Redis各类数据结构应用场景总结
- 引言
- String
- 应用场景
- List
- 应用场景
- Hash
- 应用场景
- Set
- 应用场景
- ZSet
- 应用场景
- 小结
引言
实际面试过程中更多看重的是对Redis相关数据结构的活学活用,同时也可能会引申出Redis相关底层数据结构原理的实现,笔者最近面试过程中对这块内容有点生疏,所以本文也是为了笔者个人查漏补缺所写。
文章内容很短,大家可放心食用,同时欢迎各位在评论区进行补充。
在线Redis命令练习
String
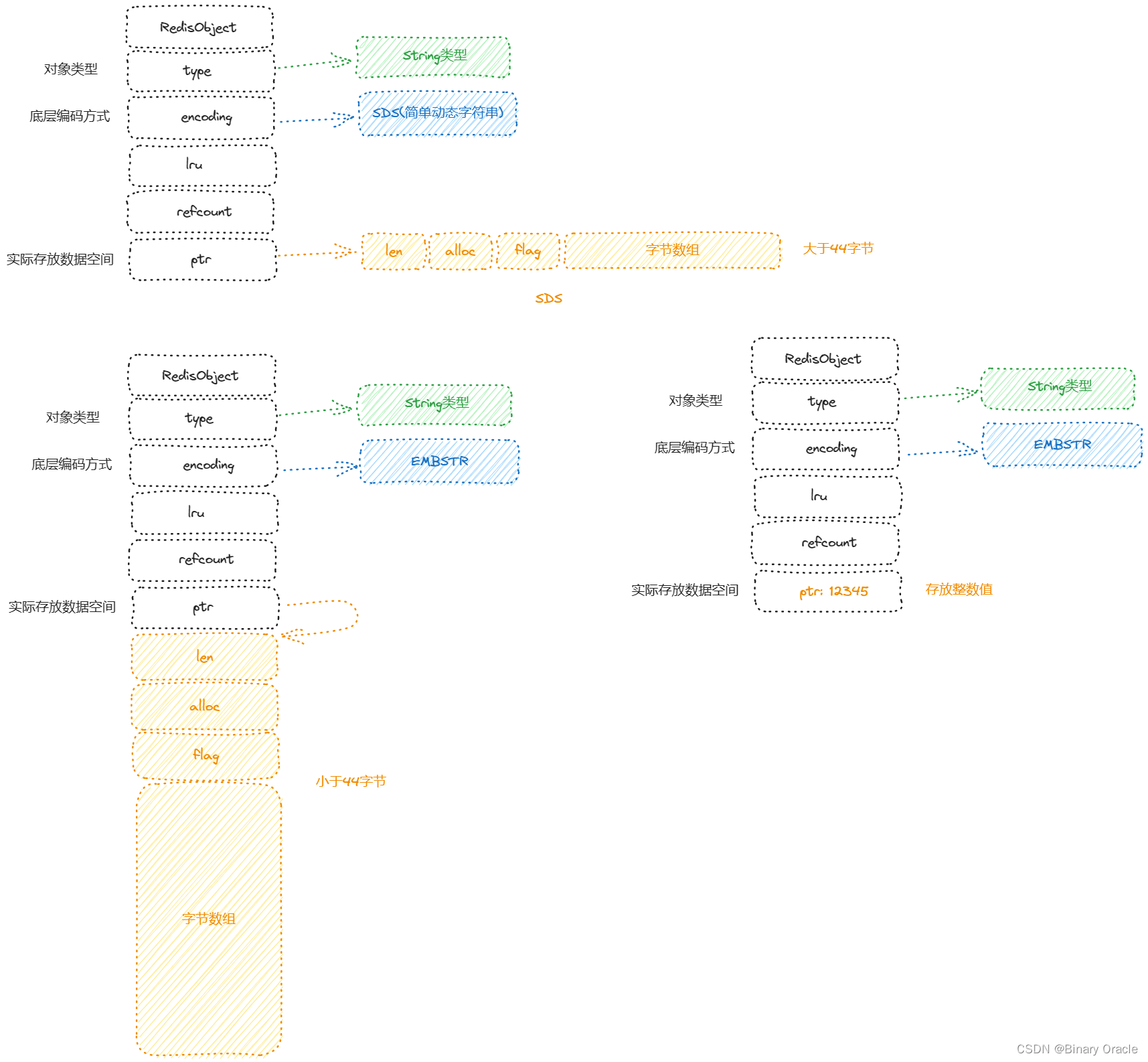
当value是字符串类型时,根据字符串格式的不同,可以分为三类:
- string : 普通字符串
- int : 整数类型 , 可以做自增,自减操作
- float : 浮点类型 , 可以做自增,自减操作
但是不论是何种格式,底层都是采用字节数组形式存储,只不过是编码方式不同,如下图所示:
常见命令:
set k1 v1 [NX | EX expireTime ]get k1mset k1 v1 k2 v2mget k1 k2incr count (val类型必须是int类型)incrby count 2 incrbyfloat floatCount 1.5 setnx k3 v3setex k4 v4 expireTime# string 中每个位的操作
SETBIT key offset value # 将指定位置设置为0或1
GETBIT key offset # 获取指定位置的bit值
BITCOUNT key [start end] # 统计bitmap中值为1的bit位数量
BITOP operation destkey key [key ...] # 对指定的多个 key 进行位操作,并将结果保存在 destkey 中。操作可以是 AND、OR、XOR、NOT
应用场景
String数据结构的应用场景如下图所示,大家可以右键在新标签页中打开浏览:
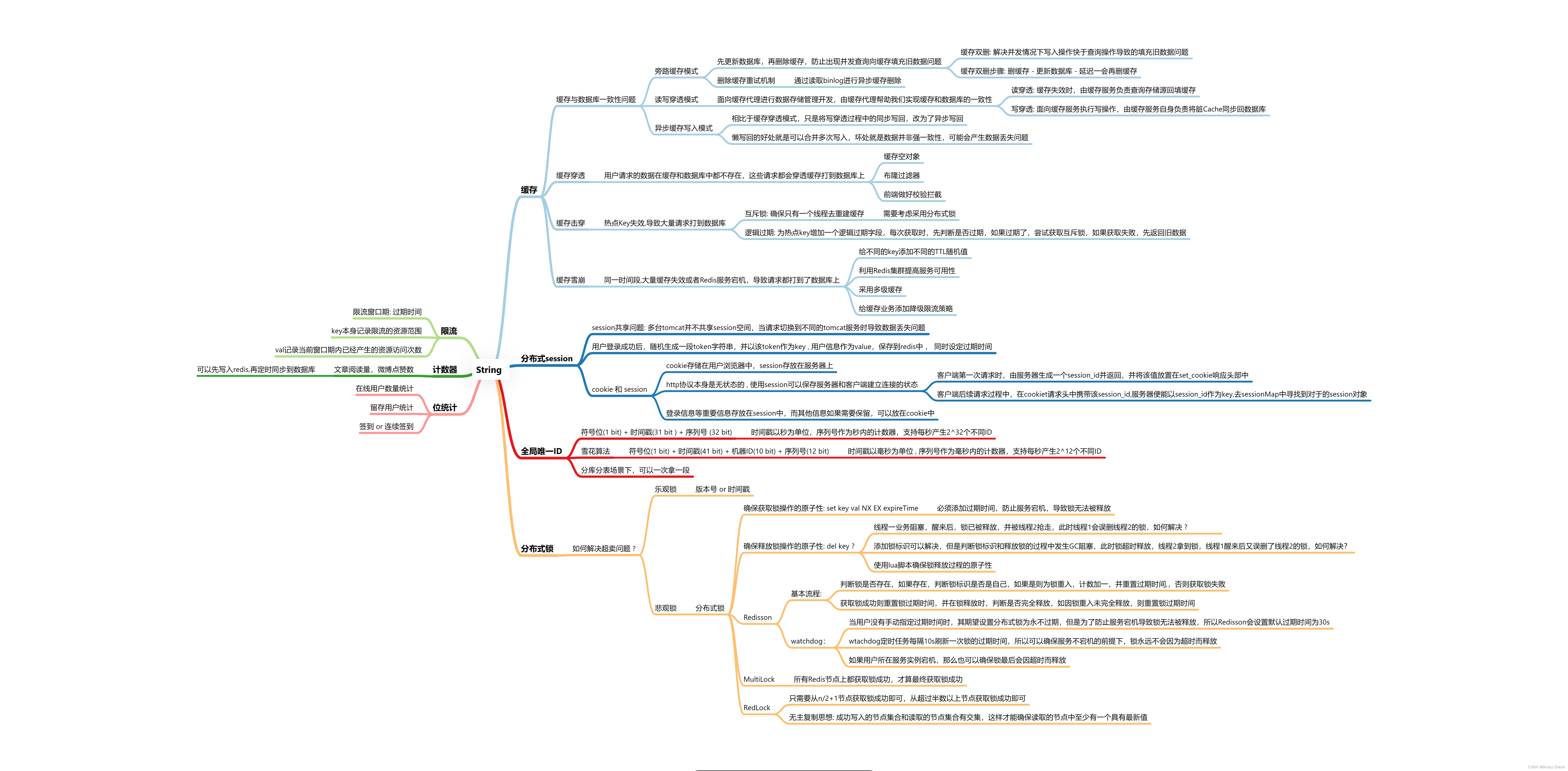
这里针对String类型作为bitmap的应用场景进行特殊说明:
- 统计当前在线用户数量
# setbit onlineUsers userId 1> setbit onlineUsers 1 1
0
> setbit onlineUsers 2 1
0
> setbit onlineUsers 10 1
0
> setbit onlineUsers 25 1
0
> bitcount onlineUsers
4
- 计算连续2天都在线的用户
> setbit online_one 1 1
0
> setbit online_two 1 1
0
> setbit online_two 2 1
0
> setbit online_two 3 1
0
> bitop and both_two_online online_one online_two
