吐槽一下:
在我第一次看到链表这个东西的时候,我觉得数据结构好难啊,怎么这么难理解啊,这是什么玩意啊,结果慢慢的我才发现,链表是除了顺序表最简单的一个数据结构了;我以为我学完了链表,我就很牛了,后面才发现我连数据结构的门坎都没没摸到。下面来看下链表到底是个什么玩意。
链表:
需要提示一下,对于C语言中的指针不熟悉的小伙伴,我会在出一个专门讲指针的一篇文章,因为数据结构中,对于指针的使用是非常多的。
它的数据结构:
在顺序表的那篇文章中,我提过数据结构 = 结构定义 + 结构操作;
那么链表的结构定义是什么?他的物理结构和逻辑结构分别是什么?在学习一个新的数结构之前需要这要问一下自己,这样你的思路会更清晰,也不会混乱;
物理结构:他是由节点组成的,然后每个节点里面,有一个值域,有一个指针域;
值域是什么,用来存数据的,就像数组每个位置存的值一样;
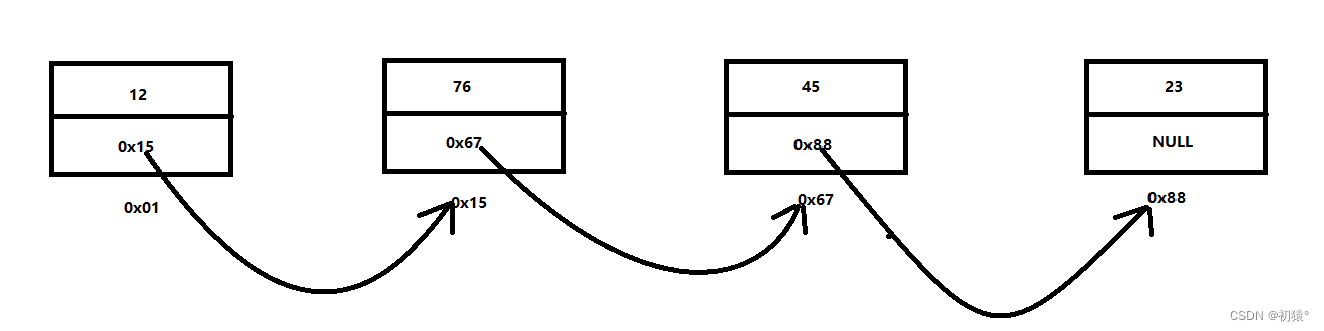
指针域存的是什么,用来存他下一个节点的地址的,已能通过该节点找到下一个节点;这样就这个把每个结点串联起来,形成一个链状;大概就是图1的样子
图1
那么他的结构定义用代码实现是怎么样的,来看下面的代码:
typedef struct Node {//结点定义void val;//值域,可以是int,char等等类型struct Node *next;//指针域,用来存下一个结点的地址的 } Node;可能会有小伙伴会问,不是链表吗?怎么就定义结点?其实只要有头节点,是不是可以找到链表的每一个结点,因为每个结点中有存着下一个结点的地址,假如现在在头结点,是不是可找到头结点的下一个结点,同样的道理可以找到下下个结点,直到找到末尾;他是通过像图2的方式来找寻下个结点的;每个矩形上方代表值域,下方代表指针域:
