目录
- 创建数据库
- 字符集和校验规则
- 查看系统默认字符集以及校验规则
- 校验规则对数据库的影响
- 操纵数据库
- 查看已经创建的数据库
- 显示某个数据库的创建语句
- 修改数据库
- 删除数据库
- 数据库备份和还原
- 备份
- 还原
- 查看连接情况
创建数据库
语法:
create database [if not exists] 数据库名字 [charset=xxx] [collate=yyy];
说明:
[]里面的表示可选项,也就是可写也可以不写;
charset=xxx,指定当前数据库采用什么样的编码格式来进行存储数据;
collate:指定数据库字符集的校验规则;
注意加";"
eg:
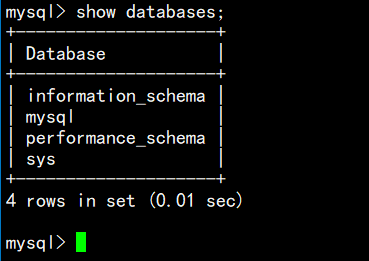
在创建之前,我们可以先使用show databases;语句来查看一下当前MySQL服务器维护的有那些数据库:
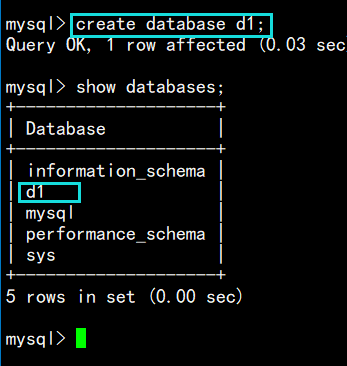
现在我们可以利用create database 语句创建一个数据库:create database d1
我们可以发现,我们的确完成了一次数据库的创建,可是前面我们说了数据库也是一个文件啊,那么这些数据库文件存储在哪里呢?
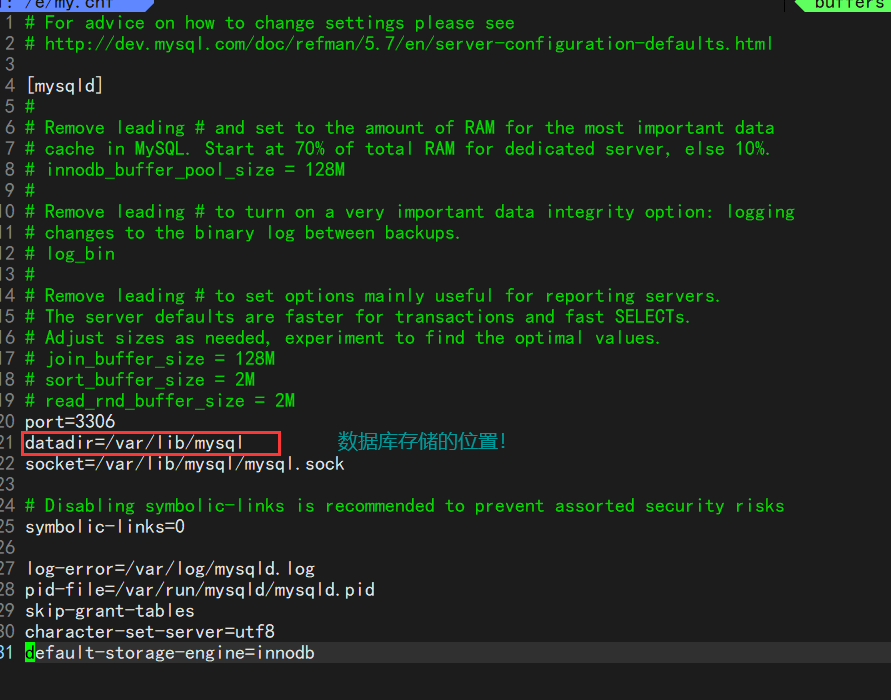
这个我们可以通过查看/etc/my.cnf文件来得知数据库文件的存储位置:
于是我们可以去这个路径下看一看,我们创建的d1数据库是不是真的存储在这个路径下:
看来确实是这样子的!
那么数据库文件里面都有什么东西呢?