1
> bitcount both_two_online
1
- 签到
# 签到 sign:userId:yyyy-MM
> setbit sign:1:2023-08 27 1
0
> setbit sign:1:2023-08 28 1
0
> setbit sign:1:2023-08 29 1
0
> bitcount sign:1:2023-08
3
- 连续签到
- 获取当前key对应的bitmap, 从后往前定位到bitmap中出现的第一个1,从该位置开始依次与1进行与运算,如果结果不为0,则累加计数器,然后右移一位,然后再与1进行与运算,重复以上过程直到与运算结果为0
- 此时计数器的结果即为当前用户连续签到的天数
List
当val类型为List时,其可能存在以下三种编码情况:
- Redis 3.2 版本之前 ,采用 ZipList 和 LinkedList 来实现 List ,当元素数量小于 512 并且 元素大小小于 64 字节时采用 ZipList 编码 , 超过则采用 LinkedList 编码 。
- Redis 3.2 版本之后 , Redis 统一采用 QuickList 来实现 List
常见命令:
LPUSH key element ... # 向列表左侧插入一个或多个元素
LPOP key # 移除并返回列表左侧第一个元素,没有则返回nil
RPUSH key element ... # 向列表右侧插入一个或多个元素
RPOP key # 移除并返回列表右侧的第一个元素
LRANGE key start end # 返回该范围内的所有元素
BLPOP , BRPOP # 没有元素时超时阻塞等待 , 而不是直接返回nil
redis提供的List列表类型其实可以用来替换我们常见的三种数据结构:
- 栈 : 出入口在同一边
- 队列 : 出入口不在同一边
- 阻塞队列 : 增加超时阻塞等待
应用场景
-
消息队列
- 基于List的阻塞模式实现阻塞队列,利用阻塞队列来实现一个简易的生产者-消费者模型
- 优点: 可利用Redis的持久化机制,确保数据一定程度上可靠性。 消息按照投递时间顺序在队列中排序。
- 缺点: 无法避免消息丢失,只支持单消费者
- Pub/Sub 可以用来实现发布订阅模式 ,支持多生产,多消费 ;缺点就是不支持数据持久化,无法避免消息丢失,消息堆积有上限,超出时数据丢失。
- Stream流实现消息队列
- 基于List的阻塞模式实现阻塞队列,利用阻塞队列来实现一个简易的生产者-消费者模型
-
用户消息时间线 – timeline
- list中的元素按照插入的先后顺序排序
Hash
当val类型为Hash时,可能存在以下几种编码情况:
- 数据量比较小时,默认采用ZipList编码,ZipList中相邻的两个entry分别保存field和value
- 数据量比较大时,采用Dict实现,触发条件有两个:
- ZipList中的元素数量超过了默认的512个