为了让你们更好理解后面的结构操作,我还是把链表的结构定义写出来:
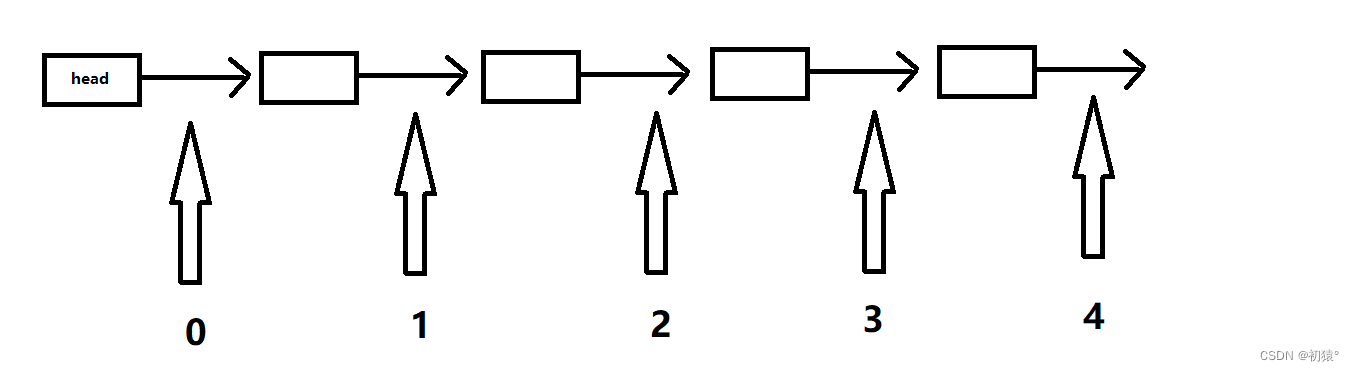
typedef struct List {//链表int len;//结点个数Node *head;//头结点 } List;逻辑结构:链表在我们的思维中,也就是我们的脑子中以为他是连成一串的,就像图1的样子一样,但是在计算机中他的样子可能是图3的样子:
图3
而图3中的样子才是链表在计算机中的真实样子;
它的结构操作:
了解完它的结构定义之后,一定要把结构定义刻在脑子里,就像你忘不了你的昨天晚上那场王者荣耀你mvp被0-14的队友嘲讽的那场比赛一样;
对于数据的操作,无非就是增删改查嘛,下面我会实现增删两个操作,改查可以自己去摸索一下自己尝试后,你就会发现这**博主讲东西只讲一半;
下面是代码实现:
#include <stdio.h> #include <stdlib.h> #include <time.h>typedef struct Node {//结构定义结点int val;struct Node *next; } Node;typedef struct List {//结构定义链表int len;Node head; } List;Node *getNewNode(int val) {//初始化,获取新节点Node *n = (Node *)malloc(sizeof(Node));n->val = val;n->next = NULL;return n; }List *getNewList() {//初始化,获取新链表List *list = (List *)malloc(sizeof(List));list->len = 