【数仓建设系列之三】数仓建模方式及如何评估数仓完善性
上篇文章我们对数仓的分层架构及核心概念做了简单介绍,同时也指明DW层是数仓建模的核心层。本篇文章,将详细从常见的维度模型建设手段及如何评估数仓建设的完善性展开讨论。
一、数仓维度建模
数仓维度建模是一种强大的方法,用于将复杂的业务现实映射到易于理解的数据结构中,它是构建数据仓库的核心技术之一,能够帮助企业将分散和不一致的数据整合到一个一致性高、可查询的数据存储中。通过将业务过程、维度信息和度量指标等要素转化为清晰的关系模型,揭示出隐藏在数据背后的模式和趋势。
目前市面上主流的维度模型主要包含 :星型模型,雪花模型和星座模型,接下来我们将一一讨论每个模型的优劣势。
(1)星型模型
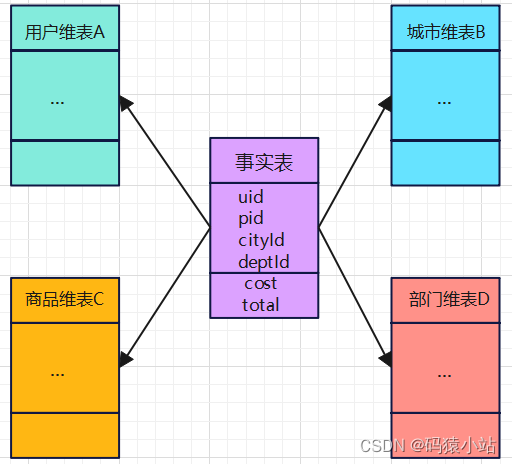
星型模型是维度建模中最为常见且广泛使用的方法之一。它依赖于一张事实表和多张维度表。事实表为基本结构中心,周围环绕着多个维度表,这种形状类似于一个星星,因此而得名。在星型模型中,事实表中每一条数据都表示一个特定的业务事件或交易场景,内部数据是可以根据需求进行聚合的,而维度表则是描述业务事件的不同维度属性,可以是时间,地点,客户,产品等。这种模型使得查询和分析变得直观和高效,数据分析可以通过外键对两张表进行关联,轻松地从不同的角度分析数据。
- 优势:
建模方式简单,结构清晰, 在简化查询和分析方面具有很大优势;
- 不足:
随着企业业务需求的不断扩张,分析场景会愈发复杂,这种简单的模型有时候在很大程度上并不能满足实际的需求,同时,如果不合理设置维度或定义数据结构,可能会导致数据冗余过大,引起性能瓶颈。
(2)雪花模型
雪花模型在某种程度上是星型模型的一个变种,它也是基于一张事实表和多张维度表构建而成的。但它在维度表的设计上更加详细,通常会将一个维度表拆分为多个相关联的更细粒度的子维度表,这样做的目的是将维度表中的属性进行规范化,减少数据的冗余和提供数据的一致性。

- 优势:
减少了数据的冗余,因为维度表的属性被标准化并存储在单独的表中,可以提高数据的一致性,并降低存储成本。另外,雪花模型在某些情况下能够更好地应对高度规范化的业务需求,例如需要多个维度层次或者复杂的属性分组。
- 不足:
因为需要进行更多的维表关联,因此雪花模型的查询更为复杂,主要体现在SQL维护层面和查询耗时上。其次,从上图也能看出来,维表会随着业务事件的发展,不断扩张,所以就需要维护更多的表,在一定程度上,也增加了数仓维护的成本。
(3)星座模型
星座模型是一种高度灵活的方法,它结合了星型模型和雪花模型的特点,旨在处理更为复杂的业务需求。它将多张维度表共享属性抽离出来,形成一张共享维度表,多张事实表共同关联共享维度表,减少数据的冗余,使得维表数据一致统一,也更方便维护。它适用于需要同时兼顾数据查询性能和数据标准化的场景,能够平衡数据冗余和灵活性之间的关系,因此可以适应多种不同的业务需求,企业数仓建模大多选择星座模型。
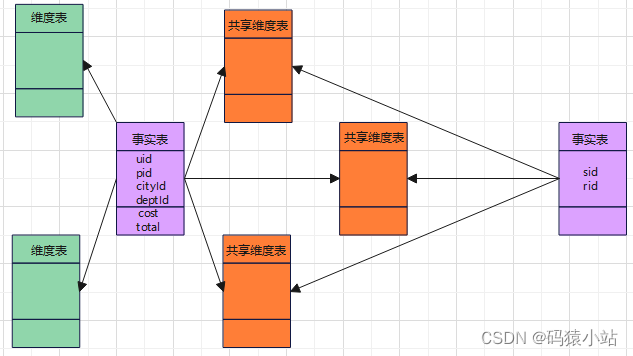
- 优势:
星座模型在设计时更加注重灵活性和性能,它将多个维度表中的共享属性抽取出来,放置在一个共享维度表中,这样可以减少数据冗余并提高维度数据的一致性。其次,事实表与维度表之间的关系更加直接,有助于提高查询性能,因此可以适应多种不同的业务需求。
- 不足:
模型的复杂性可能会增加查询的复杂性,同时维护共享维度表可能需要更多的注意和管理。
综上3种模型,我们可以看出,每种模型都有自己的优劣势,如何选择一款合适的模型是需要综合考量和评估业务需求,性能要求以及维护复杂性等因素的。我们在企业中可以灵活选择,最终的目的其实都是在尽可能不增加维护成本的前提下,更好的解决企业需求。
二、如何评估数仓建设完善性?