- ZipList中的任意entry大小超过了默认规定的64字节大小
应用场景
String 和 Hash 数据结构都可以用来存储对象信息,对于String数据类型来说,通常存储JSON序列化后的对象信息,当需要频繁修改对象某个属性时,这种方式就不太合适了。
Hash类型可以针对某个属性单独修改,没有序列化,也无需修改整个对象,如果某个对象内部属性需要频繁修改,如: 商品价格,销量,关注数,评价数等,可以考虑hash类型。如果需要单独读取对象内部某几个属性,也可以考虑Hash类型。
Set
当val类型为Set时,其底层编码有以下两种情况:
- 当存储的所有数据都是整数时,并且元素数量不超过set-max-intset-entries时,Set会采用IntSet编码
- 大部分情况下,Set都是采用Dict实现,其中使用Dict中的Key来存储元素,val统一为nil
Redis中的Set数据结构具备什么特点:
- 无序性
- 唯一性
- 支持求交集,并集和差集
常用命令:
sadd key member ...
srem key member ... # 删除
scard key # 返回set中元素的个数
sismember key member # 判断元素是否存在当前set中
smembers # 获取set中所有元素
sinter k1 k2 # 求k1和k2关联的两个set集合的交集
sdiff k1 k2 # 求差集
sunion k1 k2 # 求并集
set 和 zset 是面试重点,这两个数据结构大家要尤其注意其应用场景。
应用场景
- 点赞 — 但是每个人只能点赞一次 , 同时记录哪些人点了赞
# 点赞此篇文章
> sadd like:t0001 u0001
(integer) 1
> sadd like:t0001 u0001
(integer) 0
> sadd like:t0001 u0002
(integer) 1
> sadd like:t0001 u0003
(integer) 1
# 返回当前文章点赞总数
> scard like:t0001
3
# 用户u0002取消点赞
> srem like:t0001 u0002
1
> scard like:t0001
2
# 判断用户u0002是否点赞了当前文章
> sismember like:t0001 u0002
(integer) 0
# 获取点赞当前文章的所有用户
> smembers like:t0001
1) "u0003"
2) "u0001"
- 存放商品标签
# 为当前物品添加标签信息
> sadd tags:i5001 物美价廉
(integer) 1
> sadd tags:i5001 4K高清
(integer) 1
# 返回当前物品具备的所有标签信息
> smembers tags:i5001
1) "4K高清"
2) "物美价廉"
- 商品筛选
# 为每个商品添加标签
> sadd 苹果手机 价格昂贵
