文章目录
- FOCUS-AND-DETECT: A SMALL OBJECT DETECTION FRAMEWORK FOR AERIAL IMAGES
- ABSTRACT
- 1 Introduction
- 2 Related Work
- 3 Focus-and-Detect
- 3.1 Overview
- 3.2 Focus Stage
- 3.2.1 Generating Ground-Truth Boxes of Focal Regions Using Gaussian Mixture Model
- 3.3 Detection Stage
- 3.4 Post Processing
- 3.4.1 Incomplete Box Suppression
- 3.4.2 Non-max Suppression
- 4 Experimental Results
- 4.1 Implementation Details
- 4.2 Dataset and Evaluation Metric && 4.3 Results && 4.4 Ablation Study
- 5 Conclusion
FOCUS-AND-DETECT: A SMALL OBJECT DETECTION FRAMEWORK FOR AERIAL IMAGES
ABSTRACT
航空影像中的目标检测仍然是一项具有挑战性的任务。航空影像中的特定问题使得检测更加困难,例如小尺寸物体、密集排列的物体、不同尺寸和方向的物体等。为了解决小尺寸物体检测问题,我们提出了一个名为“Focus-and-Detect”的两阶段目标检测框架。第一阶段由一个受高斯混合模型监督的目标检测器网络组成,生成构成聚焦区域的物体群集。第二阶段同样是一个目标检测器网络,预测聚焦区域内的物体。我们还提出了Incomplete Box Suppression(IBS)方法,以克服区域搜索方法的截断效应。结果表明,所提出的两阶段框架在VisDrone验证数据集上实现了42.06的AP得分,据作者所知,超越了文献中报告的所有其他最先进的小物体检测方法。
1 Introduction
目标检测包括目标定位和分类两个子任务。许多其他任务依赖于它,比如图像字幕生成、目标跟踪、实例分割和场景理解。随着基于深度学习的方法的进步,基于手工特征的方法,如HOG和SIFT,已经过时了。SIFT和HOG特征是低级特征,无法作为hierarchical layer-wise representations来使用,而深度模型能够将数据表示为abstract representations的分层组合。通常,检测网络包括主干网(backbone)、颈部网络(neck)和头部网络(head)。在这个背景下,主干模型是为检测任务提取特征的网络,头部是实际的检测模型,用于预测边界框和类别,颈部位于主干和头部网络之间,融合来自主干模型不同阶段的特征图。对于检测头部,有不同的方法,例如一阶段检测和两阶段检测模型。一阶段检测模型在头部模型中不包括region proposa layer,直接在密集位置上进行检测。另一方面,两阶段模型利用region proposa网络提取用于边界框回归和分类的目标区域。
