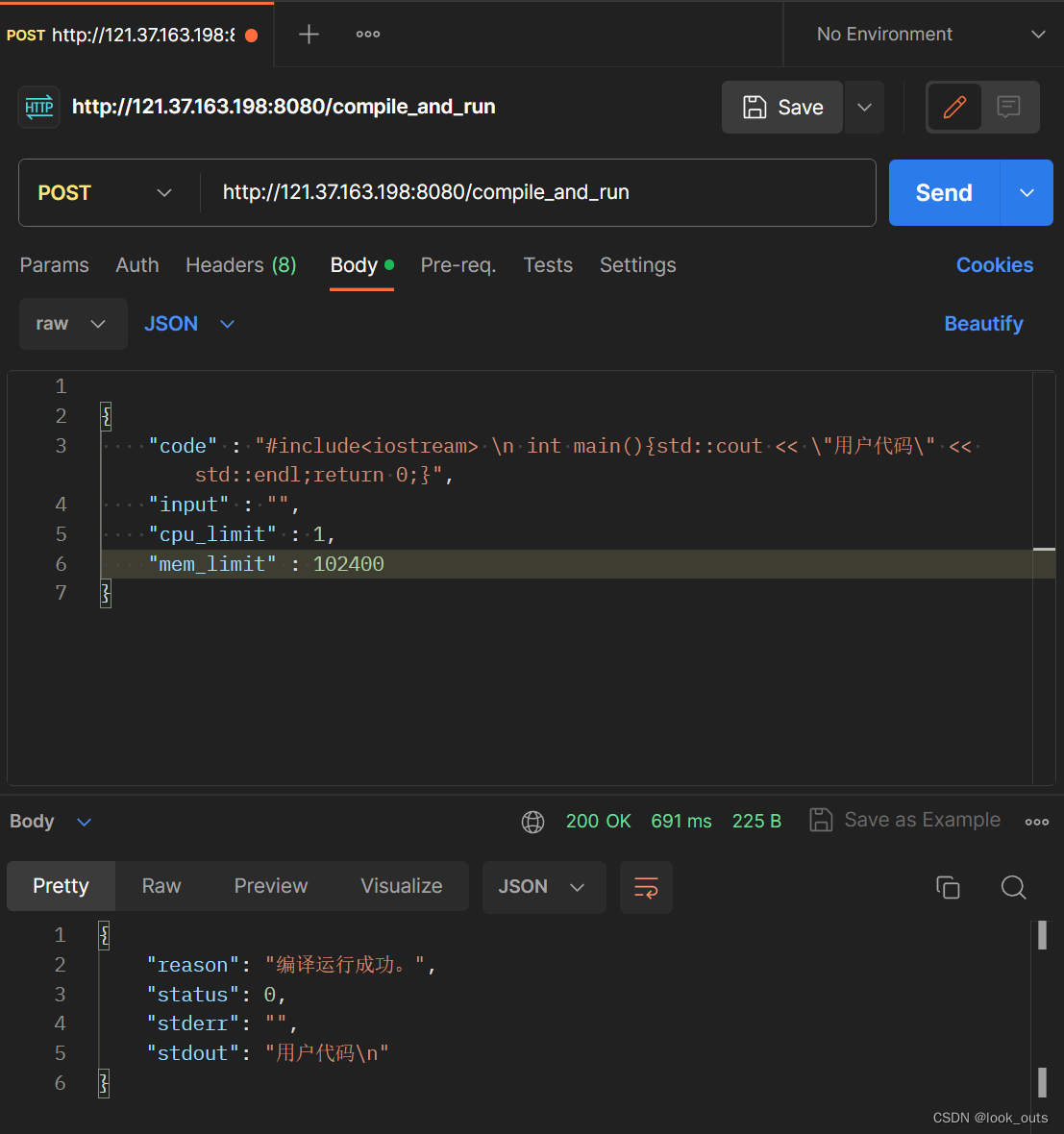
单阶段目标检测模型YOLOv3
R-CNN系列算法需要先产生候选区域,再对候选区域做分类和位置坐标的预测,这类算法被称为两阶段目标检测算法。近几年,很多研究人员相继提出一系列单阶段的检测算法,只需要一个网络即可同时产生候选区域并预测出物体的类别和位置坐标。
YOLOv3使用单个网络结构,在产生候选区域的同时即可预测出物体类别和位置,而且YOLOv3算法产生的预测框数目比Faster R-CNN少很多。Faster R-CNN中每个真实框可能对应多个标签为正的候选区域,而YOLOv3里面每个真实框只对应一个正的候选区域。这些特性使得YOLOv3算法具有更快的速度,能到达实时响应的水平。
Joseph Redmon等人在2015年提出YOLO(You Only Look Once,YOLO)算法,通常也被称为YOLOv1;2016年,他们对算法进行改进,又提出YOLOv2版本;2018年发展出YOLOv3版本。
1.YOLOv3模型设计思想
YOLOv3算法的基本思想可以分成两部分:
- 按一定规则在图片上产生一系列的候选框,然后根据这些候选区域与图片上物体真实框之间的位置关系对候选区域进行标注。跟真实框足够接近的那些候选区域会被标注为正样本,同时将真实框的位置作为正样本的位置目标。偏离真实框较大的那些候选区域则会被标注为负样本,负样本不需要预测位置或者类别。
- 使用卷积神经网络提取图片特征并对候选框的位置和类别进行预测。这样每个预测框就可以看成是一个样本,根据真实框相对它的位置和类别进行的标注而获得标签值,通过网络模型预测其位置和类别,将网络预测值和标签值进行比较,就可以建立起损失函数。
YOLOv3算法训练过程的流程图如下图所示:
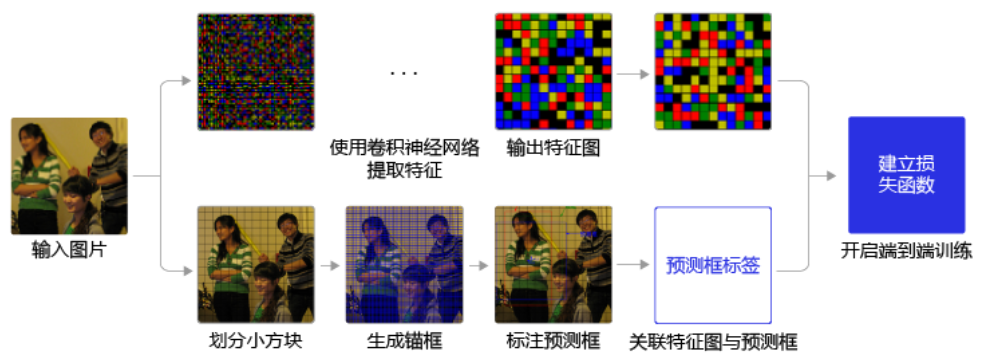
- 左边是输入图片,上半部分所示的过程是使用卷积神经网络对图片提取特征,随着网络不断向前传播,特征图的尺寸越来越小,每个像素点会代表更加抽象的特征模式,直到输出特征图,其尺寸减小为原图的1/32。
- 下半部分描述了生成候选区域的过程,首先将原图划分成多个小方块,每个小方块的大小是32×32,然后以每个小方块为中心分别生成一系列锚框,整张图片都会被锚框覆盖到。在每个锚框的基础上产生一个与之对应的预测框,根据锚框和预测框与图片上物体真实框之间的位置关系,对这些预测框进行标注。
- 将上方支路中输出的特征图与下方支路中产生的预测框标签建立关联,创建损失函数,开启端到端的训练过程。
2.候选区域
2.1产生候选区域
如何产生候选区域,是检测模型的核心设计方案。目前大多数基于卷积神经网络的模型所采用的方式大体如下:
- 按一定的规则在图片上生成一系列位置固定的锚框,将这些锚框看作是可能的候选区域。
