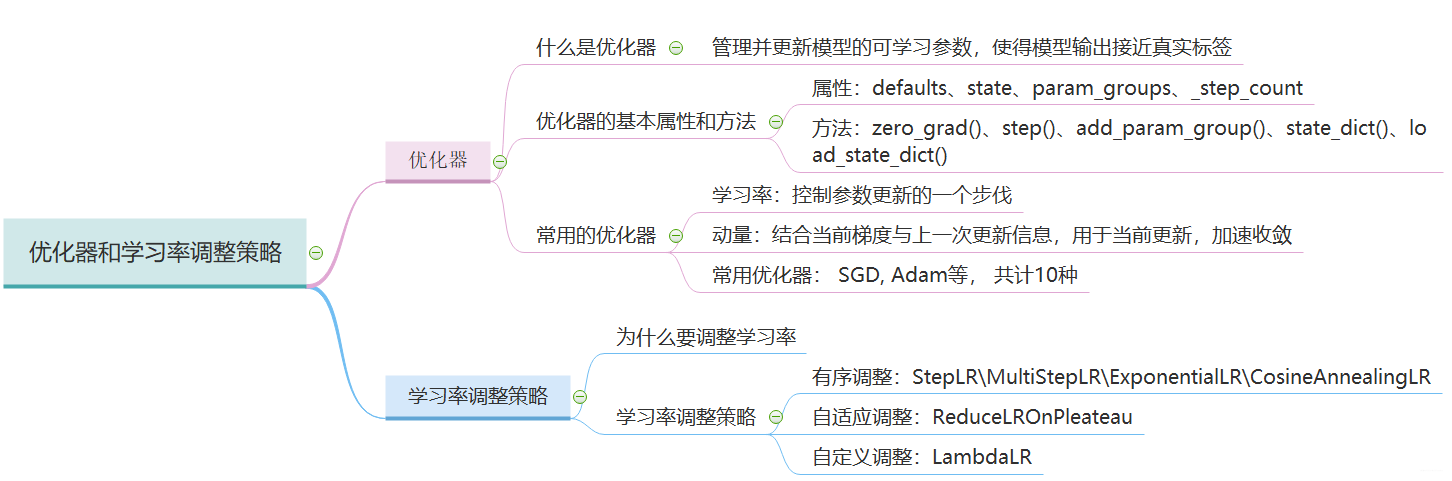
学习率是可以控制更新的步伐的。 我们在训练模型的时候,一般开始的时候学习率会比较大,这样可以以一个比较快的速度到达最优点的附近,然后再把学习率降下来, 缓慢的去收敛到最优值。学习率前期要大,后期要小
在学习学习率调整策略之前,得先学习一个基类, 因为后面的六种学习率调整策略都是继承于这个类的,所以得先明白这个类的原理:

主要属性:
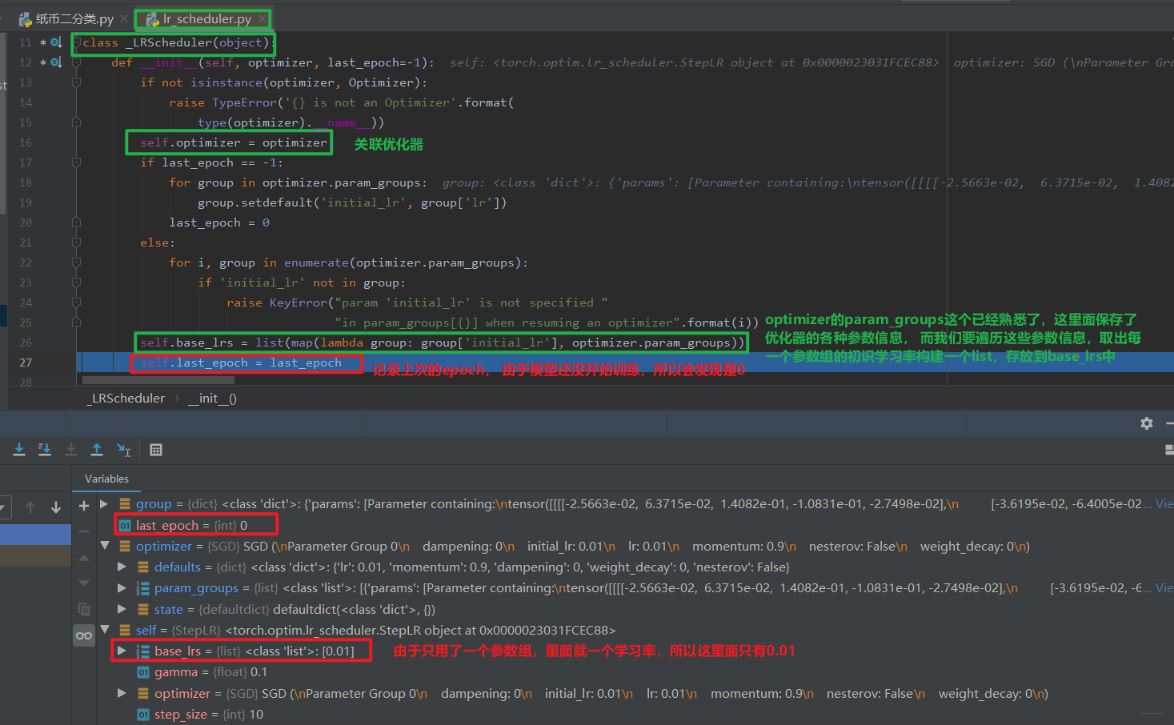
optimizer: 关联的优化器, 得需要先关联一个优化器,然后再去改动学习率
last_epoch: 记录epoch数, 学习率调整以epoch为周期
base_lrs: 记录初始学习率
主要方法:
step(): 更新下一个epoch的学习率, 这个是和用户对接
get_lr(): 虚函数, 计算下一个epoch的学习率, 这是更新过程中的一个步骤
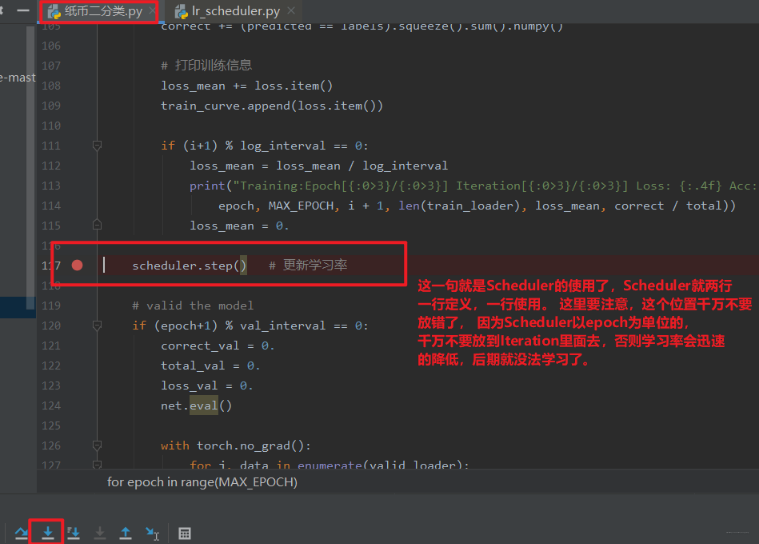
这样我们就构建好了一个Scheduler。下面就看看这个Scheduler是如何使用的, 当然是调用step()方法更新学习率了, 那么这个step()方法是怎么工作的呢? 继续调试: 打断点,debug,步入:
步入之后,我们进入了_LRScheduler的step函数,
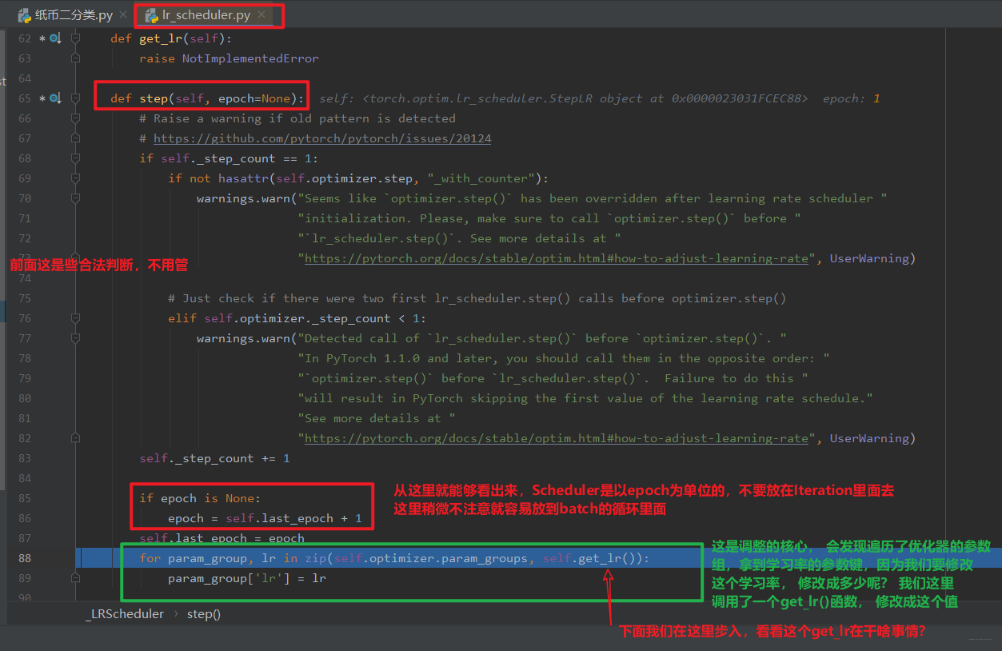
我们发现,这个跳到了我们的StepLR这个类里面,因为我们说过,这个get_lr在基类里面是个虚函数,我们后面编写的Scheduler要继承这个基类,并且要覆盖这个get_lr函数,要不然程序不知道你想怎么个衰减学习率法啊。 所以我们得把怎么衰减学习率通过这个函数告诉程序:
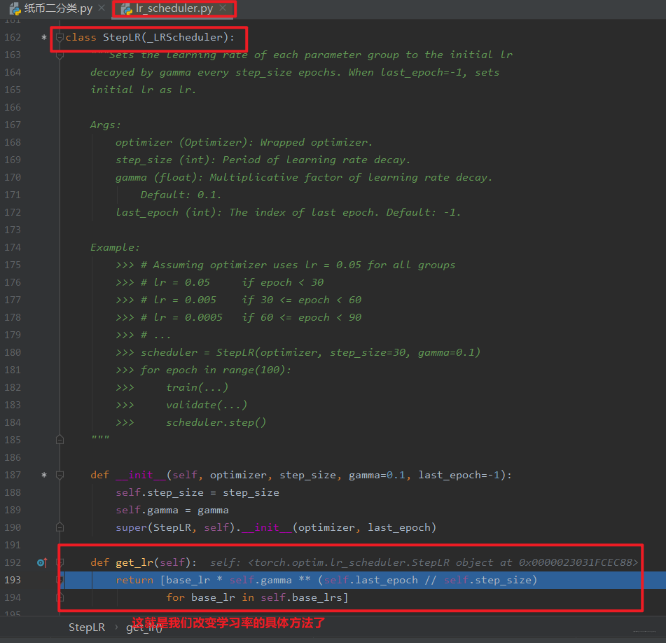
可以看到这里面就用到了初始化时候的base_lr属性
下面关于优化器的定义和使用的内部运行原理就可以稍微总结了
首先我们在定义优化器的时候,这时候会完成优化器的初始化工作, 主要有关联优化器(self.optimizer属性), 然后初始化last_epoch和base_lrs(记录原始的学习率,后面get_lr方法会用到)。 然后就是用Scheduler,我们是直接用的step()方法进行更新下一个epoch的学习率(这个千万要注意放到epoch的for循环里面而不要放到batch的循环里面 ),而这个内部是在_Scheduler类的step()方法里面调用了get_lr()方法, 而这个方法需要我们写Scheduler的时候自己覆盖,告诉程序按照什么样的方式去更新学习率,这样程序根据方式去计算出下一个epoch的学习率,然后直接更新进优化器的_param_groups()里面去。
六种学习率调整策略已经整理完毕,下面小结一下:
有序调整: Step、MultiStep、 Exponential和CosineAnnealing, 这些得事先知道学习率大体需要在多少个epoch之后调整的时候用
自适应调整: ReduceLROnPleateau, 这个非常实用,可以监控某个参数,根据参数的变化情况自适应调整
自定义调整:Lambda, 这个在模型的迁移中或者多个参数组不同学习策略的时候实用
调整策略就基本完了,那么我们得先有个初始的学习率啊, 下面介绍两种学习率初始化的方式:
- 设置较小数:0.01, 0.001, 0.0001
- 搜索最大学习率: 看论文《Cyclical Learning Rates for Training Neural Networks》, 这个就是先让学习率从0开始慢慢的增大,然后观察acc, 看看啥时候训练准确率开始下降了,就把初始学习率定为那个数。