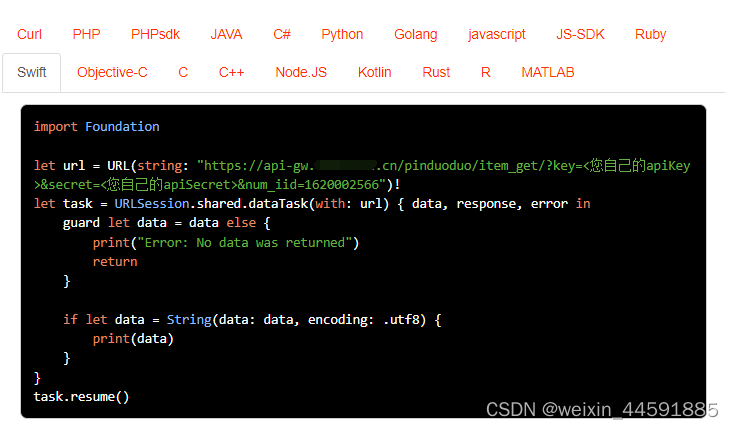
目录结构
注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下:
1、参考书籍:《Oracle Database SQL Language Reference》
2、参考书籍:《PostgreSQL中文手册》
3、EDB Postgres Advanced Server User Guides,点击前往
4、PostgreSQL数据库仓库链接,点击前往
5、PostgreSQL中文社区,点击前往
6、Oracle Real Application Testing 官网首页,点击前往
7、Oracle 21C RAT Testing Guide,点击前往
8、Oracle Database 19c:Real Application Testing Overview,点击前往
9、数据库回放白皮书 11g,点击前往
10、论文一 原文地址,点击前往
1、本文内容全部来源于开源社区 GitHub和以上博主的贡献,本文也免费开源(可能会存在问题,评论区等待大佬们的指正)
2、本文目的:开源共享 抛砖引玉 一起学习
3、本文不提供任何资源 不存在任何交易 与任何组织和机构无关
4、大家可以根据需要自行 复制粘贴以及作为其他个人用途,但是不允许转载 不允许商用 (写作不易,还请见谅 💖)
Oracle数据库数据库回放功能之论文一翻译及学习
- 文章快速说明索引
- 摘要
- 简介
- 数据库重放架构
- 捕获生产工作负载
- 重放生产工作负载
- 演示
- 示范应用
- 测试策略
- 数据库同步重放
- 不同步测试

文章快速说明索引
学习目标:
目的:接下来这段时间我想做一些兼容Oracle数据库Real Application Testing (即:RAT)上的一些功能开发,本专栏这里主要是学习以及介绍Oracle数据库功能的使用场景、原理说明和注意事项等,基于PostgreSQL数据库的功能开发等之后 由新博客进行介绍和分享!
学习内容:(详见目录)
1、Oracle数据库数据库回放功能之论文一翻译及学习
学习时间:
2023年08月18日 22:17:23
学习产出:
1、Oracle数据库Real Application Testing之真实应用测试概述白皮书
2、CSDN 技术博客 1篇
注:下面我们所有的学习环境是Centos7+PostgreSQL15.0+Oracle19c+MySQL5.7
postgres=# select version();version
-----------------------------------------------------------------------------PostgreSQL 15.0 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.1.0, 64-bit
(1 row)postgres=##-----------------------------------------------------------------------------#SQL> select * from v$version; BANNER BANNER_FULL BANNER_LEGACY CON_ID
