4.1.1 Zookeeper 存储的 Kafka 信息
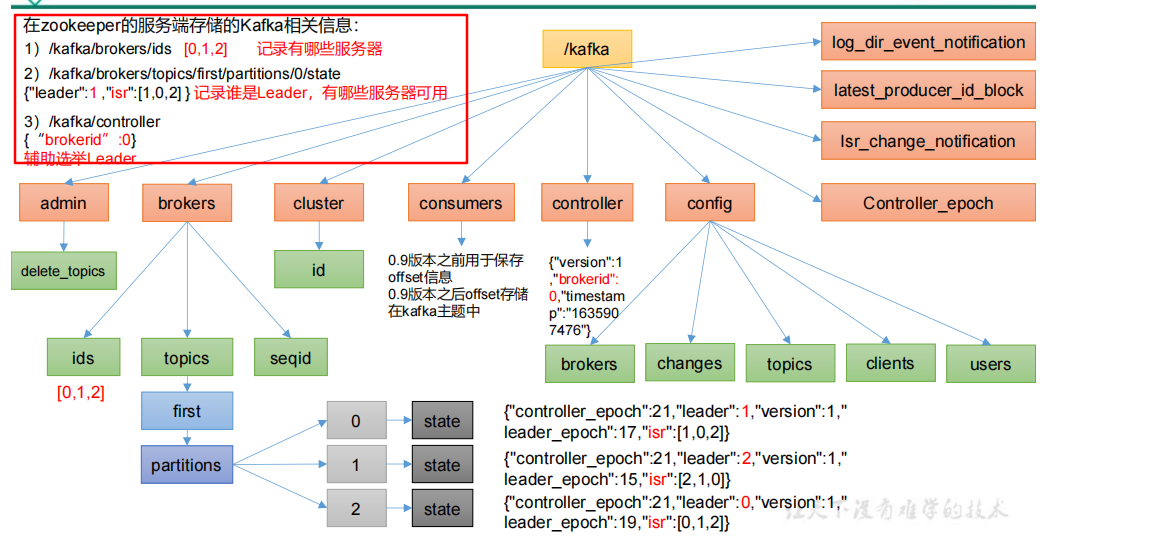
4.1.2 Kafka Broker 总体工作流程
4.2 生产经验 - 节点的服役和退役
自己的理解:其实就是将kafka的分区,负载到集群中的各个节点上。
1、服役新节点
2、退役旧节点
4.3 kafka副本
1、副本的作用
2、Leader的选举流程
选举规则:在isr中存活为前提,按照AR中排在前面的优先。例如ar[1,0,2], isr [1,0,2],那么leader就会按照1,0,2的顺序轮询。
3、 Leader 和 Follower 故障处理细节
两个概念:
- LEO(Log End Offset):每个副本的最后一个offset,LEO其实就是最新的offset + 1
- HW(High Watermark):所有副本中最小的LEO
4、分区副本分配
5、手动分配分区副本
6、Leader Partition 负载平衡
正常情况下,Kafka本身会自动把Leader Partition均匀分散在各个机器上,来保证每台机器的读写吞吐量都是均匀的。但是如果某些broker宕机,会导致Leader Partition过于集中在其他少部分几台broker上,这会导致少数几台broker的读写请求压力过高,其他宕机的broker重启之后都是follower partition,读写请求很低,造成集群负载不均衡
·最好不要设置集群自动再平衡,因为它浪费集群大量的性能·
7、生产经验——增加副本因子
在生产环境当中,由于某个主题的重要等级需要提升,我们考虑增加副本。副本数的增加需要先制定计划,然后根据计划执行
【注意】不能直接通过命令行的方式修改副本,而是需要通过一下方式来增加副本数量 !
