背景
- 为什么要提出这个问题?
在一个项目中,每一个python文件打开后,都会看到依赖了其他的一些包、模块等;概念混乱,魔改目标不清晰
- 为什么要修改?
如果需要将某开源包进行自定义处理,不再使用pip install xxx的方式来使用,那么就需要将项目代码放在自己的项目中,通过自己的脚本去调用
一、模块
首先,python没有确定的项目入口,原则上每一个文件都可以是入口,每一个文件入口进去后,所执行的代码也不一定相同,但一般还是以main.py的约定俗成来规定项目入口;那么来看例子,目前有多个文件:

这张图的意思就是,每一个python文件本质都是一个模块。
module_0.py代码如下:
import module_1
import module_2print(module_1.module_name)
print(module_2.module_name)
module_1.module_info()
module_2.module_info()
module_1.py代码如下:
module_name = 'module1'def module_info():print("func in module1")
module_2.py代码如下:
module_name = 'module2'def module_info():print("func in module2")
执行module_0.py,有几种情况:
- 点击IDE的运行,或者vscode装了插件后的运行的按钮,实际上是调用了
& C:/msys64/mingw64/bin/python.exe d:/my/test_py_module/module_0.py
这个命令行
- 直接命令行执行:
python .\module_0.py
其实本质是一样的,因为环境变量添加了python,所以可以识别,并且依旧调用了自己的某个python解释器(有多个解释器的时候需要在IDE选择,或者使用完整路径指定解释器)
有时候会看到py文件中有以下内容,例如在module_0.py中加入:
if __name__ == "__main__":print("hello world")
再执行,发现:
module1
module2
func in module1
func in module2
hello world
多了其作为程序入口(即main的角色)时需要进行的步骤
那么让module_1.py作为主函数呢?
修改其代码,试图让其引用module_0.py:
module_name = 'module1'def module_info():print("func in module1")import module_0print(module_0.module_name)
module_0.module_info()
发现出错:
(base) PS D:\my\test_py_module> python .\module_1.py
Traceback (most recent call last):File "D:\my\test_py_module\module_1.py", line 6, in <module>import module_0File "D:\my\test_py_module\module_0.py", line 1, in <module>import module_1File "D:\my\test_py_module\module_1.py", line 8, in <module>print(module_0.module_name)^^^^^^^^^^^^^^^^^^^^
AttributeError: partially initialized module 'module_0' has no attribute 'module_name' (most likely due to a circular import)
可以发现模块不可以循环引用,正常来讲一个主函数引用其他模块是一种更合适的方式
最后说一句,模块的引用路径顺序:
- 当前目录:Python解释器会先搜索当前目录,也就是包含当前脚本的目录。
- 环境变量PYTHONPATH指定的目录:如果PYTHONPATH环境变量被设置了,Python解释器会搜索这些目录。
- Python默认的安装路径:Python解释器会搜索Python默认的安装路径下的标准库目录和第三方库目录。
三、包
包的出现就是为了避免模块太多放在同一级目录下带来的繁琐问题:
- 不同模块中可以出现同名的变量、函数等,模块名不同,就可以区分
- 模块太多之后,模块也容易重名,就需要再套一级了
所以直接看例子,当前目录结构:

各包的内容:
'''package_1''''''module_1'''
module_name = 'module1'def module_info():print("func in module1")'''module_2'''
module_name = 'module2'def module_info():print("func in module2")
'''package_2''''''module_1'''
module_name = 'module1 from package_2'def module_info():print("func in module1 from package_2")'''module_2'''
module_name = 'module2 from package_2'def module_info():print("func in module2 from package_2")
module_0.py入口函数:
import package_1.module_1 as module_1
import package_1.module_2 as module_2print(module_1.module_name)
print(module_2.module_name)
module_1.module_info()
module_2.module_info()import package_2.module_1
import package_2.module_2print(package_2.module_1.module_name)
print(package_2.module_2.module_name)
package_2.module_1.module_info()
package_2.module_2.module_info()if __name__ == "__main__":print("hello world")
结果:
module1
module2
func in module1
func in module2
module1 from package_2
module2 from package_2
func in module1 from package_2
func in module2 from package_2
hello world
注意:import 参数的最后部分必须是模块名(文件名),而不能是包名(目录名)
可以发现,我们在这里并没有像一些规范的代码一样,严格的加入__init__.py文件,这个文件是一个 Python 包的标识文件,它告诉 Python 解释器该目录应该被视为一个包。当一个包被导入时,Python 解释器会首先查找并执行该包下的 __init__.py 文件,然后才会继续执行其他模块。
__init__.py 文件可以为空,也可以包含 Python 代码,用于初始化包的状态或执行其他必要的操作。例如,它可以定义包级别的变量、函数或类,或者导入其他模块或子包。
在 Python 3.3 及以上版本中,__init__.py 文件不再是必需的,因为 Python 解释器可以自动识别包目录。但是,为了保持向后兼容性,建议在包目录中始终包含一个空的 __init__.py 文件。
所以可以加一下:

如果更多级别的目录,如图所示:

那么在主函数(module_0.py)中引用子包中的模块,并不是难事,直接使用:
import package_1.module_1 as module_1
import package_1.module_2 as module_2print(module_1.module_name)
print(module_2.module_name)
module_1.module_info()
module_2.module_info()import package_2.module_1
import package_2.module_2print(package_2.module_1.module_name)
print(package_2.module_2.module_name)
package_2.module_1.module_info()
package_2.module_2.module_info()import package_1.sub_package_1.module_1 as psm_1
import package_1.sub_package_1.module_2 as psm_2print(psm_1.module_name)
print(psm_2.module_name)
psm_1.module_info()
psm_2.module_info()if __name__ == "__main__":print("hello world")
输出:
module1
module2
func in module1
func in module2
module1 from package_2
module2 from package_2
func in module1 from package_2
func in module2 from package_2
module1 from sub_package_1
module2 from sub_package_1
func in module1 from sub_package_1
func in module2 from sub_package_1
hello world
有时候需要在package_2中,使用子包的模块,就在package_2试一下,引入包1的模块,再引入包1中子包的模块:

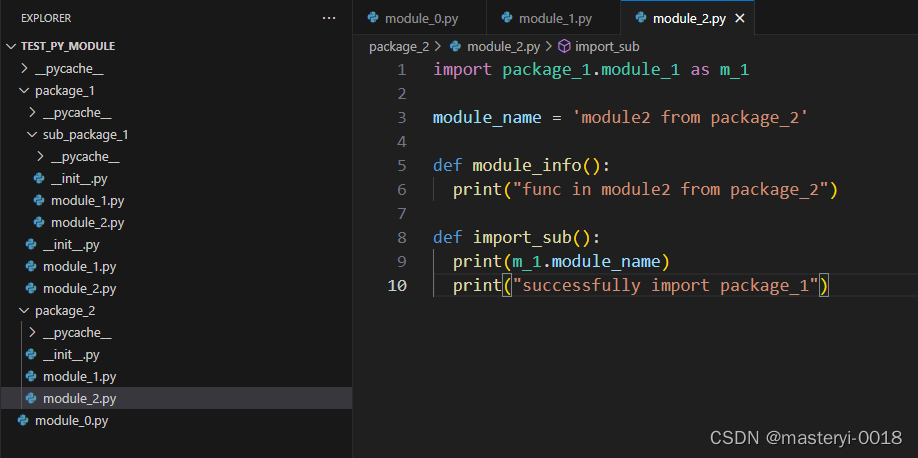
主函数使用:
import package_1.module_1 as module_1
import package_1.module_2 as module_2print(module_1.module_name)
print(module_2.module_name)
module_1.module_info()
module_2.module_info()import package_2.module_1
import package_2.module_2print(package_2.module_1.module_name)
print(package_2.module_2.module_name)
package_2.module_1.module_info()
package_2.module_2.module_info()package_2.module_1.import_sub()
package_2.module_2.import_sub()if __name__ == "__main__":print("hello world")
结果:
module1
module2
func in module1
func in module2
module1 from package_2
module2 from package_2
func in module1 from package_2
func in module2 from package_2
module1 from sub_package_1
successfully import sub_package
module1
successfully import package_1
hello world
有了这样的关系,更复杂的包结构也可以分析了
四、直接导入类和函数
有时候可以看到导入模块后,使用时需要先加模块名,再加类名或者函数名,但如果只使用了模块中特定的类或者函数,为了方便可以直接导入到具体的类或者函数:
在Python中,可以使用import语句来导入类和函数。如果要导入一个模块中的所有内容,可以使用*通配符。
例如,假设我们有一个名为my_module的模块,其中包含一个名为MyClass的类和一个名为my_function的函数。要导入这些内容,可以使用以下语法:
from my_module import MyClass, my_function
这将使MyClass和my_function在当前作用域中可用。如果要导入所有内容,可以使用以下语法:
from my_module import *
这将导入my_module中的所有内容,并使其在当前作用域中可用。但是,这种方法不是推荐的做法,因为它可能会导致命名冲突和代码可读性问题。
五、遗留问题
__init__.py执行的关系,具体使用方法- 导入模块的具体类,但没有导入模块名,此类依赖了本身模块中的其他东西,怎么处理这样的关系:
当你执行from my_module import MyClass时,Python会尝试导入my_module模块,并查找MyClass类。如果MyClass类依赖于my_module中的其他类,那么这些类也会被导入。
具体来说,当Python导入一个模块时,它会执行该模块的代码。如果该模块依赖于其他模块,那么Python会尝试导入这些模块。如果这些模块也依赖于其他模块,那么Python会递归地导入这些模块,直到所有依赖关系都被满足为止。
在导入模块时,Python会将已导入的模块缓存起来,以便在后续的导入中重用。这样可以避免重复导入模块,提高导入效率。
六、参考资料
- https://pythonhowto.readthedocs.io/zh_CN/latest/module.html#
- ChatGPT
- python官方文档:https://docs.python.org/zh-cn/3/reference/import.html
七、相对导入和绝对导入
在Python中,导入模块有两种方式:相对导入和绝对导入。
相对导入是相对于当前模块的位置进行导入,使用相对路径来指定要导入的模块。相对导入使用点号(.)来表示当前模块,使用双点号(…)来表示当前模块的父模块。相对导入的语法如下:
from .module import name
from ..module import name
绝对导入是从项目的根目录开始导入模块,使用绝对路径来指定要导入的模块。绝对导入使用包的完整名称来指定要导入的模块。绝对导入的语法如下:
from package.module import name
在Python 3中,相对导入和绝对导入的默认行为是不同的。在Python 3中,相对导入默认是相对于当前模块的位置进行导入,而绝对导入默认是从项目的根目录开始导入模块。如果要使用Python 2中的相对导入行为,可以在模块中添加以下代码:
from __future__ import absolute_import