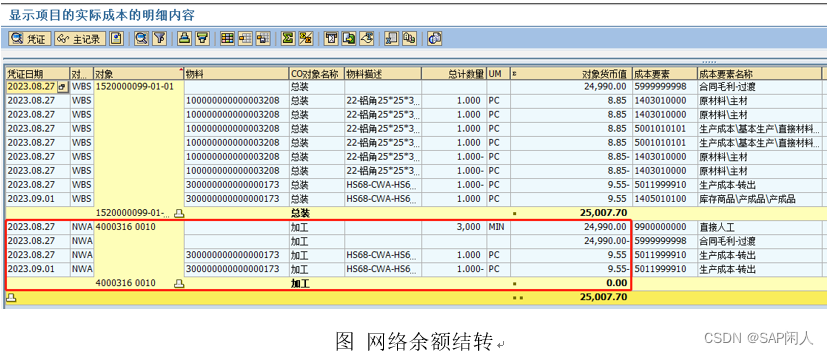
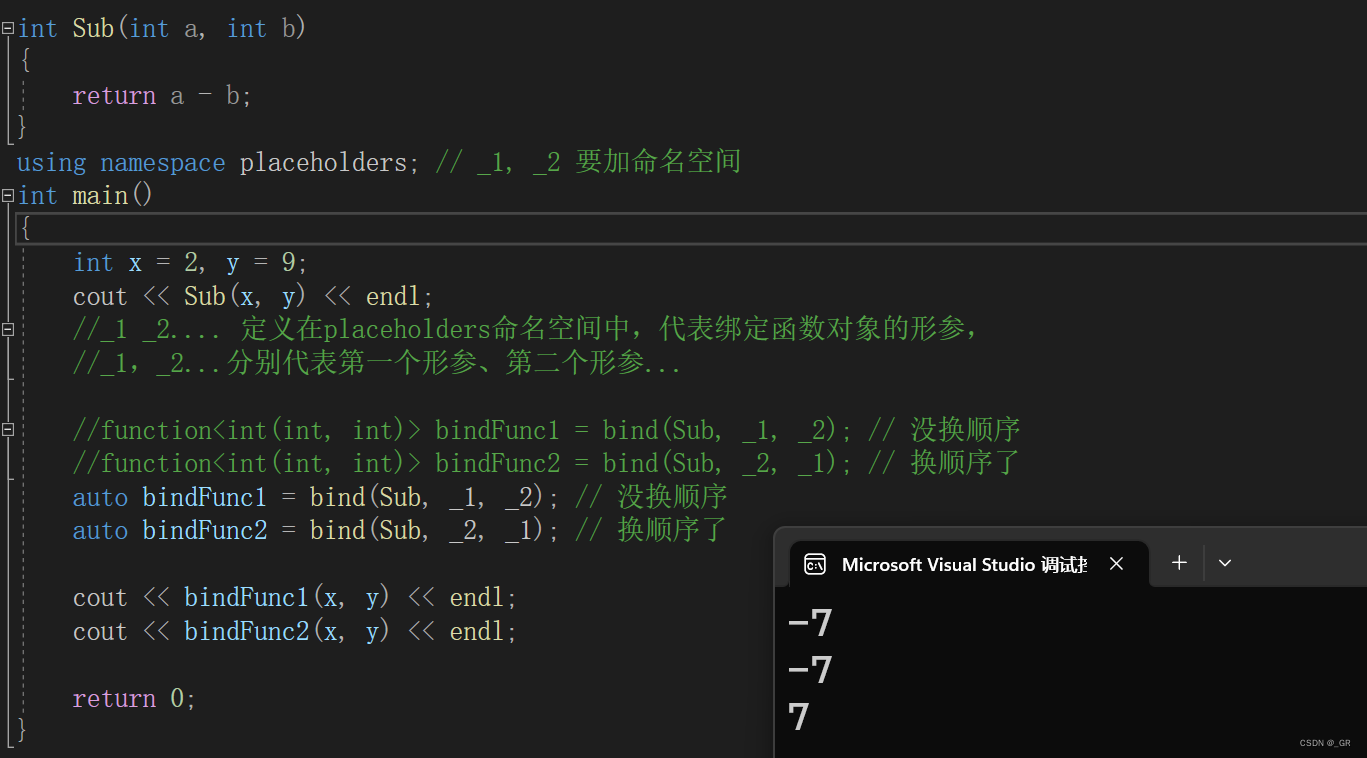
现在我们已经学习了 Rust 编程语言中最常用的部分。在第二十章开始另一个新项目之前,让我们聊聊一些总有一天你会遇上的部分内容。你可以将本章作为不经意间遇到未知的内容时的参考。本章将要学习的功能在一些非常特定的场景下很有用处。虽然很少会碰到它们,我们希望确保你了解 Rust 提供的所有功能。
本章将涉及如下内容:
- 不安全 Rust:用于当需要舍弃 Rust 的某些保证并负责手动维持这些保证
- 高级 trait:与 trait 相关的关联类型,默认类型参数,完全限定语法(fully qualified syntax),超(父)trait(supertraits)和 newtype 模式
- 高级类型:关于 newtype 模式的更多内容,类型别名,never 类型和动态大小类型
- 高级函数和闭包:函数指针和返回闭包
- 宏:定义在编译时定义更多代码的方式
19.1 不安全Rust
目前为止讨论过的代码都有 Rust 在编译时会强制执行的内存安全保证。然而,Rust 还隐藏有第二种语言,它不会强制执行这类内存安全保证:这被称为 不安全 Rust(unsafe Rust)。它与常规 Rust 代码无异,但是会提供额外的超级力量。
不安全 Rust 之所以存在,是因为静态分析本质上是保守的。当编译器尝试确定一段代码是否支持某个保证时,拒绝一些有效的程序比接受无效程序要好一些。这必然意味着有时代码可能是合法的,但是 Rust 不这么认为!在这种情况下,可以使用不安全代码告诉编译器,“相信我,我知道我在干什么。”这么做的缺点就是你只能靠自己了:如果不安全代码出错了,比如解引用空指针,可能会导致不安全的内存使用。
另一个 Rust 存在不安全一面的原因是:底层计算机硬件固有的不安全性。如果 Rust 不允许进行不安全操作,那么有些任务则根本完成不了。Rust 需要能够进行像直接与操作系统交互,甚至于编写你自己的操作系统这样的底层系统编程!这也是 Rust 语言的目标之一。让我们看看不安全 Rust 能做什么,和怎么做。
不安全的超级力量
可以通过 unsafe 关键字来切换到不安全 Rust,接着可以开启一个新的存放不安全代码的块。这里有四类可以在不安全 Rust 中进行而不能用于安全 Rust 的操作,它们称之为 “不安全的超级力量。” 这些超级力量是:
- 解引用裸指针
- 调用不安全的函数或方法
- 访问或修改可变静态变量
- 实现不安全 trait
- 访问
union的字段
有一点很重要,unsafe 并不会关闭借用检查器或禁用任何其他 Rust 安全检查:如果在不安全代码中使用引用,它仍会被检查。unsafe 关键字只是提供了那四个不会被编译器检查内存安全的功能。你仍然能在不安全块中获得某种程度的安全。
再者,unsafe 不意味着块中的代码就一定是危险的或者必然导致内存安全问题:其意图在于作为程序员你将会确保 unsafe 块中的代码以有效的方式访问内存。
人是会犯错误的,错误总会发生,不过通过要求这四类操作必须位于标记为 unsafe 的块中,就能够知道任何与内存安全相关的错误必定位于 unsafe 块内。保持 unsafe 块尽可能小,如此当之后调查内存 bug 时就会感谢你自己了。
为了尽可能隔离不安全代码,将不安全代码封装进一个安全的抽象并提供安全 API 是一个好主意,当我们学习不安全函数和方法时会讨论到。标准库的一部分被实现为在被评审过的不安全代码之上的安全抽象。这个技术防止了 unsafe 泄露到所有你或者用户希望使用由 unsafe 代码实现的功能的地方,因为使用其安全抽象是安全的。
让我们按顺序依次介绍上述四个超级力量,同时我们会看到一些提供不安全代码的安全接口的抽象。
解引用裸指针
回到第四章的悬垂引用部分,那里提到了编译器会确保引用总是有效的。不安全 Rust 有两个被称为 裸指针(raw pointers)的类似于引用的新类型。和引用一样,裸指针是可变或不可变的,分别写作 *const T 和 *mut T。这里的星号不是解引用运算符;它是类型名称的一部分。在裸指针的上下文中,不可变 意味着指针解引用之后不能直接赋值。
与引用和智能指针的区别在于,记住裸指针
- 允许忽略借用规则,可以同时拥有不可变和可变的指针,或多个指向相同位置的可变指针
- 不保证指向有效的内存
- 允许为空
- 不能实现任何自动清理功能
通过去掉 Rust 强加的保证,你可以放弃安全保证以换取性能或使用另一个语言或硬件接口的能力,此时 Rust 的保证并不适用。
fn main() {let mut num = 5;let r1 = &num as *const i32;let r2 = &mut num as *mut i32;
}
注意这里没有引入 unsafe 关键字。可以在安全代码中 创建 裸指针,只是不能在不安全块之外 解引用 裸指针,稍后便会看到。
这里使用 as 将不可变和可变引用强转为对应的裸指针类型。因为直接从保证安全的引用来创建他们,可以知道这些特定的裸指针是有效,但是不能对任何裸指针做出如此假设。
接下来会创建一个不能确定其有效性的裸指针,下面示例展示了如何创建一个指向任意内存地址的裸指针。尝试使用任意内存是未定义行为:此地址可能有数据也可能没有,编译器可能会优化掉这个内存访问,或者程序可能会出现段错误(segmentation fault)。通常没有好的理由编写这样的代码,不过却是可行的:
fn main() {let address = 0x012345usize;let r = address as *const i32;
}
记得我们说过可以在安全代码中创建裸指针,不过不能 解引用 裸指针和读取其指向的数据。现在我们要做的就是对裸指针使用解引用运算符 *,这需要一个 unsafe 块
fn main() {let mut num = 5;let r1 = &num as *const i32;let r2 = &mut num as *mut i32;unsafe {println!("r1 is: {}", *r1);println!("r2 is: {}", *r2);}
}
创建一个指针不会造成任何危险;只有当访问其指向的值时才有可能遇到无效的值。
还需注意上面示例中创建了同时指向相同内存位置 num 的裸指针 *const i32 和 *mut i32。相反如果尝试创建 num 的不可变和可变引用,这将无法编译因为 Rust 的所有权规则不允许拥有可变引用的同时拥有不可变引用。通过裸指针,就能够同时创建同一地址的可变指针和不可变指针,若通过可变指针修改数据,则可能潜在造成数据竞争。请多加小心!
