的压缩率较佳,所以 Tarball 渐渐的以 bzip2 及 xz 的压缩技术来取代 gzip 啰!因此档名也会变成 *.tar.bz2, *.tar.xz 之类的哩。所以说, Tarball 是一个软件包, 妳将他解压缩之后,里面的文件通常就会有:
- 源代码文件;
- 侦测程序文件 (可能是 configure 或 config 等檔名);
- 本软件的简易说明与安装说明 (INSTALL 或 README)。
其中最重要的是那个 INSTALL 或者是 README 这两个文件,通常你只要能够参考这两个文件,Tarball 软件的安装是很简单的啦!
如何安装与升级软件
基本上更新的方法可以分为两大类,分别是:
- 直接以原始码透过编译来安装与升级;
- 直接以编译好的 binary program 来安装与升级。
预先编译好程序的机制存在于很多 distribution 喔,包括有 Red Hat 系统 (含 Fedora/CentOS 系列) 发展的 RPM 软件管理机制与 yum 在线更新模式;Debian 使用的 dpkg 软件管理机制与 APT 在线更新模式等等。
那么一个软件的 Tarball 是如何安装的呢?基本流程是这样的啦:
- 将 Tarball 由厂商的网页下载下来;
- 将 Tarball 解开,产生很多的原始码文件;
- 开始以 gcc 进行原始码的编译 (会产生目标文件 object files);
- 然后以 gcc 进行函式库、主、子程序的链接,以形成主要的 binary file;
- 将上述的 binary file 以及相关的配置文件安装至自己的主机上面。
38.2 使用传统程序语言进行编译的简单范例
经过上面的介绍之后,你应该比较清楚的知道原始码、编译程序、函式库与执行档之间的相关性了。不过,详细的流程可能还是不很清楚,所以,在这里我们以一个简单的程序范例来说明整个编译的过程喔!赶紧进入 Linux 系统,实地的操作一下底下的范例呢!
单一程序:印出 Hello World
请先确认你的 Linux 系统里面已经安装了 gcc 了喔!如果尚未安装 gcc 的话,请先参考下一节的 RPM 安装法,先安装好 gcc 之后,再回来阅读本章。 如果你已经有网络了,那么直接使用『 yum groupinstall “Development Tools” 』 预安装好所需的所有软件即可。
编辑程序代码,亦即原始码
[root@study ~]# vim hello.c <==用 C 语言写的程序扩展名建议用 .c
#include <stdio.h>
int main(void)
{printf("Hello World\n");
}
开始编译与测试执行
[root@study ~]# gcc hello.c
[root@study ~]# ll hello.c a.out
-rwxr-xr-x. 1 root root 8503 Sep 4 11:33 a.out <==此时会产生这个档名
-rw-r--r--. 1 root root 71 Sep 4 11:32 hello.c
[root@study ~]# ./a.out
Hello World <==呵呵!成果出现了!
在预设的状态下,如果我们直接以 gcc 编译原始码,并且没有加上任何参数,则执行档的档名会被自动设定为 a.out 这个文件名!所以妳就能够直接执行 ./a.out 这个执行档啦!
那如果我想要产生目标文件 (object file) 来进行其他的动作,而且执行档的档名也不要用预设的 a.out ,那该如何是好?其实妳可以将上面的第 2 个步骤改成这样:
[root@study ~]# gcc -c hello.c
[root@study ~]# ll hello*
-rw-r--r--. 1 root root 71 Sep 4 11:32 hello.c
-rw-r--r--. 1 root root 1496 Sep 4 11:34 hello.o <==就是被产生的目标文件
[root@study ~]# gcc -o hello hello.o
[root@study ~]# ll hello*
-rwxr-xr-x. 1 root root 8503 Sep 4 11:35 hello <==这就是可执行文件! -o 的结果
-rw-r--r--. 1 root root 71 Sep 4 11:32 hello.c
-rw-r--r--. 1 root root 1496 Sep 4 11:34 hello.o
[root@study ~]# ./hello
Hello World
主、子程序链接:子程序的编译
如果我们在一个主程序里面又呼叫了另一个子程序呢?这是很常见的一个程序写法, 因为可以简化整个程序的易读性!在底下的例子当中,我们以 thanks.c 这个主程序去呼叫 thanks_2.c 这个子程序,写法很简单:
撰写所需要的主、子程序
# 1. 编辑主程序:
[root@study ~]# vim thanks.c
#include <stdio.h>
int main(void)
{printf("Hello World\n");thanks_2();
