地球科学家需要对地质环境进行最佳估计才能进行模拟或评估。 除了地质背景之外,建立地质模型还需要一整套数学方法,如贝叶斯网络、协同克里金法、支持向量机、神经网络、随机模型,以在钻井日志或地球物理信息确实稀缺或不确定时定义哪些可能是岩石类型/属性。

推荐:用 NSDT编辑器 快速搭建可编程3D场景
我们已经用 Python 和最新强大的库(Scikit Learn)完成了一个教程,以根据宝藏谷(美国爱达荷州)钻探的岩性创建地质模型。 本教程生成钻井岩性的点云,并针对神经网络进行转换和缩放。 所选的神经网络分类器是多层感知器分类器,在 Scikit Learn 库上实现为 sklearn.neural_network.MLPClassifier。 对神经网络的混淆进行分析。 本教程还包括 Paraview 中 Vtk 格式的井岩性和插值地质学的地理参考 3D 可视化。
首先导入必要的库:
#import required libraries
%matplotlib inline
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import pyvista as pv
import vtk
1、井位置和岩性
数据来自来自公开发表论文,选定的单位为:
- 粗粒河流和冲积矿床
- 上新世-更新世和中新世玄武岩
- 细粒湖相沉积
- 流纹岩和花岗岩基岩
wellLoc = pd.read_csv('../inputData/TV-HFM_Wells_1Location_Wgs11N.csv',index_col=0)
wellLoc.head()
| 东向 | 北向 | 高度ft | 东向UTM | 北向UTM | 高程m | |
|---|---|---|---|---|---|---|
| A. Isaac | 2333140.95 | 1372225.65 | 3204.0 | 575546.628834 | 4.820355e+06 | 976.57920 |
| A. Woodbridge | 2321747.00 | 1360096.95 | 2967.2 | 564600.366582 | 4.807827e+06 | 904.40256 |
| A.D. Watkins | 2315440.16 | 1342141.86 | 3168.3 | 558944.843404 | 4.789664e+06 | 965.69784 |
| A.L. Clark; 1 | 2276526.30 | 1364860.74 | 2279.1 | 519259.006159 | 4.810959e+06 | 694.66968 |
| A.L. Clark; 2 | 2342620.87 | 1362980.46 | 3848.6 | 585351.150270 | 4.811460e+06 | 1173.05328 |
2、岩性点云
litoPoints = []for index, values in wellLito.iterrows():wellX, wellY, wellZ = wellLoc.loc[values.Bore][["EastingUTM","NorthingUTM","Elevation_m"]]wellXY = [wellX, wellY]litoPoints.append(wellXY + [values.topLitoElev_m,values.hydrogeoCode])litoPoints.append(wellXY + [values.botLitoElev_m,values.hydrogeoCode])litoLength = values.topLitoElev_m - values.botLitoElev_mif litoLength < 1:midPoint = wellXY + [values.topLitoElev_m - litoLength/2,values.hydrogeoCode]else:npoints = int(litoLength)for point in range(1,npoints+1):disPoint = wellXY + [values.topLitoElev_m - litoLength*point/(npoints+1),values.hydrogeoCode]litoPoints.append(disPoint)
litoNp=np.array(litoPoints)
np.save('../outputData/litoNp',litoNp)
litoNp[:5]
array([[5.48261389e+05, 4.83802316e+06, 7.70442960e+02, 1.00000000e+00],[5.48261389e+05, 4.83802316e+06, 7.70138160e+02, 1.00000000e+00],[5.48261389e+05, 4.83802316e+06, 7.70138160e+02, 3.00000000e+00],[5.48261389e+05, 4.83802316e+06, 7.68614160e+02, 3.00000000e+00],[5.48261389e+05, 4.83802316e+06, 7.69376160e+02, 3.00000000e+00]])
3、坐标变换和神经网络分类器设置
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import confusion_matrix
from sklearn import preprocessing
litoX, litoY, litoZ = litoNp[:,0], litoNp[:,1], litoNp[:,2]
litoMean = litoNp[:,:3].mean(axis=0)
litoTrans = litoNp[:,:3]-litoMean
litoTrans[:5]#setting up scaler
scaler = preprocessing.StandardScaler().fit(litoTrans)
litoScale = scaler.transform(litoTrans)#check scaler
print(litoScale.mean(axis=0))
print(litoScale.std(axis=0))
[ 2.85924590e-14 -1.10313442e-15 3.89483608e-20]
[1. 1. 1.]
