论文信息
标题: Dynamic Snake Convolution based on Topological Geometric Constraints for Tubular Structure Segmentation
作者: 戚耀磊、何宇霆、戚晓明、张媛、杨冠羽
会议: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
发表时间: 2023年10月
论文链接: arXiv:2307.08388
关键词: 动态蛇形卷积、拓扑几何约束、管状结构分割

创新点
该论文提出了一种新的动态蛇形卷积(Dynamic Snake Convolution, DSCNet)方法,主要创新点包括:
-
动态蛇形卷积(DSConv): 通过自适应聚焦细长和曲折的局部结构,增强对管状特征的捕捉能力。
-
多视角特征融合策略: 结合来自不同视角的信息,确保在特征融合过程中保留重要的全局形态信息。
-
拓扑连续性约束损失函数(TCLoss): 基于持久同调的方法,增强分割结果的拓扑连续性。
方法
论文的方法主要分为三个阶段:
-
特征提取: 采用动态蛇形卷积,专注于细长和弯曲的局部结构,以准确捕捉管状特征。
-
特征融合: 通过多视角特征融合策略,整合来自不同视角的信息,确保在特征融合过程中保留重要的细节。
-
损失约束: 引入拓扑连续性约束损失函数,以确保分割结果的拓扑结构连续性。

动态蛇形卷积
一、原理
动态蛇形卷积(Dynamic Snake Convolution, DSC)是一种新型的卷积操作,旨在提高对细长和复杂管状结构(如血管和道路)的特征提取能力。其设计灵感来源于生物医学中的“活性轮廓”模型,特别适用于处理具有复杂几何形状和拓扑结构的图像。
-
自适应卷积核: 动态蛇形卷积通过引入变形偏移(deformation offsets),使卷积核能够根据输入数据的特征动态调整其形状和大小。这种灵活性使得卷积核能够更好地聚焦于细长和曲折的局部结构。
-
连续性约束: 为了避免卷积核在处理细长结构时偏离目标,DSC引入了连续性约束。每个卷积位置的选择依赖于前一个位置,确保卷积核的运动是连续的,类似于蛇的移动方式。这种设计可以有效捕捉细小的结构特征,减少分割结果中的断裂现象。
二、结构
动态蛇形卷积的结构主要包括以下几个部分:
-
卷积核设计: DSC的卷积核不是固定的,而是根据输入数据的特征动态调整。以一个标准的3x3卷积核为例,卷积核的每个位置可以通过变形偏移来改变其位置,从而更好地适应目标的几何特征。
- 对于每个卷积核位置 ( K ),其位置可以表示为:
K i ± c = ( x i ± c , y i + Σ i i ± c Δ y ) K_{i \pm c} = (x_i \pm c, y_i + \Sigma_{i}^{i \pm c} \Delta y) Ki±c=(xi±c,yi+Σii±cΔy)
其中,( c ) 表示距离中心网格的水平距离, ( Δ y ) ( \Delta y ) (Δy) 是动态调整的偏移量。
- 对于每个卷积核位置 ( K ),其位置可以表示为:
-
特征提取与融合: DSC在特征提取阶段,通过动态卷积核自适应地聚焦于细长和曲折的局部结构,确保捕捉到管状结构的关键特征。在特征融合阶段,DSC结合来自不同视角的信息,增强对全局形态的理解。
-
损失约束: DSC还引入了基于持久同调的拓扑连续性约束损失函数,以确保分割结果的拓扑结构连续性。这一约束有助于提高分割的准确性和一致性。
动态蛇形卷积通过自适应的卷积核设计和连续性约束,显著提高了对细长和复杂管状结构的特征提取能力。其灵活性和适应性使其在医学图像处理和道路检测等领域具有广泛的应用前景。
效果
实验结果表明,DSCNet在管状结构分割任务上表现出色,尤其是在处理细小脆弱的局部结构和复杂多变的全局形态时,能够提供更好的准确性和连续性。
实验结果
在多个数据集上的实验结果显示,DSCNet相较于多种现有方法,提供了更高的分割准确性和更好的拓扑连续性。具体实验结果包括:
-
DRIVE视网膜数据集:
- Dice: 82.06%
- ACC: 96.87%
-
马萨诸塞州道路数据集(ROADS):
- Dice: 78.21%
-
3D心脏CCTA数据集:
- Dice提升: 1.31%
这些结果表明,DSCNet在捕捉细小管状结构的关键特征方面表现良好,具有重要的临床应用价值。
总结
该论文提出的动态蛇形卷积方法为管状结构的分割提供了一种新的思路,结合了动态卷积和拓扑几何约束,能够有效应对细长和复杂形态的挑战。通过多视角特征融合和拓扑连续性约束,DSCNet在准确性和连续性上均取得了显著的进展,为相关领域的研究提供了重要的参考和启示。
代码
# -*- coding: utf-8 -*-
import os
import torch
from torch import nn
import einops"""Dynamic Snake Convolution Module"""class DSConv_pro(nn.Module):def __init__(self,in_channels: int = 1,out_channels: int = 1,kernel_size: int = 9,extend_scope: float = 1.0,morph: int = 0,if_offset: bool = True,device: str | torch.device = "cuda",):"""A Dynamic Snake Convolution ImplementationBased on:TODOArgs:in_ch: number of input channels. Defaults to 1.out_ch: number of output channels. Defaults to 1.kernel_size: the size of kernel. Defaults to 9.extend_scope: the range to expand. Defaults to 1 for this method.morph: the morphology of the convolution kernel is mainly divided into two types along the x-axis (0) and the y-axis (1) (see the paper for details).if_offset: whether deformation is required, if it is False, it is the standard convolution kernel. Defaults to True."""super().