上面主要讲述了数仓建模主流模型框架,每个企业都可以按需选择最符合自己需求的一个模型,但我们需要从以下几点考量一个数仓建设的完善性:
1.完善性
完善性主要体现在数据的丰富度,简单描述就是每一层被其上层引用的次数和比例。比如ODS层被DWD层引用的表有多少,占ODS层所有表数量的比例是多少;DWD层的表被DWS层引用了多少,占DWD层总表数量的比例是多少,以此类推。其次,在建模过程中,完全不跨层引用是非常完美且理想的一种状态,但在实际过程中,却很难做到不跨层引用,因此,我们也可以适当统计跨层引用的比例是多少。除此之外,我们也可以统计上层表(DWS和ADS)表被引用查询的次数是多少,这也能从侧面反应出一张表的完善性如何。引用比例是一个正向值,值越高,说明上层建设的越完整,通过这种简单统计,我们就可以粗略估算出数仓建设的完整性。
2.高效性
高效性主要包括开发高效性和查询高效性。开发高效性主要是说,我们在开发一个上层报表或查询接口时,能否减少底层建设?是否能够复用一些已经存在的维表或事实表,通过简单的关联,就能快速抽离出一张上层需要的汇总数据。查询高效性主要体现在做查询时接口耗时如何,当然,接口耗时的影响因素众多,抛开其他因素不谈,如果能在一定程度上减少表与表之间的关联,对查询效率的提升肯定是有很大帮助的。因为在企业中,很少会有单表查询的场景,大部分都需要进行关联查询得到最终结果。因此,我们需要采用一些维度退化的手段,尽量减少关联表的数量。
3.规范性
规范性存在于各行各业。每个行业的规范性也各不相同,比如我们在java开发时,需要遵循开发的规范性,比如类名首字母大写,方法名见名知意等等。在数仓建设中,规范性主要体现在以下几点:分层规范性,库表规范性和字段规范性。
3.1.分层规范性:
-
主要体现在分层数据表的结构是否清晰;
-
上层数据能否屏蔽掉底层错误数据的影响;
-
是否能够快速追踪数据血缘信息;
-
维度表设计是否规范,是否能够提高复用性并减少数据冗余;
3.2.库表规范性:
-
库表命名需要体现数据的含义和用途,数据从那个业务系统来,当前数据属于数仓哪个分层 ,准备把数据应用在哪个方面;
-
表的数据模型,分区,分桶,副本数量和索引设置是否合理,是否能够容灾同时能够提高SQL查询性能;
3.3.字段规范:
-
同一个字段在不同的表中,数据类型和命名是否一致;
-
表与表之间的主外键能够清晰的从字段上明确;
-
表中每个字段的维度,度量含义是否清晰等;
4.安全性:
-
控制不同用户对库表的操作权限,比如针对A业务组的分析同学,只能看到A业务组下部分业务数据;
-
不同分层的表权限也不一样,比如ODS层,数据分析同学,只能进行查看操作,不能修改表结构和增删数据;
-
提供统一的访问接口,避免业务系统直连数仓
以上就是数仓建设完善性的部分指标描述,其实,在数仓建设中,还有很多需要我们去注意和控制的点,包括:数据生命周期管理,数据质量管理,数据审计和版本控制等等,每一块内容都需要我们不断的摸索和实践。
三、总结
通过本篇文章,我们基本了解了数仓模型分类和其优劣势,同时也对数仓完善性建设有了大概的认知。在实际生产环境中,需要我们不断的探索和踩坑才能满足和提高源源不断的复杂业务场景。接下来,将从数仓开发规范展开讨论。