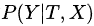索引的底层数据结构
MySQL中常用的是Hash索引和B+树索引
Hash索引:基于哈希表实现的,查找速度非常快,但是由于哈希表的特性,不支持范围查找和排序,在MySQL中支持的哈希索引是自适应的,不能手动创建
B+树的结构
B+树 是一种高效的多路平衡树,适合磁盘存储和范围查询。它的结构特点包括数据集中在叶子节点、叶子节点连接成链表、内部节点仅存储键值和指针。在数据库和文件系统中,B+树 被广泛应用于索引和数据存储,具有查询性能稳定、适合高并发等优势。
如图:B+树具有以下特点:
只有叶子结点才存放数据,中间节点都是用来存放目录项作为索引
非叶子节点分为不同层次,通过分层来降低每一层的搜索量
B+树的搜索策略:
从根节点开始,通过二分法快速定位到符合页内范围包含查询值的页,在中间结点中继续根据二分法来寻找符合页内范围复合查询值的页,接着在叶子节点中通过槽查找记录使用二分法快速定位要查询的记录在哪个槽,找到槽后再遍历槽中所有的记录,找到寻找的分组。
为什么InnoDB使用B+树而不是B树呢
B-Tree:
- 每个节点既存储数据也存储子节点的指针
- 数据分布在所有的节点中,包括内部节点和叶子节点
- 查找时可能会直接在内部节点中就能找到数据不需要遍历到叶子节点
B+Tree:
- 只有叶子结点存储数据,内部节点仅存储键值和子节点的指针
- 所有叶子节点通过指针连接成一个有序链表
- 查找时必须遍历到叶子节点才能获取数据
B+Tree的优势:
更适合磁盘I/O:
- 因为B+树的内部节点不存储数据只存储键值和指针,所以每个节点可以存储更多的键值,从而降低树的高度,树的高度越低磁盘I/O次数越少,查询性能越高(索引数据量很大,一定是存储在磁盘中的,每访问一个节点就会进行一次磁盘IO操作,所以树的高度越低,一次查询的期望IO次数就越少,效率就越高)
- B+树的叶子节点通过指针连接成链表,更适合范围查询如(BETWEEN,>,<等操作),而树的范围查询需要在不同层级的节点之间跳转,效率较低
更适合数据库场景:
- 数据集中在叶子节点上,查询时都需要遍历到叶子节点,这使得查询性能更稳定。B树的数据可能分布在内部节点和叶子结点,查询性能不稳定
- 数据库查询中经常需要使用范围查询,B+树的叶子节点链表结构非常适合这种场景,而B树需要多次遍历内部节点
更适合并发控制:
- 在并发场景下,B+树的叶子节点链表可以更容易地支持范围查询和顺序访问
- 而B树的结构在并发访问时可能需要更多的锁机制(数据分布在内部节点和叶子节点。节点分裂与合并涉及多个节点。锁的粒度较大,容易导致锁冲突)
B+树在InnoDB中的具体应用:
主键索引(聚簇索引):
InnoDB使用B+树实现主键索引,叶子节点存储完整的数据行
这种设计是的通过主键查询数据时可以直接获取数据,不需要回表
二级索引(非聚簇索引):
InnoDB的二级索引也是B+树,但是叶子节点存储的是主键值,通过二级索引查询时,先获取主键值再通过主键索引查找数据(回表)