深度学习基本理论上篇:(MLP/激活函数/softmax/损失函数/梯度/梯度下降/学习率/反向传播)
深度学习基本理论上篇:(MLP/激活函数/softmax/损失函数/梯度/梯度下降/学习率/反向传播)、深度学习面试_会害羞的杨卓越的博客-CSDN博客
18、 请说明Momentum、AdaGrad、Adam梯度下降法的特点
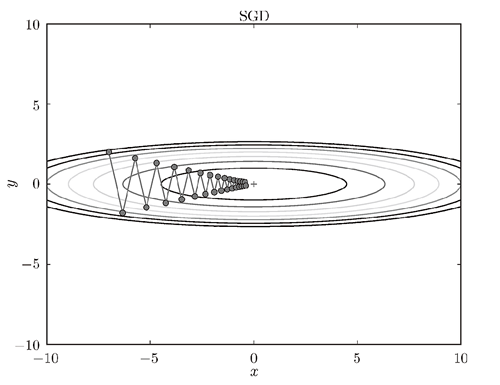
Momentum、AdaGrad、Adam是针对SGD梯度下降算法的缺点的改进算法。在SGD算法中,如果函数的形状非均向(参数大小差异较大),SGD的搜索路径会呈“之字形”移动,搜索效率较低。如下图所示:
1)Momentum
Momentum是“动量”的意思,和物理有关。用数学式表示Momentum方法,如下所示:
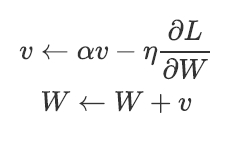
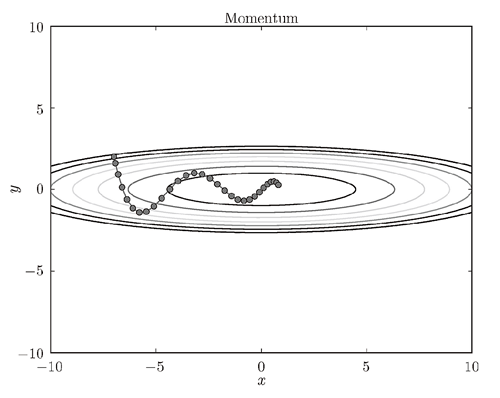
其中,W表示要更新的权重参数,∂L/∂w表示W的梯度,η表示学习率,v对应物理上的速度。在物体不受任何力时,该项承担使物体逐渐减速的任务(α设定为0.9之类的值),对应物理上的地面摩擦或空气阻力。和SGD相比,我们发现“之”字形的“程度”减轻了。这是因为,虽然x轴方向上受到的力非常小,但是一直在同一方向上受力,所以朝同一个方向会有一定的加速。反过来,虽然y轴方向上受到的力很大,但是因为交互地受到正方向和反方向的力,它们会互相抵消,所以y轴方向上的速度不稳定。因此,和SGD时的情形相比,可以更快地朝x轴方向靠近,减弱“之”字形的变动程度。如下图所示:
2)AdaGrad
AdaGrad会为参数的每个元素适当地调整学习率,与此同时进行学习(AdaGrad的Ada来自英文单词Adaptive,即“适当的”的意思),其表达式为:
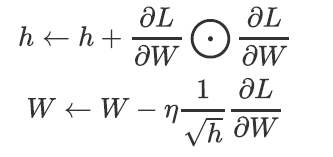
其中,W表示要更新的权重参数,$\frac{\partial L}{\partial W}$表示W的梯度,$\eta$表示学习率,$\frac{\partial L} {\partial W} \bigodot \frac{\partial L} {\partial W}$表示所有梯度值的平方和。在参数更新时,通过乘以$\frac{1}{\sqrt h}$就可以调整学习的尺度。这意味着,参数的元素中变动较大(被大幅更新)的元素的学习率将变小。也就是说,可以按参数的元素进行学习率衰减,使变动大的参数的学习率逐渐减小。其收敛路径如下图所示:
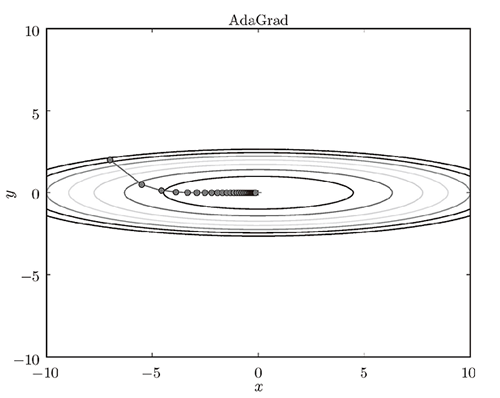
3)Adam
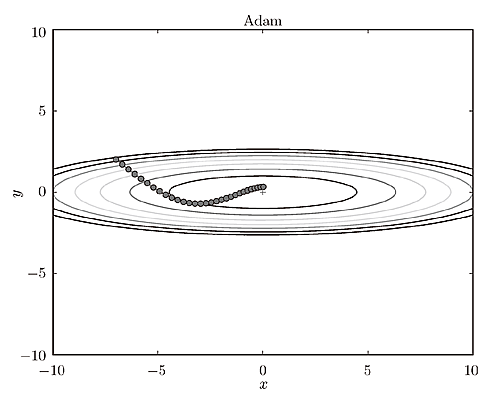
Adam是2015年提出的新方法。它的理论有些复杂,直观地讲,就是融合了Momentum和AdaGrad的方法。通过组合前面两个方法的优点,有望实现参数空间的高效搜索。其收敛路径如下图所:
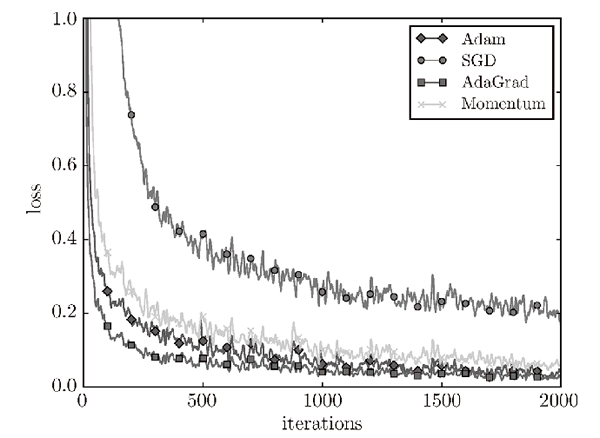
以下是几种梯度下降算法的收敛情况对比:
19. 什么是卷积函数
卷积函数指一个函数和另一个函数在某个维度上的加权“叠加”作用,其表达式为:
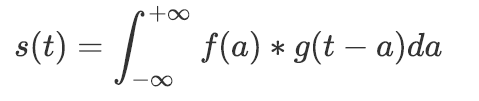
离散化卷积函数表示为:
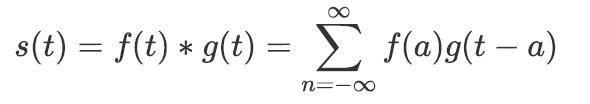
20. 二维卷积运算中,输出矩阵大小与输入矩阵、卷积核大小、步幅、填充的关系?
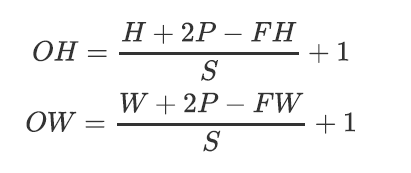
- OH:输出高
- OW:输出宽
- H:输入高
- W:输入宽
- P:padding层数
- FH:卷积核高
- FW:卷积核宽
- S:步长
21. 什么是池化,池化层的作用是什么
也称子采样层或下采样层(Subsampling Layer),目的是缩小高、长方向上的空间的运算,以降低计算量,提高泛化能力。
22. 什么是最大池化、平均池化
最大池化:取池化区域内的最大值作为池化输出
平均池化:取池化区域内的平均值作为池化输出
23. 池化层有什么特征
1)没有要学习的参数
2)通道数不发生变化
3)对微小的变化具有鲁棒性
24. 什么是归一化, 为什么要进行归一化
1)归一化的含义。归一化是指归纳统一样本的统计分布性。归一化在 $ 0-1$ 之间是统计的概率分布,归一化在$ -1--+1$ 之间是统计的坐标分布
2)归一化处理的目的
- 为了后面数据处理的方便,归一化的确可以避免一些不必要的数值问题
- 为了程序运行时收敛加快
- 统一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准
- 避免神经元饱和。当神经元的激活在接近 0 或者 1 时会饱和,在这些区域,梯度几乎为 0,这样,在反向传播过程中,局部梯度就会接近 0,这会有效地“杀死”梯度。
25. 什么是批量归一化,其优点是什么
1)批量归一化(Batch Normalization,简写BN)指在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批量归一化。
2)优点
- 减少了人为选择参数。在某些情况下可以取消 dropout 和 L2 正则项参数,或者采取更小的 L2 正则项约束参数;
- 减少了对学习率的要求。现在我们可以使用初始很大的学习率或者选择了较小的学习率,算法也能够快速训练收敛;
- 可以不再使用局部响应归一化(BN 本身就是归一化网络) ;
- 破坏原来的数据分布,一定程度上缓解过拟合;
- 减少梯度消失,加快收敛速度,提高训练精度。
26. 请列举AlexNet的特点
- 使用ReLU作为激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度消失问题
- 使用Dropout(丢弃学习)随机忽略一部分神经元防止过拟合
- 在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果
- 提出了LRN(Local Response Normalization,局部正规化)层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力
- 使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算
27. 什么是dropout操作,dropout的工作原理?
