在上一个视频中,您探讨了训练大型语言模型的计算挑战。在这里,您将了解关于模型大小、训练、配置和性能之间关系的研究,以确定模型需要多大。请记住,预训练期间的目标是最大化模型的学习目标性能,即在预测令牌时最小化损失。您有两种选择来实现更好的性能:增加您训练模型的数据集大小和增加模型中的参数数量。理论上,您可以扩展这两个数量中的任何一个来提高性能。
但是,还需要考虑的另一个问题是您的计算预算,其中包括您可以访问的GPU数量和用于训练模型的可用时间等因素。

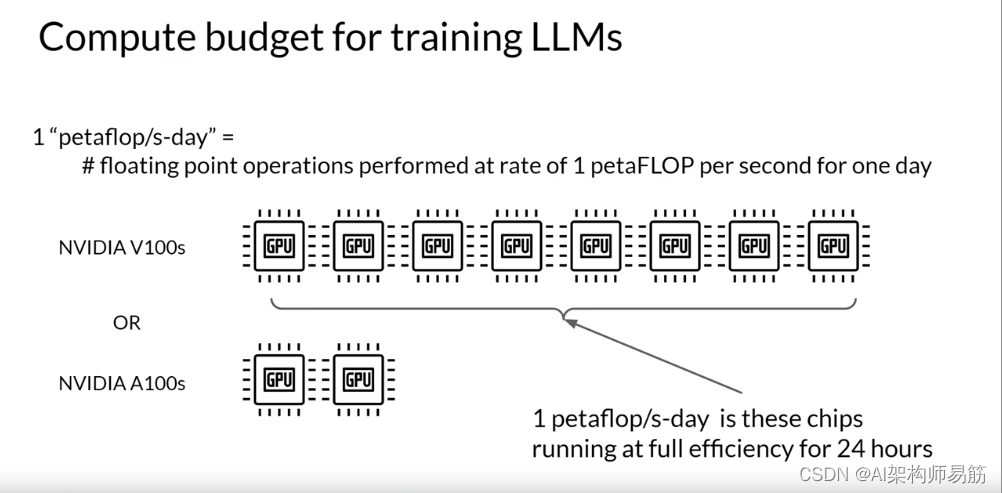
为了帮助您理解接下来的讨论,让我们首先定义一个计算单位,用于量化所需的资源。每秒petaFLOP每天是测量浮点操作的数量,以每秒一个petaFLOP的速度执行,持续一整天。请注意,一个petaFLOP对应于每秒一千万亿次浮点运算。当特别考虑训练变压器时,每秒每天一个petaFLOP大约相当于八个NVIDIA V100 GPU,全天全效率运行。

