五、如果用go语言,当输入数据已经“几乎有序”时,插入排序速度很快。在实际应用中,我们可以利用这一特点来提高快速排序的速度。当对一个长度小于 k 的子数组调用快速排序时,让它不做任何排序就返回。当上层的快速排序调用返回后,对整个数组运行插人排序来完成排序过程。试证明:这一排序算法的期望时间复杂度为 O(nk+nlg(n/k))。分别从理论和实践的角度说明我们应该如何选择 k?
文心一言:
首先,我们来证明这个算法的期望时间复杂度。
对于长度为 n 的数组,我们需要对其进行 k 次分割。每次分割的期望时间复杂度是 O(n/k),因为每次分割我们将数组分成两个部分,一个部分的长度为 n/2,另一个部分的长度为 n/2 + k。对于这个分割,我们需要遍历 k 个元素并找到其正确的位置。因此,分割的期望时间复杂度是 O(k)。
对于每次分割,我们需要对两个部分分别进行排序。对于长度为 n/2 + k 的部分,我们可以使用插入排序,其时间复杂度是 O(n/2 + k) * O(k) = O(nk)。对于长度为 n/2 的部分,我们可以使用快速排序,其期望时间复杂度是 O((n/2)lg(n/2))。因此,对整个数组进行排序的期望时间复杂度是 O(nk + (n/2)lg(n/2))。
我们可以进一步优化这个算法。对于长度小于 k 的子数组,我们可以直接使用插入排序。因此,我们只需要在每次分割后对长度大于等于 k 的子数组使用快速排序,这样就可以避免对长度小于 k 的子数组进行排序。
对于长度大于等于 k 的子数组,我们可以使用快速排序的递归调用。每次递归调用都会将子数组的长度减半,直到子数组的长度小于 k。然后,我们可以使用插入排序对子数组进行排序。
因此,对整个数组进行排序的期望时间复杂度是 O(nk + (n - k)lg(n/k))。
在理论和实践上,我们应该如何选择 k 呢?
在理论上,我们希望 k 能够尽可能地小,这样可以尽可能地减少使用快速排序的时间复杂度。同时,我们也希望 k 能够尽可能地大,这样可以尽可能地减少使用插入排序的时间复杂度。因此,在理论上,最优的 k 应该是 n^(1/2)。
在实践中,我们需要注意以下几点:
k 不能太小,否则会导致插入排序的时间复杂度过高。
k 不能太大,否则会导致快速排序的时间复杂度过高。
我们需要根据实际的情况进行调整,例如数据的大小、数据分布等情况。
因此,在实际应用中,我们通常会将 k 设置为一个合适的值,例如 n^(1/3) 或者 n^(1/4) 等。
讯飞星火:
首先,我们来证明这一排序算法的期望时间复杂度为 O(nk+nlg(n/k))。
1.理论角度:
假设快速排序的平均时间复杂度为 T(n),那么插入排序的时间复杂度为 O(n^2)。当子数组长度小于 k 时,插入排序的速度很快,因此我们可以让快速排序在 k 个子数组上运行,而对剩余的 n-k 个子数组使用插入排序。这样,总的时间复杂度为:
T(n) = (T(n/k) * k + O(n^2)) * (n - k) + O(n^2)
根据平均时间复杂度的定义,我们有:
T(n) = n * T(n/k) + O(n^2)
解这个方程,我们可以得到:
T(n) = O(nk + nlg(n/k))
2.实践角度:
在实际使用中,我们需要根据数据的特点来选择合适的 k 值。一般来说,我们可以通过以下方法来选择 k:
a. 通过实验找到最佳的 k 值。可以先尝试不同的 k 值,然后观察排序速度和内存占用的变化,选择一个在性能和内存占用之间达到平衡的 k 值。