既然存在这么多的危险,为何还要使用裸指针呢?一个主要的应用场景便是调用 C 代码接口,这在下一部分 “调用不安全函数或方法” 中会讲到。另一个场景是构建借用检查器无法理解的安全抽象。让我们先介绍不安全函数,接着看一看使用不安全代码的安全抽象的例子。
调用不安全函数或方法
第二类要求使用不安全块的操作是调用不安全函数。不安全函数和方法与常规函数方法十分类似,除了其开头有一个额外的 unsafe。在此上下文中,关键字unsafe表示该函数具有调用时需要满足的要求,而 Rust 不会保证满足这些要求。通过在 unsafe 块中调用不安全函数,表明我们已经阅读过此函数的文档并对其是否满足函数自身的契约负责。
如下是一个没有做任何操作的不安全函数 dangerous 的例子:
fn main() {}unsafe fn dangerous() {}unsafe {dangerous();
}
必须在一个单独的 unsafe 块中调用 dangerous 函数。如果尝试不使用 unsafe 块调用 dangerous,则会得到一个错误:

通过将 dangerous 调用插入 unsafe 块中,我们就向 Rust 保证了我们已经阅读过函数的文档,理解如何正确使用,并验证过其满足函数的契约。
不安全函数体也是有效的 unsafe 块,所以在不安全函数中进行另一个不安全操作时无需新增额外的 unsafe 块。
创建不安全代码的安全抽象
仅仅因为函数包含不安全代码并不意味着整个函数都需要标记为不安全的。事实上,将不安全代码封装进安全函数是一个常见的抽象。作为一个例子,标准库中的函数,split_at_mut,它需要一些不安全代码,让我们探索如何可以实现它。这个安全函数定义于可变 slice 之上:它获取一个 slice 并从给定的索引参数开始将其分为两个 slice。
fn main() {let mut v = vec![1, 2, 3, 4, 5, 6];let r = &mut v[..];let (a, b) = r.split_at_mut(3);assert_eq!(a, &mut [1, 2, 3]);assert_eq!(b, &mut [4, 5, 6]);
}
这个函数无法只通过安全 Rust 实现。一个尝试可能看起来像下面示例,它不能编译。出于简单考虑,我们将 split_at_mut 实现为函数而不是方法,并只处理 i32 值而非泛型 T 的 slice。
fn main() {}fn split_at_mut(slice: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {let len = slice.len();assert!(mid <= len);(&mut slice[..mid],&mut slice[mid..])
}
此函数首先获取 slice 的长度,然后通过检查参数是否小于或等于这个长度来断言参数所给定的索引位于 slice 当中。该断言意味着如果传入的索引比要分割的 slice 的索引更大,此函数在尝试使用这个索引前 panic。
之后我们在一个元组中返回两个可变的 slice:一个从原始 slice 的开头直到 mid 索引,另一个从 mid 直到原 slice 的结尾。
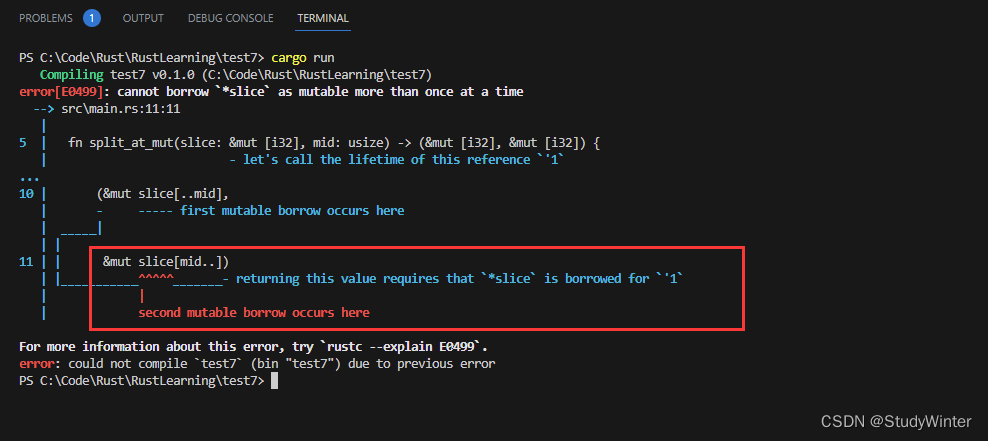
Rust 的借用检查器不能理解我们要借用这个 slice 的两个不同部分:它只知道我们借用了同一个 slice 两次。本质上借用 slice 的不同部分是可以的,因为结果两个 slice 不会重叠,不过 Rust 还没有智能到能够理解这些。当我们知道某些事是可以的而 Rust 不知道的时候,就是触及不安全代码的时候了。
下面示例展示了如何使用 unsafe 块,裸指针和一些不安全函数调用来实现 split_at_mut:
fn main() {}use std::slice;fn split_at_mut(slice: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {let len = slice.len();let ptr = slice.as_mut_ptr();assert!(mid <= len);unsafe {(slice::from_raw_parts_mut(ptr, mid),slice::from_raw_parts_mut(ptr.offset(mid as isize), len - mid))}
}
回忆第四章的 “Slice 类型” 部分,slice 是一个指向一些数据的指针,并带有该 slice 的长度。可以使用 len 方法获取 slice 的长度,使用 as_mut_ptr 方法访问 slice 的裸指针。在这个例子中,因为有一个 i32 值的可变 slice,as_mut_ptr 返回一个 *mut i32 类型的裸指针,储存在 ptr 变量中。
我们保持索引 mid 位于 slice 中的断言。接着是不安全代码:slice::from_raw_parts_mut 函数获取一个裸指针和一个长度来创建一个 slice。这里使用此函数从 ptr 中创建了一个有 mid 个项的 slice。之后在 ptr 上调用 offset 方法并使用 mid 作为参数来获取一个从 mid 开始的裸指针,使用这个裸指针并以 mid 之后项的数量为长度创建一个 slice。
slice::from_raw_parts_mut 函数是不安全的因为它获取一个裸指针,并必须确信这个指针是有效的。裸指针上的 offset 方法也是不安全的,因为其必须确信此地址偏移量也是有效的指针。因此必须将 slice::from_raw_parts_mut 和 offset 放入 unsafe 块中以便能调用它们。通过观察代码,和增加 mid 必然小于等于 len 的断言,我们可以说 unsafe 块中所有的裸指针将是有效的 slice 中数据的指针。这是一个可以接受的 unsafe 的恰当用法。
注意无需将 split_at_mut 函数的结果标记为 unsafe,并可以在安全 Rust 中调用此函数。我们创建了一个不安全代码的安全抽象,其代码以一种安全的方式使用了 unsafe 代码,因为其只从这个函数访问的数据中创建了有效的指针。
与此相对,下面示例中的 slice::from_raw_parts_mut 在使用 slice 时很有可能会崩溃。这段代码获取任意内存地址并创建了一个长为一万的 slice:
fn main() {}use std::slice;let address = 0x01234usize;
let r = address as *mut i32;let slice: &[i32] = unsafe {slice::from_raw_parts_mut(r, 10000)
};
我们并不拥有这个任意地址的内存,也不能保证这段代码创建的 slice 包含有效的 i32 值。试图使用臆测为有效的 slice 会导致未定义的行为。
使用extern函数调用外部代码
有时你的 Rust 代码可能需要与其他语言编写的代码交互。为此 Rust 有一个关键字,extern,有助于创建和使用 外部函数接口(Foreign Function Interface, FFI)。外部函数接口是一个编程语言用以定义函数的方式,其允许不同(外部)编程语言调用这些函数。
下面示例展示了如何集成 C 标准库中的 abs 函数。extern 块中声明的函数在 Rust 代码中总是不安全的。因为其他语言不会强制执行 Rust 的规则且 Rust 无法检查它们,所以确保其安全是程序员的责任:
extern "C" {fn abs(input: i32) -> i32;
}fn main() {unsafe {println!("Absolute value of -3 according to C: {}", abs(-3));}
}
在 extern "C" 块中,列出了我们希望能够调用的另一个语言中的外部函数的签名和名称。"C" 部分定义了外部函数所使用的 应用程序接口(application binary interface,ABI) —— ABI 定义了如何在汇编语言层面调用此函数。"C" ABI 是最常见的,并遵循 C 编程语言的 ABI。
从其它语言调用Rust函数
也可以使用
extern来创建一个允许其他语言调用 Rust 函数的接口。不同于extern块,就在fn关键字之前增加extern关键字并指定所用到的 ABI。还需增加#[no_mangle]注解来告诉 Rust 编译器不要 mangle 此函数的名称。Mangling 发生于当编译器将我们指定的函数名修改为不同的名称时,这会增加用于其他编译过程的额外信息,不过会使其名称更难以阅读。每一个编程语言的编译器都会以稍微不同的方式 mangle 函数名,所以为了使 Rust 函数能在其他语言中指定,必须禁用 Rust 编译器的 name mangling。在如下的例子中,一旦其编译为动态库并从 C 语言中链接,
call_from_c函数就能够在 C 代码中访问:#[no_mangle] pub extern "C" fn call_from_c() {println!("Just called a Rust function from C!");
extern的使用无需unsafe。
访问或修改可变静态变量
目前为止全书都尽量避免讨论 全局变量(global variables),Rust 确实支持他们,不过这对于 Rust 的所有权规则来说是有问题的。如果有两个线程访问相同的可变全局变量,则可能会造成数据竞争。
全局变量在 Rust 中被称为 静态(static)变量。下面示例展示了一个拥有字符串 slice 值的静态变量的声明和应用:
static HELLO_WORLD: &str = "Hello, world!";fn main() {println!("name is: {}", HELLO_WORLD);
}
static 变量类似于第三章部分讨论的常量。通常静态变量的名称采用 SCREAMING_SNAKE_CASE 写法,并 必须 标注变量的类型,在这个例子中是 &'static str。静态变量只能储存拥有 'static 生命周期的引用,这意味着 Rust 编译器可以自己计算出其生命周期而无需显式标注。访问不可变静态变量是安全的。