- 对锚框是否包含目标物体进行预测,如果包含目标物体,还需要预测所包含物体的类别,以及预测框相对于锚框位置需要调整的幅度。
2.2生成锚框
将原始图片划分成m×n个区域,如下图所示,原始图片高度H=640, 宽度W=480,如果选择小块区域的尺寸为32×32,则m=20,n=15。
YOLOv3算法会在每个区域的中心,生成一系列锚框。为了展示方便,我们先在图中第十行第四列的小方块位置附近画出生成的锚框。在每个小方块区域附近都生成3个锚框,很多锚框堆叠在一起。如下图所示。



2.3生成预测框
锚框的位置都是固定好的,不可能刚好跟物体边界框重合,需要在锚框的基础上进行位置的微调以生成预测框。预测框相对于锚框会有不同的中心位置和大小,采用什么方式能得到预测框呢?我们先来考虑如何生成其中心位置坐标。
如图中在第10行第4列的小方块区域中心生成的一个锚框,如绿色虚线框所示。以小方格的宽度为单位长度, 此小方块区域左上角的位置坐标是:

可以通过下面的方式生成预测框的中心坐标:

由于Sigmoid的函数值在0∼1之间,因此由上面公式计算出来的预测框的中心点总是落在第十行第四列的小方块区域内部 。
锚框的大小是预先设定好的,在模型中可以当作是超参数,下图中画出的锚框尺寸是Ph=350,Pw=250。
这里坐标采用xywh的格式,通过下面的公式生成预测框的大小:
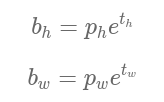
模型训练中需要学习给参数tx,ty,th,tw赋值。目标是实现预测框跟真实框重合,将上面预测框坐标中的bx,by,bh,bw设置为真实框的位置,即可求解出t的数值。
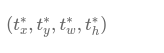
如果t是网络预测的输出值,将t∗作为目标值,以他们之间的差距作为损失函数,则可以建立起一个回归问题,通过学习网络参数,使得t足够接近t∗,从而能够求解出预测框的位置坐标和大小。
预测框可以看作是在锚框基础上的一个微调,每个锚框会有一个跟它对应的预测框,我们需要确定上面计算式中的tx,ty,tw,th,从而计算出与锚框对应的预测框的位置和形状。
3.对候选区域进行标注
每个小方块区域可以产生3种不同形状的锚框,每个锚框都是一个可能的候选区域,对候选区域我们需要了解如下几件事情:
-
锚框是否包含物体,这可以看成是一个二分类问题,使用标签objectness来表示。当锚框包含了物体时,objectness=1,表示预测框属于正类;当锚框不包含物体时,设置objectness=0,表示锚框属于负类。
-
如果锚框包含了物体,那么它对应的预测框的中心位置和大小应该是多少,或者说上面计算式中的tx,ty,tw,th应该是多少,使用location标签。
-