0;//为什么为0,因为链表结构中这个头结点是虚拟的不纯在的list->head.next = NULL;return list; }int insertNode(List *l, int val, int ind) {//插入结点,从虚拟头结点开始数位置从0开始到l->len的位置中间插入结点if (!l) return 0;if (ind < 0 || ind > l->len) return 0;//如果插入位置小于0,或者大于了l->len的值,说明插入位置不在链表中Node *p = &(l->head), *n = getNewNode(val);while (ind--) p = p->next;n->next = p->next;p->next = n;l->len++;return 1; }int eraseNode(List *l, int ind) {//删除结点if (!l) return 0;if (ind < 0 || ind >= l->len) return 0;//l->len位置是没有结点的,插入的时候就是插入在l->len的位置 Node *p = &(l->head);while (ind--) p = p->next;Node *temp = p->next;p->next = p->next->next;free(temp);l->len--;return 1; }void clearNode(Node *n) {//删除结点,借了计算机的就要还回去if (!n) return ;clearNode(n->next);free(n);return ; }void clearList(List *list) {//删除链表if (!list) return ;clearNode(list->head.next); free(list);return ; }void output(List *list) {//打印链表printf("List(%d) = ", list->len);Node *p = list->head.next;while (p) {printf("%d--->", p->val);p = p->next;}printf("NULL\n");return ; }int main() {srand(time(0));int op, val, ind;List *list = getNewList();for (int i = 0; i < 20; i++) {op = rand() % 4;val = rand() % 100;ind = rand() % (list->len + 2) - 1;switch (op) {case 0:case 1:case 2: {printf("%d insert in List %d is %d\n", val, ind, insertNode(list, val, ind));} break;case 3: {printf("erase in List %d is %d\n", ind, eraseNode(list, ind));} break;}output(list);}clearList(list);//记得还给计算机return 0; }


整段代码以及实现了,现在会有小伙伴,理解不了删除和插入结点的情况,下面我讲解一下:
插入结点:
也就是增加结点,指定了一个位置
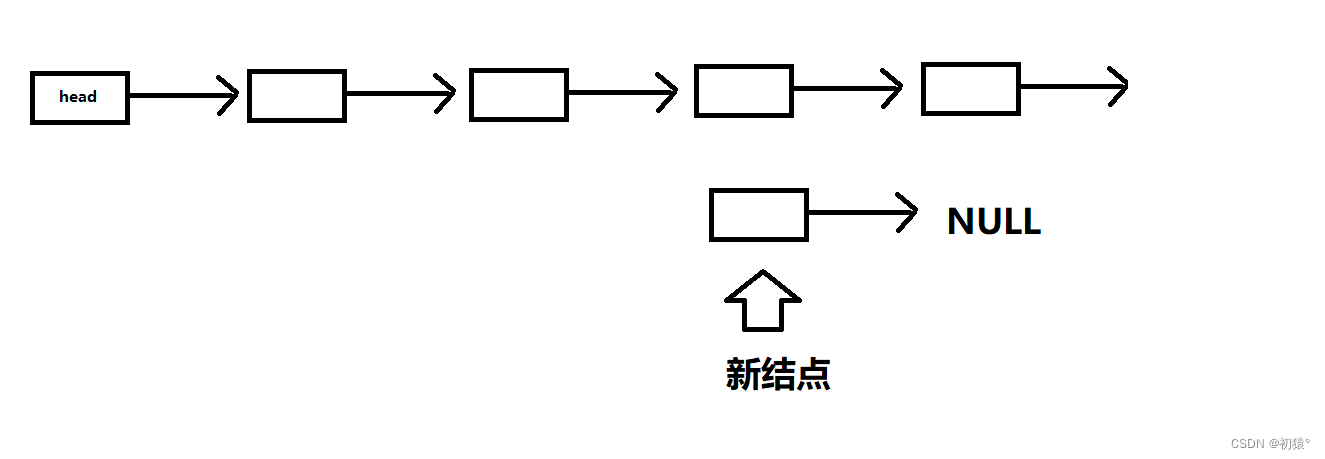
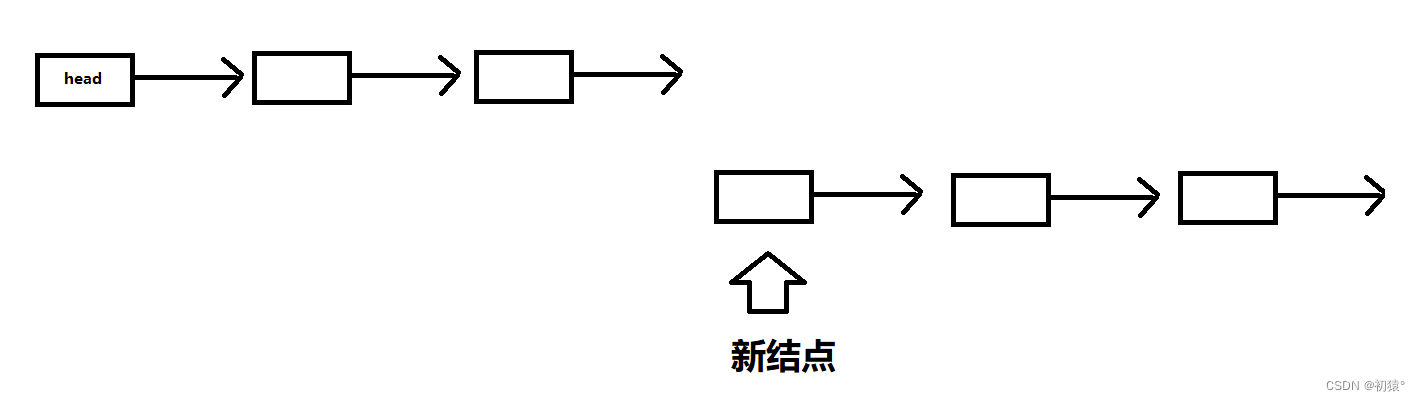
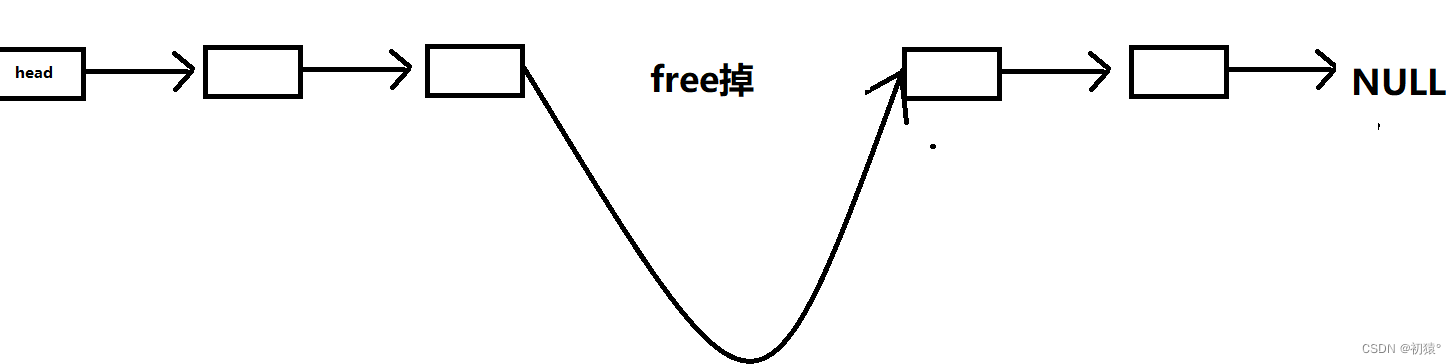