如果您有一个更强大的处理器,可以一次执行更多的操作,那么每秒每天一个petaFLOP需要的芯片更少。例如,两个NVIDIA A100 GPU提供与八个V100芯片相当的计算能力。
为了给您一个这些计算预算规模的概念,这个图表显示了预训练Bert和Roberta的不同变体所需的每秒每天的petaFLOP的比较,这两者都是仅编码器模型。T5和编码器-解码器模型,以及GPT-3,这是一个仅解码器模型。
每个家族中的模型之间的区别是被训练的参数数量,从Bert基础的几亿到最大的GPT-3变体的1750亿。请注意,y轴是对数的。每个垂直增量是10的幂。在这里,我们看到T5 XL有30亿参数,需要接近100每秒每天的petaFLOP。而更大的GPT-3 1750亿参数模型需要大约3700每秒每天的petaFLOP。
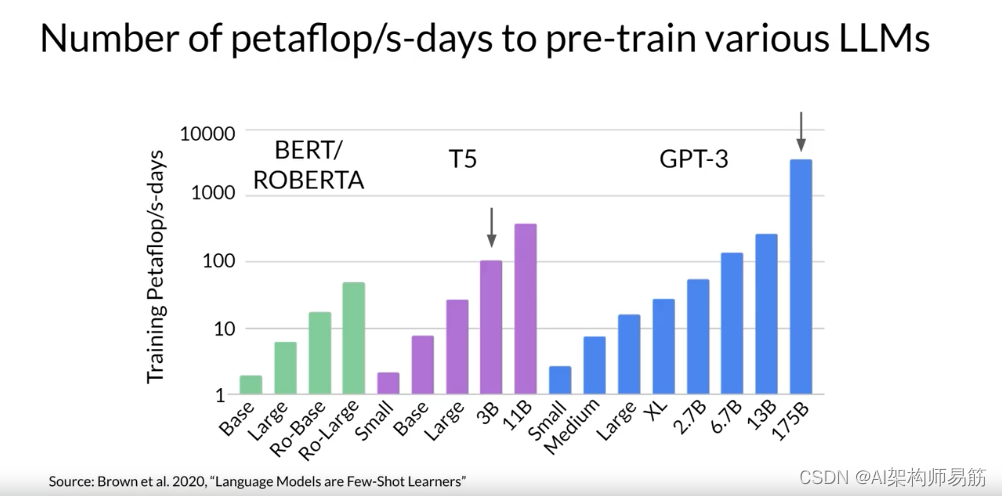
这个图表清楚地表明,训练最大的模型需要大量的计算机。您可以看到,更大的模型需要更多的计算资源来训练,并且通常还需要更多的数据来实现良好的性能。
