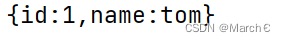数据提取之JSON与JsonPATH
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它是的人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
JSON和XML的比较可谓不相上下。
Python2.7中自带了JSON模块,直接import json就可以使用了。 官方博客:http://docs.python.org/library/json.html
Json在线解析网站:http://www.json.cn/#
JSON
json简单说就是javascript中的对象和数组,所以这两种结构就是对象和数据两种结构,通过这两种结构可以表示各种复杂的结构。
- 对象:对象在js中表示为{}括起来的内容,数据结构为{key:value,key:value,…}的键值对的结构,在面向对象的语言中,key为对象的属性,value为对应的属性值,所以很容易理解,取值方法为对象.key获取属性值,这个属性值的类型可以是数字、字符串、数组、对象这几种。
- 数组:数组在js中是中括号[]括起来的内容,数据结构为[“Python”, “javascript”, “C++”,…],取值方式和所有语言中一样,使用索引获取,字段值的类型可以是数字、字符串、数组、对象几种。
import json
json模块提供了四个功能:dumps、dump、loads、load,用于字符串和python数据类型键进行转换。
1、json.loads()
把json格式字符串解码转换成Python对象从json到Python的类型转化对照如下:
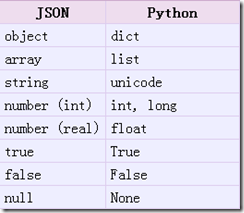
从json到python的转化关系
#json_loads.pyimport jsonstrList = '[1, 2, 3, 4]'strDict = '{"city":"北京", "name":"大猫"}'json.loads(strList)
for str in strList:print(str)
#[1, 2, 3, 4]json.loads(strDict) #json数据自动按Unicode存储
#{u'city': u'\u5317\u4eac', u'name': u'\u5927\u732b'}
2、json.dumps()
实现python类型转化为json字符串,返回一个str对象。把一个Python对象编码转换成Json字符串,从python原始类型向json类型转化对照表如下:
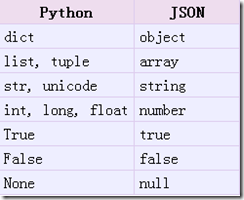
python向json转化
#json_dumps.py#-*- coding:utf-8 -*-import json
import chardetlistStr = [1, 2, 3, 4]
tupleStr = (1, 2, 3, 4)
dictStr = {"city":"北京", "name":"大猫"}print(type(json.dumps(listStr)))
# '[1, 2, 3, 4]'print(type(json.dumps(tupleStr)))
# '[1, 2, 3, 4]'#注意,json.dumps()序列化时默认使用ascii编码
#添加参数 ensure_ascii = False,禁用ascii编码,按utf-8编码
#chardet.detect()返回字典,其中confidence是检测精确度。print(json.dumps(dictStr))
#'{"city":"\\u5317\\u4eac", "name":"\\u5927\\u5218"}'print(chardet.detect(json.dumps(dictStr)))print(json.dumps(dictStr, ensure_ascii=False))print(chardet.detect(json.dumps(dictStr, ensure_ascii=False)))
chardet是一个非常优秀的编码识别模块,可通过pip安装
3. json.dump()
将Python内置类型序列化为json对象后写入文件
#json_dump.pyimport jsonlistStr = [{"city":"北京"}, {"name":"大刘"}]json.dump(listStr, open("listStr.json", "w"), ensure_ascii=False)dictStr = {"city":"北京", "name":"大刘"}
json.dump(dictStr.open("dictStr.json", "w"), ensure_ascii=False)
4.json.load()
读取文件中json形式的字符串元素转化成python类型
#-*- coding:utf-8 -*-import jsonstrList = json.load(open("listStr.json"))
print strList
# [{u'city': u'\u5317\u4eac'}, {u'name': u'\u5927\u5218'}]strDict = json.load(open("dictStr.json"))
print strDict
# {u'city': u'\u5317\u4eac', u'name': u'\u5927\u5218'}
JsonPath
JsonPath是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种原因实现保本:JavaScript/Python/PHP和Java