航空目标检测是一种新兴领域,可以被归类为一般小物体检测问题的一个案例,近年来取得了一些进展。尽管它在监控、精确农业、军事监测和城市管理等许多应用中具有广泛的应用,但它是最具挑战性的计算机视觉任务之一。早些时候,一些研究提出将用于自然图像的方法调整为航空图像。然而,这种方法,出现了各种困难。首先,在航空图像中,方向和长宽比可能与自然图像有很大差异。其次,航空图像中的尺度变化对于类内和类间样本都更为严重。例如,MS COCO和VisDrone 数据集中“车辆”类的统计数据。其中在VisDrone数据集中,“车辆”对象的尺寸方差几乎是MS COCO数据集的五倍。第三,航空图像中的物体尺寸小且密集排列。例如,在VisDrone Detection数据集中,单张图像中可能存在多达902个对象。此外,航空图像中存在类不平衡问题,使得样本数量较少的类别的小物体检测问题变得更加困难。因此,需要针对上述问题的专门方法来解决小物体检测任务。
Region search是小物体检测的一种强大方法,旨在寻找并聚焦可能包含对象的区域。由于航空图像由密集且小的物体组成,我们在本文中专注于航空目标检测问题的区域搜索。为此,我们提出了一个由两个阶段组成的框架,即focus和detection阶段。在第一阶段,由高斯混合模型监督的检测器确定要聚焦的区域。第二阶段由clusters of objects的这些区域供给,预测这些区域内的对象。在合并对这些区域的预测时,利用了NMS和所提出的IBS方法来消除重叠和截断的边界框。
我们的贡献可以列举如下:
- 我们提出了一种名为“Focus&Detect”的框架,用于在航空影像中进行小物体检测,该框架基于区域搜索方法。
- 我们提出了一种使用高斯混合模型生成对象群集的方法,生成的群集经过尺度归一化处理。
- 我们还提出了“‘Incomplete Box Suppression”(IBS)方法,以抑制由重叠的聚焦区域引起的不完整边界框。我们提出的方法在VisDrone验证集上实现了42.06的AP得分,在UAVDT测试集上实现了54.16的AP@70得分。据我们所知,我们的方法在VisDrone数据集上优于文献中报告的小物体检测最新方法。
2 Related Work
略过
3 Focus-and-Detect
3.1 Overview
一般而言,航空影像上的目标检测性能受到小物体、物体视角变化、遮挡和截断的影响。使用高分辨率图像作为输入是解决小物体检测问题的一种简单方法。然而,高分辨率图像对深度神经网络来说会带来难以承受的计算成本。使用focusing机制并增加聚焦区域的分辨率具有这种简单方法的优点,但计算成本较低。如图1所示,航空图像上的检测包括两个阶段:Focus network,用于检测由物体群集构成的聚焦区域,detection network,用于在聚焦区域内检测物体。在合并预测后,应用后处理方法。具体而言,我们提出了Incomplete Box Suppression(IBS)机制,以从重叠的聚焦区域中抑制不完整的边界框。在合并预测的边界框后,我们还使用标准的非最大抑制(NMS)来抑制重叠的边界框。