1)定义
Dropout是用于深度神经网络防止过拟合的一种方式,在神经网络训练过程中,通过忽略一定比例
的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。简单来说,在前向传播的时候,让某个神经元的激活值以一定的概率P停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
2)dropout工作原理
假设我们要训练这样一个网络,结构如左图所示:
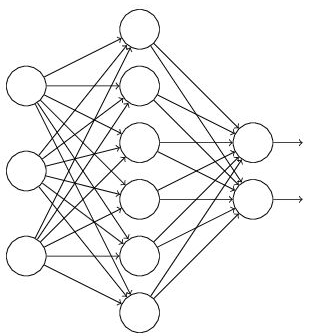
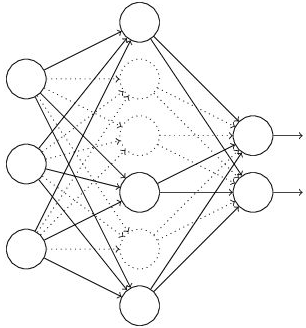
输入是x输出是y,正常的流程是:我们首先把x通过网络前向传播,然后把误差反向传播以决定如何更新参数让网络进行学习。使用Dropout之后,过程变成如右图:
(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(上图中虚线表示临时被删除的神经元)
(2) 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)
(3)然后继续重复以下过程:
- 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
- 从隐藏层神经元中随机选择一定比率子集临时删除掉(备份被删除神经元的参数)
- 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)
3)为什么dropout能避免过拟合
(1)取平均作用。不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。
(2)减少神经元之间复杂的共适应关系。因为dropout程序导致两个神经元不一定每次都在一个
dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征
仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元
的随机子集中也存在。
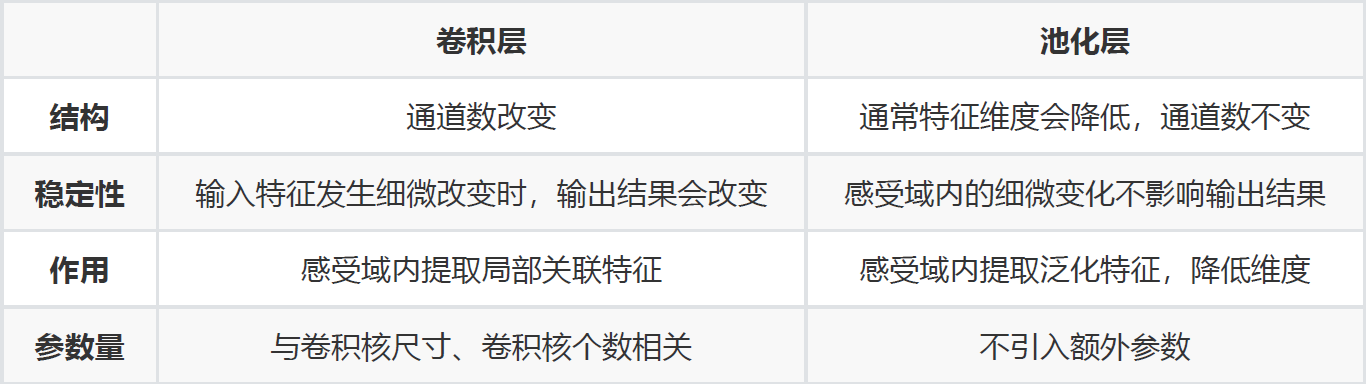
28. 卷积层和池化层有什么区别
卷积层和池化层在结构上具有一定的相似性,都是对感受域内的特征进行提取,并且根据步长设置
获取到不同维度的输出,但是其内在操作是有本质区别的,如下表所示:
 29. 如何选择卷积核大小
29. 如何选择卷积核大小
在早期的卷积神经网络中(如LeNet-5、AlexNet),用到了一些较大的卷积核($11\times11$),受限于当时的计算能力和模型结构的设计,无法将网络叠加得很深,因此卷积网络中的卷积层需要设置较大的卷积核以获取更大的感受域。但是这种大卷积核反而会导致计算量大幅增加,不利于训练更深层的模型,相应的计算性能也会降低。后来的卷积神经网络(VGG、GoogLeNet等),发现通过堆叠2个$3\times 3$卷积核可以获得与$5\times 5$卷积核相同的感受视野,同时参数量会更少($3×3×2+1$ < $ 5×5×1+1$),$3\times 3$卷积核被广泛应用在许多卷积神经网络中。因此可以认为,在大多数情况下通过堆叠较小的卷积核比直接采用单个更大的卷积核会更加有效。
30. 如何提高图像分类的准确率
1)样本优化
增大样本数量
数据增强:形态、色彩、噪声扰动
2)参数优化
批量正则化
变化学习率
权重衰减
3)模型优化
增加网络模型深度
更换更复杂的模型
深度学习基本理论上篇:(MLP/激活函数/softmax/损失函数/梯度/梯度下降/学习率/反向传播)
深度学习基本理论上篇:(MLP/激活函数/softmax/损失函数/梯度/梯度下降/学习率/反向传播)、深度学习面试_会害羞的杨卓越的博客-CSDN博客