JsonPath对于JSON来说,相当于XPATH对于XML
下载地址:https://pypi.python.org/pypi/jsonpath 安装方法:点击Download URL链接下载jsonpath,解压之后执行python setup.py install 官方文档:http://goessner.net/articles/JsonPath
JsonPath与XPath语法对比:
Json结构清晰,可读性高,复杂度低,非常容易匹配,下表中对应了XPath的用法。
| Xpath | JSONPath | 描述 |
|---|---|---|
| / | $ | 跟节点 |
| . | @ | 现行节点 |
| / | . or [] | 取子节点 |
| … | n/a | 就是不管位置,选择所有符合条件的条件 |
| * | * | 匹配所有元素节点 |
| [] | [] | 迭代器标示(可以在里面做简单的迭代操作,如数组下标,根据内容选值等) |
| | | [,] | 支持迭代器中做多选 |
| [] | ?() | 支持过滤操作 |
| n/a | () | 支持表达式计算 |
| () | n/a | 分组,JsonPath不支持 |
实例:
我们以拉勾网城市JSON文件http://www.lagou.com/lbs/getAllCitySearchLabels.json为例,获取所有城市。
#-*- coding:utf-8 -*-import urllib2
import json
import jsonpath
import chardeturl = "http://www.lagou.com/lbs/getAllCitySearchLabels.json"
request = urllib2.Request(url)response = urllib2.urlopen(request)html = response.read()#把json格式字符串转换成python对象
jsonobj = json.loads(html)#从根节点开始,匹配name节点
citylist = jsonpath.jsonpath(jsonobj, '$..name')print citylist
print(type(citylist))fp = open('city.json', 'w')content = json.dumps(citylist, ensure_ascii=False)
print content
fp.write(content.encode('utf-8'))fp.close()
注意事项:
json.loads()是把Json格式字符串解码转换成Python对象,如果在json.loads的时候出错,要注意被解码的Json字符的编码。
如果传入的字符串的编码不是UTF-8的话,需要制定字符编码的参数:encoding
dataDict = json.loads(jsonStrGBK);
- dataJsonStr是JSON字符串,假设其编码本身是非UTF-8的话而是GBK的,那么上述代码会导致出错,改为对应的。
dataDict = json.loads(jsonStrGBK, encoding="GBK")
- 如果dataJsonStr通过encoding指定了合适的编码,但是其中又包含了其它编码的字符,则需要先去将dataJsonStr转换为Unicode,然后再指定编码格式调用json.loads()
dataJsonStrUni = data.JsonStr.decode("GB2312")
dataDict = json.loads(dataJsontrUni, encoding="GB2312")
字符串编码转换
这是程序员最苦逼的地方,什么乱码之类的几乎都是由汉字引起的。 其实编码问题很好搞定,只要记住一点:
任何平台的任何编码,都能和Unicode互相转换。
UTF-8与GBK互相转换,那就先把UTF-8转换成Unicode,再从Unicode转换成GBK,反之同理。
# 这是一个 UTF-8 编码的字符串
utf8Str = "你好地球"# 1. 将 UTF-8 编码的字符串 转换成 Unicode 编码
unicodeStr = utf8Str.decode("UTF-8")# 2. 再将 Unicode 编码格式字符串 转换成 GBK 编码
gbkData = unicodeStr.encode("GBK")# 1. 再将 GBK 编码格式字符串 转化成 Unicode
unicodeStr = gbkData.decode("gbk")# 2. 再将 Unicode 编码格式字符串转换成 UTF-8
utf8Str = unicodeStr.encode("UTF-8")
decode的作用是将其它编码的字符串转换成Unicode编码 encode的作用是将Unicode编码转换成其他编码的字符串 一句话:**UTF-8**是对Unicode字符集记性编码的一种编码格式
更多Python的学习资料可以扫描下方二维码无偿领取!!!

1)Python所有方向的学习路线(新版)
总结的Python爬虫和数据分析等各个方向应该学习的技术栈。

比如说爬虫这一块,很多人以为学了xpath和PyQuery等几个解析库之后就精通的python爬虫,其实路还有很长,比如说移动端爬虫和JS逆向等等。
(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然达不到大佬的程度,但是精通python是没有问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

。