- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:Pytorch实战 | 第P3周:彩色图片识别:天气识别
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
目录
- 环境
- 步骤
- 环境设置
- 数据准备
- 模型设计
- 模型训练
- 结果展示
- 总结与心得体会
环境
- 系统: Linux
- 语言: Python3.8.10
- 深度学习框架: Pytorch2.0.0+cu118
步骤
环境设置
首先是包引用
import torch # pytorch主包
import torch.nn as nn # 模型相关的包,创建一个别名少打点字
import torch.optim as optim # 优化器包,创建一个别名
import torch.nn.functional as F # 可以直接调用的函数,一般用来调用里面在的激活函数from torch.utils.data import DataLoader, random_split # 数据迭代包装器,数据集切分
from torchvision import datasets, transforms # 图像类数据集和图像转换操作函数import matplotlib.pyplot as plt # 图表库
from torchinfo import summary # 打印模型结构
查询当前环境的GPU是否可用
print(torch.cuda.is_available())

创建一个全局的设备对象,用于使各类数据处于相同的设备中
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 当GPU不可用时,使用CPU# 如果是Mac系统可以多增加一个if条件,启用mps
if torch.backends.mps.is_available():device = torch.device('mps')
数据准备
这次的天气图像是由K同学提供的,我提前下载下来放在了当前目录下的data文件夹中
加载文件夹中的图像数据集,要求文件夹按照不同的分类并列存储,一个简要的文件树为
datacloudyrainshinesunrise
使用torchvisio.datasets中的方法加载自定义图像数据集,可以免除一些文章中推荐的自己创建Dataset,个人感觉十分方便,而且这种文件的存储结构也兼容keras框架。
首先我们使用原生的PythonAPI来遍历一下文件夹,收集一下分类信息
import pathlibdata_lib = pathlib.Path('data')
class_names = [f.parts[-1] for f in data_lib.glob('*')] # 将data下级文件夹作为分类名
print(class_names)

在所有的图片中随机选择几个文件打印一下信息。
import numpy as np
from PIL import Image
import randomimage_list = list(data_lib.glob('*/*'))
for _ in range(10):print(np.array(Image.open(random.choice(image_list))).shape)

通过打印图像信息,发现图像的大小并不一致,需要在创建数据集时对图像进行缩放到统一的大小。
transform = transforms.Compose([transforms.Resize([224, 224]), # 将图像都缩放到224x224transforms.ToTensor(), # 将图像转换成pytorch tensor对象
]) # 定义一个全局的transform, 用于对齐训练验证以及测试数据