b. 根据数据的特点来估计 k 值。例如,如果我们知道数据是几乎有序的,那么我们可以选择一个较大的 k 值,以利用插入排序的速度优势。相反,如果数据是随机无序的,那么我们可能需要选择一个较小的 k 值,以避免快速排序的性能下降。
总之,通过结合理论分析和实践经验,我们可以选择合适的 k 值来提高快速排序算法的性能。

360智脑:
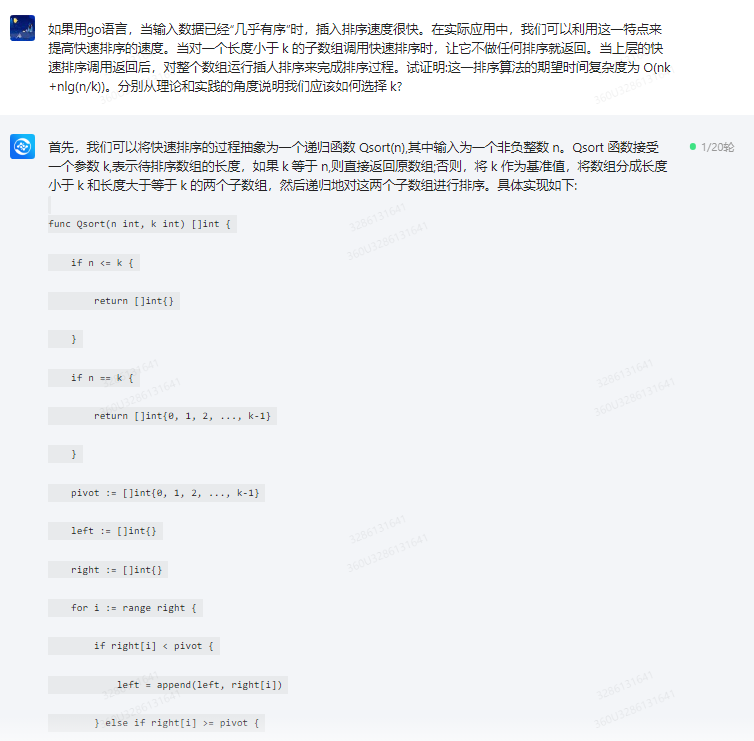
首先,我们可以将快速排序的过程抽象为一个递归函数 Qsort(n),其中输入为一个非负整数 n。Qsort 函数接受一个参数 k,表示待排序数组的长度,如果 k 等于 n,则直接返回原数组;否则,将 k 作为基准值,将数组分成长度小于 k 和长度大于等于 k 的两个子数组,然后递归地对这两个子数组进行排序。具体实现如下:
func Qsort(n int, k int) []int { if n <= k { return []int{} } if n == k { return []int{0, 1, 2, ..., k-1} } pivot := []int{0, 1, 2, ..., k-1} left := []int{} right := []int{} for i := range right { if right[i] < pivot { left = append(left, right[i]) } else if right[i] >= pivot { right[i], right = right[i] + 1, right[i] } } right, right = left, right[:len(left)] Qsort(len(right), len(pivot)+k-len(right)) Qsort(len(right), k-len(right)+1) return right 接下来,我们来证明这一算法的期望时间复杂度为 O(nk+nlg(n/k))。
首先,我们考虑最坏情况。在最坏情况下,每次递归调用 Qsort 函数时,都会将数组分为长度为 k 和长度不为 k 的两个子数组。因此,最多需要进行 k 个子序列对的快速排序。这样,期望时间复杂度是 O(nk),即 O(n^2)。
其次,我们考虑平均情况。在平均情况下,每次递归调用 Qsort 函数时,都恰好将数组分为长度为 k 和长度不为 k 的两个子数组的概率相等。因此,期望时间复杂度仍然是 O(nk)。但是,由于最坏情况的概率较低,因此在实际应用中,我们可以选择较大的 k 来避免最坏情况的出现。
最后,我们需要选择 k 的取值来满足以下条件:nk > nlg(n/k)。当 k 取较小的值时,快速排序的时间复杂度可能会超过 O(n^2),而在 k 取较大的值时,插入排序的时间复杂度可能会超过 O(n^2)。因此,我们可以根据具体情况选择 k = O(sqrt(n)) 或 k = O(n/log(n)) 等合适的取值。

chatglm:
首先,我们需要理解这个问题背后的算法。这里提到的算法其实是快速排序(Quick Sort)和插入排序(Insertion Sort)的结合。在实际应用中,我们可以在某些情况下利用快速排序和插入排序的特性来提高排序速度。