事实证明,这三种扩展选择之间实际上存在明确定义的关系。研究人员已经探讨了训练数据集大小、模型大小和计算预算之间的权衡。这是OpenAI的研究人员在一篇论文中探讨计算预算对模型性能影响的图表。y轴是测试损失,您可以将其视为模型性能的代理,其中较小的值更好。
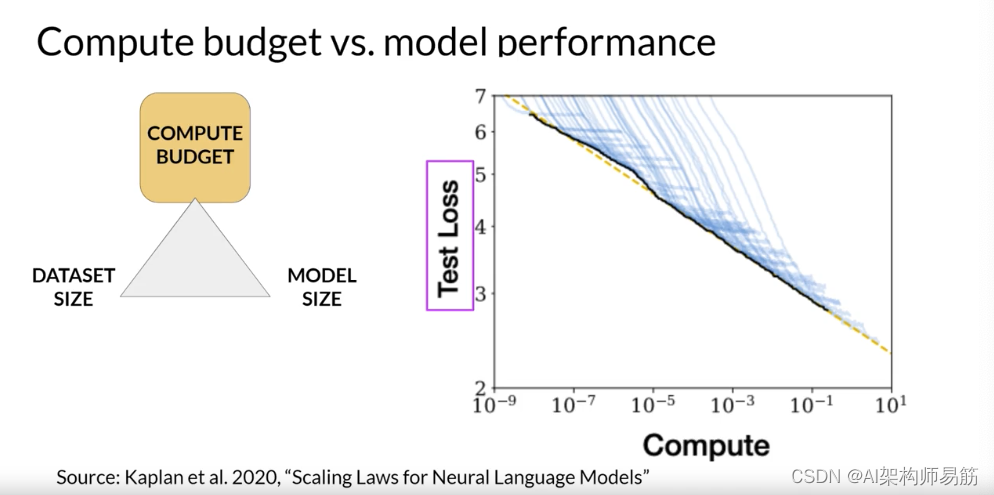
x轴是以每秒每天的petaFLOP为单位的计算预算。如您所见,更大的数字可以通过使用更多的计算能力或训练更长时间或两者兼而有之来实现。
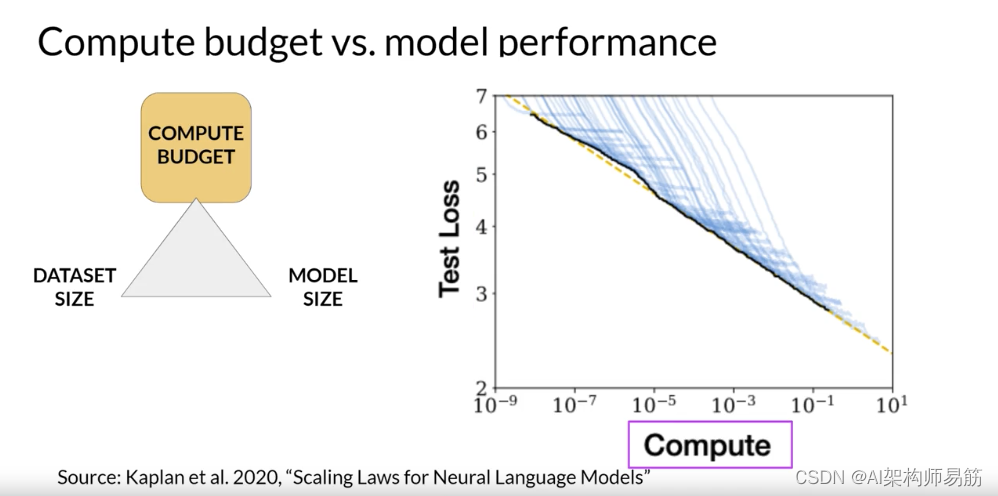
这里的每条薄蓝线都显示了单次训练运行的模型损失。查看每次运行的损失开始更慢地下降的位置,揭示了计算预算与模型性能之间的明确关系。这可以通过幂律关系来近似,由这条粉红线表示。幂律是两个变量之间的数学关系,其中一个与另一个的某个幂成正比。当在两个轴都是对数的图上绘制时,幂律关系显示为直线。
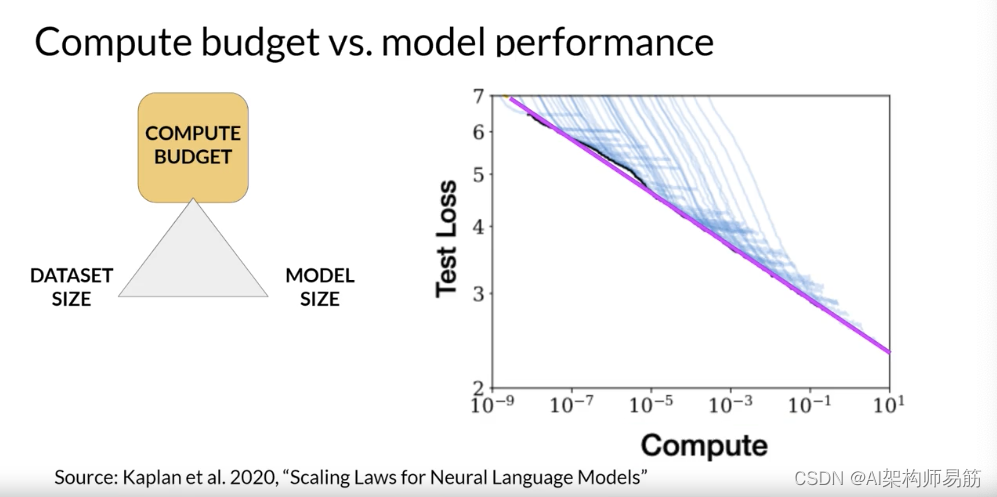
只要模型大小和训练数据集大小不妨碍训练过程,这里的关系就会保持。