接下来就可以正式从文件夹中加载数据集了
dataset = datasets.ImageFolder('data', transform=tranform)
现在把整文件夹下的所有文件加载为了一个数据集,需要根据一定的比例划分为训练和验证集,方便模型的评估
train_size = int(len(dataset) *0.8) # 80% 训练集 20% 验证集
eval_size = len(dataset) - train_sizetrain_dataset, eval_dataset = random_split(dataset, [train_size, eval_size])
创建完数据集,打印一下数据集中的图像
plt.figure(figsize=(20, 4))
for i in range(20):image, label = train_dataset[i]plt.subplot(2, 10, i+1)plt.imshow(image.permute(1,2,0)) # pytorch的tensor格式为N,C,H,W,在imshow展示需要将格式变成H,W,C格式,使用permute切换一下plt.axis('off')plt.title(class_names[label])

最后用DataLoader包装一下数据集,方便遍历
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
eval_loader = DataLoader(eval_loader, batch_size=batch_size)
模型设计
使用一个带有BatchNorm的卷积神经网络来处理分类问题
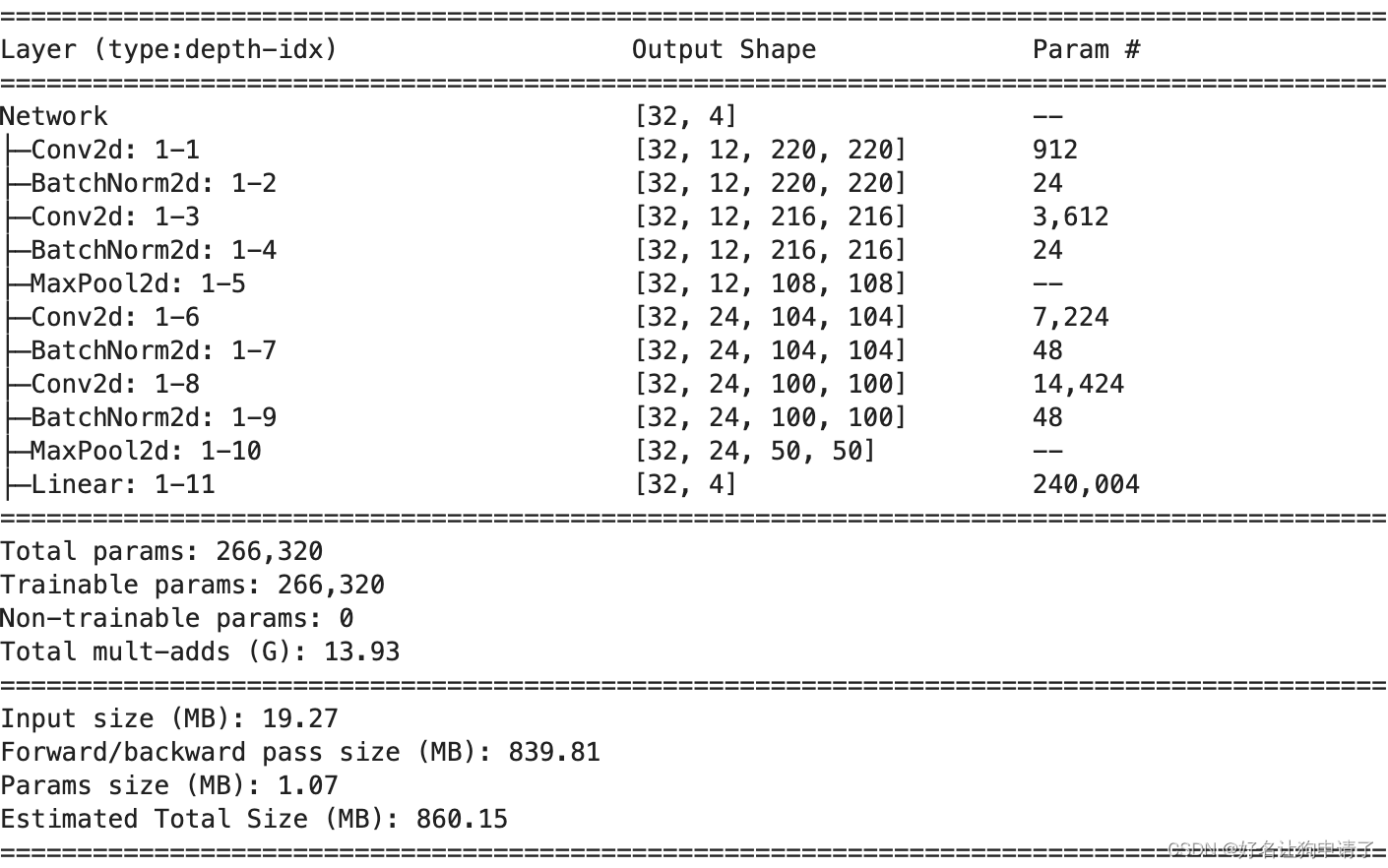
class Network(nn.Module):def __init__(self, num_classes):super().__init__()self.conv1 = nn.Conv2d(3, 12, kernel_size=5, strides=1)self.conv2 = nn.Conv2d(12, 12, kernel_size=5, strides=1)self.conv3 = nn.Conv2d(12, 24, kernel_size=5, strides=1)self.conv4 = nn.Conv2d(24, 24, kernel_size=5, strides=1)self.maxpool = nn.MaxPool2d(2)self.bn1 = nn.BatchNorm2d(12)self.bn2 = nn.BatchNorm2d(12)self.bn3 = nn.BatchNorm2d(24)self.bn4 = nn.BatchNorm2d(24)# 224 [-> 220 -> 216 -> 108] [-> 104 -> 100 -> 50]self.fc1 = nn.Linear(50*50*24, num_classes)def forward(self, x):x = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x)))x = self.maxpool(x)x = F.relu(self.bn3(self.conv3(x)))x = F.relu(self.bn4(self.conv4(x)))x = self.maxpool(x)x = x.view(x.size(0), -1)x = self.fc1(x)return xmodel = Network(len(class_names)).to(device) # 别忘了把定义的模型拉入共享中
summary(model, input_size=(32, 3, 224, 224))
模型训练