如果锚框包含了物体,那么具体类别是什么,这里使用变量label来表示其所属类别的标签。
选取任意一个锚框对它进行标注,也就是需要确定其对应的objectness, (tx,ty,tw,th)和label,下面将分别讲述如何确定这三个标签的值。
3.1标注锚框是否包含物体
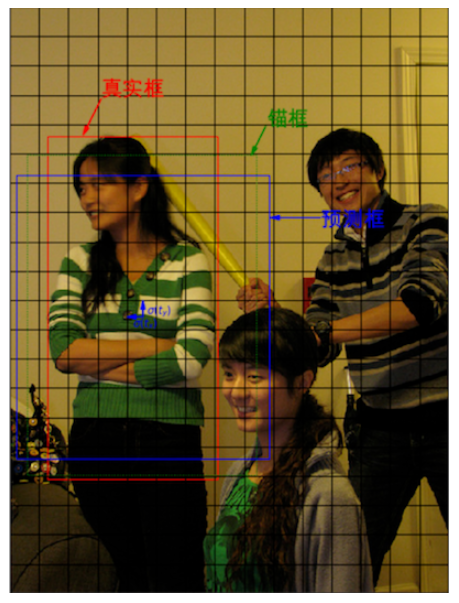
图中一共有3个目标,以最左边的人像为例,其真实框是(133.96, 328.42, 186.06, 374.63)。选出与真实框中心位于同一区域的锚框。
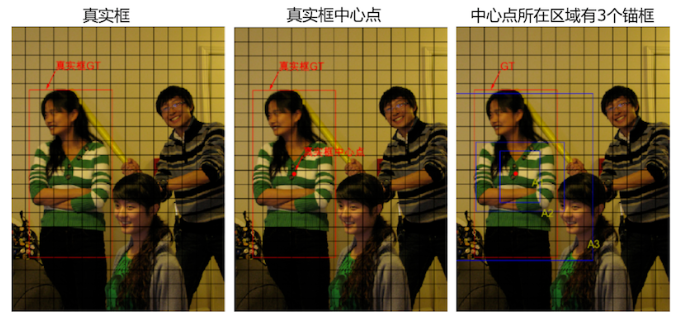
真实框的中心点坐标是:

它落在了第10行第4列的小方块内。此小方块区域可以生成3个不同形状的锚框,其在图上的编号和大小分别是A1(116,90), A2(156,198), A3(373,326)。
用这3个不同形状的锚框跟真实框计算IoU,选出IoU最大的锚框。这里为了简化计算,只考虑锚框的形状,不考虑其跟真实框中心之间的偏移,具体计算结果如下图所示。
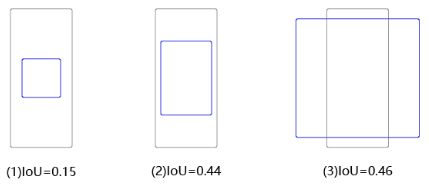
其中跟真实框IoU最大的是锚框A3,形状是(373,326),将它所对应的预测框的objectness标签设置为1,其所包括的物体类别就是真实框里面的物体所属类别。依次可以找出其他几个真实框对应的IoU最大的锚框,然后将它们的预测框的objectness标签也都设置为1。这里一共有20×15×3=900个锚框,只有3个预测框会被标注为正。
由于每个真实框只对应一个objectness标签为正的预测框,如果有些预测框跟真实框之间的IoU很大,但并不是最大的那个,那么直接将其objectness标签设置为0当作负样本,可能并不妥当。为了避免这种情况,YOLOv3算法设置了一个IoU阈值iou_threshold,当预测框的objectness不为1,但是其与某个真实框的IoU大于iou_threshold时,就将其objectness标签设置为-1,不参与损失函数的计算。
所有其他的预测框,其objectness标签均设置为0,表示负类。
对于objectness=1的预测框,需要进一步确定其位置和包含物体的具体分类标签,但是对于objectness=0或者-1的预测框,则不用管他们的位置和类别。
3.2标注预测框的位置坐标标签
当锚框objectness=1时,需要确定预测框位置相对于它微调的幅度,也就是锚框的位置标签。
将预测框坐标中的bx,by,bh,bw设置为真实框的坐标,求解t,对于tx∗和ty∗,由于Sigmoid的反函数不好计算,直接使用σ(ty∗)作为回归的目标。
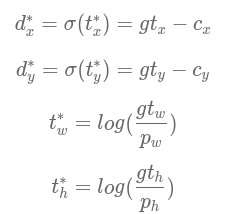