从字面上看,这似乎表明您可以增加计算预算以实现更好的模型性能。
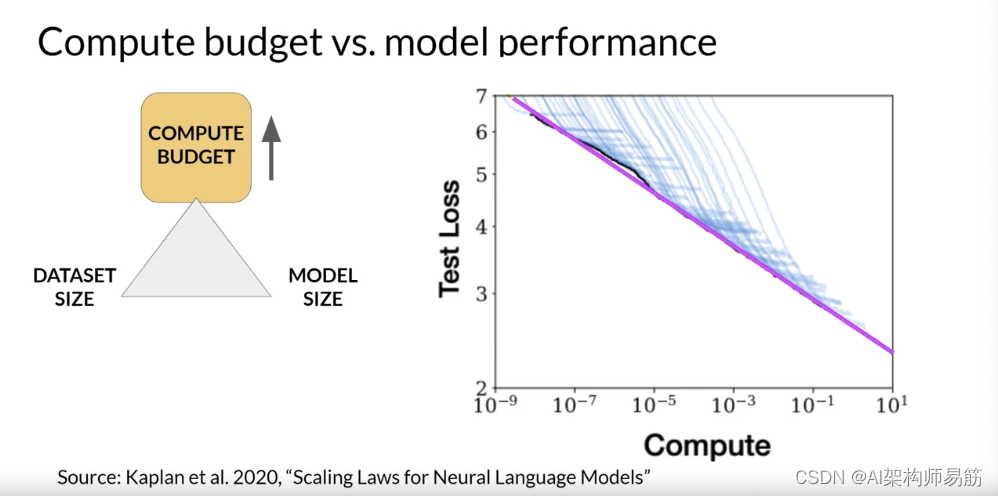
然而,实际上,您用于训练的计算资源通常是由
- 您可以访问的硬件、
- 训练的可用时间
- 项目的财务预算等因素设定的硬约束。
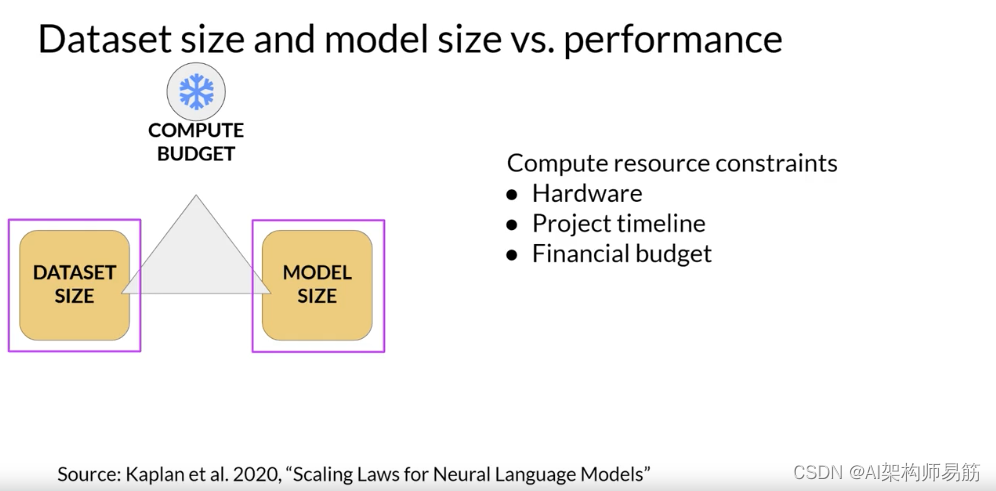
如果您将计算预算固定,那么您可以改进模型性能的两个杠杆是训练数据集的大小和模型中的参数数量。
OpenAI的研究人员发现,当其他两个变量保持固定时,这两个数量也与测试损失显示幂律关系。
这是另一张从论文中探讨训练数据集大小对模型性能影响的图表。在这里,计算预算和模型大小保持不变,训练数据集的大小是变化的。图表显示,随着训练数据量的增加,模型的性能继续提高。
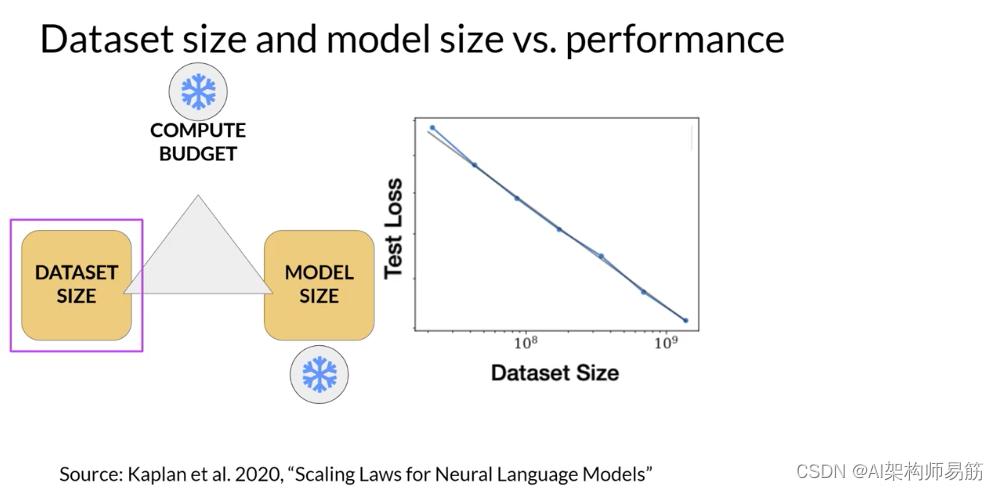
在第二张图中,计算预算和训练数据集大小保持恒定。训练了不同数量参数的模型。随着模型大小的增加,测试损失减少,表示性能更好。