上面讲了,head是虚拟头结点,它是我们思想中的一个结点,它的值域是无效的,也就是说他的值域是没用的,然后为什么需要这个虚拟头结点,因为在增加删结点时,我们需要找它对应的前一个结点的位置,才能更方便的去增删;现在是增加结点,你需要怎么去做上面操作?是不是需要把它的上一个结点的指针域改为增加结点的地址,然后增加结点的指针域改为上一个结点之前存的地址,这样链表就链接起来了;这两步我说反了,因为如果你先去覆盖了上一个结点的指针域,也就是把新结点的地址去覆盖了之前的值,那么你就会丢失后面链表;就像这样
你会发现,你找不到后面结点了,所以需要先把后面的结点接在结点的指针域上,在去覆盖前一个结点的指针域,这样才是正确的顺序插入结点;现在把代码拿过来看一下:
int insertNode(List *l, int val, int ind) {if (!l) return 0;if (ind < 0 || ind > l->len) return 0;Node *p = &(l->head), *n = getNewNode(val);//n为新添加的结点while (ind--) p = p->next;//while循环后,p现在是插入结点的前一个结点//假如ind为0,那么p是不是虚拟头结点的位置,那么就可以在头结点的位置插入结点,也就是位置0//可以发现虚拟头结点的好处就是不用去判断是否在链表的头尾还是中间插入结点,减少了代码量n->next = p->next;//新节点的指针域去存前一个结点的下一个结点的地址,也就是接上后面的结点p->next = n;//前一个结点在接上新的结点,完成了插入结点的操作l->len++;return 1; }n->next = p->next; p->next = n;这两行代码就是下面3张图片的操作:
删除结点:
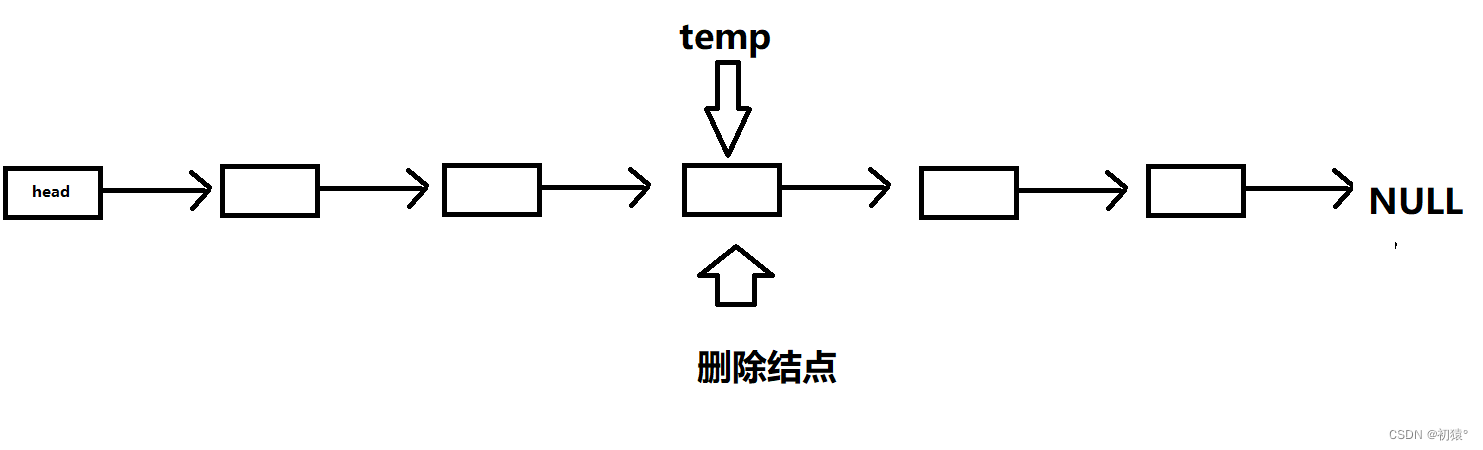
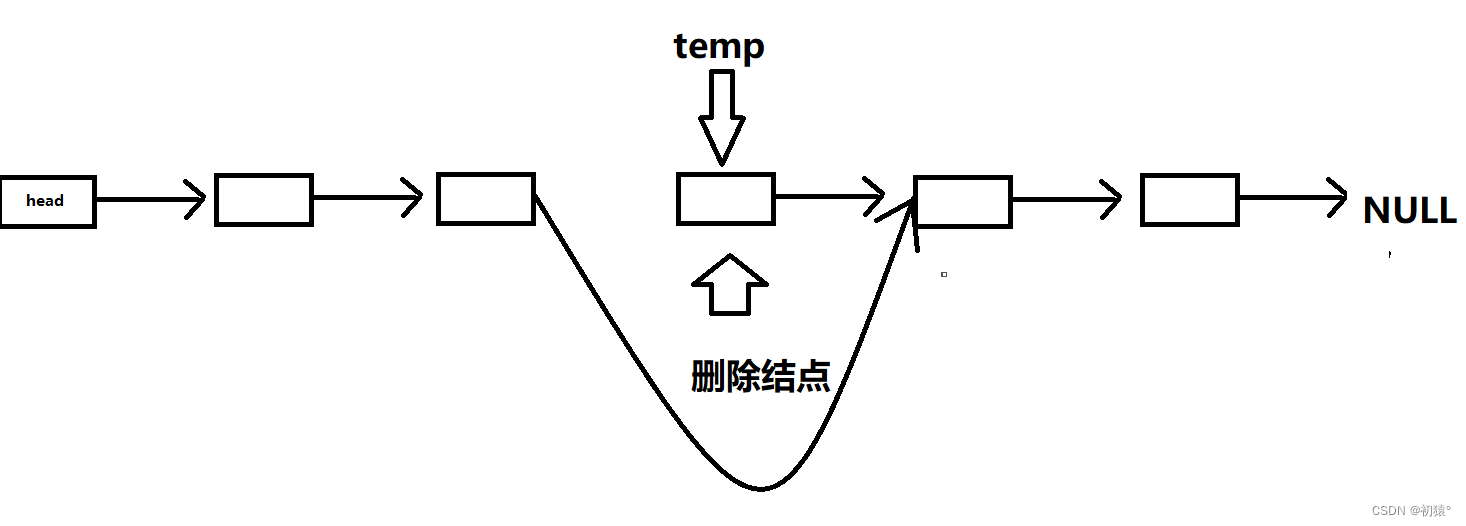
其实和插入结点差不了太多,同样和增加结点一样,找到删除结点前一个结点,然后通过前一个结点来获取到前一个结点的下下个结点的地址,然后来覆盖前一个的指针域,现在删除的结点成为了单独的结点,然后free掉还给计算机,老子不借了;
先来看代码:
int eraseNode(List *l, int ind) {if (!l) return 0;if (ind < 0 || ind >= l->len) return 0;Node *p = &(l->head);while (ind--) p = p->next;//获取到删除结点的前一个结点Node *temp = p->next;//用一个指针指向,删除结点,防止丢失;如果你没记录下来丢了,那你就去找吧,反正我没有办法找到p->next = p->next->next;//p->next现在表示的是前一个结点的指针域,然后用下下个结点的地址来覆盖掉,也就是接上下下个结点free(temp);//给删除的结点还给电脑,老子不用了l->len--;//最后链表的长度记得减1return 1; }理解不了代码的小伙伴来看图:
OK完成删除操作,非常完美



看到这儿的小伙伴我觉得应该都差不多理解了,现在直接来一道leetcode题目,练练手直接起飞!
leetcode19:删除倒数第N个结点,我们刚刚删的是正数的,现在是倒数的,嗯,看到脑壳痛,刚刚正的都没搞清楚,现在又来反的了;
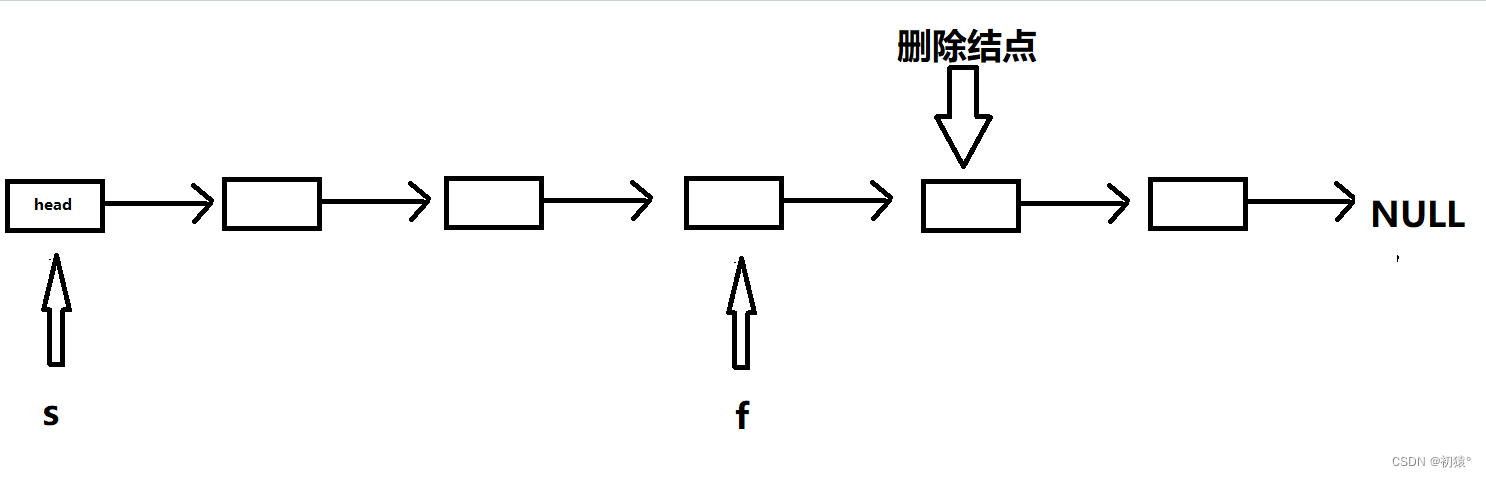