首先定义一下每个epoch内训练和评估的逻辑
def train(train_loader, model, loss_fn, optimizer):train_size = len(train_loader.dataset)num_batches = len(train_loader)train_loss, train_acc = 0, 0for x, y in train_loader:x, y = x.to(device), y.to(device)preds = model(x)loss = loss_fn(preds, y)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()train_acc += (preds.argmax(1) == y).type(torch.float).sum().item()train_loss /= num_batchestrain_acc /= train_sizereturn train_loss, train_accdef eval(eval_loader, model, loss_fn):eval_size = len(eval_loader.dataset)num_batches = len(eval_loader)eval_loss, eval_acc = 0, 0for x, y in eval_loader:x, y = x.to(device), y.to(device)preds = model(x)loss = loss_fn(preds, y)eval_loss += loss.item()eval_acc += (preds.argmax(1) == y).type(torch.float).sum().item()eval_loss /= num_batcheseval_acc /= eval_sizereturn eval_loss, eval_acc
然后编写代码进行训练
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
epochs = 10train_loss, train_acc = [], []
eval_loss, eval_acc =[], []
for epoch in range(epochs):model.train()epoch_train_loss, epoch_train_acc = train(train_loader, model, loss_fn, optimizer)model.eval()model.no_grad():epoch_eval_loss, epoch_eval_acc = test(eval_loader, model, loss_fn)
结果展示

基于训练和测试数据展示结果
range_epochs = range(len(train_loss))
plt.figure(figsize=(12, 4))
plt.subplot(1,2,1)
plt.plot(range_epochs, train_loss, label='train loss')
plt.plot(range_epochs, eval_loss, label='validation loss')
plt.legend(loc='upper right')
plt.title('Loss')plt.subplot(1,2,2)
plt.plot(range_epochs, train_acc, label='train accuracy')
plt.plot(range_epochs, eval_acc, label='validation accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')
总结与心得体会