常量与不可变静态变量可能看起来很类似,不过一个微妙的区别是静态变量中的值有一个固定的内存地址。使用这个值总是会访问相同的地址。另一方面,常量则允许在任何被用到的时候复制其数据。
常量与静态变量的另一个区别在于静态变量可以是可变的。访问和修改可变静态变量都是 不安全 的。下面示例展示了如何声明、访问和修改名为 COUNTER 的可变静态变量:
static mut COUNTER: u32 = 0;fn add_to_count(inc: u32) {unsafe {COUNTER += inc;}
}fn main() {add_to_count(3);unsafe {println!("COUNTER: {}", COUNTER);}
}
就像常规变量一样,我们使用 mut 关键来指定可变性。任何读写 COUNTER 的代码都必须位于 unsafe 块中。这段代码可以编译并如期打印出 COUNTER: 3,因为这是单线程的。拥有多个线程访问 COUNTER 则可能导致数据竞争。
拥有可以全局访问的可变数据,难以保证不存在数据竞争,这就是为何 Rust 认为可变静态变量是不安全的。任何可能的情况,请优先使用第十六章讨论的并发技术和线程安全智能指针,这样编译器就能检测不同线程间的数据访问是否是安全的。
实现不安全trait
最后一个只能用在 unsafe 中的操作是实现不安全 trait。当至少有一个方法中包含编译器不能验证的不变量时 trait 是不安全的。可以在 trait 之前增加 unsafe 关键字将 trait 声明为 unsafe,同时 trait 的实现也必须标记为 unsafe
unsafe trait Foo {// methods go here
}unsafe impl Foo for i32 {// method implementations go here
}
通过 unsafe impl,我们承诺将保证编译器所不能验证的不变量。
作为一个例子,回忆第十六章部分中的 Sync 和 Send 标记 trait,编译器会自动为完全由 Send 和 Sync 类型组成的类型自动实现他们。如果实现了一个包含一些不是 Send 或 Sync 的类型,比如裸指针,并希望将此类型标记为 Send 或 Sync,则必须使用 unsafe。Rust 不能验证我们的类型保证可以安全的跨线程发送或在多线程键访问,所以需要我们自己进行检查并通过 unsafe 表明。
何时使用不安全代码
使用 unsafe 来进行这四个操作(超级力量)之一是没有问题的,甚至是不需要深思熟虑的,不过使得 unsafe 代码正确也实属不易,因为编译器不能帮助保证内存安全。当有理由使用 unsafe 代码时,是可以这么做的,通过使用显式的 unsafe 标注使得在出现错误时易于追踪问题的源头。
19.2 高级trait
第十章部分,我们第一次涉及到了 trait,不过就像生命周期一样,我们并没有覆盖一些较为高级的细节。现在我们更加了解 Rust 了,可以深入理解其本质了。
关联类型在trait定义中指定占位符类型
关联类型(associated types)是一个将类型占位符与 trait 相关联的方式,这样 trait 的方法签名中就可以使用这些占位符类型。trait 的实现者会针对特定的实现在这个类型的位置指定相应的具体类型。如此可以定义一个使用多种类型的 trait,直到实现此 trait 时都无需知道这些类型具体是什么。
本章所描述的大部分内容都非常少见。关联类型则比较适中;它们比本书其他的内容要少见,不过比本章中的很多内容要更常见。
一个带有关联类型的 trait 的例子是标准库提供的 Iterator trait。它有一个叫做 Item 的关联类型来替代遍历的值的类型。第十三章的 “Iterator trait 和 next 方法” 部分曾提到过 Iterator trait 的定义如下面示例所示:
pub trait Iterator {type Item;fn next(&mut self) -> Option<Self::Item>;
}
Item 是一个占位类型,同时 next 方法定义表明它返回 Option<Self::Item> 类型的值。这个 trait 的实现者会指定 Item 的具体类型,然而不管实现者指定何种类型, next 方法都会返回一个包含了此具体类型值的 Option。
关联类型看起来像一个类似泛型的概念,因为它允许定义一个函数而不指定其可以处理的类型。那么为什么要使用关联类型呢?
让我们通过一个在第十三章中出现的 Counter 结构体上实现 Iterator trait 的例子来检视其中的区别。
impl Iterator for Counter {type Item = u32;fn next(&mut self) -> Option<Self::Item> {// --snip--区别在于当如前面示例那样使用泛型时,则不得不在每一个实现中标注类型。这是因为我们也可以实现为 Iterator<String> for Counter,或任何其他类型,这样就可以有多个 Counter 的 Iterator 的实现。换句话说,当 trait 有泛型参数时,可以多次实现这个 trait,每次需改变泛型参数的具体类型。接着当使用 Counter 的 next 方法时,必须提供类型注解来表明希望使用 Iterator 的哪一个实现。
通过关联类型,则无需标注类型因为不能多次实现这个 trait。对于示例使用关联类型的定义,我们只能选择一次 Item 会是什么类型,因为只能有一个 impl Iterator for Counter。当调用 Counter 的 next 时不必每次指定我们需要 u32 值的迭代器。
默认泛型类型参数和运算符重载
当使用泛型类型参数时,可以为泛型指定一个默认的具体类型。如果默认类型就足够的话,这消除了为具体类型实现 trait 的需要。为泛型类型指定默认类型的语法是在声明泛型类型时使用 <PlaceholderType=ConcreteType>。
这种情况的一个非常好的例子是用于运算符重载。运算符重载(Operator overloading)是指在特定情况下自定义运算符(比如 +)行为的操作。
Rust 并不允许创建自定义运算符或重载任意运算符,不过 std::ops 中所列出的运算符和相应的 trait 可以通过实现运算符相关 trait 来重载。
use std::ops::Add;#[derive(Debug, PartialEq)]
struct Point {x: i32,y: i32,
}impl Add for Point {type Output = Point;fn add(self, other: Point) -> Point {Point {x: self.x + other.x,y: self.y + other.y,}}
}fn main() {assert_eq!(Point { x: 1, y: 0 } + Point { x: 2, y: 3 },Point { x: 3, y: 3 });
}
add 方法将两个 Point 实例的 x 值和 y 值分别相加来创建一个新的 Point。Add trait 有一个叫做 Output 的关联类型,它用来决定 add 方法的返回值类型。
这里默认泛型类型位于 Add trait 中。这里是其定义:
trait Add<RHS=Self> {type Output;fn add(self, rhs: RHS) -> Self::Output;
}
这看来应该很熟悉,这是一个带有一个方法和一个关联类型的 trait。比较陌生的部分是尖括号中的 RHS=Self:这个语法叫做 默认类型参数(default type parameters)。RHS 是一个泛型类型参数(“right hand side” 的缩写),它用于定义 add 方法中的 rhs 参数。如果实现 Add trait 时不指定 RHS 的具体类型,RHS 的类型将是默认的 Self 类型,也就是在其上实现 Add 的类型。
当为 Point 实现 Add 时,使用了默认的 RHS,因为我们希望将两个 Point 实例相加。让我们看看一个实现 Add trait 时希望自定义 RHS 类型而不是使用默认类型的例子
这里有两个存放不同单元值的结构体,Millimeters 和 Meters。我们希望能够将毫米值与米值相加,并让 Add 的实现正确处理转换。可以为 Millimeters 实现 Add 并以 Meters 作为 RHS,如下面示例所示。
use std::ops::Add;struct Millimeters(u32);
struct Meters(u32);impl Add<Meters> for Millimeters {type Output = Millimeters;fn add(self, other: Meters) -> Millimeters {Millimeters(self.0 + (other.0 * 1000))}
}fn main() {}为了使 Millimeters 和 Meters 能够相加,我们指定 impl Add<Meters> 来设定 RHS 类型参数的值而不是使用默认的 Self。
默认参数类型主要用于如下两个方面:
- 扩展类型而不破坏现有代码。
- 在大部分用户都不需要的特定情况进行自定义。
标准库的 Add trait 就是一个第二个目的例子:大部分时候你会将两个相似的类型相加,不过它提供了自定义额外行为的能力。在 Add trait 定义中使用默认类型参数意味着大部分时候无需指定额外的参数。换句话说,一小部分实现的样板代码是不必要的,这样使用 trait 就更容易了。
第一个目的是相似的,但过程是反过来的:如果需要为现有 trait 增加类型参数,为其提供一个默认类型将允许我们在不破坏现有实现代码的基础上扩展 trait 的功能。
完全限定语法与消歧义:调用相同名称的方法
Rust 既不能避免一个 trait 与另一个 trait 拥有相同名称的方法,也不能阻止为同一类型同时实现这两个 trait。甚至直接在类型上实现开始已经有的同名方法也是可能的!