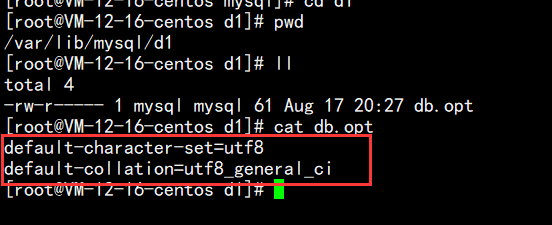
我们可以查看我们刚才创建的数据库d1来看看:
通过查看d1文件,发现虽然我们还没有向这个数据库中插入任何数据,但是这个数据库中早以存在着一个文件,这个文件中是这个数据库的默认配置文件,里面存的是当前数据库下存储数据时所采用的编码格式和数据库字符集的校验规则;
可是为什么是上面这个样子呢?
这主要是因为,我们在/etc/my.cnf配置文件中配置的默认编码格式就是Utf8的因此,当我们在创建数据库的时候如果不指明当前数据库所采用的编码格式的话,那么它会采用配置文文件中的编码格式及其对应的校验规则!
为此,如果我们想要指名一个数据库的编码格式该怎么办呢?
可以使用以下SQL语句:create database d2 charset=gbk collate=gbk_chinese-ci;
我们可以看到新的数据库d2确实使用的我们指定的编码格式和校验字符集;
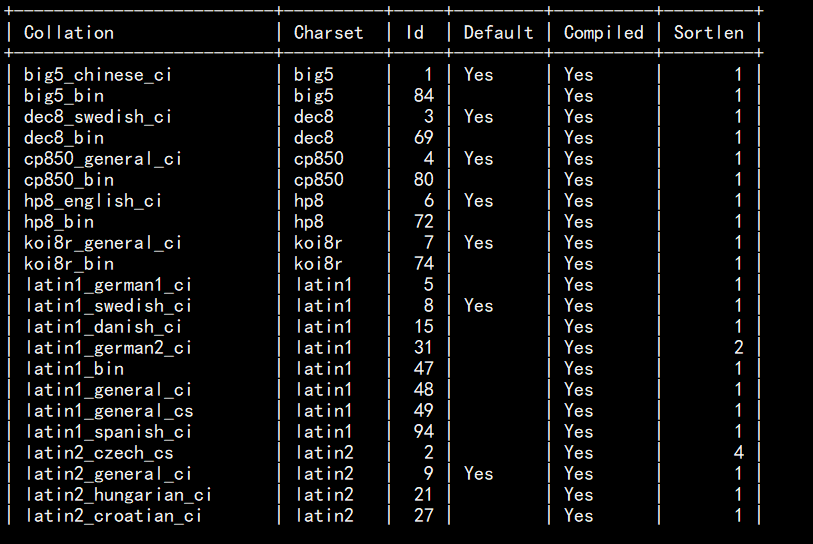
当然,我们可以通过show charset;语句来查看编码格式对应的校验规则:
同理我们也可以使用
show collation来查看校验规则对应的编码格式:


字符集和校验规则
什么是字符集?什么又是校验规则?
字符集就是规定了数据库在存储或读取数据时所采用的一种编码格式,在存储和读取时采用的编码格式必须一样,不然会造成数据错误解释!
而校验规则呢?
