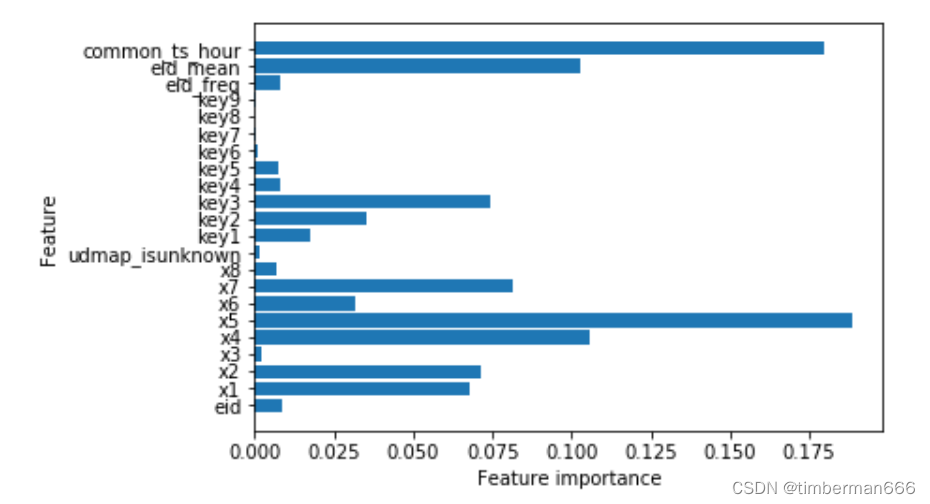
DEFORMABLE DETR
DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION
参考:AI-杂货铺-Transformer跨界CV又一佳作!Deformable DETR:超强的小目标检测算法!
摘要
摘要部分,作者主要说明了如下几点:
- 为了解决DETR中使用Transformer架构在处理图像特征图时的局限性而导致的收敛速度慢,特征空间分辨率有限的问题;
- Deformable DETR只关注和参考周围的一小部分关键采样点(例如对一个输入到encoder中的图片拉直后的向量,每个像素点只关注其周围的几个像素点,互相计算相似度即可,不需要和所有的像素点计算相似度),并获得了更好的效果(尤其是在小目标任务当中),收敛时间相较于DETR减少了近10倍;
延伸:YOLO检测小目标效果不好是因为网络越深检测小目标的效果越不好,同时YOLO中图片的输入尺寸较小
介绍
DETR存在的问题
原始的DETR需要更多的Epochs数量才收敛;DETR在检测小物体时性能不好,导致检测小物体性能不好的原因是因为Transformer架构在初始化时,其注意力模块对特征图中所有像素施加了几乎一致的注意力权重(即在初始化时,注意力机制没有被唤醒,特征图中的一些很有意义的像素点没有被注意力机制关注到),因此训练epochs数量很多(训练Epochs数量增加之后,就会激活注意力机制对图像特征的关注)。
同时,作者指出Transformer中的自注意力机制是针对于图像像素数量的二次计算,这在处理高分辨率特征图时会具有非常高的计算和记忆复杂性。(Transformer中计算复杂度与图像的宽度W和高度H成正相关,例如:一张图片为100x100,那么拉直之后输入到encoder的时候为10000,然后每个像素点与自己和其他像素点计算相似度,那么计算量就是10000x10000,就是十亿,计算代价太高,而且没有共享参数)这就导致原始的DETR是耗费大量资源的,同时还不能处理高分辨率图片。
Deformable Convolution(可变形卷积)
可变形卷积是一种处理稀疏空间位置的强大而有效的机制,这种机制可以很好地解决上述问题,但是可变形卷积缺少元素之间的关系建模机制,而关系建模(全局建模能力)是DETR成功的关键所在。
Deformable DETR中,可变形卷积思想的作用就是将原来的注意力机制中,每个像素点和周围的像素点进行相似度计算转为,每个像素点注意力进行偏移(使得每个像素点注意力在一些重要的地方),但是这样带来一个问题就是可变性卷积无法关注注意力集中的地方相似的特征,即点与点之间的关系建模等(为什么可变形卷积关注的是重要特征,希望模型去学习重要特征之间有什么关系),这就需要结合DETR的全局建模能力来解决这一问题。
Deformable DETR

Deformable DETR结合了可变形卷积的稀疏建模能力,同时又结合了DETR的关系建模能力。作者提出了可变形注意力模块,关注一小部分采样位置,作为所有特征图像素中突出关键元素的预滤波器。同时,该模块可以很轻松地扩展以聚合多尺度特征,而不需要FPN。
可变形注意力模块
针对某个像素点周边的像素进行采样,同时该模块还具有聚合多尺度特征的能力(在聚合多尺度特征的时候如果考虑细致的话需要进行特征对齐,如果考虑的不细致的话就是简单的拼接)。在该篇文章中,作者就做了对齐的操作。(延伸:使用FPN网络,例如类似于UNet一样,进行多尺度操作,这样的特征融合之后是没有对齐的,只是简单做了拼接操作)
作者提出的可变形注意力模块替代了传统的Transformer架构中的attention模块。
相关工作
相关工作对Transformer和DETR介绍较多,可以直接去读两者相关的论文。
文章主体部分(第四章-Methods)
Deformable Attention模块