__init__()if morph not in (0, 1):raise ValueError("morph should be 0 or 1.")self.kernel_size = kernel_sizeself.extend_scope = extend_scopeself.morph = morphself.if_offset = if_offsetself.device = torch.device(device)self.to(device)# self.bn = nn.BatchNorm2d(2 * kernel_size)self.gn_offset = nn.GroupNorm(kernel_size, 2 * kernel_size)self.gn = nn.GroupNorm(out_channels // 4, out_channels)self.relu = nn.ReLU(inplace=True)self.tanh = nn.Tanh()self.offset_conv = nn.Conv2d(in_channels, 2 * kernel_size, 3, padding=1)self.dsc_conv_x = nn.Conv2d(in_channels,out_channels,kernel_size=(kernel_size, 1),stride=(kernel_size, 1),padding=0,)self.dsc_conv_y = nn.Conv2d(in_channels,out_channels,kernel_size=(1, kernel_size),stride=(1, kernel_size),padding=0,)def forward(self, input: torch.Tensor):# Predict offset map between [-1, 1]offset = self.offset_conv(input)# offset = self.bn(offset)offset = self.gn_offset(offset)offset = self.tanh(offset)# Run deformative convy_coordinate_map, x_coordinate_map = get_coordinate_map_2D(offset=offset,morph=self.morph,extend_scope=self.extend_scope,device=self.device,)deformed_feature = get_interpolated_feature(input,y_coordinate_map,x_coordinate_map,)if self.morph == 0:output = self.dsc_conv_x(deformed_feature)elif self.morph == 1:output = self.dsc_conv_y(deformed_feature)# Groupnorm & ReLUoutput = self.gn(output)output = self.relu(output)return outputdef get_coordinate_map_2D(offset: torch.Tensor,morph: int,extend_scope: float = 1.0,device: str | torch.device = "cuda",
):"""Computing 2D coordinate map of DSCNet based on: TODOArgs:offset: offset predict by network with shape [B, 2*K, W, H]. Here K refers to kernel size.morph: the morphology of the convolution kernel is mainly divided into two types along the x-axis (0) and the y-axis (1) (see the paper for details).extend_scope: the range to expand. Defaults to 1 for this method.device: location of data. Defaults to 'cuda'.Return:y_coordinate_map: coordinate map along y-axis with shape [B, K_H * H, K_W * W]x_coordinate_map: coordinate map along x-axis with shape [B, K_H * H, K_W * W]"""if morph not in (0, 1):raise ValueError("morph should be 0 or 1.")batch_size, _, width, height = offset.shapekernel_size = offset.shape[1] // 2center = kernel_size // 2device = torch.device(device)y_offset_, x_offset_ = torch.split(offset, kernel_size, dim=1)y_center_ = torch.arange(0, width, dtype=torch.float32, device=device)y_center_ = einops.repeat(y_center_, "w -> k w h", k=kernel_size, h=height)x_center_ = torch.arange(0, height, dtype=torch.float32, device=device)x_center_ = einops.repeat(x_center_, "h -> k w h", k=kernel_size, w=width)if