(integer) 1
> sadd 苹果手机 流畅好用
(integer) 1> sadd 小米手机 价格实惠
(integer) 1
> sadd 小米手机 流畅好用
(integer) 1> sadd 华为手机 价格适中
(integer) 1
> sadd 华为手机 流畅好用
(integer) 1# 获取三者的共同点
> sinter 苹果手机 小米手机 华为手机
1) "流畅好用"
# 获取苹果手机相较于小米手机的不同点
> sdiff 苹果手机 小米手机
1) "价格昂贵"
# 获取小米手机相较于苹果手机的不同点
> sdiff 小米手机 苹果手机
1) "价格实惠"
# 获取苹果手机和小米手机的共同点
> sunion 苹果手机 小米手机
1) "价格实惠"
2) "流畅好用"
3) "价格昂贵"
- 共同关注
# 用户1关注了用户2,3,4
> sadd 1:follow 2
(integer) 1
> sadd 1:follow 3
(integer) 1
> sadd 1:follow 4
(integer) 1
# 用户2关注了用户3,1
> sadd 2:follow 3
(integer) 1
> sadd 2:follow 1
(integer) 1
# 用户2的粉丝有用户1
> sadd 2:fans 1
(integer) 1
# 用户1的粉丝有用户2
> sadd 1:fans 2
(integer) 1# 求用户1和用户2共同关注的人
> sinter 1:follow 2:follow
1) "3"# 求用户1可能认识的人 -- 需要从返回结果中移除用户1自身
> sdiff 2:follow 1:follow
1) "1"# 求用户2可能认识的人 -- 需要从返回结果中移除用户2自身
> sdiff 1:follow 2:follow
1) "2"
2) "4"
ZSet
当val类型为ZSet时,其具备以下特性:
- 在set的基础上,需要给每个member增加一个socre , 然后zset有序集合内部按照socre对member进行排序
- member的唯一性保持不变
- 可以查询member对应的socre
ZSet结构可能存在两种编码类型:
- 当元素数量不多时,采用ziplist编码
- 元素数量小于zset_max_ziplist_entries , 默认为128
- 每个元素都小于zset_max_ziplist_value 字节,默认为64
- 否则采用SkipList + Dict 编码,利用SkipList的有序性实现排序和范围查找 , 利用Dict实现快速定位和去重
Redis提供的ZSet功能很类似Java中的TreeMap:
- ZSet基于单独为每个key指定的score进行升序排序 , 而TreeMap默认基于key进行升序排列,当然我们可以自定义排序规则
- ZSet 底层基于SkipList 进行排序 , TreeMap 基于红黑树进行排序