顾名思义,是一组规则,用来定义在进行字符串比较和排序时,字符的比较规则,不同的校验规则可以影响字符的排序顺序、大小写敏感性;例如某些校验规则不区分大小写(eg:utf8_general_ci),某些校验规则区分大小写(eg:utf8_bin);
查看系统默认字符集以及校验规则
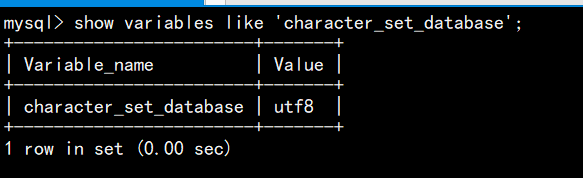
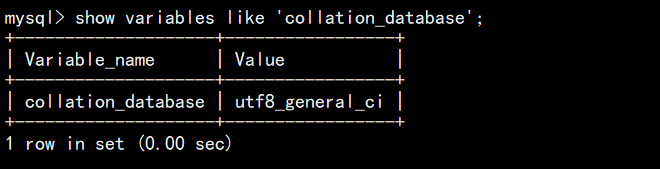
show variables like 'character_set_database';//查看默认字符集;
show variables like 'collation_database';//查看默认校验规则;
校验规则对数据库的影响
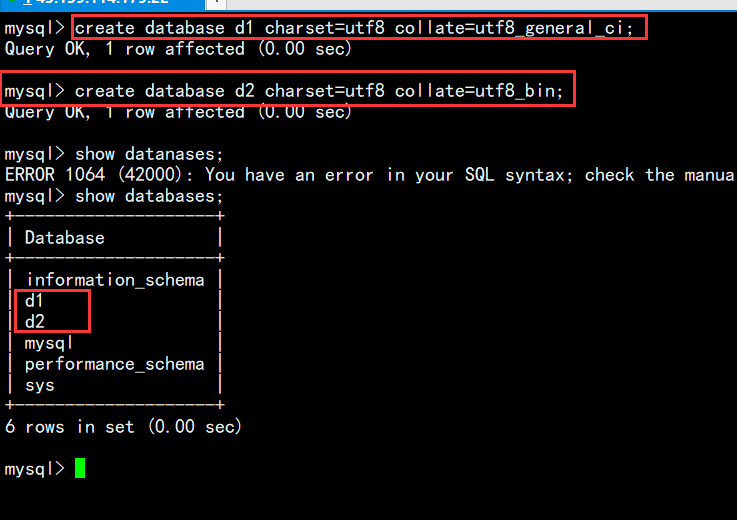
创建一个d1数据库,字符集为utf8,校验格式为utf8_general_ci(不区分大小写),
再创建一个d2数据库,字符集为uthf8,校验格式为utf8_bin(区分大小写)
紧接着,我们可以在d1,d2两个数据库里面形成同一张表,并且插入同样的数据,然后观察最后的排序结果:
d1数据库:
use d1;切到d1数据库
create table person(name varchar(20));//创建一个表结构;
inster info person values(‘a’);
inster info person values(‘A’);
inster info person values(‘b’);
inster info person values(‘B’);
inster info person values(‘c’);
inster info person values(‘C’);
d2数据库也是同样的操作;
通过select * from person;语句查询d1和d2数据库中两个person表的结果!
很明显两个结果是一样的,这个毫无疑问!紧接着,我们在利用select * from person where name='a';语句筛选出‘a’的数据:
在d1数据库中的筛选结果:
这也不意外,因为d1数据库的校验规则是不区分大小写的,因此,当我们筛选’a’的时候,‘A’也会被筛选出来,同理我们预测一下d2数据库的筛选结果,d2数据库数区分大小写的因此筛选’a’的时候筛选结果就应该只有’a’:
事实确实是这样的!
这也就验证了不同校验规则对于数据库的不同影响!



操纵数据库
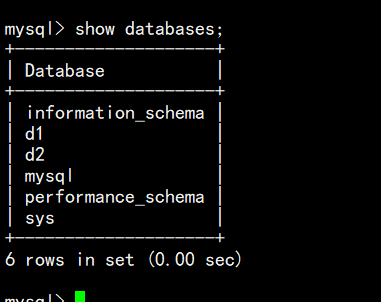
查看已经创建的数据库
show databases;
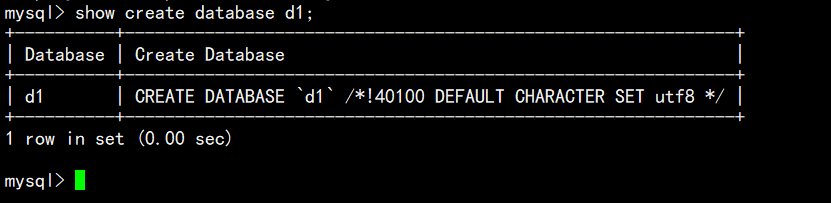
显示某个数据库的创建语句
show create database d1;
- MySQL建议我们关键字大写,但是不是必须的!;
- 数据库名字反引号’ ',是为了防止使用的数据库名和关键字冲突!;
/*!40100 default.... */这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话 ;
修改数据库
对于数据库的修改主要在于对于数据库字符集、校验规则的修改;
语法:
alter database 数据库名 [charset=xxx] [collate=yyy];
eg:
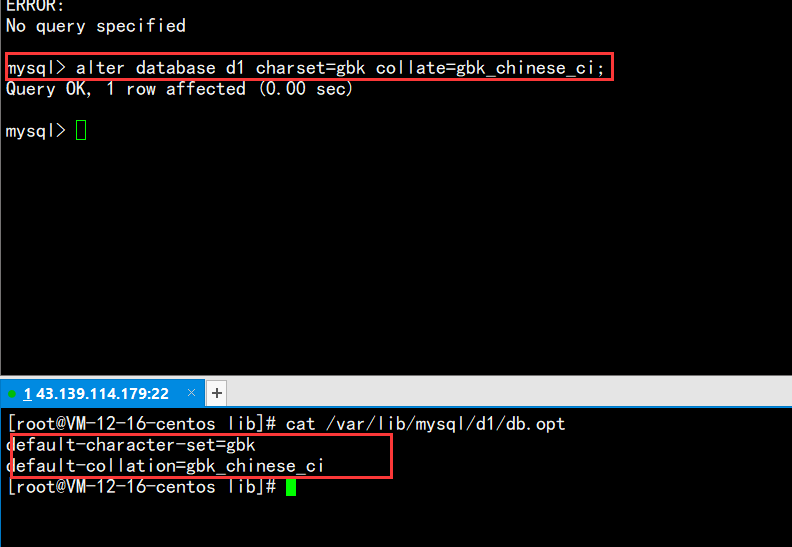
我们可以更改以下d1数据库的字符集和校验规则,d1目前的字符集是utf8,校验规则是utf8_general_ci;
现将其更改为:字符集:gbk,校验规则:gbk_chinese_ci;
更改语句:alter database d1 charset=gbk collate=gbk_chinese_ci;
删除数据库
语法:
drop database [if exists] 数据库名;
执行删除之后的结果:
- 数据库内部看不到对应的数据库;
- 对应的数据库文件夹被删除,级联删除里面的数据表也会被删除;
所以,千万不要轻易删除一个数据库,万一真的要删除,可以先在删除之前做个备份,关于如何备份,我们后面再说;
eg:
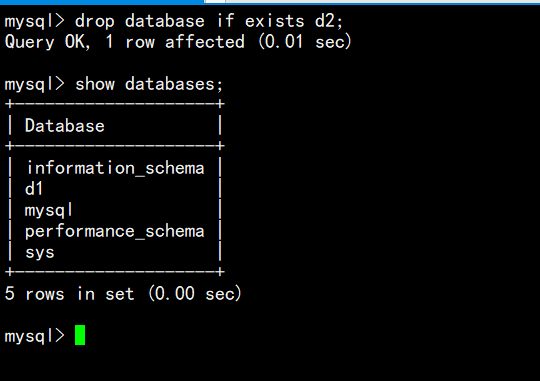
我们现在要删除d2数据库;
删除语句drop database if exists d2;
不在存在d2数据库!