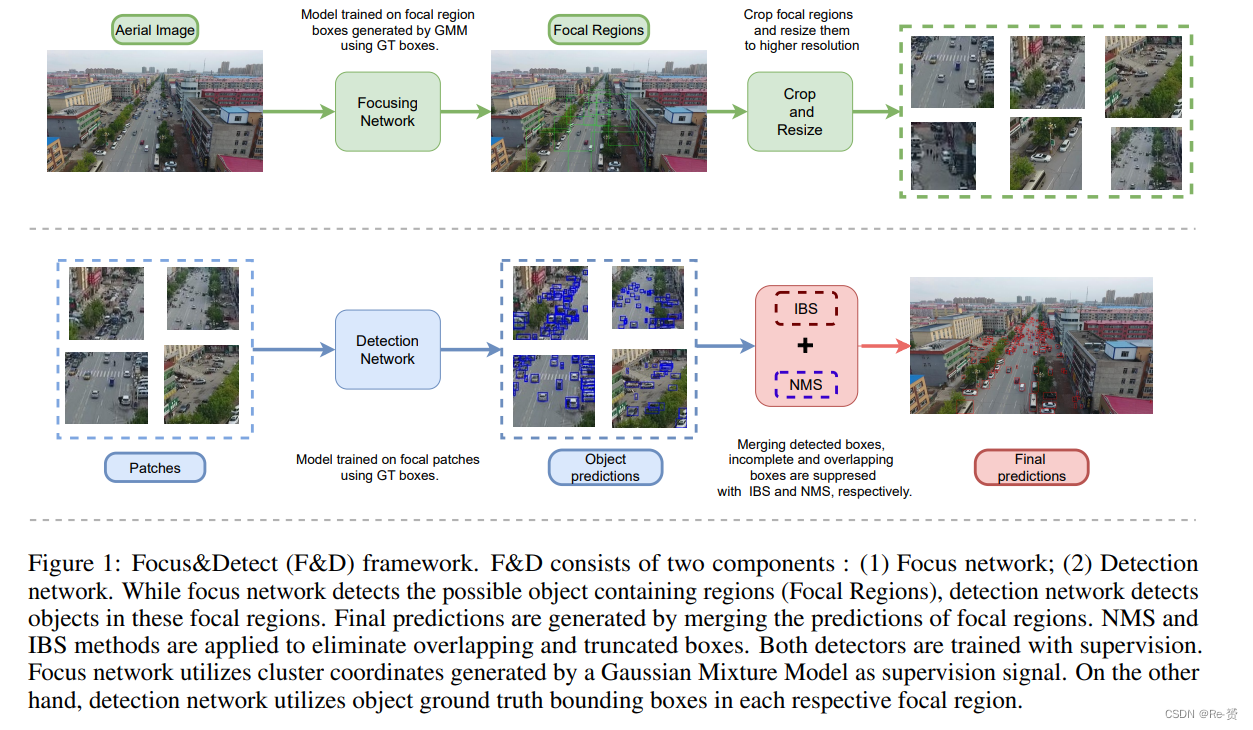
3.2 Focus Stage
聚焦阶段由一个目标检测网络组成,用于检测 focal regions。聚焦区域是通过由ground truth边界框训练后的高斯混合模型生成的。作为基础检测方法,选择了广义聚焦损失(GFL)。模型的主干是具有可变形卷积层的ResNet-50网络。模型的第二部分,即特征金字塔网络(FPN),旨在利用和优化从ResNet-50不同阶段获得的特征图,最后一部分是模型的检测头,用于预测聚焦区域的边界框。可变形卷积层在主干的最后三个阶段中被使用。
传统的卷积网络由于卷积层和池化层的受限形式,在几何变换上具有有限的性能。传统的网络架构在聚焦区域检测任务上表现不佳。聚焦区域features的可转移性不如传统对象特征的可转移性。为了提高学到features的可转移性,使用了可变形卷积层在ResNet-50内部,因为可变形卷积可以动态地改变感受野。因此得到更好的聚焦区域representation。
整体框架的性能大部分取决于聚焦阶段。理想情况下,预测的聚焦区域必须包含所有物体边界框,且没有任何截断。然而,在这些区域中可能存在重叠的区域和截断的物体。这些问题通过将IBS方法作为后处理阶段来解决,下面会详细介绍。
3.2.1 Generating Ground-Truth Boxes of Focal Regions Using Gaussian Mixture Model
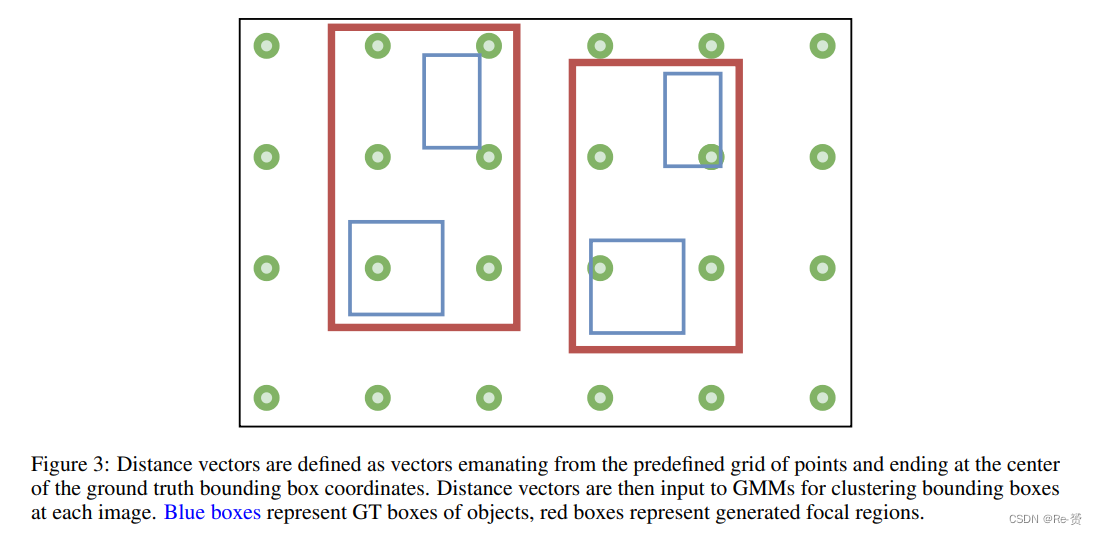
在目标定位问题中,同一类别中的物体区域可以用高斯分布建模,因为物体的尺寸变化不大。这个假设对于像MS COCO或PASCAL VOC 这样的目标检测数据集是成立的。然而,在像VisDrone 这样的航空图像数据集中,物体的区域因相机的角度和高度而有所偏移。与单一高斯模型不同,高斯混合模型是更好的选择,因为在将物体位置作为混合模型的输入时,多个高斯分布组成的混合模型由具有较小deviations。
在这个背景下,focal regions可以被定义为一组物体的群集,这些群集是通过一个以 ground-truth(GT)边界框的位置信息作为输入的高斯混合模型获得的。位置信息包括一个向量,表示边界框到图像中均匀采样点的网格的距离,如图3所示。与直接使用边界框坐标相比,这种方法可以获得更好的结果。
focal regions的数量是根据相应图像中的(GT)边界框数量来选择的。聚焦区域的数量(Nf)可以表示为:(即高斯混合模型中高斯函数的数量)
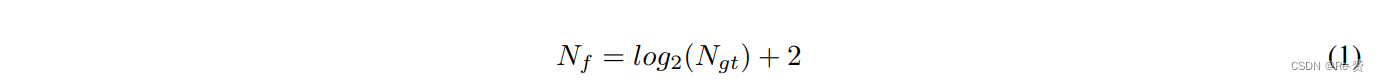
其中 Ngt 是(GT)边界框的数量。设 x ‾ \overline{\text{x}} x 是图像中第 i th 个 GT 边界框的大小为 1 × M 的距离向量,X 是大小为 Nf × M 的特征向量数组。高斯混合模型可以定义为:
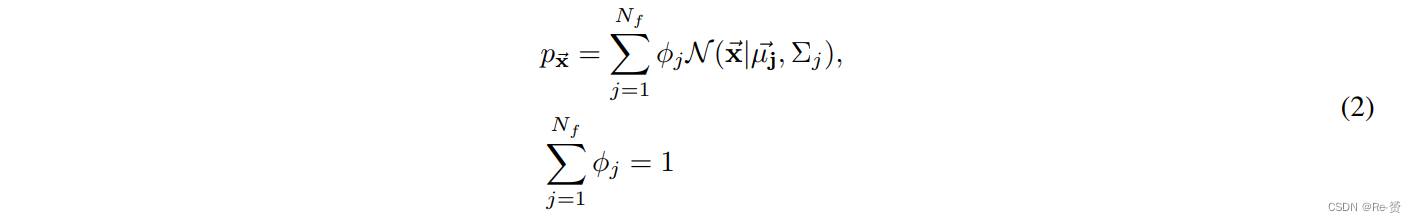
其中μj和σj分别是第j个聚类的均值和方差。