- ZSet 只存储Key ,没有Val ,TreeMap 作为 map 既存储 Key 也存储 Val
常见命令:
zadd key score member
zrem key member
zscore key member # 获取每个member的分数
zcard key # 获取当前zset集合中的元素个数
zcount key min max # 统计score在指定范围内的所有元素个数
zincrby key incrment member # 为zset中某个member的socre增加指定大小
zrange key min max # 按照score排序后,根据索引获取指定范围内的元素
zrangebyscore key min max # 按照score排序后,根据score获取指定分数段内的元素
zdiff,zinter,zunion # 求差集,交集,并集
所有排名默认升序,如果要降序则在命令后添加REV即可。
应用场景
- 排行榜
# 记录2023-8-24的热点信息排行榜 , 依次添加每个信息 , 记录每个新闻的热点数
> zincrby hotNews:2023-8-24 30000 福岛核废水
30000.0
> zincrby hotNews:2023-8-24 25000 日本3天已连发5次地震
25000.0
> zincrby hotNews:2023-8-24 25000 ShowMaker谈LPL中单
25000.0
> zincrby hotNews:2023-8-24 23000 大脑在替熬夜负重前行
23000.0
> zincrby hotNews:2023-8-24 22000 俄罗斯海岸现恐怖怪鱼
22000.0# 按照默认升序返回所有热点信息
> zrange hotNews:2023-8-24 0 -1
1) "俄罗斯海岸现恐怖怪鱼"
2) "大脑在替熬夜负重前行"
3) "ShowMaker谈LPL中单"
4) "日本3天已连发5次地震"
5) "福岛核废水"# 按照降序返回
> zrevrange hotNews:2023-8-24 0 -1
1) "福岛核废水"
2) "日本3天已连发5次地震"
3) "ShowMaker谈LPL中单"
4) "大脑在替熬夜负重前行"
5) "俄罗斯海岸现恐怖怪鱼"# 获取排名前三的热点信息 -- 降序返回并携带score热度值
> zrevrange hotNews:2023-8-24 0 2 withscores
1) "福岛核废水"
2) 30000.0
3) "日本3天已连发5次地震"
4) 25000.0
5) "ShowMaker谈LPL中单"
6) 25000.0
- 设计一个游戏排行榜,有三个关键信息: 用户id,score ,time ; 要求排行榜先按照用户得分降序排列,再分数相同的情况下,再按照time升序排列;
- key 如何设计
- member 如何设计
- 要求: 返回排名前三的用户 id,score 和 time