数据库备份和还原
备份
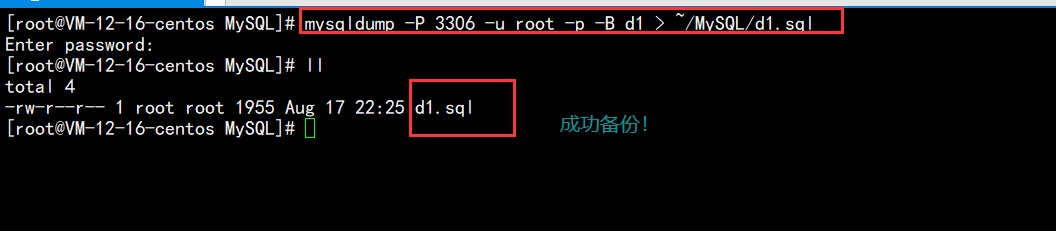
关于数据库的备份工作,我们需要借用mysqldump工具,这个工具在我们安装MySQL服务时就已经安装好了;
语法mysqldump -h ip -P 端口号 -u 用户 -p 密码 -B 数据库名 > 数据库备份存储的文件路径(退出mysql客户端)
eg:
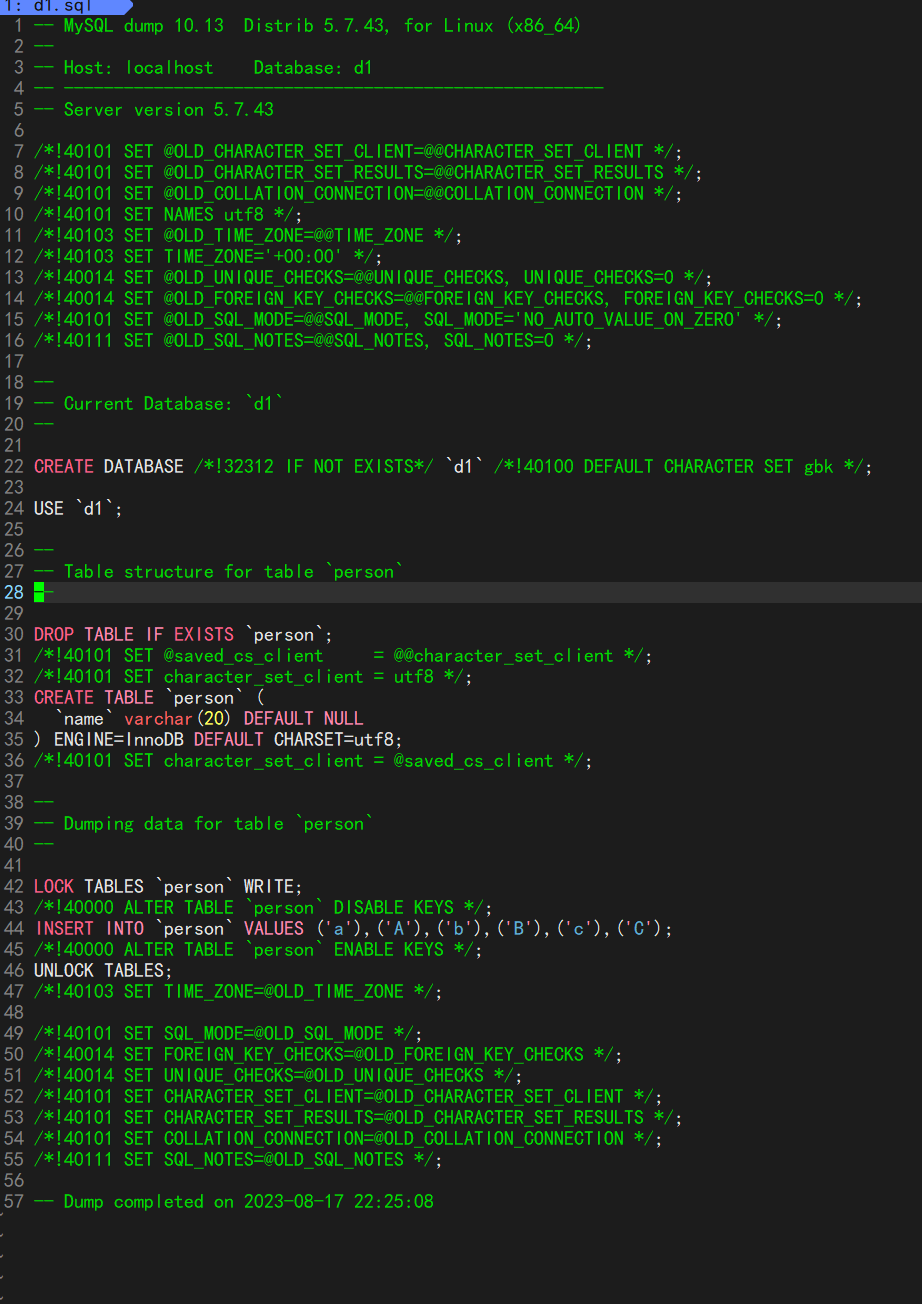
我们可以先看一看这个备份文件里面的内容:
这些视乎好像就是我们创建d1数据库和对d1数据库进行的各种操作!因此数据库的备份原理就是将一个数据库从创建开始的每一次操作都保存下来,最后还原的时候,只需要重新执行一下这些操作就行了,当然不是我们用户来执行啦!