如果t=(tx,ty,th,tw)是网络预测的输出值,将(dx∗,dy∗,tw∗,th∗)作为(σ(tx),σ(ty),th,tw)的目标值,以它们之间的差距作为损失函数,则可以建立起一个回归问题,通过学习网络参数,使得t足够接近t∗,从而能够求解出预测框的位置。
3.3标注锚框包含物体类别的标签
对于objectness=1的锚框,需要确定其具体类别。正如上面所说,objectness标注为1的锚框,会有一个真实框跟它对应,该锚框所属物体类别,即是其所对应的真实框包含的物体类别。这里使用one-hot向量来表示类别标签label。比如一共有10个分类,而真实框里面包含的物体类别是第2类,则label为(0,1,0,0,0,0,0,0,0,0)
3.4标注流程小结
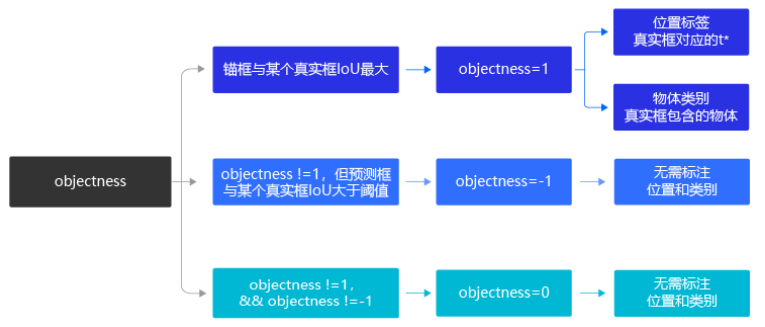
通过这种方式,我们在每个小方块区域都生成了一系列的锚框作为候选区域,并且根据图片上真实物体的位置,标注出了每个候选区域对应的objectness标签、位置需要调整的幅度以及包含的物体所属的类别。位置需要调整的幅度由4个变量描述(tx,ty,tw,th),objectness标签需要用一个变量描述obj,描述所属类别的变量长度等于类别数C。
对于每个锚框,模型需要预测输出(tx,ty,tw,th,Pobj,P1,P2,...,PC),其中Pobj是锚框是否包含物体的概率,P1,P2,...,PC则是锚框包含的物体属于每个类别的概率。接下来让我们一起学习如何通过卷积神经网络输出这样的预测值。
4.卷积神经网络提取特征
前面图像分类中已经学习了如何通过卷积神经网络提取图像特征。通过连续使用多层卷积和池化等操作,能得到语义含义更加丰富的特征图。在检测问题中,也使用卷积神经网络逐层提取图像特征,通过最终的输出特征图来表征物体位置和类别等信息。
YOLOv3算法使用的骨干网络是Darknet53。Darknet53网络的具体结构如下图所示,在ImageNet图像分类任务上取得了很好的成绩。在检测任务中,将图中C0后面的平均池化、全连接层和Softmax去掉,保留从输入到C0部分的网络结构,作为检测模型的基础网络结构,也称为骨干网络。YOLOv3模型会在骨干网络的基础上,再添加检测相关的网络模块。

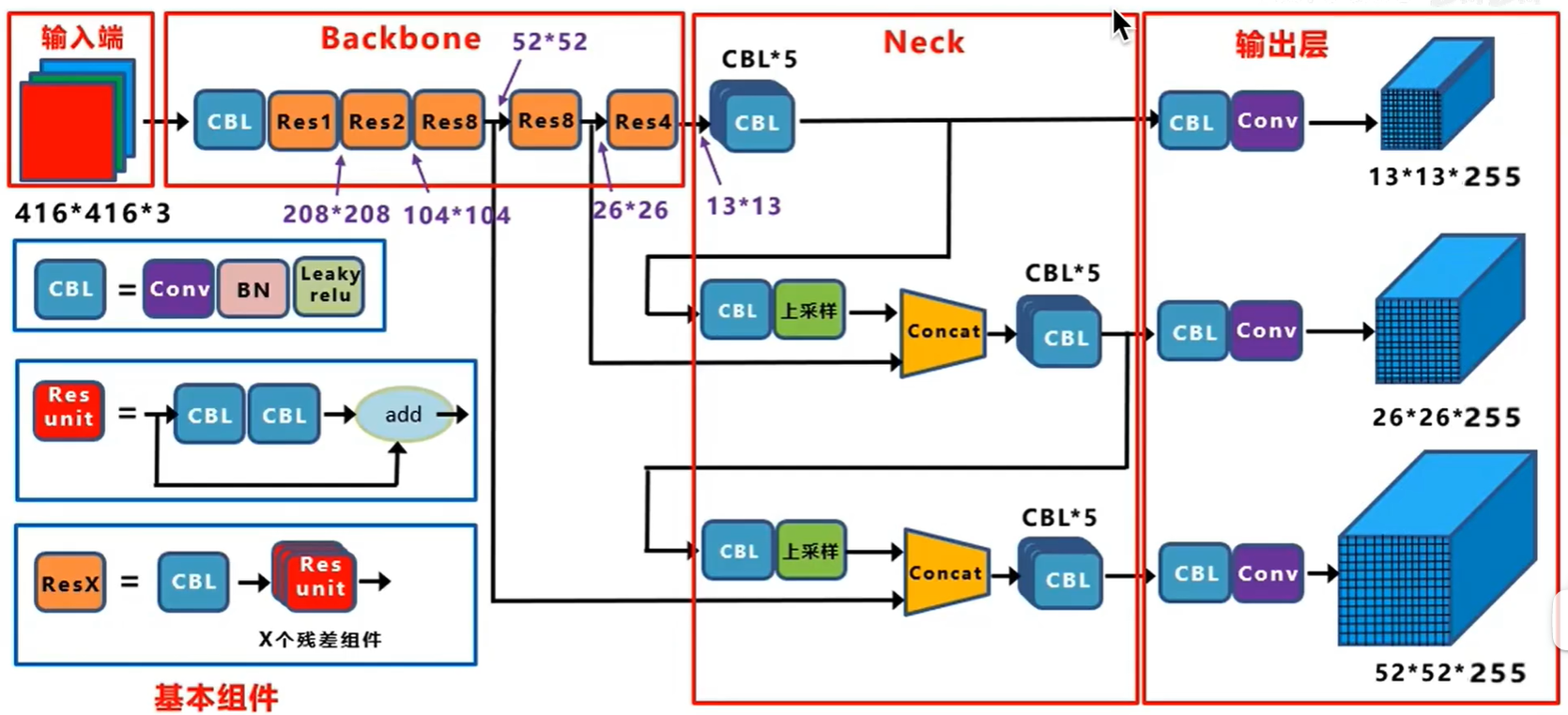
特征图的步幅(stride):在提取特征的过程中通常会使用步幅大于1的卷积或者池化,导致后面的特征图尺寸越来越小,特征图的步幅等于输入图片尺寸除以特征图尺寸。例如:C0的尺寸是20×20,原图尺寸是640×640,则C0的步幅是640/20=32。同理,C1的步幅是16,C2的步幅是8。
5.根据输出特征图计算
5.1计算预测框位置和类别
