文章目录
- 1. **选择适当的数据存储技术:**
- 2. **采用分布式架构:**
- 3. **数据分区和索引:**
- 4. **采用列式存储:**
- 5. **数据压缩和编码:**
- 6. **使用缓存技术:**
- 7. **数据分片和复制:**
- 8. **自动化运维和监控:**
- 9. **数据安全和权限控制:**
- 10. **实时处理和流式分析:**
- 11. **数据质量和清洗:**
- 12. **持续优化和改进:**
🎈个人主页:程序员 小侯
🎐CSDN新晋作者
🎉欢迎 👍点赞✍评论⭐收藏
✨收录专栏:大数据系列
✨文章内容:大数据存储
🤝希望作者的文章能对你有所帮助,有不足的地方请在评论区留言指正,大家一起学习交流!🤗
在云原生时代,构建高效的大数据存储与分析平台需要综合考虑架构、技术选择和最佳实践。以下是一些方法和策略,可以帮助您构建一个高效的大数据存储与分析平台:
1. 选择适当的数据存储技术:
根据数据的特性和需求,选择适合的数据存储技术。常见的大数据存储技术包括分布式文件系统(如HDFS)、列式数据库(如Apache HBase)、对象存储(如Amazon S3)、关系数据库等。根据数据访问模式和查询需求,选择最适合的存储技术。
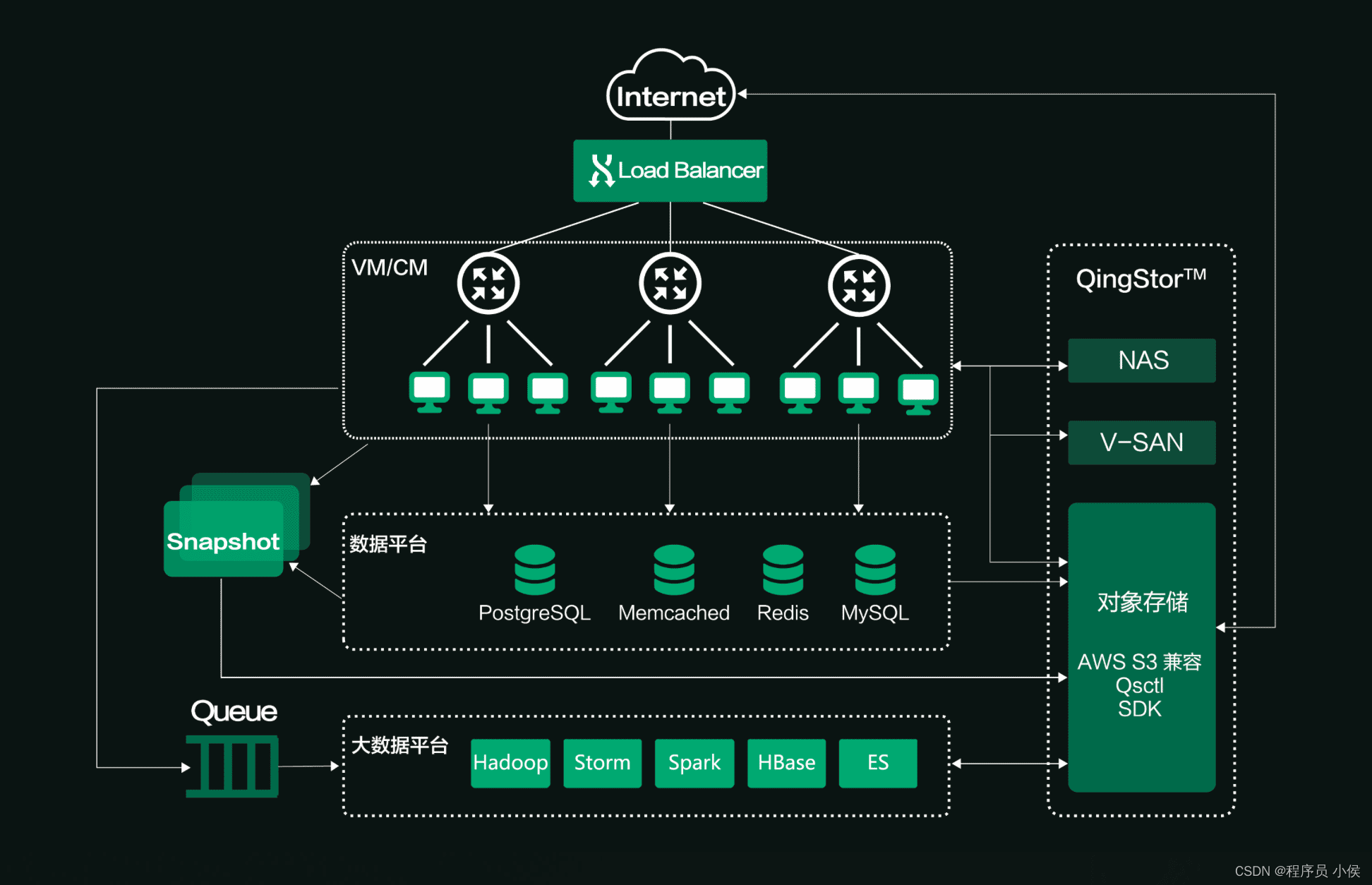
2. 采用分布式架构:
在大数据存储与分析平台中,采用分布式架构是必要的。分布式架构可以将数据存储在多个节点上,实现数据的并行处理和查询。采用分布式计算框架(如Apache Spark)进行数据分析,可以充分利用集群的计算资源。
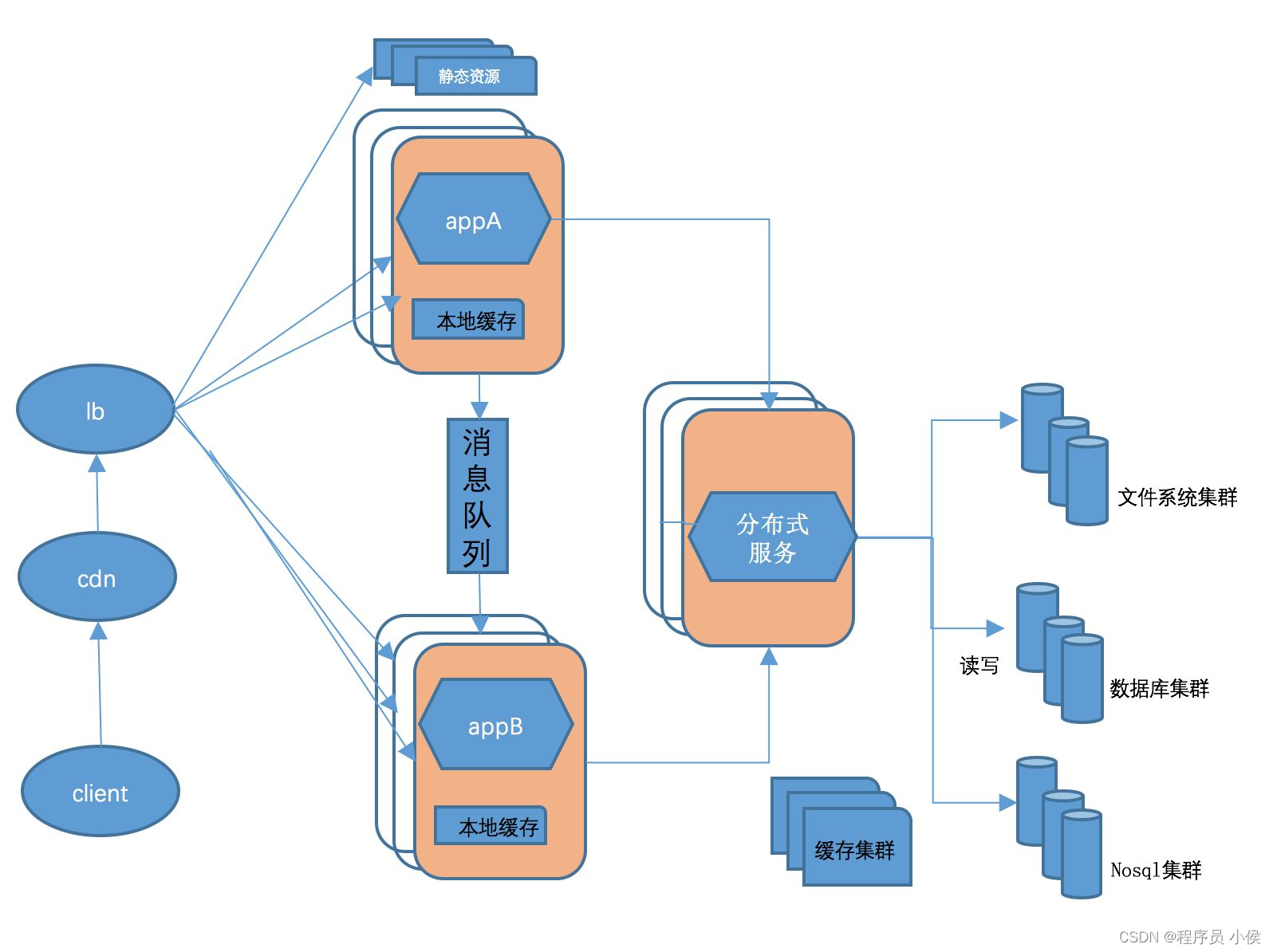
3. 数据分区和索引:
将数据进行适当的分区和索引,以加速数据访问和查询。根据查询需求,设计合适的索引结构,减少不必要的数据扫描和读取操作。
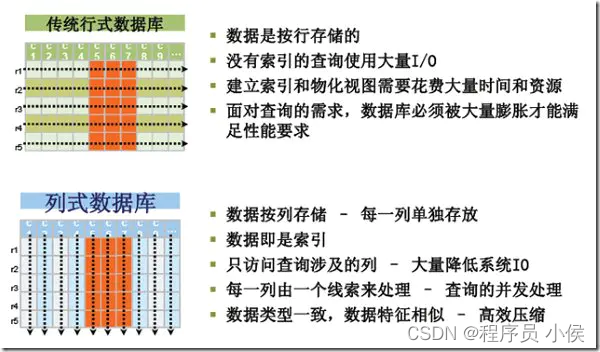
4. 采用列式存储:
列式存储引擎适用于分析型工作负载,可以提高查询性能。列式存储将数据按列存储,可以更有效地进行聚合和分析操作。
5. 数据压缩和编码:
采用适当的数据压缩和编码技术,减少存储空间的占用和数据传输的成本。压缩后的数据也可以提高读取和传输性能。
6. 使用缓存技术:
采用缓存技术,将常用的数据加载到内存中,提高数据访问速度。缓存可以在存储和计算层面进行,减少对底层存储的访问次数。
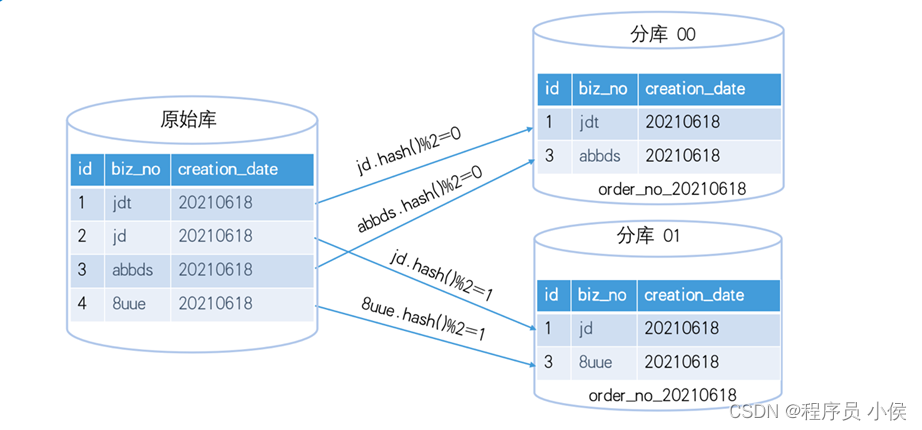
7. 数据分片和复制:
将数据分片存储在多个节点上,减轻单一节点的负担,提高系统的可扩展性。此外,数据的冗余复制可以增加数据的可用性和容错性。
8. 自动化运维和监控:
使用自动化工具管理和监控平台的运维活动。自动化的伸缩和资源管理可以根据负载变化自动调整计算资源,保证性能稳定。
9. 数据安全和权限控制:
保障数据的安全性,实施适当的权限控制和访问管理。对于敏感数据,采用数据加密和身份认证技术,确保数据不受未经授权的访问。