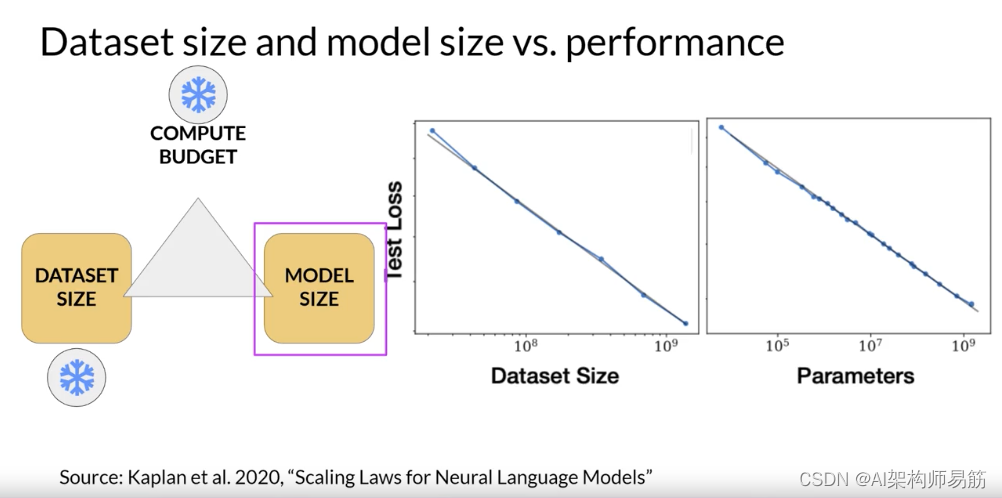
此时,您可能会问,这三个数量之间的理想平衡是什么?事实证明,很多人对这个问题感兴趣。
研究和行业社区都发布了大量预训练计算最佳模型的实证数据。在2022年发表的一篇论文中,由Jordan Hoffmann、Sebastian Borgeaud和Arthur Mensch领导的研究小组对各种大小和训练数据量的语言模型的性能进行了详细研究。目标是找到给定计算预算的参数数量和训练数据量的最佳值。作者的名字,得出的计算最佳模型是Chinchilla。

这篇论文通常被称为Chinchilla论文。
让我们看看他们的一些发现。Chinchilla论文暗示,许多1000亿参数的大型语言模型,如GPT-3,实际上可能是过度参数化的,这意味着它们的参数比实现良好的语言理解所需的更多,
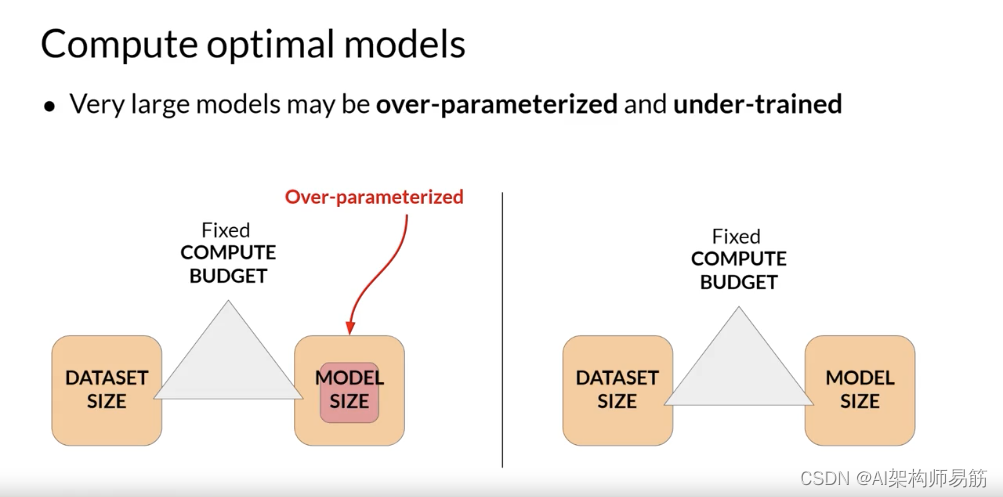
并且训练不足,因此它们将受益于查看更多的训练数据。
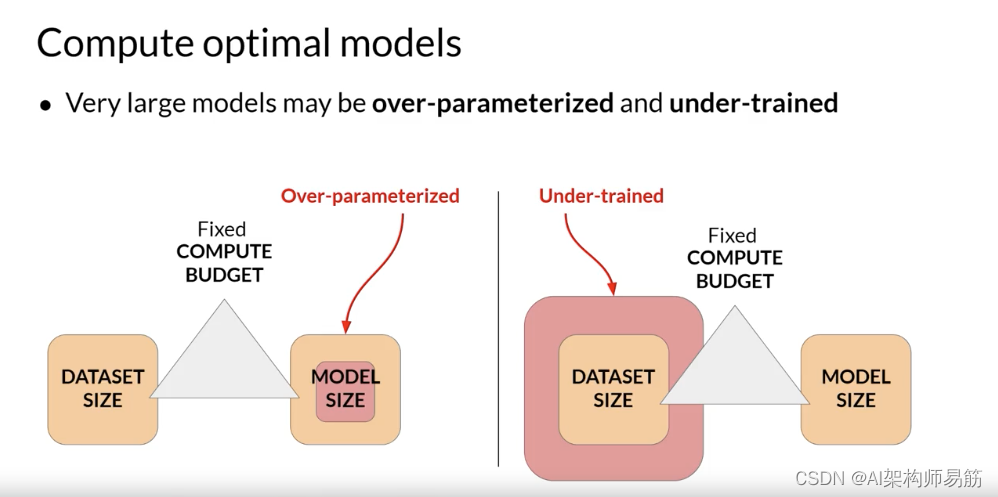