YOLOv3中对每个预测框计算逻辑如下:
-
预测框是否包含物体。也可理解为objectness=1的概率是多少,可以用网络输出一个实数x,可以用Sigmoid(x)表示objectness为正的概率Pobj
-
预测物体位置和形状。物体位置和形状tx,ty,tw,th可以用网络输出4个实数来表示tx,ty,tw,th
-
预测物体类别。预测图像中物体的具体类别是什么,或者说其属于每个类别的概率分别是多少。总的类别数为C,需要预测物体属于每个类别的概率(P1,P2,...,PC),可以用网络输出C个实数(x1,x2,...,xC),对每个实数分别求Sigmoid函数,让Pi=Sigmoid(xi),则可以表示出物体属于每个类别的概率。
对于一个预测框,网络需要输出(5+C)个实数来表征它是否包含物体、位置和形状尺寸以及属于每个类别的概率。
每个小方块区域都生成了K个预测框,则所有预测框一共需要网络输出的预测值数目是:
[K(5+C)]×m×n
更重要的一点是网络输出必须要能区分出小方块区域的位置来,不能直接将特征图连接一个输出大小为[K(5+C)]×m×n的全连接层。
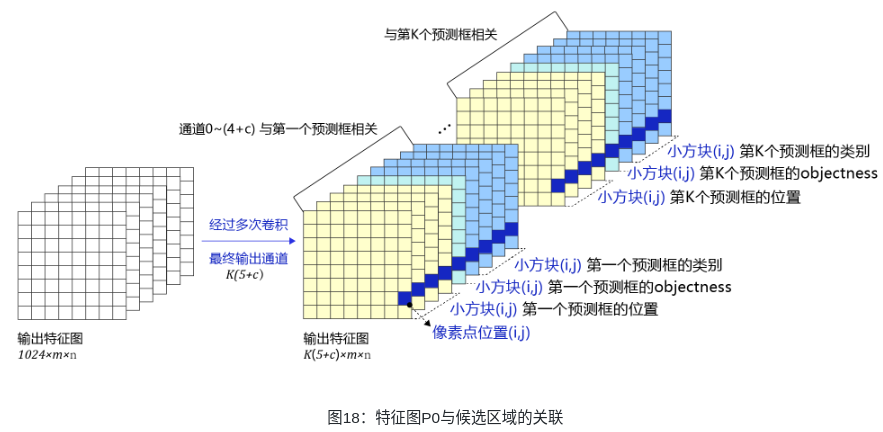
5.2建立特征图与预测框的关联
现在观察特征图,经过多次卷积核池化之后,其步幅stride=32,640×480大小的输入图片变成了20×15的特征图;而小方块区域的数目正好是20×15,也就是说可以让特征图上每个像素点分别跟原图上一个小方块区域对应。这也是为什么我们最开始将小方块区域的尺寸设置为32的原因,这样可以巧妙的将小方块区域跟特征图上的像素点对应起来,解决了空间位置的对应关系。
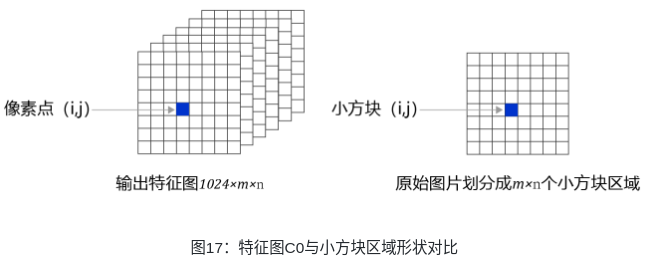
下面需要将像素点(i, j)与第i行第j列的小方块区域所需要的预测值关联起来,每个小方块区域产生K个预测框,每个预测框需要(5+C)个实数预测值,则每个像素点相对应的要有K(5+C)个实数。为了解决这一问题,对特征图进行多次卷积,并将最终的输出通道数设置为K(5+C),即可将生成的特征图与每个预测框所需要的预测值巧妙的对应起来。当然,这种对应是为了将骨干网络提取的特征对接输出层来形成Loss。实际中,这几个尺寸可以随着任务数据分布的不同而调整,只要保证特征图输出尺寸(控制卷积核和下采样)和输出层尺寸(控制小方块区域的大小)相同即可。
骨干网络的输出特征图是C0,对C0进行多次卷积可以得到跟预测框相关的特征图P0。
由特征图C0生成特征图P0,P0的形状是[1,36,20,20]。如果每个小方块区域生成的锚框或者预测框的数量是3,物体类别数目是7,每个区域需要的预测值个数是3×(5+7)=36,正好等于P0的输出通道数。