}
# 上面的 thanks_2(); 那一行就是呼叫子程序啦!
[root@study ~]# vim thanks_2.c
#include <stdio.h>
void thanks_2(void)
{printf("Thank you!\n");
}
进行程序的编译与链接 (Link)
# 2. 开始将原始码编译成为可执行的 binary file :
[root@study ~]# gcc -c thanks.c thanks_2.c
[root@study ~]# ll thanks*
-rw-r--r--. 1 root root 75 Sep 4 11:43 thanks_2.c
-rw-r--r--. 1 root root 1496 Sep 4 11:43 thanks_2.o <==编译产生的!
-rw-r--r--. 1 root root 91 Sep 4 11:42 thanks.c
-rw-r--r--. 1 root root 1560 Sep 4 11:43 thanks.o <==编译产生的!
[root@study ~]# gcc -o thanks thanks.o thanks_2.o
[root@study ~]# ll thanks*
-rwxr-xr-x. 1 root root 8572 Sep 4 11:44 thanks <==最终结果会产生这玩意儿
# 3. 执行一下这个文件:
[root@study ~]# ./thanks
Hello World
Thank you!
知道为什么要制作出目标文件了吗?由于我们的原始码文件有时并非仅只有一个文件,所以我们无法直接进行编译。这个时候就需要先产生目标文件,然后再以连结制作成为 binary 可执行文件。另外,如果有一天,你更新了 thanks_2.c 这个文件的内容,则你只要重新编译 thanks_2.c 来产生新的thanks_2.o ,然后再以连结制作出新的 binary 可执行文件即可!而不必重新编译其他没有更动过的原始码文件。
此外,如果你想要让程序在执行的时候具有比较好的效能,或者是其他的除错功能时, 可以在编译的过程里面加入适当的参数,例如底下的例子:
[root@study ~]# gcc -O -c thanks.c thanks_2.c <== -O 为产生优化的参数
[root@study ~]# gcc -Wall -c thanks.c thanks_2.c
thanks.c: In function ‘main’:
thanks.c:5:9: warning: implicit declaration of function ‘thanks_2’
[-Wimplicit-function-declaration]thanks_2();^
thanks.c:6:1: warning: control reaches end of non-void function [-Wreturn-type]
}
^
# -Wall 为产生更详细的编译过程信息。上面的讯息为警告讯息 (warning) 所以不用理会也没有关系!
至于更多的 gcc 额外参数功能,就得要 man gcc 啰~呵呵!可多的跟天书一样~
呼叫外部函式库:加入连结的函式库
刚刚我们都仅只是在屏幕上面印出一些字眼而已,如果说要计算数学公式呢?例如我们想要计算出三角函数里面的 sin (90 度角)。要注意的是,大多数的程序语言都是使用径度而不是一般我们在计算的『角度』, 180 度角约等于 3.14 径度!嗯!那我们就来写一下这个程序吧!
[root@study ~]# vim sin.c
#include <stdio.h>
#include <math.h>
int main(void)
{float value;value = sin ( 3.14 / 2 );printf("%f\n",value);
}
那要如何编译这支程序呢?我们先直接编译看看:
[root@study ~]# gcc sin.c
# 新的 GCC 会主动将函数抓进来给你用,所以只要加上 include <math.h> 就好了!
新版的 GCC 会主动帮你将所需要的函式库抓进来编译,所以不会出现怪异的错误讯息! 事实上,数学函式库使用的是 libm.so 这个函式库,你最好在编译的时候将这个函式库纳进去比较好~另外要注意, 这个函式库放置的地方是系统默认会去找的 /lib, /lib64 ,所以你无须使用底下的-L去加入搜寻的目录! 而 libm.so 在编译的写法上,使用的是-lm (lib 简写为 l 喔!)喔!因此就变成:
编译时加入额外函式库连结的方式:
[root@study ~]# gcc sin.c -lm -L/lib -L/lib64 <==重点在 -lm
[root@study ~]# ./a.out <==尝试执行新文件!