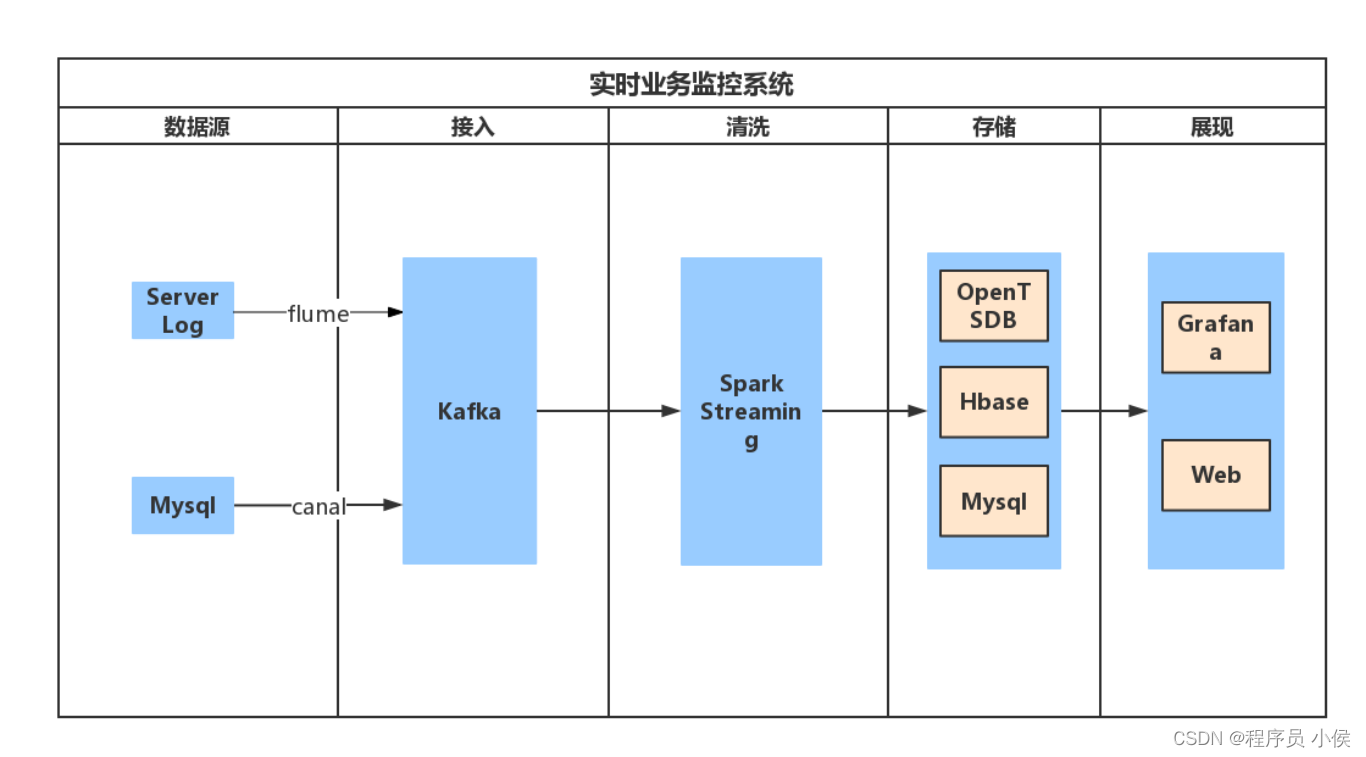
10. 实时处理和流式分析:
在平台中集成实时处理和流式分析能力,可以在数据产生时即时分析和处理数据。采用流式处理框架(如Apache Kafka、Apache Flink)可以实现实时数据流的处理。
11. 数据质量和清洗:
确保数据质量和准确性,进行数据清洗和预处理。垃圾数据和重复数据会影响分析结果的准确性,因此需要进行数据清理和校验。
12. 持续优化和改进:
不断地优化和改进平台性能。通过持续的监控和性能分析,发现瓶颈并采取相应的优化措施,以保持平台的高效性能。
通过综合考虑上述方法和策略,您可以在云原生环境中构建一个高效、可扩展的大数据存储与分析平台,满足不断增长的数据分析需求。同时,持续的优化和改进将确保平台的性能和稳定性。
后记 👉👉💕💕美好的一天,到此结束,下次继续努力!欲知后续,请看下回分解,写作不易,感谢大家的支持!! 🌹🌹🌹