这是一道真实的面试题,笔者当时一时绕进去了,没给出正确答案,此处给出我自己的理解:
- member的得分如何设计 : score左移32位,然后或上32的时间戳 — 这里的时间戳需要翻转一下
这里出于简单,就不翻转了,排序规则改为按照得分降序,分数相同的情况下,再按照time降序排列
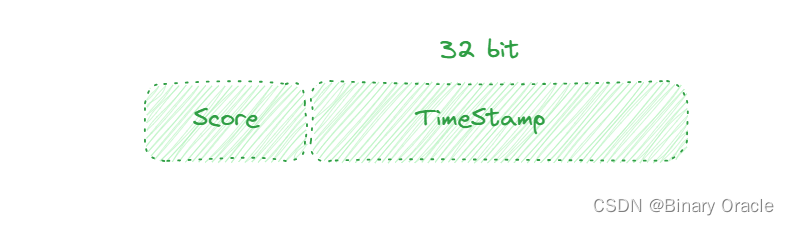
- key如何设计: 假设这里求的是排行日榜 —> rank:2023-8-24
- member如何设计: 存放用户id即可
下面给出返回排名前三的用户 id,score 和 time 的具体命令实现:
# 排行榜添加条目信息
# 用户1得分80,时间戳为1
> zadd rank:2023-8-24 343597383681 1
(integer) 1
# 用户2得分75,时间戳为1
> zadd rank:2023-8-24 322122547201 2
(integer) 1
# 用户3得分90,时间戳为1
> zadd rank:2023-8-24 386547056641 3
(integer) 1
# 用户4得分75,时间戳为2
> zadd rank:2023-8-24 322122547202 4
(integer) 1# 按照默认升序返回整个排行榜信息
> zrange rank:2023-8-24 0 -1
1) "2" # 用户2得分75,时间戳为1
2) "4" # 用户4得分75,时间戳为2
3) "1" # 用户1得分80,时间戳为1
4) "3" # 用户3得分90,时间戳为1# 返回排名前三的用户信息
> zrevrange rank:2023-8-24 0 2 withscores
1) "3"
2) 386547056641.0
3) "1"
4) 343597383681.0
5) "4"
6) 322122547202.0
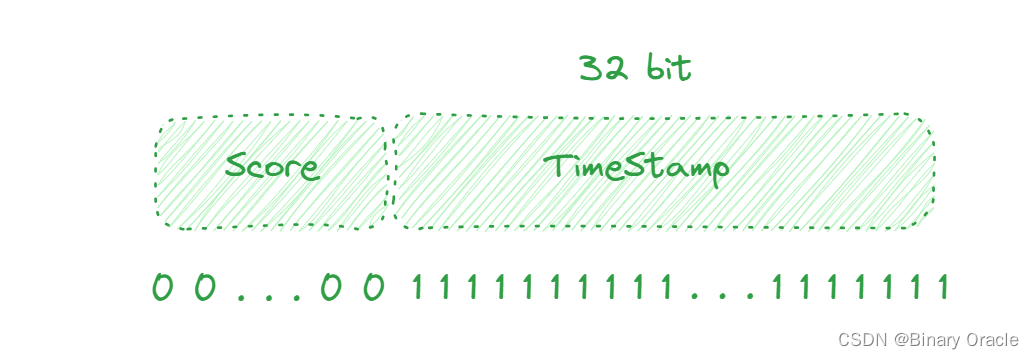
用户id可以从返回的member中直接获取到,而当前用户得分和time可以通过位运算获取到:
# score + 时间戳(32bit)
386547056641 & (2的31次方 - 1) = 8589934591 --> 获取时间戳结果为1
386547056641 >> 32 = 90
- 优先级队列
- 我们可以利用zset按照score排序的这个特性,将score设置为任务的优先级,将其插入zset集合中,这样zset就变成了优先级队列
我们可以利用优先级队列实现延迟队列,只需要将优先级定义为任务执行的时间戳即可,然后应用线程不断循环,直到发现队列头部第一个任务到期了,则从队列移除并执行任务。
小结
关于Redis数据结构,大家需要重点关注String,Set和ZSet的应用,特别是Set和ZSet,绝对是面试场景题的重要考点。
本文只列举了部分笔者目前所能想到的内容,各位大佬如果有补充,可以在评论区留言。