不过,当调用这些同名方法时,需要告诉 Rust 我们希望使用哪一个。考虑一下下面示例中的代码,这里定义了 trait Pilot 和 Wizard 都拥有方法 fly。接着在一个本身已经实现了名为 fly 方法的类型 Human 上实现这两个 trait。每一个 fly 方法都进行了不同的操作:
trait Pilot {fn fly(&self);
}trait Wizard {fn fly(&self);
}struct Human;impl Pilot for Human {fn fly(&self) {println!("This is your captain speaking.");}
}impl Wizard for Human {fn fly(&self) {println!("Up!");}
}impl Human {fn fly(&self) {println!("*waving arms furiously*");}
}
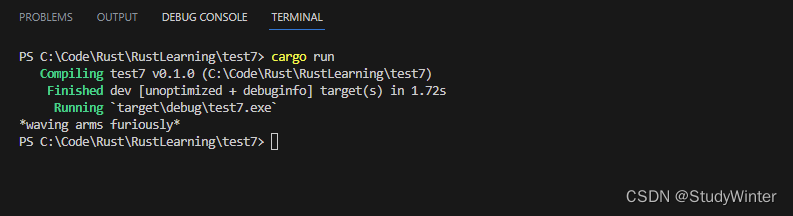
当调用 Human 实例的 fly 时,编译器默认调用直接是现在类型上的方法
fn main() {let person = Human;person.fly();
}
运行这段代码会打印出 *waving arms furiously*,这表明 Rust 调用了直接实现在 Human 上的 fly 方法。
为了能够调用 Pilot trait 或 Wizard trait 的 fly 方法,我们需要使用更明显的语法以便能指定我们指的是哪个 fly 方法。
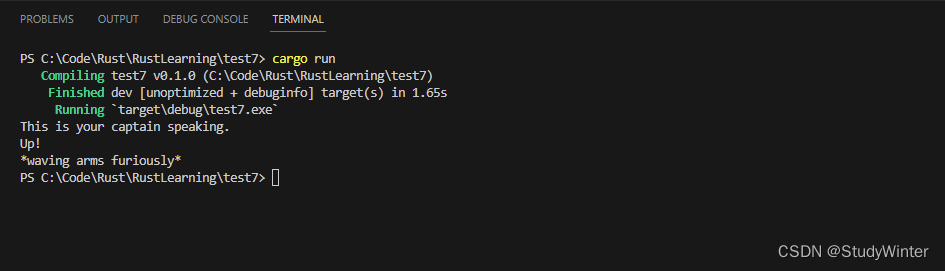
fn main() {let person = Human;Pilot::fly(&person);Wizard::fly(&person);person.fly();
}在方法名前指定 trait 名向 Rust 澄清了我们希望调用哪个 fly 实现。也可以选择写成 Human::fly(&person),这等同于示例中的 person.fly(),不过如果无需消歧义的话这么写就有点长了。
运行这段代码会打印出:
因为 fly 方法获取一个 self 参数,如果有两个 类型 都实现了同一 trait,Rust 可以根据 self 的类型计算出应该使用哪一个 trait 实现。
然而,关联函数是 trait 的一部分,但没有 self 参数。当同一作用域的两个类型实现了同一 trait,Rust 就不能计算出我们期望的是哪一个类型,除非使用 完全限定语法(fully qualified syntax)。例如,拿下面示例的 Animal trait 来说,它有关联函数 baby_name,结构体 Dog 实现了 Animal,同时有关联函数 baby_name 直接定义于 Dog 之上:
trait Animal {fn baby_name() -> String;
}struct Dog;impl Dog {fn baby_name() -> String {String::from("Spot")}
}impl Animal for Dog {fn baby_name() -> String {String::from("puppy")}
}fn main() {println!("A baby dog is called a {}", Dog::baby_name());
}
这段代码用于一个动物收容所,他们将所有的小狗起名为 Spot,这实现为定义于 Dog 之上的关联函数 baby_name。Dog 类型还实现了 Animal trait,它描述了所有动物的共有的特征。小狗被称为 puppy,这表现为 Dog 的 Animal trait 实现中与 Animal trait 相关联的函数 baby_name。
在 main 调用了 Dog::baby_name 函数,它直接调用了定义于 Dog 之上的关联函数。这段代码会打印出:

这并不是我们需要的。我们希望调用的是 Dog 上 Animal trait 实现那部分的 baby_name 函数,这样能够打印出 A baby dog is called a puppy。示例 19-18 中用到的技术在这并不管用;如果将 main 改为下面示例中的代码,则会得到一个编译错误:
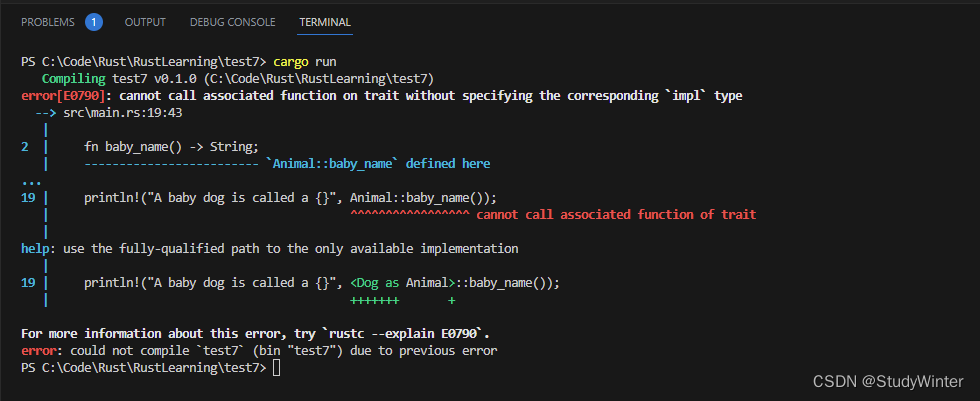
fn main() {println!("A baby dog is called a {}", Animal::baby_name());
}
因为 Animal::baby_name 是关联函数而不是方法,因此它没有 self 参数,Rust 无法计算出所需的是哪一个 Animal::baby_name 实现。我们会得到这个编译错误:
为了消歧义并告诉 Rust 我们希望使用的是 Dog 的 Animal 实现,需要使用 完全限定语法,这是调用函数时最为明确的方式。
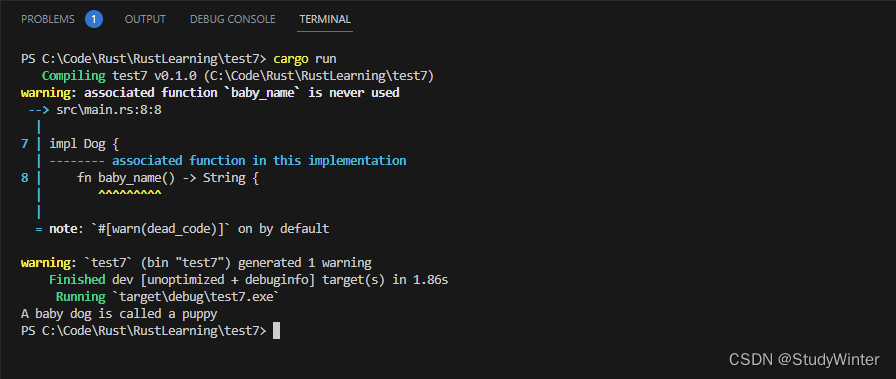
fn main() {println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
}
我们在尖括号中向 Rust 提供了类型注解,并通过在此函数调用中将 Dog 类型当作 Animal 对待,来指定希望调用的是 Dog 上 Animal trait 实现中的 baby_name 函数。现在这段代码会打印出我们期望的数据:
通常,完全限定语法定义为:
<Type as Trait>::function(receiver_if_method, next_arg, ...);
对于关联函数,其没有一个 receiver,故只会有其他参数的列表。可以选择在任何函数或方法调用处使用完全限定语法。然而,允许省略任何 Rust 能够从程序中的其他信息中计算出的部分。只有当存在多个同名实现而 Rust 需要帮助以便知道我们希望调用哪个实现时,才需要使用这个较为冗长的语法。
父trait用于在另一个trait中使用某trait的功能
有时我们可能会需要某个 trait 使用另一个 trait 的功能。在这种情况下,需要能够依赖相关的 trait 也被实现。这个所需的 trait 是我们实现的 trait 的 父(超) trait(supertrait)。
例如我们希望创建一个带有 outline_print 方法的 trait OutlinePrint,它会打印出带有星号框的值。也就是说,如果 Point 实现了 Display 并返回 (x, y),调用以 1 作为 x 和 3 作为 y 的 Point 实例的 outline_print 会显示如下:
**********
* *
* (1, 3) *
* *
**********
在 outline_print 的实现中,因为希望能够使用 Display trait 的功能,则需要说明 OutlinePrint 只能用于同时也实现了 Display 并提供了 OutlinePrint 需要的功能的类型。可以通过在 trait 定义中指定 OutlinePrint: Display 来做到这一点。这类似于为 trait 增加 trait bound。下面示例展示了一个 OutlinePrint trait 的实现:
use std::fmt;trait OutlinePrint: fmt::Display {fn outline_print(&self) {let output = self.to_string();let len = output.len();println!("{}", "*".repeat(len + 4));println!("*{}*", " ".repeat(len + 2));println!("* {} *", output);println!("*{}*", " ".repeat(len + 2));println!("{}", "*".repeat(len + 4));}
}fn main() {}
因为指定了 OutlinePrint 需要 Display trait,则可以在 outline_print 中使用 to_string, 其会为任何实现 Display 的类型自动实现。如果不在 trait 名后增加 : Display 并尝试在 outline_print 中使用 to_string,则会得到一个错误说在当前作用域中没有找到用于 &Self 类型的方法 to_string。
让我们看看如果尝试在一个没有实现 Display 的类型上实现 OutlinePrint 会发生什么,比如 Point 结构体:
struct Point {x: i32,y: i32,
}impl OutlinePrint for Point {}这样会得到一个错误说 Display 是必须的而未被实现:
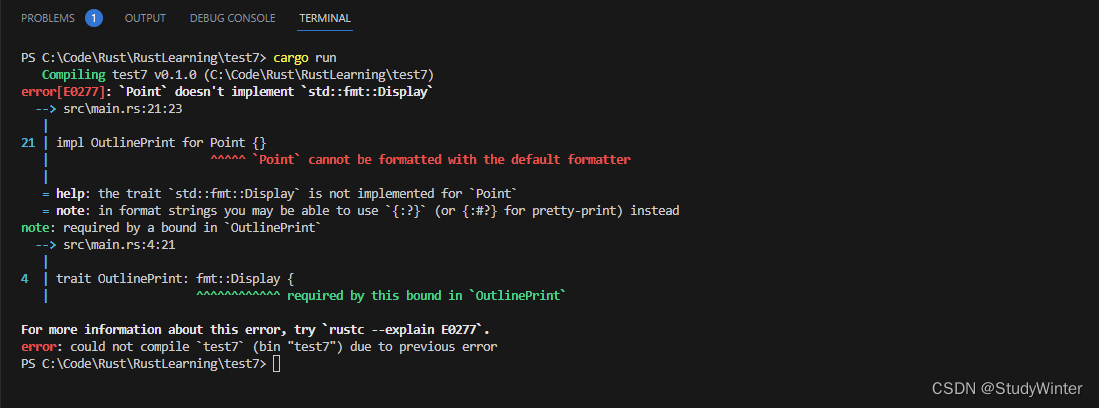
一旦在 Point 上实现 Display 并满足 OutlinePrint 要求的限制,比如这样:
use std::fmt;impl fmt::Display for Point {fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {write!(f, "({}, {})", self.x, self.y)}
}
那么在 Point 上实现 OutlinePrint trait 将能成功编译,并可以在 Point 实例上调用 outline_print 来显示位于星号框中的点的值。
newtype模式用以在外部类型上实现外部 trait