morph == 0:"""Initialize the kernel and flatten the kernely: only need 0x: -num_points//2 ~ num_points//2 (Determined by the kernel size)"""y_spread_ = torch.zeros([kernel_size], device=device)x_spread_ = torch.linspace(-center, center, kernel_size, device=device)y_grid_ = einops.repeat(y_spread_, "k -> k w h", w=width, h=height)x_grid_ = einops.repeat(x_spread_, "k -> k w h", w=width, h=height)y_new_ = y_center_ + y_grid_x_new_ = x_center_ + x_grid_y_new_ = einops.repeat(y_new_, "k w h -> b k w h", b=batch_size)x_new_ = einops.repeat(x_new_, "k w h -> b k w h", b=batch_size)y_offset_ = einops.rearrange(y_offset_, "b k w h -> k b w h")y_offset_new_ = y_offset_.detach().clone()# The center position remains unchanged and the rest of the positions begin to swing# This part is quite simple. The main idea is that "offset is an iterative process"y_offset_new_[center] = 0for index in range(1, center + 1):y_offset_new_[center + index] = (y_offset_new_[center + index - 1] + y_offset_[center + index])y_offset_new_[center - index] = (y_offset_new_[center - index + 1] + y_offset_[center - index])y_offset_new_ = einops.rearrange(y_offset_new_, "k b w h -> b k w h")y_new_ = y_new_.add(y_offset_new_.mul(extend_scope))y_coordinate_map = einops.rearrange(y_new_, "b k w h -> b (w k) h")x_coordinate_map = einops.rearrange(x_new_, "b k w h -> b (w k) h")elif morph == 1:"""Initialize the kernel and flatten the kernely: -num_points//2 ~ num_points//2 (Determined by the kernel size)x: only need 0"""y_spread_ = torch.linspace(-center, center, kernel_size, device=device)x_spread_ = torch.zeros([kernel_size], device=device)y_grid_ = einops.repeat(y_spread_, "k -> k w h", w=width, h=height)x_grid_ = einops.repeat(x_spread_, "k -> k w h", w=width, h=height)y_new_ = y_center_ + y_grid_x_new_ = x_center_ + x_grid_y_new_ = einops.repeat(y_new_, "k w h -> b k w h", b=batch_size)x_new_ = einops.repeat(x_new_, "k w h -> b k w h", b=batch_size)x_offset_ = einops.rearrange(x_offset_, "b k w h -> k b w h")x_offset_new_ = x_offset_.detach().clone()# The center position remains unchanged and the rest of the positions begin to swing# This part is quite simple. The main idea is that "offset is an iterative process"x_offset_new_[center] = 0for index in range(1, center + 1):x_offset_new_[center + index] = (x_offset_new_[center + index - 1] + x_offset_[center + index])x_offset_new_[center - index] = (x_offset_new_[center - index + 1] + x_offset_[center - index])x_offset_new_ = einops.rearrange(x_offset_new_, "k b w h -> b k w h")x_new_ = x_new_.add(x_offset_new_.mul(extend_scope))y_coordinate_map = einops.rearrange(y_new_, "b k w h -> b w (h k)")x_coordinate_map = einops.rearrange(x_new_, "b k w h -> b w (h k)")return y_coordinate_map, x_coordinate_mapdef get_interpolated_feature(input_feature: torch.Tensor,y_coordinate_map: torch.Tensor,x_coordinate_map: torch.Tensor,interpolate_mode: str = "bilinear",
