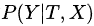一、FFmpeg工具介绍
FFmpeg命令行工具主要包括以下几个部分:
- ffmpeg:编解码工具
- ffprobe:多媒体分析器
- ffplay:简单的音视频播放器
这些工具共同构成了FFmpeg的核心功能,支持各种音视频格式的处理和转换
二、在Ubuntu18.04上安装FFmpeg工具
1、sudo apt-update
2、sudo apt-get install ffmpeg
![]()
3、安装完成后,使用ffmpeg -version 查看当前版本

三、ffmpeg命令
1、ffmpeg的功能
ffmpeg在执行音视频编解码、转码等操作时非常便利,很多场景下转