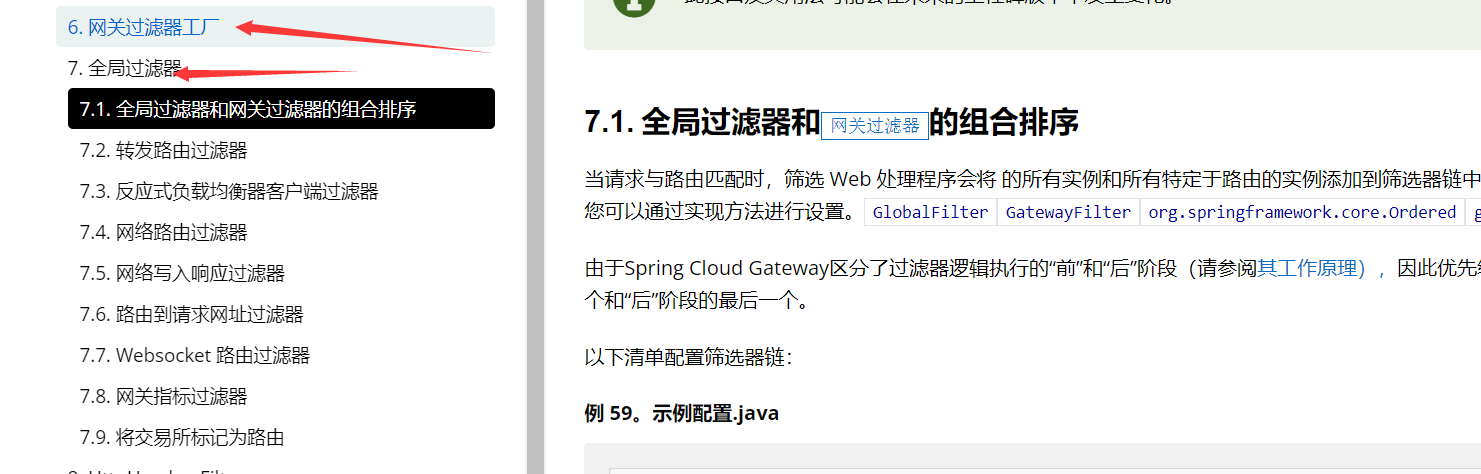
在进行大规模数据爬取时,爬虫速度往往是一个关键问题。本文将介绍一个提升爬虫速度的秘密武器:多线程+隧道代理。通过合理地利用多线程技术和使用隧道代理,我们可以显著提高爬虫的效率和稳定性。本文将为你提供详细的解决方案和实际操作价值,同时附上Python代码示例,让你轻松掌握这个提升爬虫速度的技巧。

在传统的单线程爬虫中,每次请求都需要等待服务器的响应,这会导致爬取速度较慢。而多线程爬虫可以同时发送多个请求,充分利用计算机的多核处理能力,从而提高爬取速度。以下是一些使用多线程爬虫的优势:
1、提高爬取速度:通过并发发送多个请求,减少等待时间,从而显著提高爬取速度。
2、提高效率和稳定性:多线程爬虫可以充分利用计算机资源,提高爬虫的效率和稳定性。
我们来认识一下隧道代理:
隧道代理是一种将网络请求通过中间代理服务器转发的技术。通过使用隧道代理,我们可以隐藏真实的IP地址,同时实现分布式爬取,提高爬虫的稳定性和安全性。以下是使用隧道代理的步骤:
1、获取隧道代理:选择一个可靠的隧道代理服务提供商,注册并获取相应的代理信息。
2、设置代理:在爬虫代码中,设置代理服务器的地址和端口,并将请求通过代理服务器发送。
下面是一个使用多线程+隧道代理的爬虫示例代码:
import requests
import threading
# 隧道代理信息
proxy_host = 'your_proxy_host'
proxy_port = 'your_proxy_port'
# 爬取任务
def crawl(url):proxies = {'http': f'http://{proxy_host}:{proxy_port}','https': f'http://{proxy_host}:{proxy_port}'}response = requests.get(url, proxies=proxies)# 处理响应数据# ...# 多线程爬虫
def multi_thread_crawler(urls):threads = []for url in urls:thread = threading.Thread(target=crawl, args=(url,))thread.start()threads.append(thread)for thread in threads:thread.join()# 执行爬虫任务
if __name__ == '__main__':urls = ['https://www.example.com/page1','https://www.example.com/page2','https://www.example.com/page3',# ...]multi_thread_crawler(urls)
通过合理地利用多线程和隧道代理,我们可以显著提升爬虫的速度和稳定性。多线程爬虫利用并发请求的特性,提高了爬取效率;而隧道代理则可以隐藏真实IP地址,实现分布式爬取。希望本文提供的解决方案和代码示例对你在爬虫速度优化方面有所帮助。
未来,随着技术的不断发展,我们可以进一步探索更多的爬虫优化技巧,提高爬虫的效率和稳定性。




![[四次挥手]TCP四次挥手握手由入门到精通(知识精讲)](https://img-blog.csdnimg.cn/24b696d76d374a9992017e1625389592.gif)