作者假设,如果在更大的数据集上训练,较小的模型可能能够实现与更大的模型相同的性能。
在这个表格中,您可以看到一些模型以及它们的大小和它们被训练的数据集的信息。

Chinchilla论文的一个重要结论是,对于给定模型的理想训练数据集大小大约是模型中参数数量的20倍。
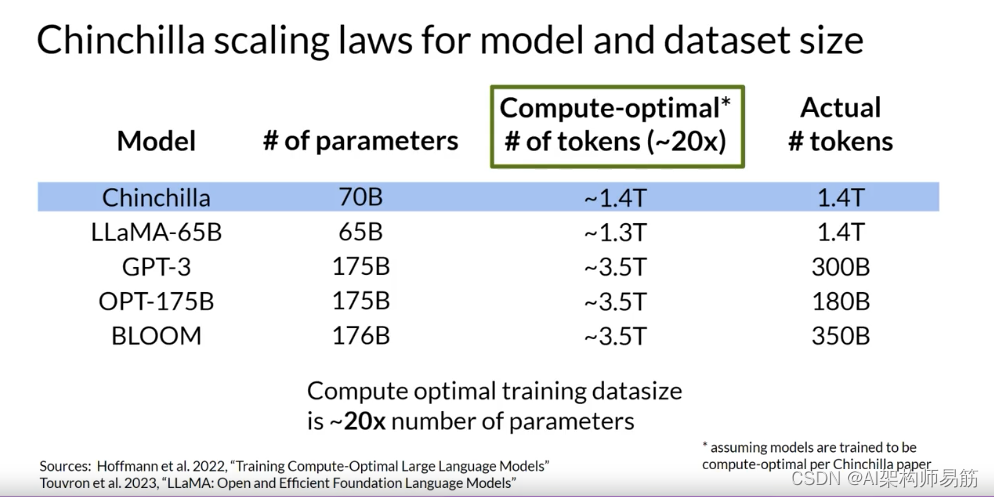
对于一个700亿参数的模型,理想的训练数据集包含1.4万亿令牌,或参数数量的20倍。

表中的最后三个模型是在小于Chinchilla最佳大小的数据集上训练的。这些模型实际上可能是训练不足的。

相比之下,LLaMA是在1.4万亿令牌的数据集大小上训练的,这接近于Chinchilla推荐的数字。

论文的另一个重要结果是,计算最佳的Chinchilla模型在大范围的下游评估任务上胜过非计算最佳的模型,如GPT-3。
有了Chinchilla论文的结果,团队最近开始开发较小的模型,这些模型实现了与以非最佳方式训练的较大模型相似,如果不是更好的结果。
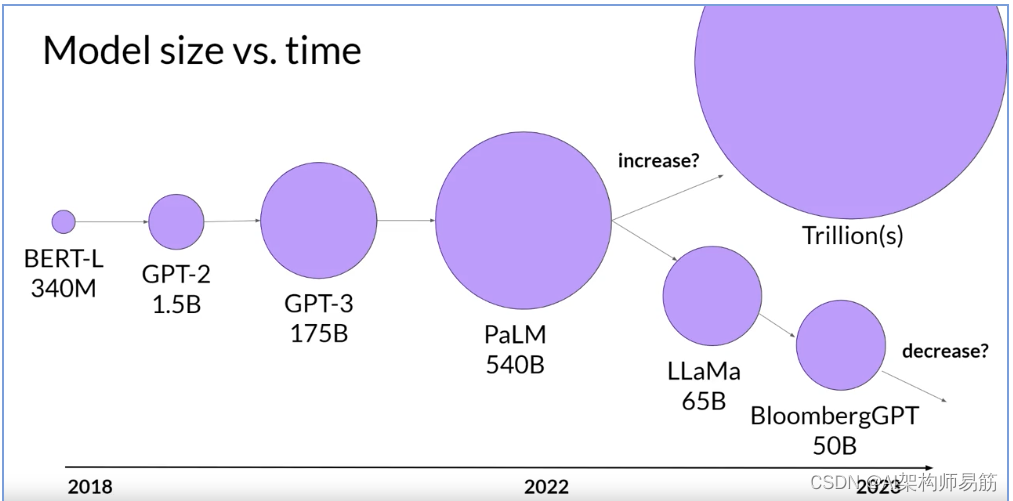