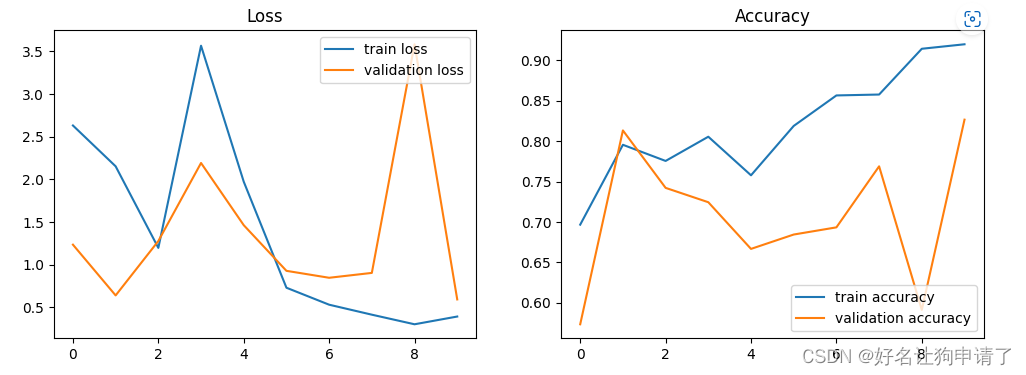
通过对训练过程的观察,训练过程中的数据波动很大,并且验证集上的最好正确率只有82%。
目前行业都流行小卷积核,于是我把卷积核调整为了3x3,并且每次卷积后我都进行池化操作,直到通道数为64,由于天气识别时,背景信息也比较重要,高层的卷积操作后我使用平均池化代替低层使用的最大池化,加大了全连接层的Dropout惩罚比重,用来抑制过拟合问题。最后的模型如下:
class Network(nn.Module):def __init__(self, num_classes):super().__init__()self.conv1 = nn.Conv2d(3, 16, kernel_size=3)self.conv2 = nn.Conv2d(16, 32, kernel_size=3)self.conv3 = nn.Conv2d(32, 64, kernel_size=3)self.conv4 = nn.Conv2d(64, 64, kernel_size=3)self.bn1 = nn.BatchNorm2d(16)self.bn2 = nn.BatchNorm2d(32)self.bn3 = nn.BatchNorm2d(64)self.bn4 = nn.BatchNorm2d(64)self.maxpool = nn.MaxPool2d(2)self.avgpool = nn.AvgPool2d(2)self.dropout = nn.Dropout(0.5)# 224 -> 222-> 111 -> 109 -> 54 -> 52 -> 50 -> 25self.fc1 = nn.Linear(25*25*64, 128)self.fc2 = nn.Linear(128, num_classes)def forward(self, x):x = F.relu(self.bn1(self.conv1(x)))x = self.maxpool(x)x = F.relu(self.bn2(self.conv2(x)))x = self.avgpool(x)x = F.relu(self.bn3(self.conv3(x)))x = F.relu(self.bn4(self.conv4(x)))x = self.avgpool(x)x = x.view(x.size(0), -1)x = self.dropout(x)x = F.relu(self.fc1(x))x = self.dropout(x)x = self.fc2(x)return x
然后增大训练的epochs为30,学习率降低为1e-4
optimizer = optim.Adam(model.parameters(), lr=1e-4)
epochs = 30
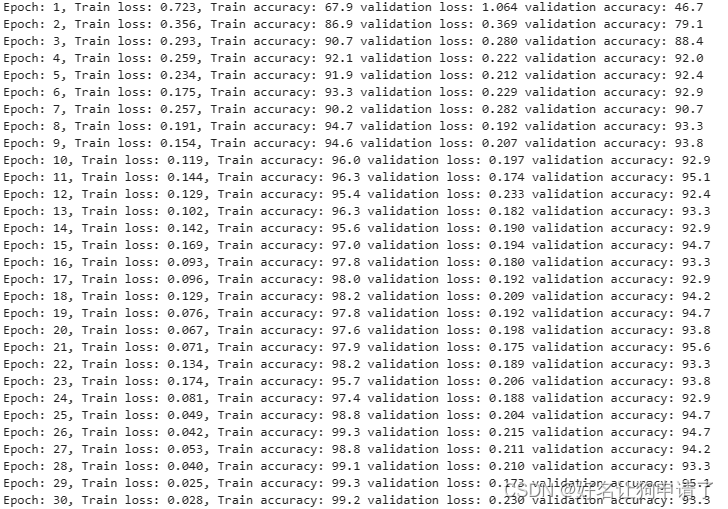
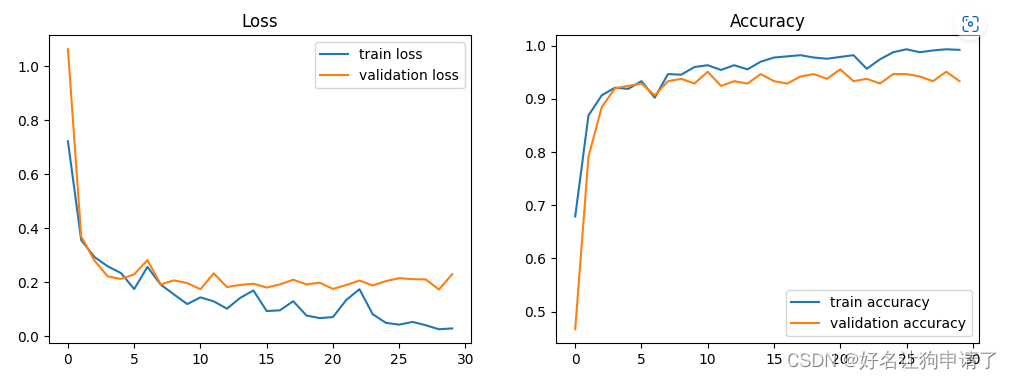
训练结果如下
可以看到,验证集上的正确率最高达到了95%以上
在数据集中随机选取一个图像进行预测展示
image_path = random.choice(image_list)
image_input = transform(Image.open(image_path))
image_input = image_input.unsqueeze(0).to(device)
model.eval()
pred = model(image_input)plt.figure(figsize=(5, 5))
plt.imshow(image_input.cpu().squeeze(0).permute(1,2,0))
plt.axis('off')
plt.title(class_names[pred.argmax(1)])
结果如下