一、基于LangChain源码react来解析prompt engineering
在LangChain源码中一个特别重要的部分就是react,它的基本概念是,LLM在推理时会产生很多中间步骤而不是直接产生结果,这些中间步骤可以被用来与外界进行交互,然后产生new context:
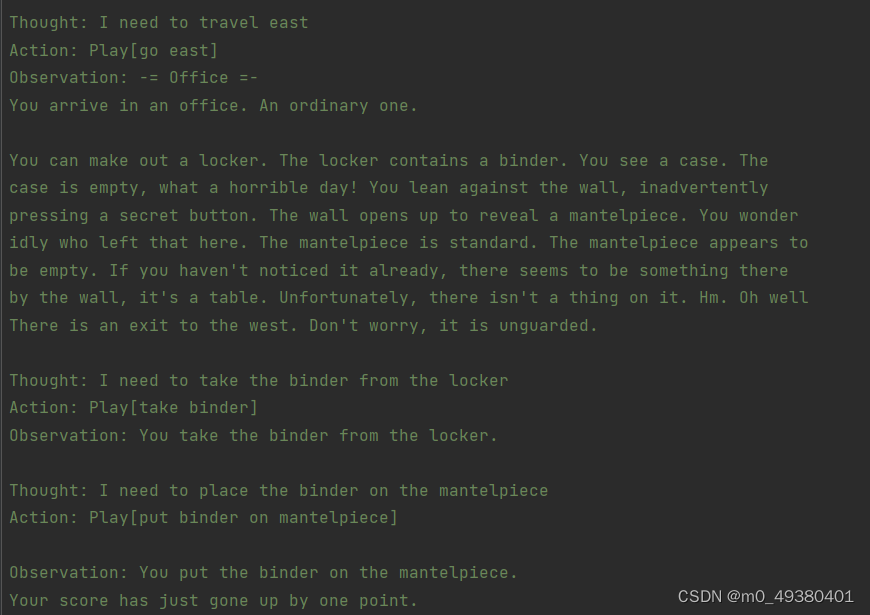
我们先看下textworld_prompt这个文件,按照前面提到的“thought”,“action”,“observation”的结构给出了如下样例,其中observation部分以文字的形式提供了一种类似于解题的思路来说明如何完成具体的action:
另外看一下wiki_prompt这个文件,在所给的例子中,首先也是给出一个question,然后针对问题给出thought,也就是如何进行推理:
Question: What is the elevation range for the area that the eastern sector of the Colorado orogeny extends into?
Thought: I need to search Colorado orogeny, find the area that the eastern sector of the Colorado orogeny extends into, then find the elevation range of the area.
Action: Search[Colorado orogeny]
在这里,执行action的不是LLM,而是agent,执行wiki搜索之后返回结果:
Observation: The Colorado orogeny was an episode of mountain building (an orogeny) in Colorado and surrounding areas.
Thought: It does not mention the eastern sector. So I need to look up eastern sector.
Action: Lookup[eastern sector]
从上面的返回结果看,并没有提到关键信息“eastern sector”,因此上面的thought提示需要查找这部分信息:
Observation: (Result 1 / 1) The eastern sector extends into the High Plains and is called the Central Plains orogeny.
Thought: The eastern sector of Colorado orogeny extends into the High Plains. So I need to search High Plains and find its elevation range.
Action: Search[High Plains]
根据上面查询“eastern sector”的结果,接下来需要搜索关于“High Plains”的信息:
Observation: High Plains refers to one of two distinct land regions
Thought: I need to instead search High Plains (United States).
Action: Search[High Plains (United States)]
由于上面的搜索结果提到了“two distinct land regions”,所以接下来的步骤就是搜索关于“High Plains (United States)”的信息:
Observation: The High Plains are a subregion of the Great Plains. From east to west, the High Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130 m).[3]
Thought: High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer is 1,800 to 7,000 ft.
Action: Finish[1,800 to 7,000 ft]
基于上面的搜索结果进行推理,最后获得了我们想要的数据:1,800 to 7,000 ft。
上面重复迭代多次的observation+thought+action就构成了一个链式的过程。
二、结合Chain of Thought(COT)经典案例剖析prompt
接下来我们针对这样一个链式的过程,来看一个应用案例。在这个例子中,我们使用了OpenAI的API来调用GPT-3.5模型,并没有使用LangChain的方式:
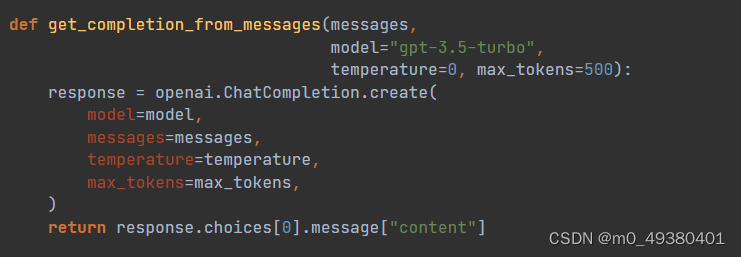
我们来看下关于“Chain-of-Thought Prompting”是如何进行构造的,这个prompt是跟客户查询有关的,定义了多个步骤来回答客户的问题:
Step 1是检查用户的问题是否针对一个具体的产品或者一组产品来说的
Step 2是检查用户问题涉及到的产品是否是以下列出的这些产品,这里可能是为了演示的方便,所以直接以文本的形式呈现出来,当然这些产品信息可以存储在数据库里