文中指出,传统的Transformer中的注意力机制存在遍历所有可能的空间位置。(论文中“the deformable attention module only attends to a small set of key sampling points around a reference point, regardless of the spatial size of the feature maps,”,这句话中的reference point可以理解为:图片特征map中的一些坐标点(特征Map中的一些初始化位置点)。在论文对应的源码中,在每个坐标点周围只设置了K=4个采样点)
Deformable Attention公式理解
D e f o r m A t t n ( z q , p q , x ) = ∑ m = 1 M W m [ ∑ k = 1 K A m q k ⋅ W m ′ x ( p q + Δ p m q k ) ] DeformAttn(z_q, p_q, x)=\sum_{m=1}^M W_m[\sum_{k=1}^K A_{mqk}\cdot W'_m x(p_q + \Delta p_{mqk})] DeformAttn(zq,pq,x)=∑m=1MWm[∑k=1KAmqk⋅Wm′x(pq+Δpmqk)]
其中, x x x文中说明为图片的特征Map,但是实际上更可以理解为输入到Encoder中的序列,然后该序列的宽为W,高为H。其中每个点对应的channel通道数为C。文中设定 q q q索引一个叫做 z q z_q zq的内容query。(这里的内容query就是每个点对应的通道数为channel的特征向量)然后, p q p_q pq表示特征图Map中的某个q索引位置上的点。m表示多头注意力机制中的头的数量(源码当中设置为M=8)。k表示采样点数量,也就是从当前点开始与索引值在k这个范围内的所有点之间计算交互(源码中的K=4)。
公式中, Δ p m q k \Delta p_{mqk} Δpmqk表示采样偏移量,是需要通过训练得到的。 A m q k A_{mqk} Amqk表示在第m个注意力头中的第q个参考点周围的共k个采样点中每个采样点分配的注意力权重(也就是说K个采样点权重相加应当为1),也是需要训练得到的。

其中,蓝色点表示当前点(reference point),然后按照K=4的采样点数量,蓝色点周围的红色点是需要进行计算交互的,但是,由于红色点左上角的绿色点才是蓝色点真正地需要关注的,那么这个时候偏移量就是绿色点针对于蓝色点左边的红色点的偏移。

同时,还存在一个问题,如果上图中蓝色点关注右上角的黑色点的时候,注意力没有正好落在黑点上,那么这个时候,关注的点的权重是由其周围四个点根据距离加权之后得到的。
偏移量是由 z q z_q zq得到的,可变形机制就是说的偏移量可变。
公式中, W W W和 W ′ W' W′都是全连接层,也是需要训练来决定其中的权重的。偏移量是通过将feature map中每个点对应的特征 z q z_q zq输入到一个FC(包含W和b)中,在反向传播过程中去更新FC中的W和b即可。
原始论文中有语句:Both Δ p m q k \Delta p_{mqk} Δpmqk and A m q k A_{mqk} Amqk are obtained via linear projection over the query feature z q z_q zq.
其中, Δ p m q k \Delta p_{mqk} Δpmqk和 A m q k A_{mqk} Amqk是由 z q z_q zq输入到FC层中得到的。然后在实现的时候,作者说明:In implementation, the query feature z q z_q zq is fed to a linear projection operator of 3MK channels, where the first 2MK channels encode the sampling offsets Δ p m q k \Delta p_{mqk} Δpmqk, and the remaining MK channels are fed to a softmax operator to obtain the attention weights A m q k A_{mqk} Amqk.
Multi-scale Deformable Attention 模块理解(本篇论文的核心)
作者首先强调,多尺度在很多任务当中都很work,然后又说Deformable Attention Module模块也可以扩展到多尺度。

上式中, p ^ q ∈ [ 0 , 1 ] 2 \hat{p}_q \in [0, 1]^2 p^q∈[0,1]2表示对q索引对应的query element中的参考点的归一化坐标(相当于多尺度对齐)。
多尺度可变形注意力模块中,计算方式基本上和单尺度的一样,只是从原来的对单个feature map进行操作改为对L层多尺度feature map进行操作。这里需要注意的是,其中的 ϕ l ( p ^ q ) \phi_l (\hat{p}_q) ϕl(p^q)表示将归一化之后的坐标针对l层特征的大小,进行缩放,从而找到对应l层特征的参考点的实际位置,然后在该层特征下计算可变形注意力。

上图中是对上述公式的一个详细的形象化概括。其中,对于不同level的特征,其位置编码(positional encoding)除了该层级对应的位置编码之外,还需要加上一个层级的位置编码(主要是用来区分归一化坐标相同的点在不同层级feature map上具有实际不同的位置编码)。此外,这篇文章中的位置编码也是可学习的。
注意:上图中的Object Queries数量由传统的DETR的N=100,增加到了N=300