将P0[t,0:12,i,j]与输入的第 t 张图片上小方块区域(i, j)第1个预测框所需要的12个预测值对应,P0[t,12:24,i,j]与输入的第 t 张图片上小方块区域(i, j)第2个预测框所需要的12个预测值对应,P0[t,24:36,i,j]与输入的第t张图片上小方块区域(i, j)第3个预测框所需要的12个预测值对应。
P0[t,0:4,i,j]与输入的第 t 张图片上小方块区域(i, j)第1个预测框的位置对应, P0[t,4,i,j]与输入的第 t 张图片上小方块区域(i, j)第1个预测框的objectness对应, P0[t,5:12,i,j]与输入的第 t 张图片上小方块区域(i, j)第1个预测框的类别对应。
通过这种方式可以巧妙的将网络输出特征图,与每个小方块区域生成的预测框对应起来了。
5.3计算预测框包含物体的概率
根据前面的分析,P0[t,4,i,j]与输入的第t张图片上小方块区域(i, j)第1个预测框的objectness对应,P0[t,4+12,i,j]与第2个预测框的objectness对应,…,则可以使用下面的程序将objectness相关的预测取出,并使用paddle.nn.functional.sigmoid计算输出概率。
预测框是否包含物体的概率pred_objectness_probability,其数据形状是[1, 3, 20, 20],与我们上面提到的预测框个数一致,数据大小在0~1之间,表示预测框为正样本的概率。
5.4计算预测框位置坐标
P0[t,0:4,i,j]与输入的第t张图片上小方块区域(i, j)第1个预测框的位置对应,P0[t,12:16,i,j]与第2个预测框的位置对应,依此类推,可以从P0中取出跟预测框位置相关的预测值。
网络输出值是(tx,ty,tw,th),还需要将其转化为(x1,y1,x2,y2)这种形式的坐标表示。
pred_boxes的形状是[N,H,W,num_anchors,4]、(1,20,20,3,4),坐标格式是[x1,y1,x2,y2],数值在0~1之间,表示相对坐标。
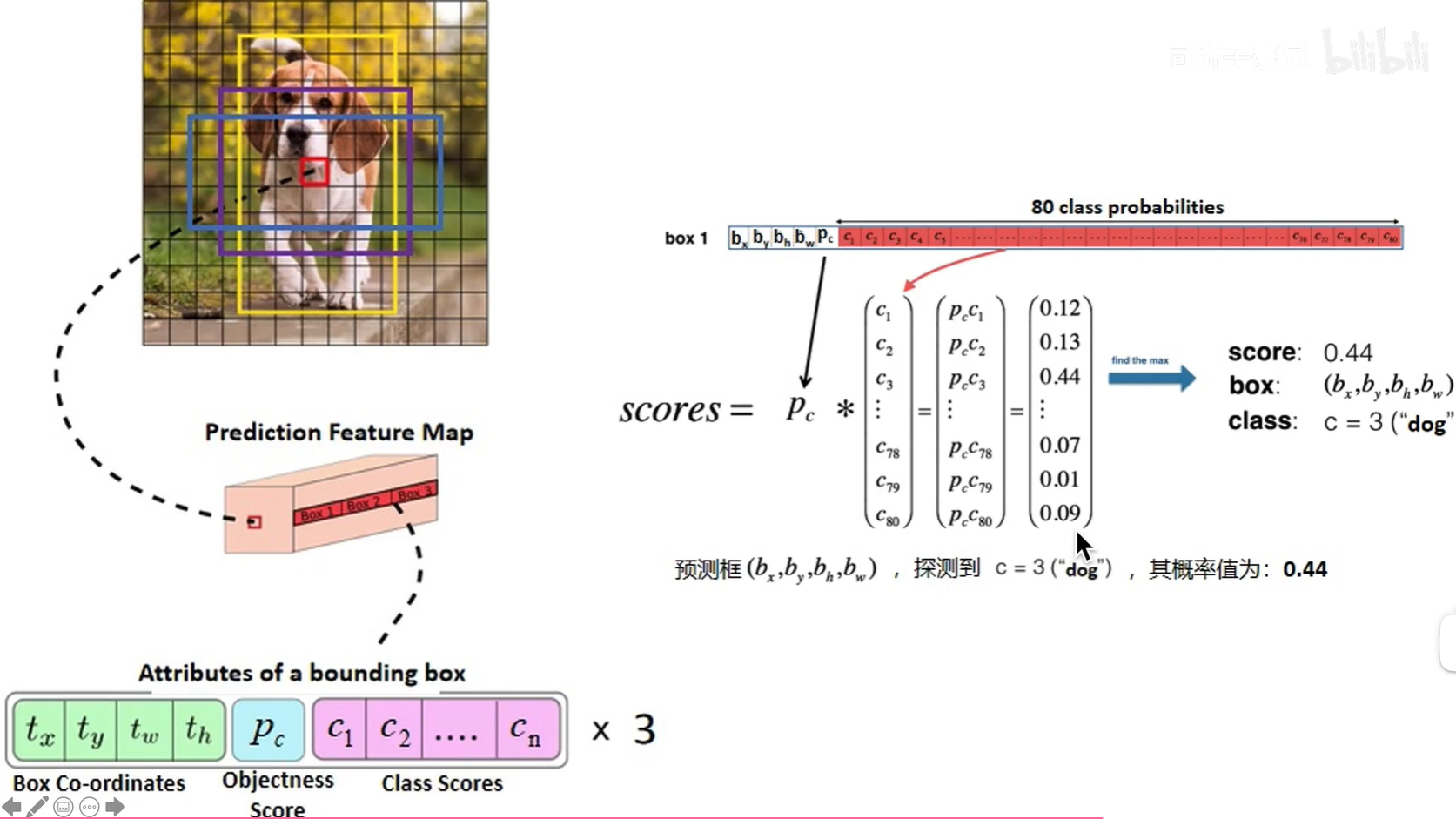
5.5计算物体属于每个类别的概率
P0[t,5:12,i,j]与输入的第t张图片上小方块区域(i, j)第1个预测框包含物体的类别对应,P0[t,17:24,i,j]与第2个预测框的类别对应,依此类推,可以从P0中取出那些跟预测框类别相关的预测值。
预测框包含的物体所属类别的概率,pred_classification_probability的形状是[1,3,7,20,20],数值在0~1之间。
6.损失函数
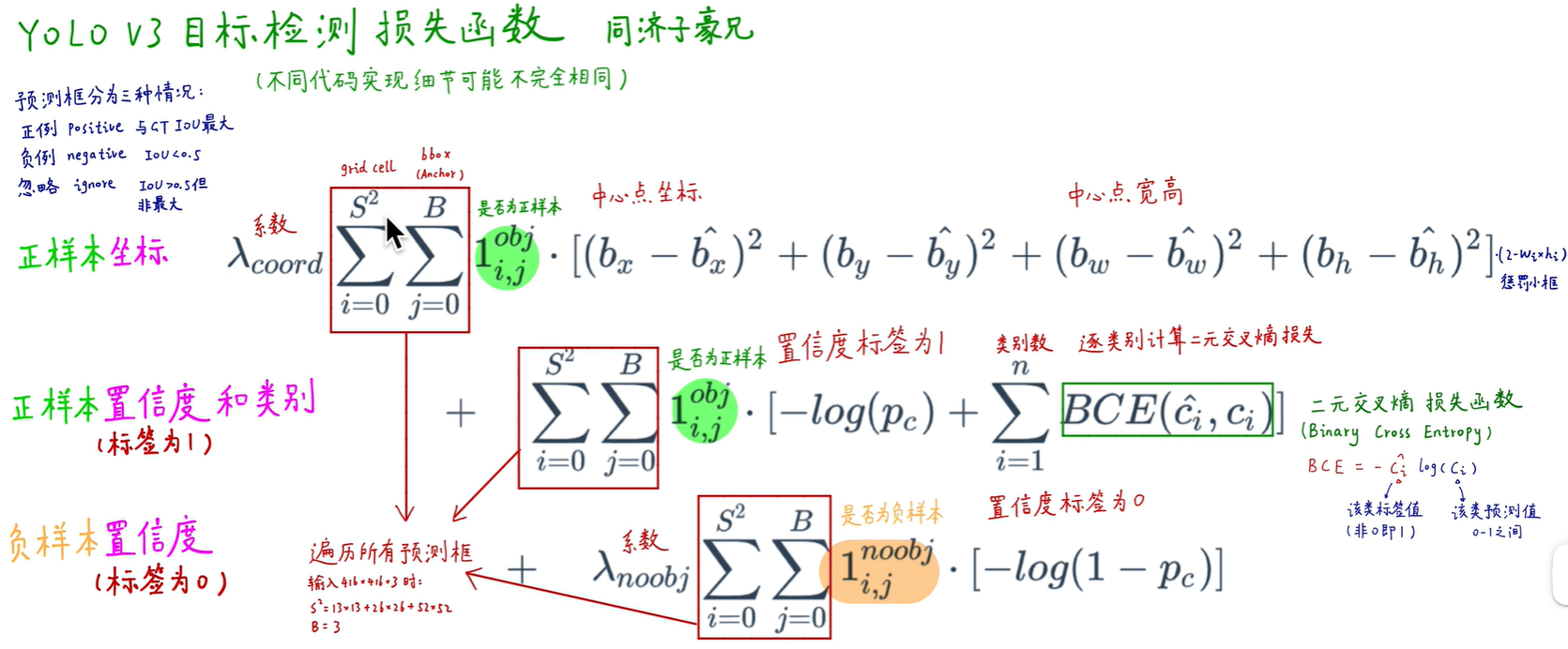