展望未来,随着更多的团队或开发者像您这样开始优化模型设计,您可能会期望看到与过去几年的“更大总是更好”的趋势有所偏离。
这张幻灯片上显示的最后一个模型,Bloomberg GPT,是一个非常有趣的模型。它是以计算最佳的方式训练的,遵循Chinchilla的损失,因此以500亿参数的大小实现了良好的性能。
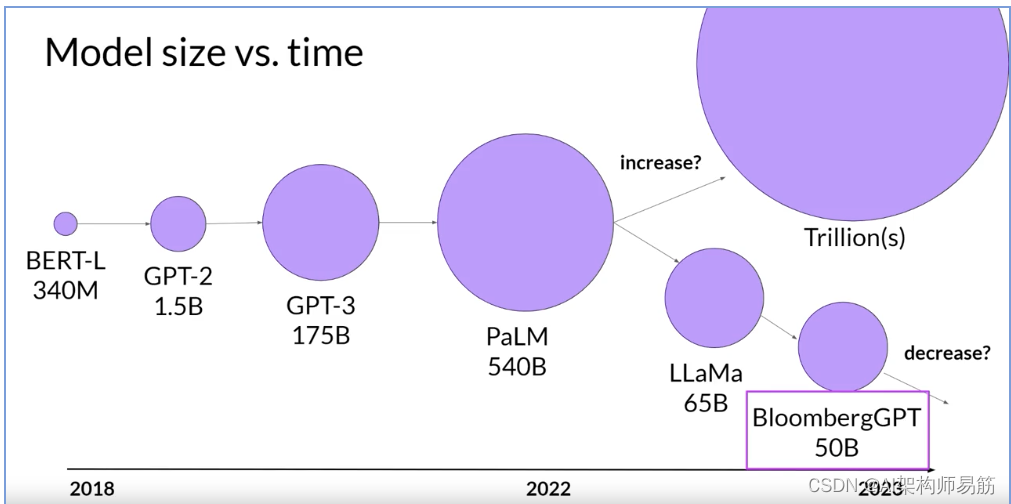
这也是一个情况的有趣例子,从头开始预训练模型是实现良好任务性能所必需的。让我们继续观看本周的最后一个视频,讨论为什么。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/SmRNp/scaling-laws-and-compute-optimal-models






![[四次挥手]TCP四次挥手握手由入门到精通(知识精讲)](https://img-blog.csdnimg.cn/24b696d76d374a9992017e1625389592.gif)