1.000000
特别注意,使用 gcc 编译时所加入的那个 -lm 是有意义的,他可以拆开成两部份来看:
- -l :是『加入某个函式库(library)』的意思,
- m :则是 libm.so 这个函式库,其中, lib 与扩展名(.a 或 .so)不需要写
所以 -lm 表示使用 libm.so (或 libm.a) 这个函式库的意思~至于那个 -L 后面接的路径呢?这表示:『我要的函式库 libm.so 请到 /lib 或 /lib64 里面搜寻!』
上面的说明很清楚了吧!不过,要注意的是,由于 Linux 预设是将函式库放置在 /lib 与 /lib64 当中,所以你没有写-L/lib与 -L/lib64 也没有关系的!不过,万一哪天你使用的函式库并非放置在这两个目录下,那么-L/path就很重要了!否则会找不到函式库喔!
除了连结的函式库之外,你或许已经发现一个奇怪的地方,那就是在我们的 sin.c 当中第一行『 #include <stdio.h>』,这行说的是要将一些定义数据由 stdio.h 这个文件读入,这包括 printf 的相关设定。这个文件其实是放置在 /usr/include/stdio.h 的!那么万一这个文件并非放置在这里呢?那么我们就可以使用底下的方式来定义出要读取的 include 文件放置的目录:
[root@study ~]# gcc sin.c -lm -I/usr/include
-I/path 后面接的路径( Path )就是设定要去搜寻相关的 include 文件的目录啦!不过,同样的,默认值是放置在 /usr/include 底下,除非你的 include 文件放置在其他路径,否则也可以略过这个项目!
gcc 的简易用法 (编译、参数与链结)
gcc 为 Linux 上面最标准的编译程序,这个 gcc 是由 GNU 计划所维护的,有兴趣的朋友请自行前往参考。既然 gcc 对于 Linux 上的 Open source 是这么样的重要,所以底下我们就列举几个 gcc 常见的参数,如此一来大家应该更容易了解原始码的各项功能吧!
# 仅将原始码编译成为目标文件,并不制作链接等功能:
[root@study ~]# gcc -c hello.c
# 会自动的产生 hello.o 这个文件,但是并不会产生 binary 执行档。
# 在编译的时候,依据作业环境给予优化执行速度[root@study ~]# gcc -O hello.c -c
# 会自动的产生 hello.o 这个文件,并且进行优化喔!
# 在进行 binary file 制作时,将连结的函式库与相关的路径填入[root@study ~]# gcc sin.c -lm -L/lib -I/usr/include
# 这个指令较常下达在最终连结成 binary file 的时候,
# -lm 指的是 libm.so 或 libm.a 这个函式库文件;
# -L 后面接的路径是刚刚上面那个函式库的搜寻目录;
# -I 后面接的是原始码内的 include 文件之所在目录。
# 将编译的结果输出成某个特定档名[root@study ~]# gcc -o hello hello.c
# -o 后面接的是要输出的 binary file 檔名
# 在编译的时候,输出较多的讯息说明[root@study ~]# gcc -o hello hello.c -Wall
# 加入 -Wall 之后,程序的编译会变的较为严谨一点,所以警告讯息也会显示出来!
比较重要的大概就是这一些。另外,我们通常称-Wall或者-O这些非必要的参数为旗标 (FLAGS),因为我们使用的是 C 程序语言,所以有时候也会简称这些旗标为 CFLAGS ,这些变量偶尔会被使用的喔!尤其是在后头会介绍的 make 相关的用法时,更是重要的很吶!^_^
该系列目录 --> 【BASH】回顾与知识点梳理(目录)