--------------------------------------------------------------------------- --------------------------------------------------------------------------- --------------------------------------------------------------------------- ----------
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production 0Version 19.3.0.0.0SQL>
#-----------------------------------------------------------------------------#mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.19 |
+-----------+
1 row in set (0.06 sec)mysql>
摘要
本文介绍了 Oracle Database Replay,这是一种测试信息系统的 关系数据库管理系统 组件更改(软件升级、硬件更改等)的新颖方法。数据库重放使测试系统能够承受真实的生产系统工作负载,这有助于在生产系统上实施计划的更改之前识别所有潜在问题。可以以最小的代价来捕获 生产数据库系统 的任何有趣的工作负载周期。捕获的工作负载可用于驱动测试系统,与此同时还可以保持实际生产工作负载的 并发性和负载特性。因此,使用数据库重放的测试结果可以在应用这些更改之前确定更改对生产系统的影响提供非常高的保证。本文介绍了数据库重放的体系结构以及证明其作为测试方法的有用性的实验结果。
本文同时展示了维护实际工作负载的并发性和负载特性的重要性。如下:
问题:当前的测试解决方案不允许基于数据依赖性的同步。如果没有适当的同步,演示工作负载就无法执行所需的工作,也无法适当地运行测试系统,从而导致覆盖范围差和负载不足。因此,许多问题仍未被发现
方案:数据库重放及其基于数据的同步使测试变得现实以及潜在问题的发现
简介
对生产系统的任何潜在更改(例如升级数据库或修改配置)都需要进行广泛的测试和验证,然后才能应用这些更改。为了在生产系统中实施更改之前有信心,需要将测试系统暴露在与生产环境中经历的工作负载非常相似的工作负载中。使用当前技术,产生模仿生产工作负载的工作负载几乎是不可能的。
因此,当前的测试方法常常无法预测经常困扰生产系统变化的问题。于是在大多数信息系统环境中,生产系统的任何变化都非常不情愿。
Oracle Database Replay 彻底改变了数据库测试。它允许记录生产系统上的生产工作负载,同时对性能影响最小。捕获的工作负载包含捕获期间向 RDBMS 发出的所有请求以及其所有的并发和事务信息。
然后,人们可以使用捕获的工作负载去驱动任何测试系统,并在生产中实施之前测试任何更改。
数据库重放生成的工作负载准确地再现了测试系统上生产工作负载的并发和负载特征。因此,使用真实工作负载进行测试可确保在生产 RDBMS 中实施更改时不会出现意外。
该演示强调了使用真实工作负载来测试数据库更改的重要性。数据库重放引入的一项重大技术突破是:一种根据数据依赖性同步重放捕获的请求的方法,这会在测试系统上产生与生产工作负载 几乎相同 的工作负载。这确保每个重放的请求对与捕获时相同的数据进行操作,因此执行与生产系统中相同的工作量。使用真实世界的应用程序架构,我们证明,如果没有基于数据的同步,工作负载就无法用于预测生产系统的潜在变化。
数据库重放架构