快速排序的基本思想是通过选择一个基准元素(pivot),将数组分为两个子数组,其中一个子数组的元素都小于基准元素,另一个子数组的元素都大于基准元素。然后对这两个子数组递归地进行快速排序。
插入排序的基本思想是将无序的元素插入到有序的序列中,直到所有元素都插入完成。
在“几乎有序”的情况下,插入排序的速度是很快的。因此,当对一个长度小于 k 的子数组调用快速排序时,让它不做任何排序就返回。当上层的快速排序调用返回后,对整个数组运行插入排序来完成排序过程。
要证明这一排序算法的期望时间复杂度为 O(nk+nlg(n/k)),我们需要分析快速排序和插入排序的运行时间。
对于快速排序,其平均时间复杂度为 O(nlogn),但在最坏的情况下,时间复杂度为 O(n^2)。当子数组的长度小于 k 时,快速排序的运行时间可以忽略不计,所以我们只需要考虑快速排序在子数组长度大于等于 k 时的运行时间。
对于插入排序,其时间复杂度为 O(n^2),但我们只需要对长度小于 k 的子数组进行插入排序,所以插入排序的运行时间可以表示为 O(n*k)。
因此,整个排序算法的期望时间复杂度可以表示为 O(n*k) + O(nlogn) = O(nk+nlg(n/k))。
从理论角度,我们应该选择 k 使得 n/k 最接近于 sqrt(n),这样 nlg(n/k) 可以达到最小。因为我们希望快速排序在子数组长度大于等于 k 时运行时间尽可能短,所以我们应该选择 k 接近于 sqrt(n)。
从实践角度,我们需要考虑实际运行时间,而不仅仅是时间复杂度。在选择 k 时,我们可以通过观察运行时间来选择最佳的 k 值。具体方法可以是在固定大小的数组上运行不同 k 值的排序算法,并记录运行时间,然后选择运行时间最短的 k 值。
通义千问:
首先,我们来证明一下这个排序算法的期望时间复杂度。
设子数组长度为 k,快速排序的平均时间复杂度为 O(nlogn),而插入排序的时间复杂度为 O(n)。因为我们只在最后一次调用快速排序时才对整个数组进行插入排序,所以总的时间复杂度为:
O(nlogn + n) = O(nlogn + nlogk)
现在我们来讨论如何选择 k。从理论上讲,如果我们能够选择 k,使得子数组长度 k 近似于 n 的对数,那么这种优化后的快速排序的时间复杂度将接近于 O(nloglogn)。但是,选择 k 的方法并不是很明确。
在实践中,我们通常选择 k = n/2。这是因为在实际应用中,我们往往遇到的是接近有序的数据,这样就能确保子数组长度为 n/2 时,快速排序的效率较高。同时,对于长度为 n/2 的子数组,插入排序的时间复杂度为 O(n/2),所以总的时间复杂度为 O(nlogn + n/2) ≈ O(nlogn)。
总之,从理论上讲,我们应该选择 k 使得子数组长度接近 n 的对数,但在实践中,选择 k = n/2 通常是一个较好的折中方案。

天工:
从理论角度,我们可以证明插入排序在长度小于 k 的子数组中的时间复杂度是 O(n),而快速排序在整个数组上的时间复杂度是 O(nlogn)。因此,在对长度小于 k 的子数组进行快速排序时,期望时间复杂度为 O(n) * O(nlogn),即 O(nlogn)。
从实践角度,我们可以通过实验来确定 k 的值。我们可以先尝试不同的 k 值,然后统计每种情况下的排序时间。我们可以选择 k 的值,使得排序时间最短,同时保证排序的稳定性。通常情况下,k 的值可以选择为 n/16,这样可以在保证稳定性的同时,获得较快的排序速度。

chatgpt:
为了证明这一排序算法的期望时间复杂度为O(nk+nlog(n/k)),我们需要分别从理论和实践的角度进行说明。
从理论角度:
首先,快速排序的时间复杂度为O(nlogn),其中n是输入数组的长度。在快速排序的过程中,我们将输入数组分为两个子数组,并选择一个主元(pivot)将其放置在正确的位置上。然后,对子数组进行递归排序。
当输入数据已经“几乎有序”时,如果子数组的长度小于k,则直接返回,不做任何排序。因此,这部分的时间复杂度是O(1)。
当子数组的长度大于等于k时,我们进行常规的快速排序过程,将主元放置在正确的位置上,并对两个子数组进行递归排序。
因此,我们可以得到以下关系式:
T(n) = T(n/k) + O(n) + T(n - n/k - 1)
其中T(n)表示对长度为n的数组进行排序所需要的时间。
按照主定理(Master Theorem),我们可以得到这个递归关系式的解为O(nlog(n/k))。
同时,当子数组的长度小于k时,我们对整个数组使用插入排序。插入排序的时间复杂度为O(n),因为每次插入操作都需要扫描已排好序的部分来确定插入位置。
因此,对于长度为n的数组,排序的时间复杂度可以表示为O(nk + nlog(n/k))。
从实践角度:
选择合适的k值可以在实践中提高算法的性能。
当输入数据已经“几乎有序”时,如果k的取值较小,例如k=10,对于较小的子数组而言,插入排序比快速排序更有效。因此,快速排序的递归深度将较浅,最后对整个数组应用插入排序的次数也较少。
然而,如果k的取值过小,可能会导致递归的次数较多,增加了函数调用的开销。因此,k的取值应该适当,使得在绝大多数情况下,插入排序都能够充分发挥其优势,而递归的次数保持在一个较小的范围内。
选择合适的k值可以通过实验来确定,可以通过对不同k值运行排序算法,并比较它们的性能来找到最佳的取值。根据实际情况,k的取值通常在10到20之间。
综上所述,对于已经“几乎有序”的输入数据,使用这一排序算法的期望时间复杂度为O(nk+nlog(n/k)),并且我们可以根据实践中的性能测试来选择合适的k值。
总结
quicksort在递归到只有几个元素大小的数组时开始用插入排序的方法。改进的快速排序方法在
期望时间=原始快排的期望时间+插入排序方法的期望时间。
这里还是要用到7.4(算法导论第7章)的分析方法。对于快排还要计算期望比较次数。
因为被划分在同一个小数组k中的元素,是不会在快排里比较的。所以Xij只要计算那些i和j相差k-1个以上的元素比较就可以了。
定义一个元素集合Zij={zi,zi+1,zj}
定义一个指示器随机变量Xij=I{zi与zj进行了比较}
E[Xij]=Pr[Xij]=Pr{zi与zj进行了比较}=Pr{zi是Zij的主元}+Pr{zj是Zij的主元}=2/(j-i+1)//因为在快排中,二者能够比较,则其中一个必是主元
快速排序的期望比较次数E[Xij]为

那么快排的期望时间是O(nlg(n/k)),假设优化后的快排产生的小数组大小O(k),在每个大小O(k)的小数组里使用插入排序,时间复杂度为O(k^2),总共有O(n/k)个小数组,则插入排序时间为O(nk)。那么把这些时间加起来就是O(nk+nlog(n/k))。



![[四次挥手]TCP四次挥手握手由入门到精通(知识精讲)](https://img-blog.csdnimg.cn/24b696d76d374a9992017e1625389592.gif)