):"""From coordinate map interpolate feature of DSCNet based on: TODOArgs:input_feature: feature that to be interpolated with shape [B, C, H, W]y_coordinate_map: coordinate map along y-axis with shape [B, K_H * H, K_W * W]x_coordinate_map: coordinate map along x-axis with shape [B, K_H * H, K_W * W]interpolate_mode: the arg 'mode' of nn.functional.grid_sample, can be 'bilinear' or 'bicubic' . Defaults to 'bilinear'.Return:interpolated_feature: interpolated feature with shape [B, C, K_H * H, K_W * W]"""if interpolate_mode not in ("bilinear", "bicubic"):raise ValueError("interpolate_mode should be 'bilinear' or 'bicubic'.")y_max = input_feature.shape[-2] - 1x_max = input_feature.shape[-1] - 1y_coordinate_map_ = _coordinate_map_scaling(y_coordinate_map, origin=[0, y_max])x_coordinate_map_ = _coordinate_map_scaling(x_coordinate_map, origin=[0, x_max])y_coordinate_map_ = torch.unsqueeze(y_coordinate_map_, dim=-1)x_coordinate_map_ = torch.unsqueeze(x_coordinate_map_, dim=-1)# Note here grid with shape [B, H, W, 2]# Where [:, :, :, 2] refers to [x ,y]grid = torch.cat([x_coordinate_map_, y_coordinate_map_], dim=-1)interpolated_feature = nn.functional.grid_sample(input=input_feature,grid=grid,mode=interpolate_mode,padding_mode="zeros",align_corners=True,)return interpolated_featuredef _coordinate_map_scaling(coordinate_map: torch.Tensor,origin: list,target: list = [-1, 1],
):"""Map the value of coordinate_map from origin=[min, max] to target=[a,b] for DSCNet based on: TODOArgs:coordinate_map: the coordinate map to be scaledorigin: original value range of coordinate map, e.g. [coordinate_map.min(), coordinate_map.max()]target: target value range of coordinate map,Defaults to [-1, 1]Return:coordinate_map_scaled: the coordinate map after scaling"""min, max = origina, b = targetcoordinate_map_scaled = torch.clamp(coordinate_map, min, max)scale_factor = (b - a) / (max - min)coordinate_map_scaled = a + scale_factor * (coordinate_map_scaled - min)return coordinate_map_scaledif __name__ == "__main__":# 如果GPU可用,将模块移动到 GPUdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 输入张量 (batch_size, height, width,channels)x = torch.randn(1,32,40,40).to(device)# 初始化 HWD 模块dim=32block = DSConv_pro(32,32,7)print(block)block = block.to(device)# 前向传播output = block(x)print("输入:", x.shape)print("输出:", output.shape)
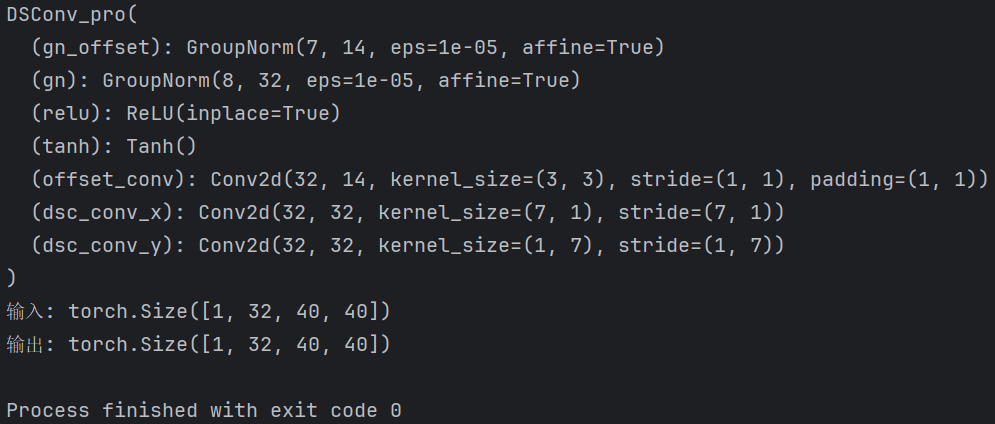
输出结果:




![[EAI-027] RDT-1B,目前最大的用于机器人双臂操作的机器人基础模型](https://i-blog.csdnimg.cn/direct/ac2f27c5c0e7474e918e6b75723a1ac2.png)






![python算法和数据结构刷题[2]:链表、队列、栈](https://i-blog.csdnimg.cn/direct/34780a8f88ee40fdb0ceb39f2b996eb3.png)