在第十章的 “为类型实现 trait” 部分,我们提到了孤儿规则(orphan rule),它说明只要 trait 或类型对于当前 crate 是本地的话就可以在此类型上实现该 trait。一个绕开这个限制的方法是使用 newtype 模式(newtype pattern),它涉及到在一个元组结构体(第五章 “用没有命名字段的元组结构体来创建不同的类型” 部分介绍了元组结构体)中创建一个新类型。这个元组结构体带有一个字段作为希望实现 trait 的类型的简单封装。接着这个封装类型对于 crate 是本地的,这样就可以在这个封装上实现 trait。Newtype 是一个源自(U.C.0079,逃)Haskell 编程语言的概念。使用这个模式没有运行时性能惩罚,这个封装类型在编译时就被省略了。
例如,如果想要在 Vec<T> 上实现 Display,而孤儿规则阻止我们直接这么做,因为 Display trait 和 Vec<T> 都定义于我们的 crate 之外。可以创建一个包含 Vec<T> 实例的 Wrapper 结构体,接着可以如列表那样在 Wrapper 上实现 Display 并使用 Vec<T> 的值:
use std::fmt;struct Wrapper(Vec<String>);impl fmt::Display for Wrapper {fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {write!(f, "[{}]", self.0.join(", "))}
}fn main() {let w = Wrapper(vec![String::from("hello"), String::from("world")]);println!("w = {}", w);
}
Display 的实现使用 self.0 来访问其内部的 Vec<T>,因为 Wrapper 是元组结构体而 Vec<T> 是结构体总位于索引 0 的项。接着就可以使用 Wrapper 中 Display 的功能了。
此方法的缺点是,因为 Wrapper 是一个新类型,它没有定义于其值之上的方法;必须直接在 Wrapper 上实现 Vec<T> 的所有方法,这样就可以代理到self.0 上 —— 这就允许我们完全像 Vec<T> 那样对待 Wrapper。如果希望新类型拥有其内部类型的每一个方法,为封装类型实现 Deref trait(第十五章 “通过 Deref trait 将智能指针当作常规引用处理” 部分讨论过)并返回其内部类型是一种解决方案。如果不希望封装类型拥有所有内部类型的方法 —— 比如为了限制封装类型的行为 —— 则必须只自行实现所需的方法。
19.3 高级类型
Rust 的类型系统有一些我们曾经提到但没有讨论过的功能。首先我们从一个关于为什么 newtype 与类型一样有用的更宽泛的讨论开始。接着会转向类型别名(type aliases),一个类似于 newtype 但有着稍微不同的语义的功能。我们还会讨论 ! 类型和动态大小类型。
为了类型安全和抽象而使用newtype模式
newtype 模式可以用于一些其他我们还未讨论的功能,包括静态的确保某值不被混淆,和用来表示一个值的单元。
另一个 newtype 模式的应用在于抽象掉一些类型的实现细节:例如,封装类型可以暴露出与直接使用其内部私有类型时所不同的公有 API,以便限制其功能。
newtype 也可以隐藏其内部的泛型类型。例如,可以提供一个封装了 HashMap<i32, String> 的 People 类型,用来储存人名以及相应的 ID。使用 People 的代码只需与提供的公有 API 交互即可,比如向 People 集合增加名字字符串的方法,这样这些代码就无需知道在内部我们将一个 i32 ID 赋予了这个名字了。newtype 模式是一种实现第十七章部分所讨论的隐藏实现细节的封装的轻量级方法。
类型别名用来创建类型同义词
连同 newtype 模式,Rust 还提供了声明 类型别名(type alias)的能力,使用 type 关键字来给予现有类型另一个名字。例如,可以像这样创建 i32 的别名 Kilometers:
type Kilometers = i32;
这意味着 Kilometers 是 i32 的 同义词(synonym);
type Kilometers = i32;let x: i32 = 5;
let y: Kilometers = 5;println!("x + y = {}", x + y);
因为 Kilometers 是 i32 的别名,他们是同一类型,可以将 i32 与 Kilometers 相加,也可以将 Kilometers 传递给获取 i32 参数的函数。但通过这种手段无法获得上一部分讨论的 newtype 模式所提供的类型检查的好处。
类型别名的主要用途是减少重复。例如,可能会有这样很长的类型:
Box<dyn Fn() + Send + 'static>
在函数签名或类型注解中每次都书写这个类型将是枯燥且易于出错的。想象一下如下面示例这样全是如此代码的项目:
let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi"));fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) {// --snip--
}fn returns_long_type() -> Box<dyn Fn() + Send + 'static> {// --snip--
}
类型别名通过减少项目中重复代码的数量来使其更加易于控制。这里我们为这个冗长的类型引入了一个叫做 Thunk 的别名,这样就可以如下面示例所示将所有使用这个类型的地方替换为更短的 Thunk:
type Thunk = Box<dyn Fn() + Send + 'static>;let f: Thunk = Box::new(|| println!("hi"));fn takes_long_type(f: Thunk) {// --snip--
}fn returns_long_type() -> Thunk {// --snip--
}
这样就读写起来就容易多了!为类型别名选择一个好名字也可以帮助你表达意图(单词 thunk 表示会在之后被计算的代码,所以这是一个存放闭包的合适的名字)。
类型别名也经常与 Result<T, E> 结合使用来减少重复。考虑一下标准库中的 std::io 模块。I/O 操作通常会返回一个 Result<T, E>,因为这些操作可能会失败。标准库中的 std::io::Error 结构体代表了所有可能的 I/O 错误。std::io 中大部分函数会返回 Result<T, E>,其中 E 是 std::io::Error,比如 Write trait 中的这些函数:
use std::io::Error;
use std::fmt;pub trait Write {fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;fn flush(&mut self) -> Result<(), Error>;fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>;fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>;
}
这里出现了很多的 Result<..., Error>。为此,std::io 有这个类型别名声明:
type Result<T> = std::result::Result<T, std::io::Error>;
因为这位于 std::io 中,可用的完全限定的别名是 std::io::Result<T> —— 也就是说,Result<T, E> 中 E 放入了 std::io::Error。Write trait 中的函数最终看起来像这样:
pub trait Write {fn write(&mut self, buf: &[u8]) -> Result<usize>;fn flush(&mut self) -> Result<()>;fn write_all(&mut self, buf: &[u8]) -> Result<()>;fn write_fmt(&mut self, fmt: Arguments) -> Result<()>;
}
类型别名在两个方面有帮助:易于编写 并 在整个 std::io 中提供了一致的接口。因为这是一个别名,它只是另一个 Result<T, E>,这意味着可以在其上使用 Result<T, E> 的任何方法,以及像 ? 这样的特殊语法。
从不返回的never type
Rust 有一个叫做 ! 的特殊类型。在类型理论术语中,它被称为 empty type,因为它没有值。我们更倾向于称之为 never type。这个名字描述了它的作用:在函数从不返回的时候充当返回值。例如:
fn bar() -> ! {// --snip--
}
这读 “函数 bar 从不返回”,而从不返回的函数被称为 发散函数(diverging functions)。不能创建 ! 类型的值,所以 bar 也不可能返回值。
let guess: u32 = match guess.trim().parse() {Ok(num) => num,Err(_) => continue,
};
当时我们忽略了代码中的一些细节。在第六章部分,我们学习了 match 的分支必须返回相同的类型。如下代码不能工作:
let guess = match guess.trim().parse() {Ok(_) => 5,Err(_) => "hello",
}
这里的 guess 必须既是整型 也是 字符串,而 Rust 要求 guess 只能是一个类型。
描述 ! 的行为的正式方式是 never type 可以强转为任何其他类型。允许 match 的分支以 continue 结束是因为 continue 并不真正返回一个值;相反它把控制权交回上层循环,所以在 Err 的情况,事实上并未对 guess 赋值。
never type 的另一个用途是 panic!。还记得 Option<T> 上的 unwrap 函数吗?它产生一个值或 panic。这里是它的定义:
impl<T> Option<T> {pub fn unwrap(self) -> T {match self {Some(val) => val,None => panic!("called `Option::unwrap()` on a `None` value"),}}
}
Rust 知道 val 是 T 类型,panic! 是 ! 类型,所以整个 match 表达式的结果是 T 类型。这能工作是因为 panic! 并不产生一个值;它会终止程序。对于 None 的情况,unwrap 并不返回一个值,所以这些代码是有效。
最后一个有着 ! 类型的表达式是 loop:
print!("forever ");loop {print!("and ever ");
}
这里,循环永远也不结束,所以此表达式的值是 !。但是如果引入 break 这就不为真了,因为循环在执行到 break 后就会终止。
动态大小类型和sized trait
因为 Rust 需要知道例如应该为特定类型的值分配多少空间这样的信息其类型系统的一个特定的角落可能令人迷惑:这就是 动态大小类型(dynamically sized types)的概念。这有时被称为 “DST” 或 “unsized types”,这些类型允许我们处理只有在运行时才知道大小的类型。
让我们深入研究一个贯穿本书都在使用的动态大小类型的细节:str。没错,不是 &str,而是 str 本身。str 是一个 DST;直到运行时我们都不知道字符串有多长。因为直到运行时都不能知道大其小,也就意味着不能创建 str 类型的变量,也不能获取 str 类型的参数。考虑一下这些代码,他们不能工作:
let s1: str = "Hello there!";
let s2: str = "How's it going?";
Rust 需要知道应该为特定类型的值分配多少内存,同时所有同一类型的值必须使用相同数量的内存。如果允许编写这样的代码,也就意味着这两个 str 需要占用完全相同大小的空间,不过它们有着不同的长度。这也就是为什么不可能创建一个存放动态大小类型的变量的原因。
那么该怎么办呢?你已经知道了这种问题的答案:s1 和 s2 的类型是 &str 而不是 str。如果你回想第四章 “字符串 slice” 部分,slice 数据结储存了开始位置和 slice 的长度。
所以虽然 &T 是一个储存了 T 所在的内存位置的单个值,&str 则是 两个 值:str 的地址和其长度。这样,&str 就有了一个在编译时可以知道的大小:它是 usize 长度的两倍。也就是说,我们总是知道 &str 的大小,而无论其引用的字符串是多长。这里是 Rust 中动态大小类型的常规用法:他们有一些额外的元信息来储存动态信息的大小。这引出了动态大小类型的黄金规则:必须将动态大小类型的值置于某种指针之后。
可以将 str 与所有类型的指针结合:比如 Box<str> 或 Rc<str>。事实上,之前我们已经见过了,不过是另一个动态大小类型:trait。每一个 trait 都是一个可以通过 trait 名称来引用的动态大小类型。在第十七章 “为使用不同类型的值而设计的 trait 对象” 部分,我们提到了为了将 trait 用于 trait 对象,必须将他们放入指针之后,比如 &Trait 或 Box<Trait>(Rc<Trait> 也可以)。
为了处理 DST,Rust 有一个特定的 trait 来决定一个类型的大小是否在编译时可知:这就是 Sized trait。这个 trait 自动为编译器在编译时就知道大小的类型实现。另外,Rust 隐式的为每一个泛型函数增加了 Sized bound。也就是说,对于如下泛型函数定义:
fn generic<T>(t: T) {// --snip--
}
实际上被当作如下处理:
fn generic<T: Sized>(t: T) {// --snip--
}
泛型函数默认只能用于在编译时已知大小的类型。然而可以使用如下特殊语法来放宽这个限制:
fn generic<T: ?Sized>(t: &T) {// --snip--
}
?Sized trait bound 与 Sized 相对;也就是说,它可以读作 “T 可能是也可能不是 Sized 的”。这个语法只能用于 Sized ,而不能用于其他 trait。
另外注意我们将 t 参数的类型从 T 变为了 &T:因为其类型可能不是 Sized 的,所以需要将其置于某种指针之后。在这个例子中选择了引用。
19.4 高级函数与闭包
最后我们将探索一些有关函数和闭包的高级功能:函数指针以及返回值闭包。
函数指针
我们讨论过了如何向函数传递闭包;也可以向函数传递常规函数!这在我们希望传递已经定义的函数而不是重新定义闭包作为参数是很有用。通过函数指针允许我们使用函数作为另一个函数的参数。函数的类型是 fn (使用小写的 “f” )以免与 Fn 闭包 trait 相混淆。fn 被称为 函数指针(function pointer)。指定参数为函数指针的语法类似于闭包。
fn add_one(x: i32) -> i32 {x + 1
}fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 {f(arg) + f(arg)
}fn main() {let answer = do_twice(add_one, 5);println!("The answer is: {}", answer);
}
这会打印出 The answer is: 12。do_twice 中的 f 被指定为一个接受一个 i32 参数并返回 i32 的 fn。接着就可以在 do_twice 函数体中调用 f。在 main 中,可以将函数名 add_one 作为第一个参数传递给 do_twice。
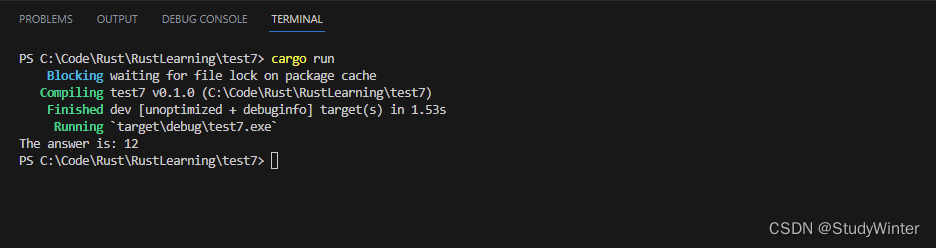
不同于闭包,fn 是一个类型而不是一个 trait,所以直接指定 fn 作为参数而不是声明一个带有 Fn 作为 trait bound 的泛型参数。
函数指针实现了所有三个闭包 trait(Fn、FnMut 和 FnOnce),所以总是可以在调用期望闭包的函数时传递函数指针作为参数。倾向于编写使用泛型和闭包 trait 的函数,这样它就能接受函数或闭包作为参数。
一个只期望接受 fn 而不接受闭包的情况的例子是与不存在闭包的外部代码交互时:C 语言的函数可以接受函数作为参数,但 C 语言没有闭包。
作为一个既可以使用内联定义的闭包又可以使用命名函数的例子,让我们看看一个 map 的应用。使用 map 函数将一个数字 vector 转换为一个字符串 vector,就可以使用闭包,比如这样:
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> = list_of_numbers.iter().map(|i| i.to_string()).collect();或者可以将函数作为 map 的参数来代替闭包,像是这样:
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> = list_of_numbers.iter().map(ToString::to_string).collect();注意这里必须使用 “高级 trait” 部分讲到的完全限定语法,因为存在多个叫做 to_string 的函数;这里使用了定义于 ToString trait 的 to_string 函数,标准库为所有实现了 Display 的类型实现了这个 trait。
另一个实用的模式暴露了元组结构体和元组结构体枚举成员的实现细节。这些项使用 () 作为初始化语法,这看起来就像函数调用,同时它们确实被实现为返回由参数构造的实例的函数。它们也被称为实现了闭包 trait 的函数指针,并可以采用类似如下的方式调用:
enum Status {Value(u32),Stop,
}let list_of_statuses: Vec<Status> =(0u32..20).map(Status::Value).collect();这里创建了 Status::Value 实例,它通过 map 用范围的每一个 u32 值调用 Status::Value 的初始化函数。一些人倾向于函数风格,一些人喜欢闭包。这两种形式最终都会产生同样的代码,所以请使用对你来说更明白的形式吧。
返回|闭包
闭包表现为 trait,这意味着不能直接返回闭包。对于大部分需要返回 trait 的情况,可以使用实现了期望返回的 trait 的具体类型来替代函数的返回值。但是这不能用于闭包,因为他们没有一个可返回的具体类型;例如不允许使用函数指针 fn 作为返回值类型。
这段代码尝试直接返回闭包,它并不能编译:
fn returns_closure() -> Fn(i32) -> i32 {|x| x + 1
}编译器给出的错误是:
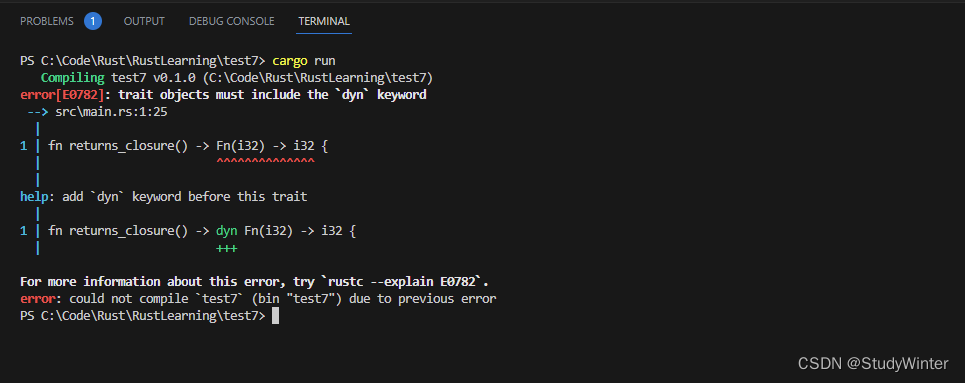
错误又一次指向了 Sized trait!Rust 并不知道需要多少空间来储存闭包。不过我们在上一部分见过这种情况的解决办法:可以使用 trait 对象:
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {Box::new(|x| x + 1)
}这段代码正好可以编译。关于 trait 对象的更多内容,请回顾第十七章。
19.5 宏
我们已经在本书中使用过像 println! 这样的宏了,不过还没完全探索什么是宏以及它是如何工作的。宏(Macro)指的是 Rust 中一系列的功能:声明(Declarative)宏,使用 macro_rules!,和三种 过程(Procedural)宏:
- 自定义
#[derive]宏在结构体和枚举上指定通过derive属性添加的代码 - 类属性(Attribute)宏定义可用于任意项的自定义属性
- 类函数宏看起来像函数不过作用于作为参数传递的 token。
我们会依次讨论每一种宏,不过首要的是,为什么已经有了函数还需要宏呢?
