| Title:[DETRs with Collaborative Hybrid Assignments Training |
| Code |
文章目录
- 1. Motivation
- 2. one to one VS one to many
- 3. Method
- (1)Encoder feature learning
- (2)Decoder attention learning
1. Motivation
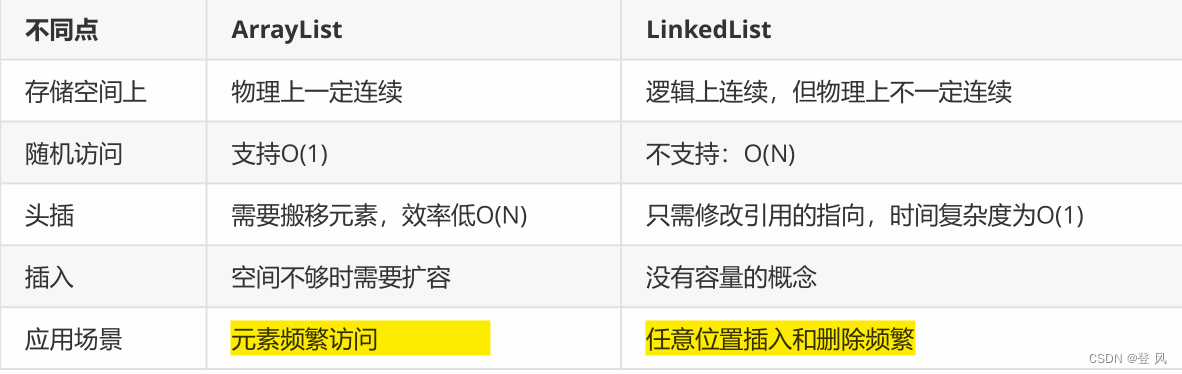
当前的DETR检测器中,为了实现端到端的检测,使用的标签分配策略是二分匹配,使得一个ground-truth只能分配到一个正样本。分配为正样本的queries太少,从而导致对encoder的输出监督过于稀疏(sparse)。
与二分匹配相反,在传统的检测器(如Faster-RCNN、ATSS)中,一个ground-truth会根据位置关系分配到多个anchor作为正样本。这种标签分配方式能够为特征图上的更多区域提供位置监督,就能让检测器的特征学习得更好。
Co-DETR的关键就是利用通用的one-to-many label assignments来提高DETR检测器训练encoder和decoder的有效性及效率。
2. one to one VS one to many
为了比较这两种不同的标签分配方法在Encoder特征图上的差异,论文直接把Deformable-DETR的decoder换成了ATSS head,使用相同的可视化方法进行了比较,效果如下:

很明显,一些显著区域中的特征在one to many matching方法中被充分激活,但在one to one matching中很少被激活。因此,论文认为正是这两种分配方式的差异使得DETR模型中的encoder特征表达能力减弱了。

同时,作者还对encoder生成的特征表示和decoder中的attention进行了定量分析:
- 左边的IoF-IoB曲线表明ATSS相较于Defomable DETR更容易区分前景和背景;
- 右边的IoF-IoB曲线表明Group DETR(其将更多的正样本query引入到decoder中)和Co-Deformable-DETR拥有更多的正样本query,其更有利于cross attention的学习。
最终的结论同样是:一对一匹配相比于一对多匹配会分别损害encoder特征和decoder中attention的学习。
3. Method

为了能够让DETR检测器利用到一对多匹配的优势,论文基于DETR的训练框架引入了两点改进,分别对应到上文提到的encoder feature learning和decoder attention learning。
Co-DETR只在训练阶段加入辅助检测头,因此仅在训练阶段中引入额外的计算开销,不会影响到模型推理的效率。
(1)Encoder feature learning
在上文的分析中,我们发现在encoder后插入一个传统的ATSS检测头就能让encoder的特征更加显著。
受到这个的启发,为了增强encoder的学习能力,论文首先利用multi-scale adapter,将encoder输出的特征转化为多尺度的特征。
对于使用单尺度特征的DETR,这个adapter的结构就类似于simple feature pyramid。而对于多尺度特征的DETR,这个结构就是恒等映射。之后我们将多尺度的特征送入到多个不同的辅助检测头,这些检测头都使用一对多的标签分配。
由于传统检测器的检测头结构轻量,因此带来的额外训练开销较少。
(2)Decoder attention learning
为了增强decoder的attention学习,我们提出了定制化的正样本query生成。
在上文的分析中,我们发现传统检测器中的anchor是密集排列的,且能够提供dense且尺度敏感的监督信息。
那么我们能不能把传统检测器中的anchor作为query来为attention的学习提供足够的监督呢?当然是可以的,在上一步中,辅助的检测头已经分配好了各自的正样本anchor及其匹配的ground-truth。
我们选择直接继承辅助检测头的标签分配结果,将这些正样本anchor转化为正样本query送到decoder中,在loss计算时无需二分匹配,直接使用之前的分配结果。
与其他引入辅助query的方法相比,这些工作会不可避免地引入大量的负样本query,而我们只在decoder引入了正样本,因此带来的额外训练代价也较小。








![java八股文面试[JVM]——垃圾回收器](https://img-blog.csdnimg.cn/a56639a6c9c0481686b5d4b72b114552.jpeg#pic_center)