Step 3判断如果用户问题涉及以上产品,那么列出用户针对产品会提什么问题的任意假设:

Step 4基于现有的产品信息来判断用户提出的问题是否有匹配的答案:

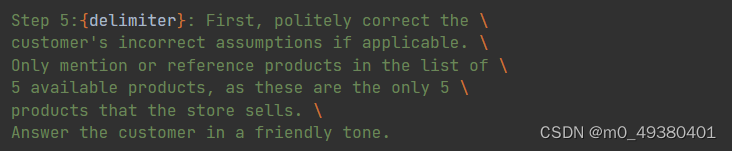
Step 5提示应该以对用户友好的方式来修正用户提到的不正确的问题假设,也就是说用户只能针对5个可用的产品来提相关问题:
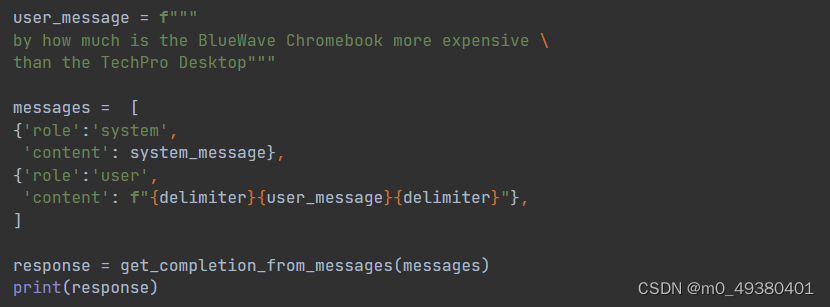
以上部分都可以看做是基本的上下文信息(system message),接下来设定user_message的内容,调用方法get_completion_from_messages获得结果:
打印的结果如下,由于用户问题提到了具体产品和价格,所以step 2给出了每一种产品的价格,并对用户的假设进行了判断:

设定用户的问题如下:
do you sell tvs
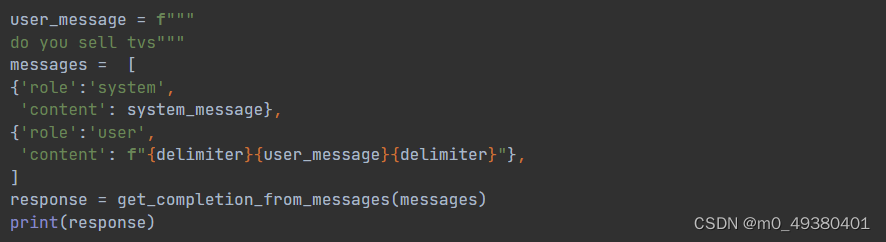
这次给出的结果如下,推理步骤1和2共同判断了用户提到的TVs不在当前可用产品列表中,所以模型在运行时会按照之前的系统设定来给出恰当的回复给用户:
Step 1:#### The user is asking about a specific product category, TVs.
Step 2:#### The list of available products does not include any TVs.
Response to user:#### I'm sorry, but we do not sell TVs at this time. Our store specializes in computers and laptops. However, if you are interested in purchasing a computer or laptop, please let me know and I would be happy to assist you.
这个例子看上去不复杂,但是它的意义重大,因为上面所列的系统信息都是私有数据,如果已经告诉模型只能从私有数据中去查询,那么模型就不会从其它地方去获取数据,譬如针对上面step 2所列的信息,可以修改为从数据库或者vector store中进行查询(也就是使用具体的工具),如果使用LangChain,那么它可以帮我们封装这个过程,如果不使用LangChain,那么可以自己来封装。
If the user is asking about \
specific products, identify whether \
the products are in the following list.
接下来设定用户信息如下:
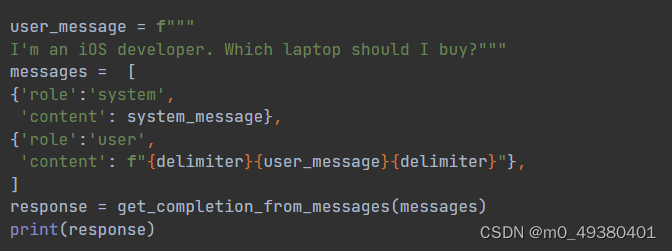
推理过程如下,step1 是针对用户问题的理解,因此step 2列出了当前可用的产品信息,由于用户问题中并没有给出明确的假设,所以step 4的内容是基于LLM的理解给出的,然后与本地的私有数据进行匹配,之后基于这些信息来回复给用户,所以整个过程都是LLM来驱动的:
Step 1:#### The user is asking for a recommendation for a laptop based on their profession.
Step 2:#### The available laptops are:
1. TechPro Ultrabook
2. BlueWave Gaming Laptop
3. PowerLite Convertible
4. TechPro Desktop
5. BlueWave Chromebook
Step 3:#### There are no assumptions made by the user in this message.
Step 4:#### Based on the user's profession as an iOS developer, they would require a laptop with a powerful processor and sufficient RAM to handle development tasks. The TechPro Ultrabook and the BlueWave Gaming Laptop would be suitable options for an iOS developer due to their powerful processors and high RAM capacity.
Response to user:#### As an iOS developer, I would recommend either the TechPro Ultrabook or the BlueWave Gaming Laptop. Both laptops have powerful processors and high RAM capacity, which are essential for development tasks.
通过以上经典案例展示了用LLM来驱动一切,驱动的关键在于你自己的prompt要写得很清楚。