宏和函数的区别
从根本上来说,宏是一种为写其他代码而写代码的方式,即所谓的 元编程(metaprogramming)。在附录 C 中会探讨 derive 属性,其生成各种 trait 的实现。我们也在本书中使用过 println! 宏和 vec! 宏。所有的这些宏以 展开 的方式来生成比你所手写出的更多的代码。
元编程对于减少大量编写和维护的代码是非常有用的,它也扮演了函数的角色。但宏有一些函数所没有的附加能力。
一个函数标签必须声明函数参数个数和类型。相比之下,宏只接受一个可变参数:用一个参数调用 println!("hello") 或用两个参数调用 println!("hello {}", name) 。而且,宏可以在编译器翻译代码前展开,例如,宏可以在一个给定类型上实现 trait 。而函数则不行,因为函数是在运行时被调用,同时 trait 需要在编译时实现。
实现一个宏而不是函数的消极面是宏定义要比函数定义更复杂,因为你正在编写生成 Rust 代码的 Rust 代码。由于这样的间接性,宏定义通常要比函数定义更难阅读、理解以及维护。
宏和函数的最后一个重要的区别是:在调用宏 之前 必须定义并将其引入作用域,而函数则可以在任何地方定义和调用。
使用macro_rules!的声明宏用于通用元编程
Rust 最常用的宏形式是 声明宏(declarative macros)。它们有时也被称为 “macros by example”、“macro_rules! 宏” 或者就是 “macros”。其核心概念是,声明宏允许我们编写一些类似 Rust match 表达式的代码。正如在第六章讨论的那样,match 表达式是控制结构,其接收一个表达式,与表达式的结果进行模式匹配,然后根据模式匹配执行相关代码。宏也将一个值和包含相关代码的模式进行比较;此种情况下,该值是传递给宏的 Rust 源代码字面值,模式用于和传递给宏的源代码进行比较,同时每个模式的相关代码则用于替换传递给宏的代码。所有这一切都发生于编译时。
可以使用 macro_rules! 来定义宏。让我们通过查看 vec! 宏定义来探索如何使用 macro_rules! 结构。第八章讲述了如何使用 vec! 宏来生成一个给定值的 vector。例如,下面的宏用三个整数创建一个 vector:
fn main() {let v : Vec<u32> = vec![1, 2, 3];
}
也可以使用 vec! 宏来构造两个整数的 vector 或五个字符串 slice 的 vector 。但却无法使用函数做相同的事情,因为我们无法预先知道参数值的数量和类型。src/lib.rs
#[macro_export]
macro_rules! vec {($( $x: expr), *) => {let mut temp = Vec::new();&(temp.push($x);)*temp};
}
注意:标准库中实际定义的
vec!包括预分配适当量的内存的代码。这部分为代码优化,为了让示例简化,此处并没有包含在内。
无论何时导入定义了宏的包,#[macro_export] 注解说明宏应该是可用的。 如果没有该注解,这个宏不能被引入作用域。
接着使用 macro_rules! 和宏名称开始宏定义,且所定义的宏并 不带 感叹号。名字后跟大括号表示宏定义体,在该例中宏名称是 vec 。
vec! 宏的结构和 match 表达式的结构类似。此处有一个单边模式 ( $( $x:expr ),* ) ,后跟 => 以及和模式相关的代码块。如果模式匹配,该相关代码块将被执行。假设这是这个宏中唯一的模式,则只有这一种有效匹配,其他任何匹配都是错误的。更复杂的宏会有多个单边模式。
宏定义中有效模式语法和在第十八章提及的模式语法是不同的,因为宏模式所匹配的是 Rust 代码结构而不是值。回过头来检查下上述示例中模式片段什么意思。对于全部的宏模式语法,请查阅参考。
首先,一对括号包含了全部模式。接下来是后跟一对括号的美元符号( $ ),其通过替代代码捕获了符合括号内模式的值。$() 内则是 $x:expr ,其匹配 Rust 的任意表达式或给定 $x 名字的表达式。
$() 之后的逗号说明一个逗号分隔符可以有选择的出现代码之后,这段代码与在 $() 中所捕获的代码相匹配。紧随逗号之后的 * 说明该模式匹配零个或多个 * 之前的任何模式。
当以 vec![1, 2, 3]; 调用宏时,$x 模式与三个表达式 1、2 和 3 进行了三次匹配。
现在让我们来看看这个出现在与此单边模式相关的代码块中的模式:在 $()* 部分中所生成的 temp_vec.push() 为在匹配到模式中的 $() 每一部分而生成。$x 由每个与之相匹配的表达式所替换。当以 vec![1, 2, 3]; 调用该宏时,替换该宏调用所生成的代码会是下面这样:
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
我们已经定义了一个宏,其可以接收任意数量和类型的参数,同时可以生成能够创建包含指定元素的 vector 的代码。
macro_rules! 中有一些奇怪的地方。在将来,会有第二种采用 macro 关键字的声明宏,其工作方式类似但修复了这些极端情况。在此之后,macro_rules! 实际上就过时(deprecated)了。在此基础之上,同时鉴于大多数 Rust 程序员 使用 宏而非 编写 宏的事实,此处不再深入探讨 macro_rules!。请查阅在线文档或其他资源,如 “The Little Book of Rust Macros” 来更多地了解如何写宏。
用于从属性生成代码的过程宏
第二种形式的宏被称为 过程宏(procedural macros),因为它们更像函数(一种过程类型)。过程宏接收 Rust 代码作为输入,在这些代码上进行操作,然后产生另一些代码作为输出,而非像声明式宏那样匹配对应模式然后以另一部分代码替换当前代码。
有三种类型的过程宏(自定义 derive,类属性和类函数),不过它们的工作方式都类似。
当创建过程宏时,其定义必须位于一种特殊类型的属于它们自己的 crate 中。这么做出于复杂的技术原因,将来我们希望能够消除这些限制。使用这些宏需采用类似下面示例所示的代码形式,其中 some_attribute 是一个使用特定宏的占位符。src/lib.rs
use proc_macro;#[some_attribute]
pub fn some_name(input: TokenStream) -> TokenStream {
}
过程宏包含一个函数,这也是其得名的原因:“过程” 是 “函数” 的同义词。那么为何不叫 “函数宏” 呢?好吧,有一个过程宏是 “类函数” 的,叫成函数会产生混乱。无论如何,定义过程宏的函数接受一个 TokenStream 作为输入并产生一个 TokenStream 作为输出。这也就是宏的核心:宏所处理的源代码组成了输入 TokenStream,同时宏生成的代码是输出 TokenStream。最后,函数上有一个属性;这个属性表明过程宏的类型。在同一 crate 中可以有多种的过程宏。
考虑到这些宏是如此类似,我们会从自定义派生宏开始。接着会解释与其他形式宏的微小区别。
如何编写自定义derive宏
让我们创建一个 hello_macro crate,其包含名为 HelloMacro 的 trait 和关联函数 hello_macro。不同于让 crate 的用户为其每一个类型实现 HelloMacro trait,我们将会提供一个过程式宏以便用户可以使用 #[derive(HelloMacro)] 注解他们的类型来得到 hello_macro 函数的默认实现。该默认实现会打印 Hello, Macro! My name is TypeName!,其中 TypeName 为定义了 trait 的类型名。src/main.rs
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;#[derive(HelloMacro)]
struct Pancakes;fn main() {Pancakes::hello_macro();
}
运行该代码将会打印 Hello, Macro! My name is Pancakes! 第一步是像下面这样新建一个库 crate:
$ cargo new hello_macro --lib
接下来,会定义 HelloMacro trait 以及其关联函数:
pub trait HelloMacro {fn hello_macro();
}
现在有了一个包含函数的 trait 。此时,crate 用户可以实现该 trait 以达到其期望的功能,像这样:
use hello_macro::HelloMacro;struct Pancakes;impl HelloMacro for Pancakes {fn hello_macro() {println!("Hello, Macro! My name is Pancakes!");}
}fn main() {Pancakes::hello_macro();
}
然而,他们需要为每一个他们想使用 hello_macro 的类型编写实现的代码块。我们希望为其节约这些工作。
另外,我们也无法为 hello_macro 函数提供一个能够打印实现了该 trait 的类型的名字的默认实现:Rust 没有反射的能力,因此其无法在运行时获取类型名。我们需要一个在运行时生成代码的宏。
下一步是定义过程式宏。在编写本部分时,过程式宏必须在其自己的 crate 内。该限制最终可能被取消。构造 crate 和其中宏的惯例如下:对于一个 foo 的包来说,一个自定义的派生过程宏的包被称为 foo_derive 。在 hello_macro 项目中新建名为 hello_macro_derive 的包。
$ cargo new hello_macro_derive --lib
由于两个 crate 紧密相关,因此在 hello_macro 包的目录下创建过程式宏的 crate。如果改变在 hello_macro 中定义的 trait ,同时也必须改变在 hello_macro_derive 中实现的过程式宏。这两个包需要分别发布,编程人员如果使用这些包,则需要同时添加这两个依赖并将其引入作用域。我们也可以只用 hello_macro 包而将 hello_macro_derive 作为一个依赖,并重新导出过程式宏的代码。但我们组织项目的方式使编程人员使用 hello_macro 成为可能,即使他们无需 derive 的功能。