上面从概念上将输出特征图上的像素点与预测框关联起来了,那么要对神经网络进行求解,还必须从数学上将网络输出和预测框关联起来,也就是要建立起损失函数跟网络输出之间的关系。下面讨论如何建立起YOLOv3的损失函数。
对于每个预测框,YOLOv3模型会建立三种类型的损失函数:
- 表征是否包含目标物体的损失函数,通过pred_objectness和label_objectness计算。
- 表征物体位置的损失函数,通过pred_location和label_location计算。
- 表征物体类别的损失函数,通过pred_classification和label_classification计算。
前面已经介绍了怎么计算这些预测值和标签,下面介绍如何标注出哪些锚框的objectness为-1。
首先需要计算出所有预测框跟真实框之间的IoU,然后把那些IoU大于阈值的真实框挑选出来。
将那些没有被标注为正样本,但又与真实框IoU比较大的样本objectness标签设置为-1了,不计算
其对任何一种损失函数的贡献。
7.多尺度检测
目前我们计算损失函数是在特征图P0的基础上进行的,它的步幅stride=32。特征图的尺寸比较小,像素点数目比较少,每个像素点的感受野很大,具有非常丰富的高层级语义信息,可能比较容易检测到较大的目标。为了能够检测到尺寸较小的那些目标,需要在尺寸较大的特征图上面建立预测输出。如果我们在C2或者C1这种层级的特征图上直接产生预测输出,可能面临新的问题,它们没有经过充分的特征提取,像素点包含的语义信息不够丰富,有可能难以提取到有效的特征模式。在目标检测中,解决这一问题的方式是,将高层级的特征图尺寸放大之后跟低层级的特征图进行融合,得到的新特征图既能包含丰富的语义信息,又具有较多的像素点,能够描述更加精细的结构。
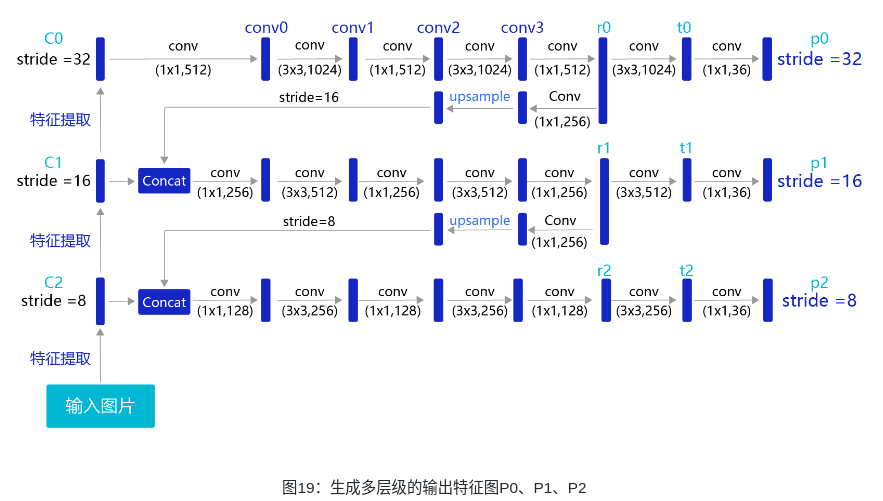
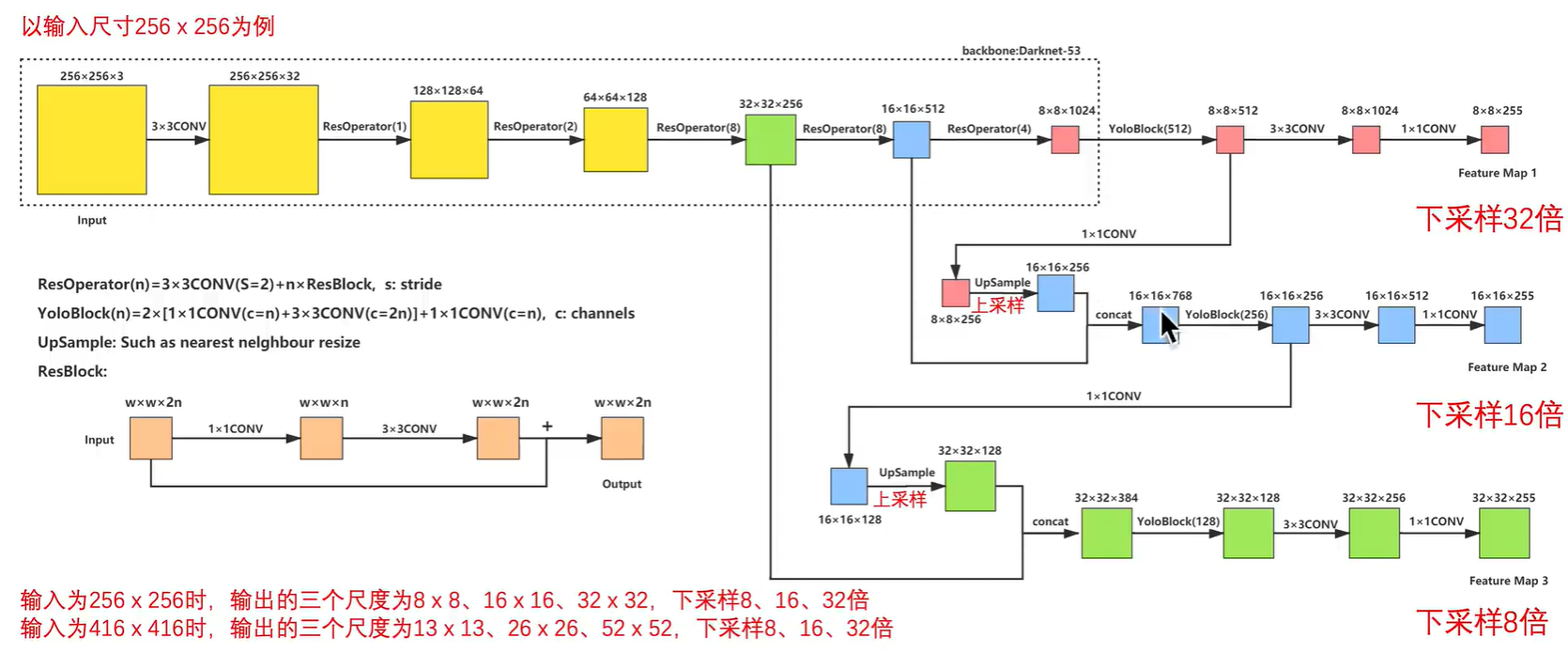
YOLOv3在每个区域的中心位置产生3个锚框,在3个层级的特征图上产生锚框的大小分别为
P2 [(10×13),(16×30),(33×23)],
P1 [(30×61),(62×45),(59× 119)],
P0[(116 × 90), (156 × 198), (373 × 326]。
越往后的特征图上用到的锚框尺寸也越大,能捕捉到大尺寸目标的信息;越往前的特征图上锚框尺寸越小,能捕捉到小尺寸目标的信息。
因为有多尺度的检测,所以需要对上面的代码进行较大的修改,而且实现过程也略显繁琐,所以推荐直接使用飞桨 paddle.vision.ops.yolo_lossAPI。
8.端到端训练
训练过程如下图所示,输入图片经过特征提取得到三个层级的输出特征图P0(stride=32)、P1(stride=16)和P2(stride=8),相应的分别使用不同大小的小方块区域去生成对应的锚框和预测框,并对这些锚框进行标注。