数据库重放允许记录生产系统上的真实工作负载,同时对性能影响最小。捕获的工作负载包含捕获期间向 RDBMS 发出的所有请求以及所有并发和事务信息。在测试系统上,数据库重放可以完全按照在生产系统上运行的方式去执行捕获的工作负载,以在生产系统中实施之前测试任何更改。因此,对 RDBMS 的任何更改都可以使用数据库重放进行测试。
例如,可以在将以下更改应用于生产系统之前对其进行测试:
- RDBMS 软件升级和补丁
- 索引和分区更改
- 所有配置更改
- 以及底层操作系统或硬件的任何更改
在重放期间,可以充分利用所有现有的 Oracle 诊断工具来诊断和修复问题,因为 RDBMS 仍然接受并服务不属于重放工作负载的请求。
捕获生产工作负载
Oracle 11g 允许任何正在运行的 RDBMS 实例开始捕获接下来的工作负载。用户需要选择一个感兴趣的工作负载周期,并在捕获工作负载之前为该工作负载找到足够的磁盘空间。工作负载存储在操作系统文件中用户指定的目录里。对生产系统的影响很小,从生产应用程序的角度来看,RDBMS 继续正常运行。捕获基础设施对运行系统的开销很小(TPC-C 吞吐量下降高达 4.5%),并且与工作负载相关。即使在捕获错误或磁盘空间不足的情况下,生产系统也不会受到影响。
通过使用特殊代码(捕获探针 the capture probes)来检测 RDBMS 内核,可以捕获工作负载,这些代码在捕获期间执行并收集重放所需的所有数据。这些探针生成独立于平台和协议的数据,使捕获的工作负载能够在运行 Oracle 数据库的任何硬件或操作系统平台上重放。RDBMS 中的每个服务器进程(server process)都会将其活动捕获存储在捕获目录中的操作系统文件中。不会捕获来自后台进程(例如维护任务或调度程序作业)的工作负载,因为在重放时,它将由捕获的前台工作负载自动触发。
捕获的内容足以在测试系统上启用重放和确定其之后的成功。工作负载捕获单元(数据库调用 a databse call)是 重放请求 和 在测试系统上验证其结果 所需的最少量信息。数据库调用包含以下类别的数据:
- 用户数据:这是从客户端发送到 RDBMS 的数据。示例包括 SQL 文本、
host variables、获取fetch请求和执行execution请求 - 服务器响应数据:这是从服务器发送回用户的数据。结果集占该数据流的大部分。但是,不会捕获结果集,因为这会在捕获期间产生过高的开销。相反,会捕获数据库中执行的工作的概要:受影响的行
rows affected和错误代码error codes。这足以确定重放调用的结果 - 系统数据:该数据是RDBMS内核的内部数据,不会返回给用户,但需要重放同步
replay synchronization和运行时数据替换
可以通过工作负载过滤器的定义对捕获进行微调。用户可以通过设置会话属性、用户 ID 和其他工作负载特定属性的过滤器来指定要在捕获的数据中 排除或包含 工作负载的哪一部分。用户完成工作负载捕获后,可以将捕获的工作负载移动到可以重放的测试系统。
重放生产工作负载
生产工作负载的重放旨在对测试系统上的 RDBMS 施加压力,以确定测试系统配置(system configuration)是否适合在生产环境中使用。一般来说,任何类型的测试都包含 4 个不同的阶段:
- 设置测试系统
- 定义测试工作负载
- 运行工作负载
- 分析结果
使用数据库重放时,不需要执行耗时的步骤2(预处理),因为工作负载已明确定义:它是在生产系统上捕获的。
