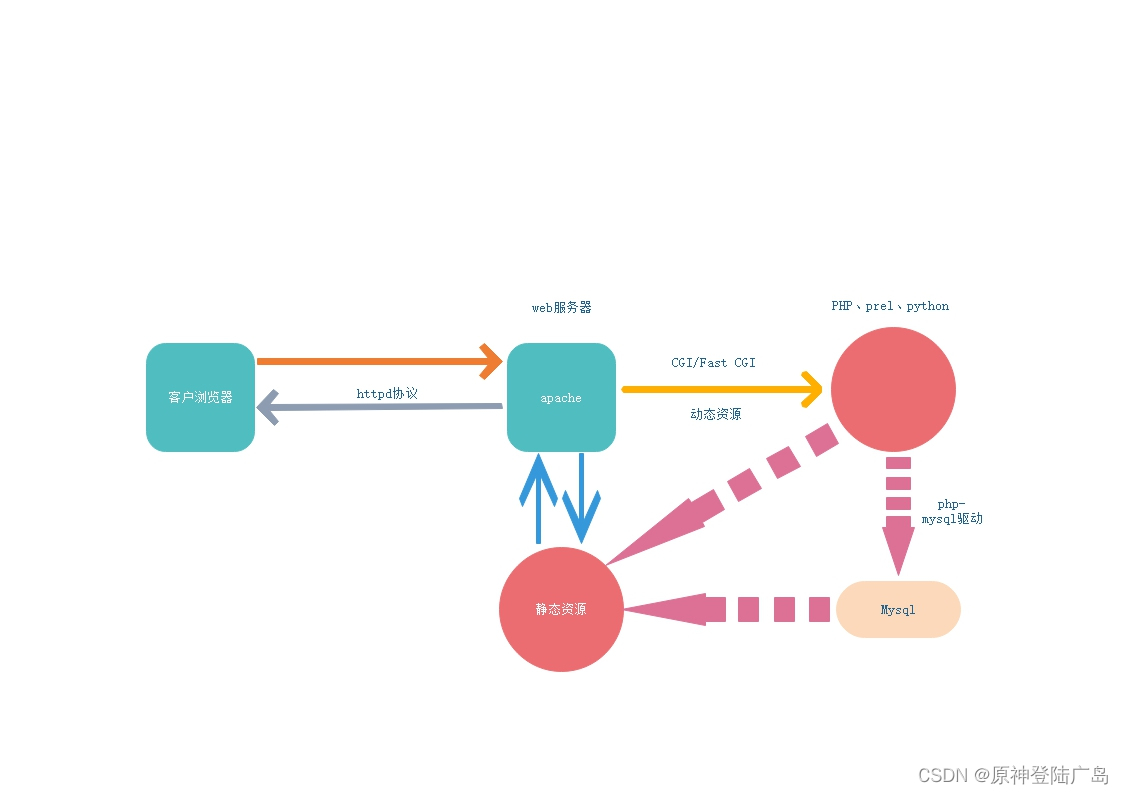
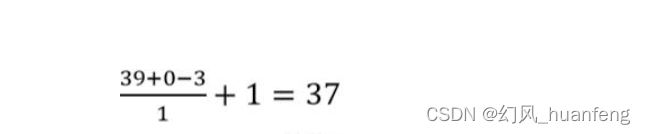概要
机器学习在现代技术中扮演着越来越重要的角色。不论是在商业界还是科学领域,机器学习都被广泛地应用。在机器学习的过程中,我们需要从原始数据中提取出有用的特征,以便训练出好的模型。但是,如何选择最佳的特征是一个关键问题。在本文中,我们将探讨特征选择和特征提取两种方法,并讨论哪种方法更好。
什么是特征选择和特征提取?
在介绍特征选择和特征提取之前,我们需要先了解一下什么是特征。在机器学习中,特征是指原始数据中可以用来训练模型的属性或特性。例如,在一组数字中,我们可以将每个数字视为一个特征。在图像识别中,我们可以将图像的像素点视为特征。
特征选择和特征提取都是从原始数据中提取有用的特征的方法。特征选择是指从原始数据中选择最重要的特征,而特征提取是指从原始数据中提取新的特征,以便训练更好的模型。现在让我们来详细了解这两种方法。
特征选择
特征选择是从原始数据中选择最重要的特征,以便训练更好的模型。特征选择可以帮助我们降低模型的复杂度,提高模型的准确性。在特征选择中,我们通常会根据特征的重要性来选择最佳的特征。通常,特征的重要性是通过以下方法来计算的:
-
方差分析(ANOVA):用于比较不同特征之间的差异性。
-
互信息:用于衡量特征之间的依赖关系。
-
皮尔逊相关系数:用于衡量特征之间的线性相关性。
Scikit-Learn库提供了许多特征选择方法,例如方差选择、卡方检验、互信息等。以下是一个使用方差选择方法来选择最佳特征的示例代码:
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(threshold=0.01)
X_train = selector.fit_transform(X_train)
在上面的代码中,我们使用方差选择方法来选择方差大于0.01的特征。然后,我们使用fit_transform()方法来对训练数据进行特征选择。
特征提取
特征提取是从原始数据中提取新的特征,以便训练更好的模型。特征提取可以帮助我们发现原始数据中潜在的特征,并将其转换为更适合训练模型的形式。在特征提取中,我们通常会使用一些转换方法来提取新的特征。以下是一些常用的特征提取方法:
-
主成分分析(PCA):用于将高维数据转换为低维数据。
-
线性判别分析(LDA):用于将原始数据转换为新的低维数据,以便进行分类。
-
核方法:用于将原始数据转换为高维数据,以便更好地进行分类。
Scikit-Learn库提供了许多特征提取方法,例如PCA,LDA等。以下是一个使用PCA方法来提取新特征的示例代码:
from sklearn.decomposition import PCA
pca = PCA(n_components=2)X_train_pca = pca.fit_transform(X_train)
在上面的代码中,我们使用PCA方法将训练数据转换为两个新的特征。然后,我们使用fit_transform()方法来对训练数据进行特征提取。
特征选择和特征提取的优缺点
现在我们已经了解了特征选择和特征提取的方法,让我们来探讨一下它们的优缺点。
特征选择的优缺点
特征选择的优点是:
-
可以降低模型的复杂度,提高模型的准确性。
-
可以加快训练速度,减少过拟合的可能性。
-
可以提高模型的可解释性,帮助我们更好地理解模型。
特征选择的缺点是:
-
可能会丢失一些重要的信息,导致模型的准确性下降。
-
计算特征的重要性需要一定的时间和计算资源。
特征提取的优缺点
特征提取的优点是:
-
可以发现原始数据中潜在的特征,提高模型的准确性。
-
可以将高维数据转换为低维数据,减少计算资源的消耗。
-
可以帮助我们更好地理解原始数据和模型。
特征提取的缺点是:
-
可能会丢失一些重要的信息,导致模型的准确性下降。
-
特征提取的过程可能比较复杂,需要一定的时间和计算资源。
特征选择还是特征提取?
现在让我们来回答本文的主题问题:特征选择还是特征提取更好?
答案是:取决于具体的情况。
特征选择和特征提取都有各自的优缺点,我们需要根据具体的情况来选择最佳的方法。如果我们已经知道哪些特征对模型的准确性影响较大,那么特征选择可能是更好的选择。如果我们想要发现原始数据中潜在的特征,那么特征提取可能是更好的选择。
结论
在本文中,我们探讨了特征选择和特征提取两种方法,并讨论了它们的优缺点,我们需要根据具体的情况来选择最佳的方法。