现在备份也备份好了,我们也就可以快乐的删除d1数据库了;
drpo database d1;
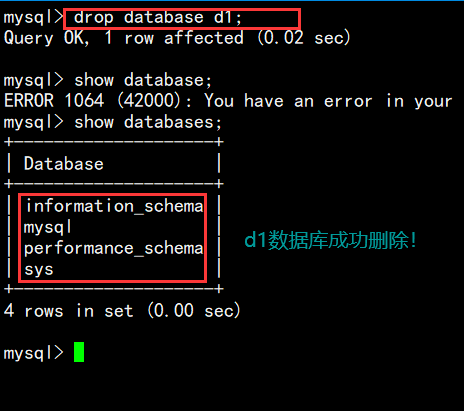
还原
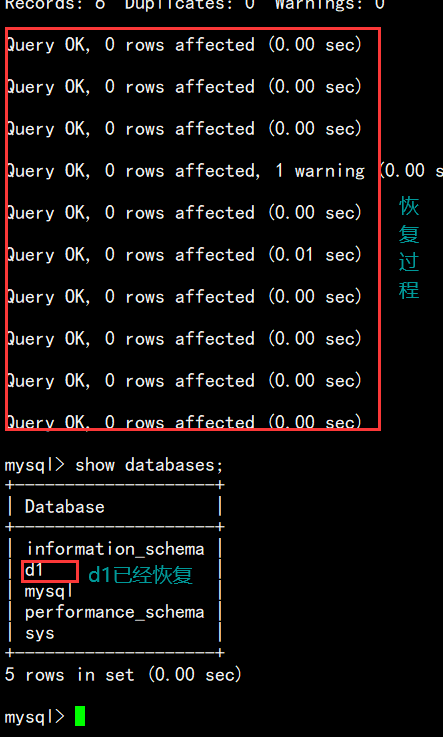
备份也备份好了,删除也删除了,我们就先来还原一下吧:
语法:source /root/MySQL.d1.sql;(需要先登录上mysql客户端)
也许这里就有读者有疑惑了,既然是备份啊,我们也知道数据库的存储地址,我们为什么不直接去(/var/lib/mysql/)路径下将数据库文件直接使用cp命令拷贝一份呢?反而要借助什么mysqldump工具,这是为什么?
因为数据库不仅仅是一个单独的文件,而是由多个文件和文件夹组成的复杂结构。这些文件包含着数据库表、索引、元数据等关键信息。直接使用cp命令复制这些文件可能会导致数据不一致、损坏、丢失。
注意:
如果我们要备份的不是一个完整数据库,而是某个数据库中的一个表该怎么办?
与备份数据库类似,只不过备份命令不用在叫-B选项;
语法:mysqldump -h ip -P port -p -u root d1 person > 备份路径 ;
eg:
接着我们还原:
首先我们还原的是一张表,因此我们就必须在一个数据库中,这个数据库可以不是原数据库,但是必须是一个数据库,接着我们在数据库中进行source 还原路径;进行还原!