在测试系统设置开始时,数据库状态需要恢复到逻辑上与捕获开始时 相同 的状态。Oracle 提供了多种工具来完成此任务。重放开始之前要完成的最后一步是工作负载的处理(指的是 预处理),这将创建重放同步和运行时重新映射所需的必要元数据,并且只需完成一次。然后,可以根据需要多次重放已处理的工作负载。
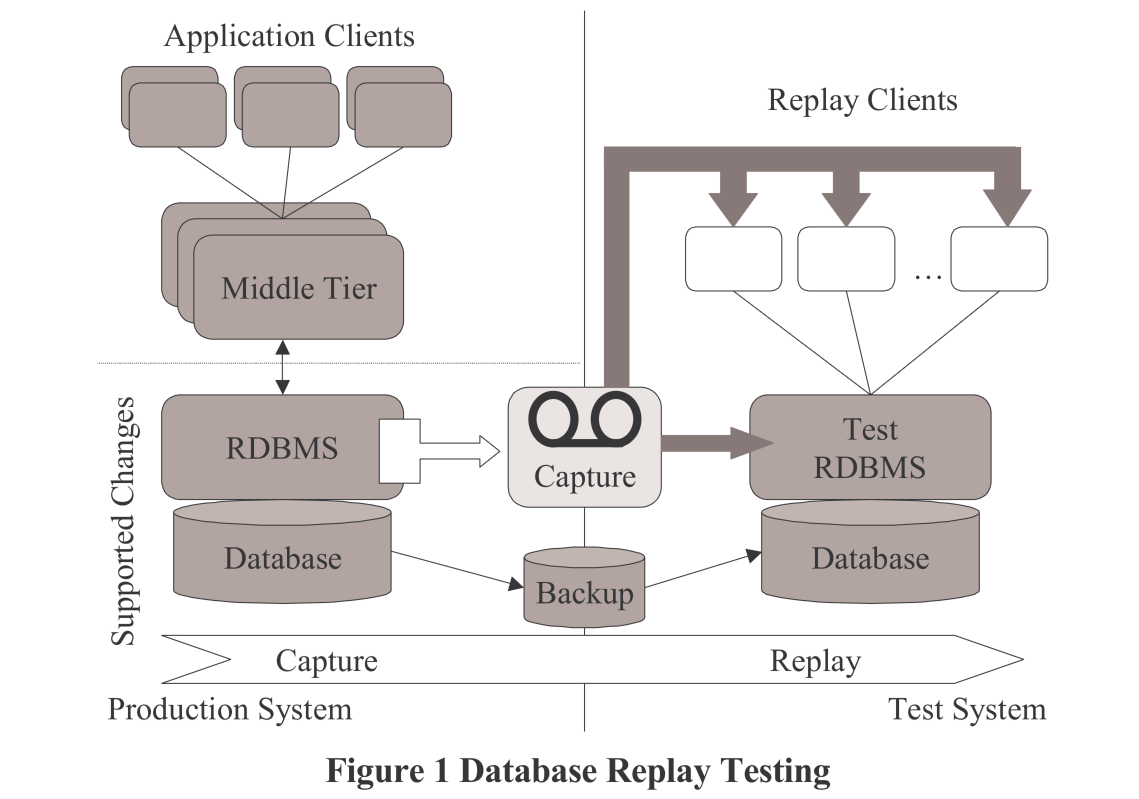
通过将捕获的工作负载发送到测试 RDBMS 来执行重放。为此,我们使用在一个或多个主机系统上运行的一个或多个重放客户端。重放客户端是一个特殊的可执行文件,它读取捕获的工作负载并将其提交到数据库。所需的重放客户端和主机的数量由捕获的工作负载的最大并发数决定,并且可以使用提供的实用程序进行估计。重放客户端替换了捕获期间存在的原始客户端(图 1)。
启动重放客户端后,用户可以开始重放。此时,服务器会向所有连接的客户端发送一条消息,以便它们可以开始发出工作负载。在重放期间,重放客户端读取捕获的工作负载并将其转换为对数据库的适当请求。
RDBMS 为每个客户端分配一部分工作负载。所有重放客户端生成的聚合工作负载准确地模拟了生产工作负载。例如,如果在捕获期间有 10000 个用户连接到 RDBMS,则在重放期间,这 10000 个用户将按照相同的连接和请求模式进行连接。因此,测试 RDBMS 在捕获期间承受与生产系统相同的负载和请求率。此外,RDBMS 通过维护捕获期间看到的数据依赖性,确保重放的请求执行有意义的工作。例如,如果请求在捕获期间更新了 10000 行,则在重放期间,RDBMS 将确保该请求在插入这 10000 行的上一个请求之后执行。结果是,使用捕获和重放测试可以使测试系统承受生产工作负载并执行高度真实的测试。
每个重放客户端都是一个多线程应用程序,它为每个捕获的会话文件生成一个线程(重放线程 the replay thread)。重放线程读取捕获的工作负载文件并将数据转换为对 RDBMS 的服务调用。重放线程通过在两个连续调用之间适当地休眠来维护捕获的计时特性。目标是维持捕获的请求速率,除非重放选项另有指定。
重要 重要 重要:重放期间 思考时间(think time)的保留不足以维持适当的数据依赖性,因为它无法保证 RDBMS 将以适当的顺序服务请求。
我们对每个重放请求的主要目标是使其执行与捕获期间相同的工作,如果各种请求的执行顺序不一致,因此操作的数据库快照与它们在捕获期间操作的数据不同,则这一点可能会受到影响。
因此,为了确保每个重放的请求执行相同的工作,重放下的 RDBMS 确保它对 与捕获期间相同的数据 进行操作。这是通过强制执行捕获期间观察到的提交顺序来实现的,方法是允许每个重放的调用仅在重放了适当的提交之后执行。
除了重放时间同步之外,重放还采用运行时重新映射技术来促进具有从生产系统到测试系统不同的系统特定数据的请求的重放。Replay 还使用一种方法来适当地重新创建唯一编号(序列)生成器的值。(详细信息超出了本文的范围)
尽管付出了很大努力来确保重放调用在重放期间执行与捕获期间相同的工作,但在某些情况下,重放调用可能会影响(更新/返回 update/return)不同的数据并遇到错误(数据和错误分歧 Data and Error Divergence)。数据库重放通过比较 SQL 执行影响或返回的行数以及从捕获到重放的错误代码差异来检测数据分歧。重放报告中广泛报告了分歧数据,该报告用于评估给定重放的有效性。
重放完成后,可以使用多个报告并利用各种 Oracle 实用程序来执行工作负载分析。重放报告提供高级性能概述和差异报告,可用于确定重放是否执行与生产工作负载类似的工作。为了进一步分析性能特征并诊断性能问题,可以使用现有的完善的 Oracle 功能,例如自动数据库诊断监视器 (ADDM) 或自动工作负载存储库 (AWR) 报告。
