本文章仅供技术研究参考,勿做它用!
-
5秒盾的特点
<title>Just a moment...</title>返回的页面中不是目标数据,而是包含上面的代码:Just a moment...
或者第一次打开网页的时候:
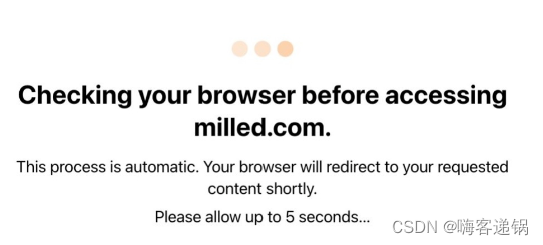
这几个特征就是被Cloudflare保护的网站,熟称5秒盾。
-
免费版5秒盾的绕过方法
安装cloudscraper
pip3 install cloudscraperimport cloudscraper
scraper = cloudscraper.create_scraper()
resp = scraper.get('目标网站').text将代码中的requests 替换成scraper即可,其他和requests一样正常使用。
-
付费版5秒盾的绕过方法
如果网站部署的是付费版的5秒盾,用上述的cloudscraper就无法绕过,会返回下面的内容
Detected a Cloudflare version 2 (aptcha challengeeature is not available in the operce (free) version
付费版本绕过方法:docker 部署 flaresolverr 。
绕盾大致过程就是使用flaresolverr来代理我们的request请求,flaresolverr启动模拟浏览器绕盾成功之后我们保存好所需的cookies等参数,后续的requests就使用这些参数直接请求目标页面即可。如果请求的时候发现又被拒绝了,就重新启动绕盾步骤。
部署flaresolverr,本文章中的docker 和 flaresolverr 部署在爬虫程序同一台机器上。
linux 指令:
docker run -d --name=flaresolverr -p 8191:8191 -e LOG_LEVEL=info --restart unless-stopped ghcr.io/flaresolverr/flaresolverr:latest
这里的代理端口设置的是 8191
部署完毕后使用curl 指令进行测试,不是本机部署请更换localhost 为flaresolverr 机器IP
curl -L -X POST 'http://localhost:8191/v1' -H 'Content-Type: application/json' --data-raw '{"cmd": "request.get","url":"https://你的目标网站/","maxTimeout": 160000}'
这里有个注意点就是如果部署的机器性能比较差、目标网站性能差、或者网络通路不良等情况,maxTimeout 的值要设置 的足够大(ms),不然会失败,我在实测一个网站的时候最大一次绕盾过程用了两分钟,例子代码中设置了160秒超时。
附上绕盾用的python代码:
def 绕过5秒盾(self,xxxx):print("破盾中...")urlServer = "http://localhost:8191/v1"payload = json.dumps({"cmd": "request.get","url":'https://www.目标网站.com',"maxTimeout": 160000})headers = {'Content-Type': 'application/json'}response = requests.post(urlServer, headers=headers, data=payload)# print(response.status_code)# print(response.json()['solution']['cookies'])if response.status_code==200:userAgent = response.json()['solution']['userAgent']for item in response.json()['solution']['cookies']:self.cookies[item["name"]] = item["value"]self.UA = userAgentprint("破盾成功")return responseprint("绕过5秒盾错误!!!")获取到绕盾成功的cookies ,之后的请求都使用requests 携带此cookie 直接请求即可,不需要每个请求都使用绕盾的方式。
因为flaresolverr启动绕盾浏览器会占用大量机器资源。
参考内容:
https://www.163.com/dy/article/HUM0G2U505561QYO.html
https://www.5axxw.com/wiki/content/df5u4r