期望最大化算法(EM算法)被用来拟合这个模型。一旦EM算法运行完成,拟合的模型可以用来对GT边界框进行聚类。给定模型的参数,计算一个GT边界框属于某个聚类的概率如下(贝叶斯定理)
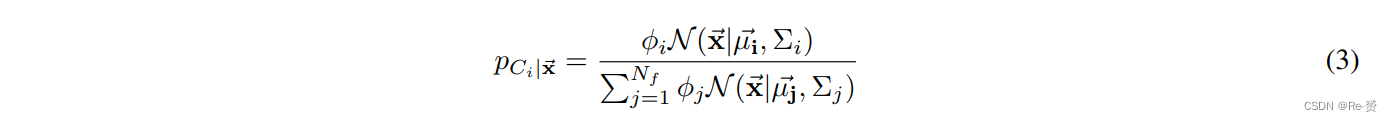
在计算完聚类后,聚焦区域被选择为包括各自聚类中的所有边界框的最小尺寸的框,每边留有20个像素的间隙。由于间隙的存在,聚焦区域中可能会有截断的物体。生成的聚焦区域被用作聚焦阶段的 ground truth边界框,如图4所示。

3.3 Detection Stage
在获得聚焦区域后,会使用专用的检测器对这些区域进行目标检测。获得的区域会被调整到更高的分辨率,这种方法有助于提高小物体检测的性能。
在这个阶段,广义聚焦损失(GFL)被采用作为基础检测器。模型的主干选用了带有可变形卷积层的ResNeXt-101网络。在颈部,使用特征金字塔网络(FPN)来通过使用来自不同阶段的特征来提高检测性能,而模型的最后部分是检测头,用于预测物体的边界框。可变形卷积层在主干的最后三个阶段中被使用。可变形卷积层相对于传统卷积层在检测小物体时产生更好的结果,因为它能够动态地改变其感受野,并提高了受到几何变换影响的检测性能。
在检测阶段,使用 GMM(高斯混合模型) 获得的聚焦区域会被裁剪和调整大小,以获得一组新的数据。GT边界框会被获得并细化到聚焦区域裁剪中。如果至少有 30% 的边界框位于裁剪区域内,那么被截断的GT边界框也会被包含进来。
3.4 Post Processing
为了获得最终的物体边界框预测,必须将检测阶段的预测与聚焦区域模型输出的预测合并。为了提高性能,应用的后处理步骤包括 Incomplete Box Suppression(IBS)和非最大抑制(NMS)。
3.4.1 Incomplete Box Suppression
利用区域搜索的模型存在一些问题。例如,合并目标区域的检测可能会很困难,因为可能存在重叠的区域和截断的物体。这个问题导致了在同一个物体上有多个边界框预测。由于截断,预测的边界框并不完全重叠。因此,非最大抑制无法抑制这种类型的错误预测。然而,这些预测会降低AP得分。
一般而言,非最大抑制用于消除高度重叠的边界框。对于传统的目标检测问题,它运行得足够好。然而,在大多数区域搜索方法中,还存在一个最终的步骤,即合并目标区域的预测。这就产生了一个新问题。这些区域中的重叠和截断的物体降低了整体性能,因为检测器可能会为同一个物体预测一个完整版本的边界框和一个截断版本的边界框,如图5所示。通常,这些边界框的交并比很小,因此它们能够逃脱非最大抑制。截断的物体本身也是一个问题。截断物体的错误类别预测很常见。结果,假阳性增加,AP得分下降。Incomplete Box Suppression(IBS)被提出来减少这些问题。
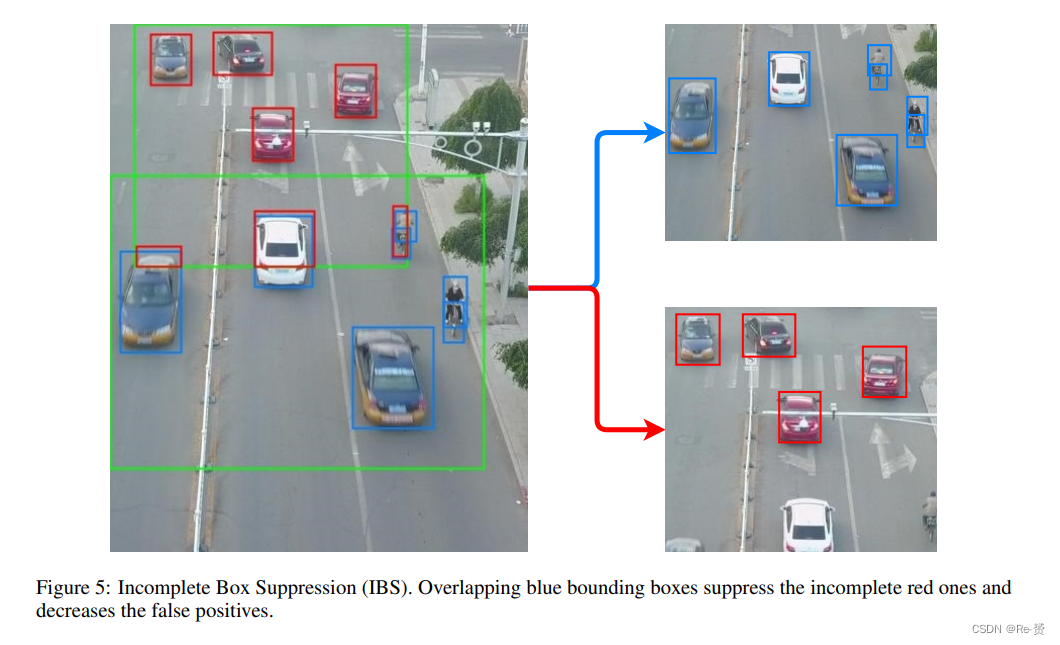
从本质上讲,IBS与NMS算法有相同的原则:找到重叠的边界框,选择具有最高置信度值的边界框,然后抑制其他边界框。虽然NMS使用简单的交并比(IoU)阈值来查找重叠,但在IBS中,重叠的聚焦区域和物体边界框都被用来决定要抑制哪个边界框。