演示
我们的演示基于一个现实世界的应用程序,该应用程序具有对数据库的高度并发和同步访问。我们展示了此工作负载的重放如何以类似于生产工作负载的实际方式加载测试 RDBMS,而其他无法 重新创建适当的数据依赖关系 的工具将无法生成足够的负载。
示范应用
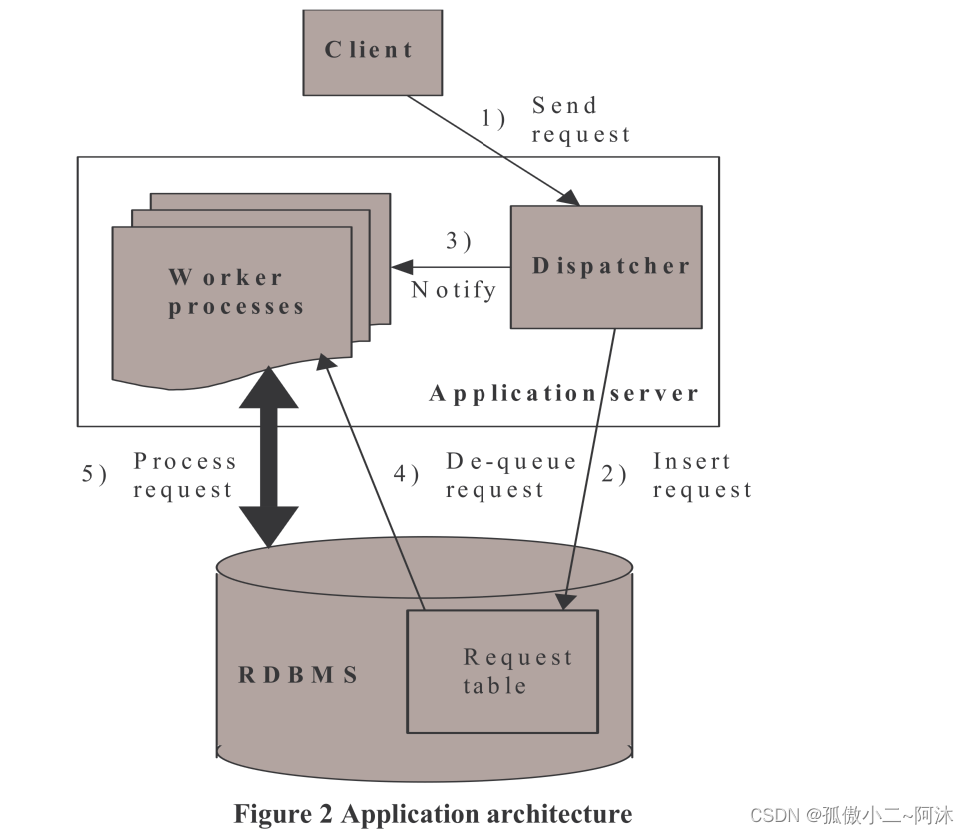
我们的演示应用程序如 图2 所示。它使用异步后台处理架构,类似于 SAP 使用的架构。
应用程序逻辑驻留在应用程序服务器上,而 RDBMS 负责应用程序数据和持久请求。调度程序和工作进程以并发方式处理传入的客户端请求。
如 图2 所示,当客户端向调度程序发送请求时(步骤 1),调度程序将其放入数据库表中 (2) 并通知客户端其请求已被接受。然后调度程序选择一个空闲的工作进程来处理给定的请求ID (3)。工作进程将请求从表 (4) 中出列并开始处理,这涉及对数据库中的应用程序数据的更多访问(5)。
测试策略
RDBMS 看到的工作负载是由 用于将请求 入队/出队 的 DML/Queries 以及 实际处理中使用的 DML/Queries 组成。为了针对 测试数据库 真实地重新创建此工作负载,有必要以某种方式模拟工作进程和调度程序进程的行为,而不实际运行应用程序(指的是:真实的应用)。
这并不容易做到。现有的数据库负载测试工具(如 Quest Benchmark Factory [4])生成合成的、手动编辑的工作负载。综合工作负载可能包含 图2 中所示的步骤 (2)、(4) 和 (5) 中发送的一些请求,但无法捕获与 RDBMS 的所有交互。最重要的是,它们无法准确地对请求之间的依赖关系进行建模。
例如,在没有同步的情况下测试我们的演示应用程序时,可能会出现 出队请求在其相应的插入请求之前在服务器上执行 的情况。这是可能的,因为通用负载测试工具不会对请求依赖关系进行建模。在这种情况下,出队请求将失败,代表该请求的所有后续处理也将失败。此类人为错误并不代表生产工作负载,因此限制了负载测试的有效性。
我们的演示将比较同步与非同步测试,并展示数据库重放 如何利用生产工作负载的数据依赖性作为事务处理的一部分 反映在数据库中并作为工作负载捕获的一部分记录这一事实。使用此信息,Database Replay 可以重新创建 RDBMS 在生产环境中看到的相同服务模式。更具体地说,它确保准确地重新创建与每个客户端、调度程序和工作进程相对应的数据库工作负载部分,并在测试 RDBMS 上执行与在生产系统中捕获期间执行的相同工作量。
数据库同步重放
数据库重放使我们能够测试和评估应用程序 数据库部分 的更改,而不会遇到并发问题。事实上,我们新颖的同步基础设施可确保在插入表之前不会将任何请求出队和删除。这样,工作进程在数据库中的负载总能找到它要查找的数据,并将与原始负载相同的负载应用于测试系统。接下来的段落将解释这是如何实现的。
捕获的系统会记录每个数据库调用的一些系统更改号 (SCN system change number),这些系统更改号描述了被捕获的调用执行时的数据库状态。SCN是一个戳,它定义了数据库在特定时间点的已提交版本。Oracle为每个提交的事务分配一个唯一的SCN。这些scn用于确保数据库服务器内的隔离和读取一致性。每个捕获的调用都包含与调用开始执行时的数据库状态对应的SCN。这个SCN被称为等待SCN。此外,每个提交操作都包含 提交SCN,该SCN对应于提交操作之后和任何后续提交操作之前的数据库状态。