需要将 hello_macro_derive 声明为一个过程宏的 crate。同时也需要 syn 和 quote crate 中的功能,正如注释中所说,需要将其加到依赖中。为 hello_macro_derive 将下面的代码加入到 Cargo.toml 文件中。
[lib]
proc-macro = true[dependencies]
syn = "0.14.4"
quote = "0.6.3"
为定义一个过程式宏,请将下面示例中的代码放在 hello_macro_derive crate 的 src/lib.rs 文件里面。注意这段代码在我们添加 impl_hello_macro 函数的定义之前是无法编译的。
extern crate proc_macro;use crate::proc_macro::TokenStream;
use quote::quote;
use syn;#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {// 构建 Rust 代码所代表的语法树// 以便可以进行操作let ast = syn::parse(input).unwrap();// 构建 trait 实现impl_hello_macro(&ast)
}注意 hello_macro_derive 函数中代码分割的方式,它负责解析 TokenStream,而 impl_hello_macro 函数则负责转换语法树:这让编写一个过程式宏更加方便。外部函数中的代码(在这里是 hello_macro_derive)几乎在所有你能看到或创建的过程宏 crate 中都一样。内部函数(在这里是 impl_hello_macro)的函数体中所指定的代码则依过程宏的目的而各有不同。
现在,我们已经引入了三个新的 crate:proc_macro 、 syn 和 quote 。Rust 自带 proc_macro crate,因此无需将其加到 Cargo.toml 文件的依赖中。proc_macro crate 是编译器用来读取和操作我们 Rust 代码的 API。
syn crate 将字符串中的 Rust 代码解析成为一个可以操作的数据结构。quote 则将 syn 解析的数据结构反过来传入到 Rust 代码中。这些 crate 让解析任何我们所要处理的 Rust 代码变得更简单:为 Rust 编写整个的解析器并不是一件简单的工作。
当用户在一个类型上指定 #[derive(HelloMacro)] 时,hello_macro_derive 函数将会被调用。原因在于我们已经使用 proc_macro_derive 及其指定名称对 hello_macro_derive 函数进行了注解:HelloMacro ,其匹配到 trait 名,这是大多数过程宏遵循的习惯。
该函数首先将来自 TokenStream 的 input 转换为一个我们可以解释和操作的数据结构。这正是 syn 派上用场的地方。syn 中的 parse_derive_input 函数获取一个 TokenStream 并返回一个表示解析出 Rust 代码的 DeriveInput 结构体。
DeriveInput {// --snip--ident: Ident {ident: "Pancakes",span: #0 bytes(95..103)},data: Struct(DataStruct {struct_token: Struct,fields: Unit,semi_token: Some(Semi)})
}该结构体的字段展示了我们解析的 Rust 代码是一个类单元结构体,其 ident( identifier,表示名字)为 Pancakes。该结构体里面有更多字段描述了所有类型的 Rust 代码,查阅 syn 中 DeriveInput 的文档 以获取更多信息。
此时,尚未定义 impl_hello_macro 函数,其用于构建所要包含在内的 Rust 新代码。但在此之前,注意其输出也是 TokenStream。所返回的 TokenStream 会被加到我们的 crate 用户所写的代码中,因此,当用户编译他们的 crate 时,他们会获取到我们所提供的额外功能。
你可能也注意到了,当调用 parse_derive_input 或 parse 失败时。在错误时 panic 对过程宏来说是必须的,因为 proc_macro_derive 函数必须返回 TokenStream 而不是 Result,以此来符合过程宏的 API。这里选择用 unwrap 来简化了这个例子;在生产代码中,则应该通过 panic! 或 expect 来提供关于发生何种错误的更加明确的错误信息。
现在我们有了将注解的 Rust 代码从 TokenStream 转换为 DeriveInput 实例的代码,让我们来创建在注解类型上实现 HelloMacro trait 的代码。/lib.rs
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {let name = &ast.ident;let gen = quote! {impl HelloMacro for #name {fn hello_macro() {println!("Hello, Macro! My name is {}", stringify!(#name));}}};gen.into()
}
我们得到一个包含以 ast.ident 作为注解类型名字(标识符)的 Ident 结构体实例。示例 中的结构体表明当 impl_hello_macro 函数运行于示例中的代码上时 ident 字段的值是 "Pancakes"。因此,示例中 name 变量会包含一个 Ident 结构体的实例,当打印时,会是字符串 "Pancakes",也就是示例中结构体的名称。
quote! 宏让我们可以编写希望返回的 Rust 代码。quote! 宏执行的直接结果并不是编译器所期望的并需要转换为 TokenStream。为此需要调用 into 方法,它会消费这个中间表示(intermediate representation,IR)并返回所需的 TokenStream 类型值。
这个宏也提供了一些非常酷的模板机制;我们可以写 #name ,然后 quote! 会以名为 name 的变量值来替换它。你甚至可以做一些类似常用宏那样的重复代码的工作。查阅 quote crate 的文档 来获取详尽的介绍。
我们期望我们的过程式宏能够为通过 #name 获取到的用户注解类型生成 HelloMacro trait 的实现。该 trait 的实现有一个函数 hello_macro ,其函数体包括了我们期望提供的功能:打印 Hello, Macro! My name is 和注解的类型名。
此处所使用的 stringify! 为 Rust 内置宏。其接收一个 Rust 表达式,如 1 + 2 , 然后在编译时将表达式转换为一个字符串常量,如 "1 + 2" 。这与 format! 或 println! 是不同的,它计算表达式并将结果转换为 String 。有一种可能的情况是,所输入的 #name 可能是一个需要打印的表达式,因此我们用 stringify! 。 stringify! 编译时也保留了一份将 #name 转换为字符串之后的内存分配。
此时,cargo build 应该都能成功编译 hello_macro 和 hello_macro_derive 。我们将这些 crate 连接到示例的代码中来看看过程宏的行为!在 projects 目录下用 cargo new pancakes 命令新建一个二进制项目。需要将 hello_macro 和 hello_macro_derive 作为依赖加到 pancakes 包的 Cargo.toml 文件中去。如果你正将 hello_macro 和 hello_macro_derive 的版本发布到 crates.io 上,其应为正规依赖;如果不是,则可以像下面这样将其指定为 path 依赖:
[dependencies]
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
然后执行 cargo run:其应该打印 Hello, Macro! My name is Pancakes!。其包含了该过程宏中 HelloMacro trait 的实现,而无需 pancakes crate 实现它;#[derive(HelloMacro)] 增加了该 trait 实现。
类属性宏
类属性宏与自定义派生宏相似,不同于为 derive 属性生成代码,它们允许你创建新的属性。它们也更为灵活;derive 只能用于结构体和枚举;属性还可以用于其它的项,比如函数。作为一个使用类属性宏的例子,可以创建一个名为 route 的属性用于注解 web 应用程序框架(web application framework)的函数:
#[route(GET, "/")]
fn index() {
#[route] 属性将由框架本身定义为一个过程宏。其宏定义的函数签名看起来像这样:
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {
这里有两个 TokenStream 类型的参数;第一个用于属性内容本身,也就是 GET, "/" 部分。第二个是属性所标记的项,在本例中,是 fn index() {} 和剩下的函数体。
除此之外,类属性宏与自定义派生宏工作方式一致:创建 proc-macro crate 类型的 crate 并实现希望生成代码的函数!
类函数宏
类函数宏定义看起来像函数调用的宏。类似于 macro_rules!,它们比函数更灵活;例如,可以接受未知数量的参数。然而 macro_rules! 宏只能使用之前 “使用 macro_rules! 的声明宏用于通用元编程” 介绍的类匹配的语法定义。类函数宏获取 TokenStream 参数,其定义使用 Rust 代码操纵 TokenStream,就像另两种过程宏一样。一个类函数宏例子是可以像这样被调用的 sql! 宏:
let sql = sql!(SELECT * FROM posts WHERE id=1);
这个宏会解析其中的 SQL 语句并检查其是否是句法正确的,这是比 macro_rules! 可以做到的更为复杂的处理。sql! 宏应该被定义为如此:
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {
这类似于自定义派生宏的签名:获取括号中的 token,并返回希望生成的代码。
参考:高级特征 - Rust 程序设计语言 简体中文版 (bootcss.com)