#run classifier
X = litoScale
Y = litoNp[:,3]
clf = MLPClassifier(activation='tanh',solver='lbfgs',hidden_layer_sizes=(15,15,15), max_iter=2000)
clf.fit(X,Y)
C:\Users\Gida\Anaconda3\lib\site-packages\sklearn\neural_network\_multilayer_perceptron.py:470: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.Increase the number of iterations (max_iter) or scale the data as shown in:https://scikit-learn.org/stable/modules/preprocessing.htmlself.n_iter_ = _check_optimize_result("lbfgs", opt_res, self.max_iter)MLPClassifier(activation='tanh', alpha=0.0001, batch_size='auto', beta_1=0.9,beta_2=0.999, early_stopping=False, epsilon=1e-08,hidden_layer_sizes=(15, 15, 15), learning_rate='constant',learning_rate_init=0.001, max_fun=15000, max_iter=2000,momentum=0.9, n_iter_no_change=10, nesterovs_momentum=True,power_t=0.5, random_state=None, shuffle=True, solver='lbfgs',tol=0.0001, validation_fraction=0.1, verbose=False,warm_start=False)
4、混淆矩阵的确定
numberSamples = litoNp.shape[0]
expected=litoNp[:,3]
predicted = []
for i in range(numberSamples):predicted.append(clf.predict([litoScale[i]]))
results = confusion_matrix(expected,predicted)
print(results)
输出如下:
[[1370 128 377 0][ 67 2176 10 0][ 274 33 1114 0][ 1 0 0 151]]
5、研究领域和输出网格细化
xMin = 540000
xMax = 560000
yMin = 4820000
yMax = 4840000
zMax = int(wellLito.topLitoElev_m.max())
zMin = zMax - 300
cellH = 200
cellV = 20
6、岩性基质的测定
vertexCols = np.arange(xMin,xMax+1,cellH)
vertexRows = np.arange(yMax,yMin-1,-cellH)
vertexLays = np.arange(zMax,zMin-1,-cellV)
cellCols = (vertexCols[1:]+vertexCols[:-1])/2
cellRows = (vertexRows[1:]+vertexRows[:-1])/2
cellLays = (vertexLays[1:]+vertexLays[:-1])/2
nCols = cellCols.shape[0]
nRows = cellCols.shape[0]
nLays = cellLays.shape[0]
i=0
litoMatrix=np.zeros([nLays,nRows,nCols])
for lay in range(nLays):for row in range(nRows):for col in range(nCols):cellXYZ = [cellCols[col],cellRows[row],cellLays[lay]]cellTrans = cellXYZ - litoMeancellNorm = scaler.transform([cellTrans])litoMatrix[lay,row,col] = clf.predict(cellNorm)if i%30000==0:print("Processing %s cells"%i)print(cellTrans)print(cellNorm)print(litoMatrix[lay,row,col])i+=1
Processing 0 cells
[-8553.96427073 8028.26104284 356.7050941 ]
[[-1.41791371 2.42904321 1.11476509]]
3.0
Processing 30000 cells
[-8553.96427073 8028.26104284 296.7050941 ]
[[-1.41791371 2.42904321 0.92725472]]
3.0
Processing 60000 cells
[-8553.96427073 8028.26104284 236.7050941 ]
[[-1.41791371 2.42904321 0.73974434]]
3.0
Processing 90000 cells
[-8553.96427073 8028.26104284 176.7050941 ]
[[-1.41791371 2.42904321 0.55223397]]
2.0
Processing 120000 cells
[-8553.96427073 8028.26104284 116.7050941 ]
[[-1.41791371 2.42904321 0.3647236 ]]
2.0
plt.imshow(litoMatrix[0])
<matplotlib.image.AxesImage at 0x14fb8688860>
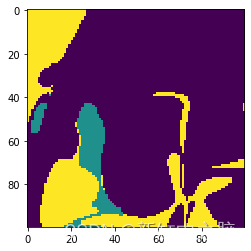
plt.imshow(litoMatrix[:,60])<matplotlib.image.AxesImage at 0x14fb871d390>

np.save('../outputData/litoMatrix',litoMatrix)#matrix modification for Vtk representation
litoMatrixMod = litoMatrix[:,:,::-1]
np.save('../outputData/litoMatrixMod',litoMatrixMod)
plt.imshow(litoMatrixMod[0])<matplotlib.image.AxesImage at 0x14fb87825f8>
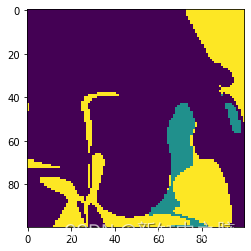
7、规则网格VTK的生成
import pyvista
import vtk# Create empty grid
grid = pyvista.RectilinearGrid()# Initialize from a vtk.vtkRectilinearGrid object
vtkgrid = vtk.vtkRectilinearGrid()
grid = pyvista.RectilinearGrid(vtkgrid)
grid = pyvista.RectilinearGrid(vertexCols,vertexRows,vertexLays)litoFlat = list(litoMatrixMod.flatten(order="K"))[::-1]
grid.cell_arrays["hydrogeoCode"] = np.array(litoFlat)
grid.save('../outputData/hydrogeologicalUnit.vtk')
8、输入数据
你可以从这个链接下载本教程的输入数据。
9、数据源
Bartolino, J.R.,2019,爱达荷州和俄勒冈州宝藏谷及周边地区的水文地质框架:美国地质调查局科学调查报告 2019-5138,第 31 页。 链接 。
Bartolino, J.R.,2020,爱达荷州和俄勒冈州宝藏谷及周边地区的水文地质框架:美国地质调查局数据发布。链接。
原文链接:3D地质神经网络模型 — BimAnt
![[Linux]命令行参数和进程优先级](https://img-blog.csdnimg.cn/img_convert/19270880a25074f42260e9062c83a050.png)