-
P0层级特征图,对应着使用32×32大小的小方块,在每个区域中心生成大小分别为[116,90], [156,198], [373,326]的三种锚框。
-
P1层级特征图,对应着使用16×16大小的小方块,在每个区域中心生成大小分别为[30,61], [62,45], [59,119]的三种锚框。
-
P2层级特征图,对应着使用8×88×8大小的小方块,在每个区域中心生成大小分别为[10,13], [16,30], [33,23]的三种锚框。
将三个层级的特征图与对应锚框之间的标签关联起来,并建立损失函数,总的损失函数等于三个层级的损失函数相加。通过极小化损失函数,可以开启端到端的训练过程。

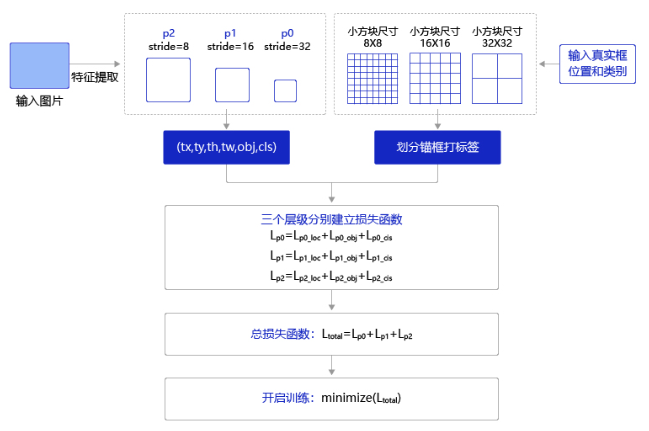
9.预测


参看上图预测过程,可以分为两步:
- 通过网络输出计算出预测框位置和所属类别的得分。
- 使用非极大值抑制来消除重叠较大的预测框。
对于第1步,前面我们已经讲过如何通过网络输出值计算pred_objectness_probability, pred_boxes以及pred_classification_probability,这里推荐大家直接使用paddle.vision.ops.yolo_box
返回值包括两项,boxes和scores,其中boxes是所有预测框的坐标值,scores是所有预测框的得分。预测框得分的定义是所属类别的概率乘以其预测框是否包含目标物体的objectness概率。
第1步的计算结果会在每个小方块区域上生成多个预测框,而这些预测框中很多都有较大的重合度,因此需要消除重叠较大的冗余检测框。这里使用非极大值抑制(non-maximum suppression, nms)来消除冗余框。基本思想是,如果有多个预测框都对应同一个物体,则只选出得分最高的那个预测框,剩下的预测框被丢弃掉。
如何判断两个预测框对应的是同一个物体呢,标准该怎么设置?
如果两个预测框的类别一样,而且他们的位置重合度比较大,则可以认为他们是在预测同一个目标。非极大值抑制的做法是,选出某个类别得分最高的预测框,然后看哪些预测框跟它的IoU大于阈值,就把这些预测框给丢弃掉。这里IoU的阈值是超参数,需要提前设置,YOLOv3模型里面设置的是0.5。


10.模型效果及可视化展示
上面的程序展示了如何读取测试数据集的图片,并将最终结果保存在json格式的文件中。为了更直观的给读者展示模型效果,下面的程序添加了如何读取单张图片,并画出其产生的预测框。
清晰的给读者展示如何使用训练好的权重,对图片进行预测并将结果可视化。最终输出的图片上,检测出了每个昆虫,标出了它们的边界框和具体类别。