这个题需要用到双指针,也就是两个指针变量,一个指针为f快指针,一个为s慢指针;f先走N + 1步,假如N为2,结点个数为5
这里只是巧合f到了删除结点的前一个结点,然后f,s同时往前移动,直到f到达NULL:
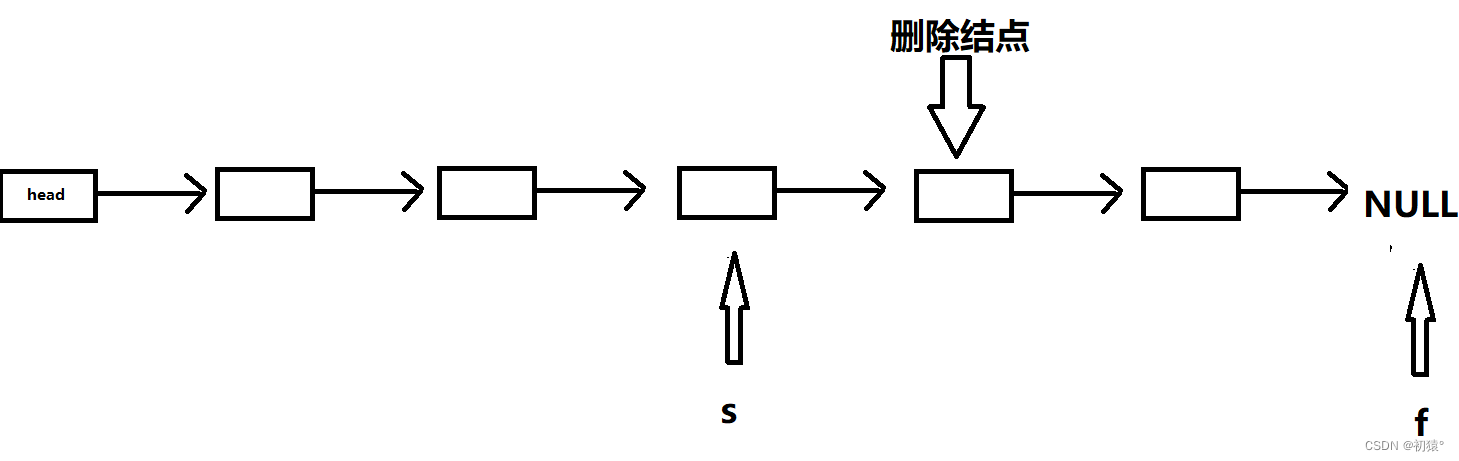
s到大删除结点的前一个,那么就和上面删除结点的操作一样了;
现在来说为什么成立f总共走了len + 1步,len为结点个数,为什么+1,因为它走到了NULL的位置还有一步;
那么s走了多少步 len + 1 - (N + 1);len + 1为f走的步减去,它之前先走的步数那么最终s走了len - N步;
那么步就得到了正着数的步数了嘛,那不就简单了嘛,和我们实现的删除操作是一样的拉嘛;
现在来看代码
struct ListNode* removeNthFromEnd(struct ListNode* head, int n){if (!head) return head;struct ListNode *s, *f, xuni_head;//没有虚拟头结点,那就自己创一个xuni_head.next = head;//虚拟头结点指向头结点s = &(xuni_head);f = head;//因为f要走n+1步那么我就先走一步while (n--) f = f->next;//f在走n步while (f) {//同时走,直到f到NULLf = f->next;s = s->next;}f = s->next;//f获取删除结点位置s->next = s->next->next;//链接上删除结点的后面结点位置free(f);return xuni_head.next; }
谢谢观看,觉得如果对你有帮助,可以点个赞,也是对我的鼓励;