4.4 文件存储
1、文件存储机制
1) Topic 文件的存储机制
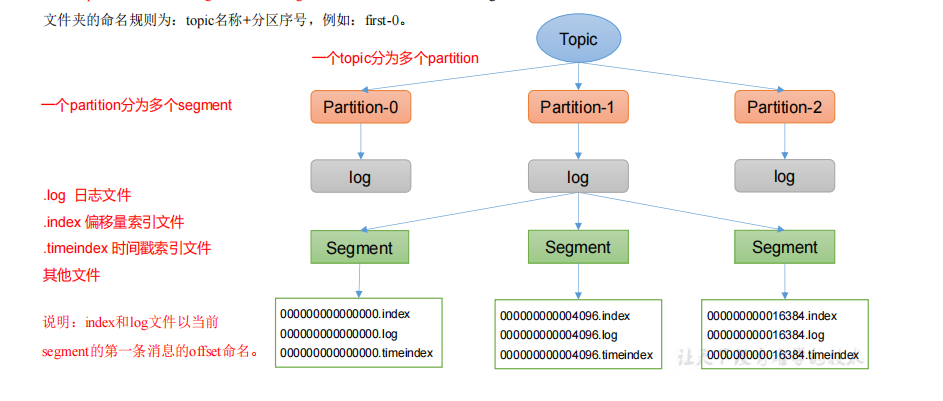
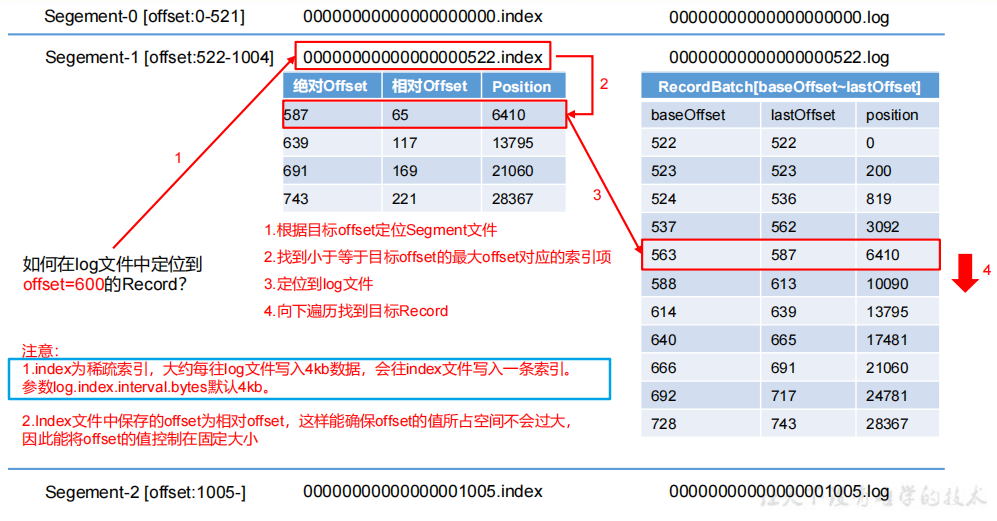
3)index 文件和 log 文件详解
2、文件清理策略
-
Kafka 中
默认的日志保存时间为 7 天,可以通过调整如下参数修改保存时间。 -
Kafka 中提供的日志清理策略有 delete 和 compact 两种
delete 日志删除:将过期数据删除
compact日志压缩:对于相同key的不同value值,只保留最后一个版本。用的比较少,知道即可

4.5 高效读写数据
1)Kafka 本身是分布式集群,采用分区技术,并行度高
2)读数据采用稀疏索引,可以快速定位要消费的数据
3)顺序写磁盘
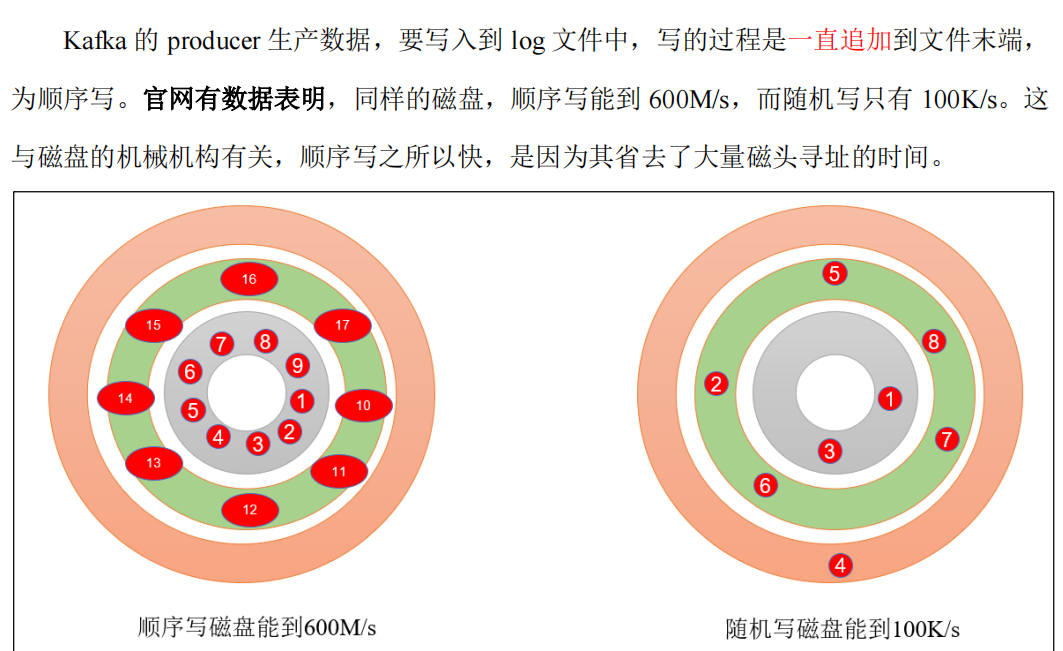
4)页缓存 + 零拷贝技术
零拷贝:Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。Kafka Broker应用层不关心存储的数据,所以就不用走应用层,传输效率高
PageCache页缓存:Kafka重度依赖底层操作系统提供的PageCache功 能。当上层有写操作时,操作系统只是将数据写入PageCache。当读操作发生时,先从PageCache中查找,如果找不到,再去磁盘中读取。实际PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用


![[Go版]算法通关村第十四关白银——堆高效解决的经典问题(在数组找第K大的元素、堆排序、合并K个排序链表)](https://img-blog.csdnimg.cn/79f2bfad071c49a5925f0781bbe91659.png)