捕获的 提交SCN值 用于在重放期间维护重放时钟(replay clock)。重放时钟与模拟时钟类似,因为它是由特定事件推进的。在重放的情况下,这些事件是提交操作。每个提交操作都会将时钟设置为其提交SCN和当前时钟的最大值。每个重放调用(提交和非提交操作)都会观察重放时钟。在每次调用开始时的重放期间,执行该调用的服务器进程会检查重放时钟的值。如果重放调用的 等待SCN 小于或等于重放时钟,则允许执行该调用。否则,调用将被阻塞,等待时钟推进发布(即提交操作)。这会在重放期间强制执行与捕获期间相同的提交顺序。
在我们的示例应用程序中,单个请求的处理方式如下。在捕获期间,当客户端请求插入表中并提交时,我们还会记录与此提交关联的SCN(提交SCN)以及此操作完成的时间。当工作进程将请求出队并从该表中删除时,我们通过此操作记录数据库中的当前SCN(等待SCN)以及当前时间。该等待 SCN 值(我们将称为 W)必然大于或等于与插入请求(insert request)操作关联的提交 SCN 值(我们将称为 C),因为它稍后发生。
在重放期间,我们的重放客户端读取捕获文件,并根据每个操作记录的时间戳将记录的操作发送到数据库服务器。在数据库内部,如果发生出队请求(de-queue request)操作尝试在插入请求(insert request)操作完成之前执行,同步基础设施将使其等待。实际上,重放时钟将严格小于 C,因为插入请求(insert request)操作尚未完成执行和提交,因此尚未将时钟移动到至少等于其提交 SCN。并且因为我们已经确定出队请求(de-queue request)操作的等待SCN W大于或等于C,所以W必然大于重放时钟。因此,它至少会阻塞,直到插入请求(insert request)操作完成并提交其工作,这正是处理请求所需要的。
最后,重放客户端以与捕获期间相同的时间发出调用,这一事实确保了出队列请求(de-queue request)操作将很快到达数据库,从而使请求不会超时(如果在捕获期间没有超时)。
不同步测试
如果一个工具不提供像我们刚刚描述的那样的数据感知同步(synchronization)功能,然后被用于重放我们的应用程序工作负载,那么它只能依靠计时来将调用发送到数据库服务器。在高并发负载下,肯定一些出队请求(de-queue request)调用在其相应的插入请求(insert request)完成提交之前最终被执行;此请求的所有后续工作线程调用都将无效,并且请求本身将超时。因此,相当数量的请求将不会得到处理,从而导致如下问题:
A possibly lighter and different load profile than the one that should have been applied.
为了突出这些问题,我们只需简单地使用关闭了同步特性的数据库重放工具(指的是:非synchronization 即:TIME),并将该时期的一些性能报告与捕获期和同步重放期的性能报告进行比较。虽然捕获和同步重放周期看起来很相似,但非同步重放周期却截然不同,负载轻得多,显然不适合得出关于生产系统的结论。
出这些问题,我们只需简单地使用关闭了同步特性的数据库重放工具(指的是:非synchronization 即:TIME),并将该时期的一些性能报告与捕获期和同步重放期的性能报告进行比较。虽然捕获和同步重放周期看起来很相似,但非同步重放周期却截然不同,负载轻得多,显然不适合得出关于生产系统的结论。