>

同时备份多个数据库:
mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径
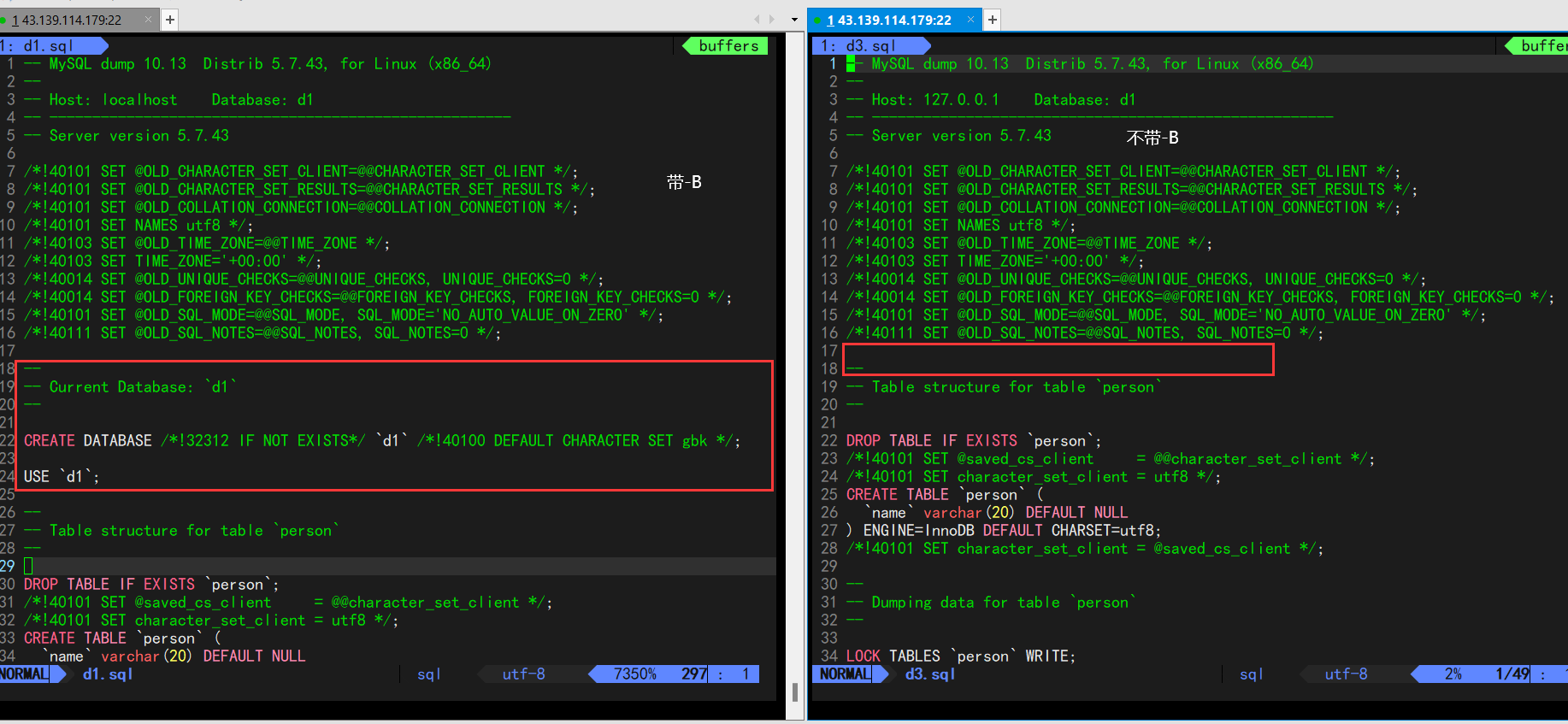
如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据
库,再使用source来还原。为什么?
我们来看一看对于同一个数据库,带-B备份和不带-B备份的差别:
从两个备份文件中,我们可以看见,带-B的备份文件在备份的时候会将创建数据库的语句也备份下来,而不带-B的备份文件不会将创建数据库的语句备份下来,因此当我们对d1.sql执行还原操作的时候mysql客户端会根据d1.sql的第一句还原语句还原出数据库,而还原d3.sql的时候则不会,而是直接进行还原表的操作,因此这也就是为什么当我们还原不带-B的数据库备份文件时需要先创建一个数据库的原因了!
查看连接情况
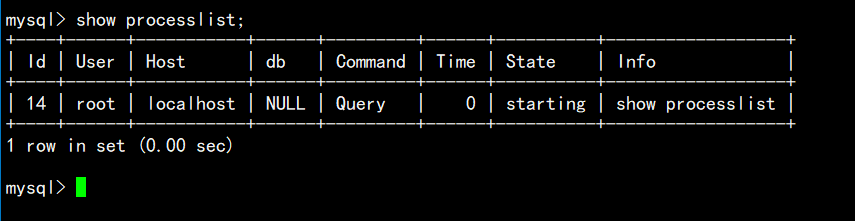
show processlist;
可以告诉我们当前有哪些用户连接到我们的MySQL,如果查出某个用户不是你正常登陆的,很有可能你的数据库被人入侵了。以后当我们发现自己数据库比较慢时,可以用这个指令来查看数据库连接情况。