设 Ci 表示第 i 个聚焦区域的坐标,Bij 表示该区域中第 j 个边界框的坐标。
- 第一步是计算聚焦区域 Ci 与其他聚焦区域之间的交并比(IoU),以找出 Ci 的重叠区域。通过将计算得到的 IoU 应用于阈值,可以获得重叠的聚焦区域。
- 第二步是将重叠聚焦区域内的边界框坐标剪裁为第 i 个聚焦区域的坐标,并收集面积大于零的边界框。
- 最后一步是计算剪裁边界框与 Bij 之间的 IoU。如果任何 IoU 分数大于所选的阈值,则抑制 Bij。
聚焦区域的 IoU 阈值是根据实验选择的,一般设为 0.05,边界框的 IoU 阈值也是实验选择的,一般设为 0.5。这些阈值用于确定是否要抑制重叠的边界框,从而最终得到合并后的预测边界框。
3.4.2 Non-max Suppression
在合并聚焦区域之后,会应用非极大抑制(Non-Max Suppression,简称NMS)来抑制重叠的检测结果。一些重叠的聚焦区域可能包含相同的物体,从而导致重复的边界框预测。为了减轻这种情况,会选择具有最高置信度的边界框,并抑制其他边界框。NMS的交并比(IoU)阈值通常选择为0.5。
4 Experimental Results
4.1 Implementation Details
我们基于公开可用的 MMDetection 和 PyTorch 来实现 “Focus&Detect”。在聚焦阶段和检测阶段,我们选择了带有特征金字塔网络的广义焦点损失(Generalized Focal Loss)。在聚焦阶段和检测阶段分别使用了 ResNet-50 和 ResNeXt-101 作为特征提取网络。通过使用NMS和IBS来合并聚焦区域的检测结果以获得最终的预测。
Training phase:聚焦阶段的输入尺寸在每个步骤中从 400 × 1400 随机采样到 1200 × 1400,样本在 VisDrone 数据集上均匀分布。对于 UAVDT 数据集,聚焦阶段和检测阶段的输入尺寸分别从 400 × 1000 随机采样到 800 × 1000 和 400 × 800 随机采样到 800 × 800。翻转增强以概率 0.5 进行。对于聚焦和检测模型,使用带有动量的梯度下降,权重衰减和学习率调度。两个模型均进行了 24 个 epoch 的训练。我们将初始学习率设置为 0.01,在第 16 和 22 个 epoch 时,学习率分别降低到 0.001 和 0.0001。动量的 Beta 参数对两个模型均选择为 0.9。权重衰减的比例为 0.0001。两个模型都使用了同步批归一化(Synchronized Batch Normalization)和组归一化(Group Normalization)在主干网络和特征金字塔网络上。
Testing phase:在使用 VisDrone 数据集进行实验时,聚焦模型和检测模型的输入尺寸分别选择为 1200 × 1400 和 600 × 1000。另一方面,在使用 UAVDT 数据集进行实验时,聚焦模型和检测模型的输入尺寸分别选择为 600 × 1000 和 600 × 800。在合并聚焦区域的检测结果时,应用了 NMS 和 IBS。NMS 的交并比(IoU)阈值为 0.5。在 NMS 之后,应用 IBS 以减少聚焦区域中截断物体造成的假阳性。IBS 的 IoU 阈值分别选择为 0.05 和 0.5,其中第一个阈值用于重叠的聚焦区域,第二个阈值用于在剪裁之后的聚焦区域中重叠的截断物体。
4.2 Dataset and Evaluation Metric && 4.3 Results && 4.4 Ablation Study
略过
5 Conclusion
A two stage framework is proposed to solve small object detection problem in aerial images. The proposed method is region search based where we utilize a Gaussian Mixture Model to generate focal regions for object detection. GMM method has a normalization effect on GT box sizes as cropping and resizing the image to a fixed resolution relatively forces objects to an average size for each class. We also propose the Incomplete Box Suppression (IBS) method to mitigate the truncated box problem that arise while merging the target regions.
Results show that the proposed IBS method improves the detection performances of all classes, especially of small object classes. GMM clustering normalizes the object scales across regions and increases overall performance. Furthermore, our method achieves the state-of-the-art performance on VisDrone validation set and UAVDT test set comparing to other small object detection methods, reported in the literature. Moreover, our method obtains the best APS score among all other methods, which indicates the positive impact of the proposed framework on small object detection