无论是 ChatGPT 还是 GPT-4,它们的核心技术机制之一都是基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)。这是大型语言模型生成领域的新训练范式,即以强化学习方式依据人类反馈优化语言模型。那么,什么是 RLHF 呢?
RLHF 背后的基本思想是采用预先训练好的语言模型,并让人们对其输出的结果进行排序。这个输出的排名作为一个信号,引导模型“更喜欢”某些结果,从而诱导响应,使其更安全可信。
RLHF 可以利用人工反馈优化语言模型。通过将RL算法与人工输入结合,帮助模型学习并提高其性能。结合人工反馈,RLHF 可以帮助语言模型更好地理解和生成自然语言,并提高它们执行特定任务的能力,如文本分类或语言翻译。此外,RLHF 还可以帮助缓解语言模型中的偏差问题,允许人类纠正并引导模型朝着更公平和包容性的语言使用方向发展。然而,另一方面,它也引入了一种途径,用于将人类偏见嵌入模型中。
1. 关于强化学习
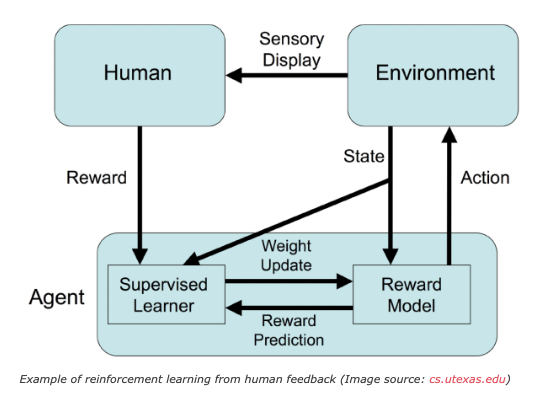
强化学习在数学方面有其基础知识,其中通过代理与环境进行交互,如下图所示:
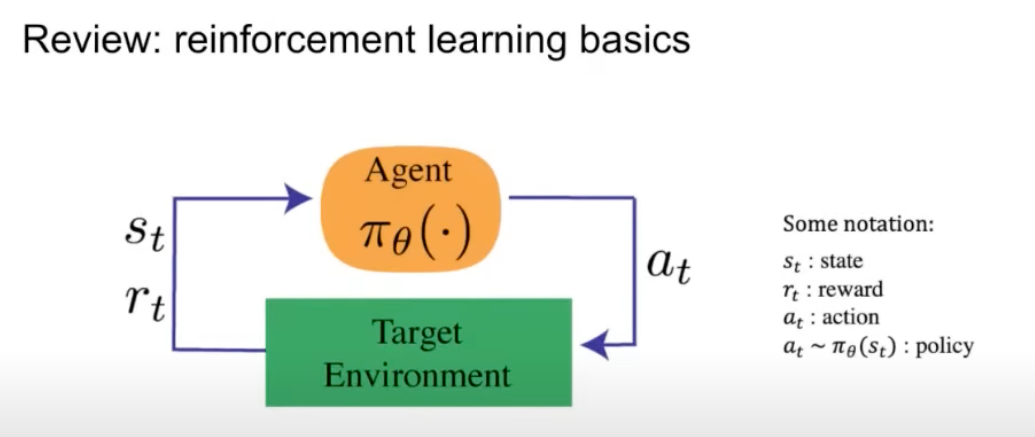
代理人通过采取一个行动与环境进行交互,环境返回一个状态和一个奖励。奖励就是我们想要优化的目标,状态是当前时间索引中环境/世界的表示,策略用于从该状态映射到操作。作为对代理执行的操作的回报,环境返回相应的奖励和下一个状态。
当利用大语音模型完成 NLP 任务时,如何为一个语言模型编码幽默、道德或者安全呢?这些都有一些人类自己能够理解的微妙之处,但是我们不能通过创建定制的损失函数来训练模型。这就是人类反馈强化学习的用武之地。
下图显示了 RLHF 模型如何从大模型和人工标注中获取输入,并创建一个比单独使用这两者更好的响应。

2. RLHF之模型训练
让我们先从一个高层次的 RLHF 开始,并首先收集所有的背景和事实。
RLHF 可能相当复杂,需要训练多个模型和不同的部署阶段。由于 GPT-4、 ChatGPT 和 DirectGPT 都用 RLHF (由 OpenAI 提供)进行了微调,因此让我们通过查看训练步骤来更深入地了解它。
RLHF 的设计是为了使模型更安全、更准确,并确保模型生成的输出文本是安全的,更符合用户的需要。人工智能代理首先在环境中随机作出决策。人工排名者会周期性地接收多个数据样本,甚至可能是模型的输出 ,根据人类偏好进行排名,例如,给定两个视频,人工排名者决定哪个视频更适合当前任务。
Agent将同时建立一个基于任务目标的模型,并通过使用 RL 对其进行细化。Agent将开始只需要人类对视频的反馈,并进一步完善其理解。
这种循环行为可以从 OpenAI 的下图中直观地看到:
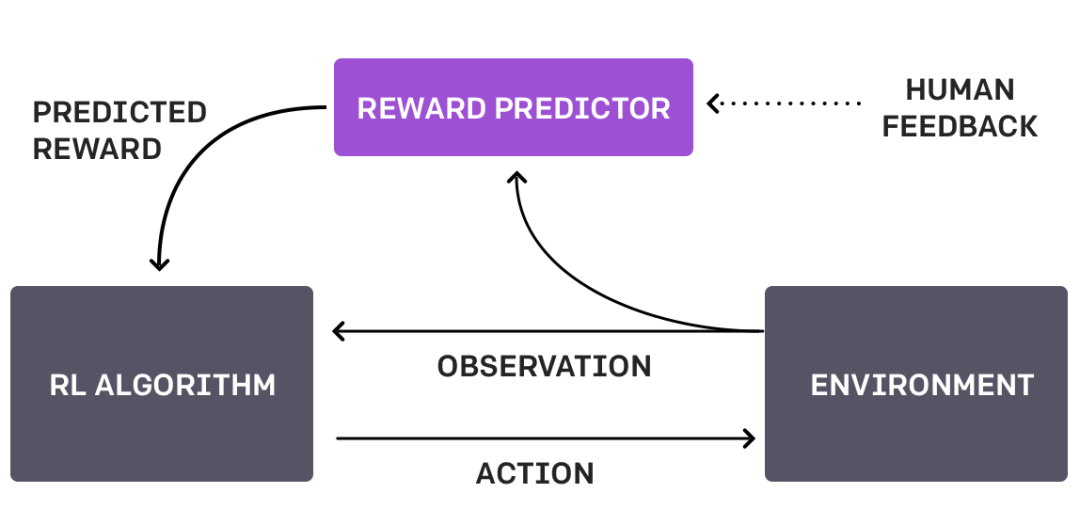
OpenAI 使用客户通过 ChatGPT API 向模型提交的提示,并通过手动对模型的几个期望输出排序来微调语言模型,从而获得人工反馈。这丰富了模型产出的质量,从而引导模型朝着信任和安全的方向发展。
这个过程被称为监督式学习,模型通过使用标记数据进行训练,以提高其准确性和性能。通过使用客户提示对模型进行微调,OpenAI 旨在使 ChatGPT在响应给定提示时更有效地生成相关且连贯的文本。
为什么我们不总是使用 RLHF呢?由于依赖人工标注,它的扩展性很差。手工标记数据既缓慢又昂贵,这就是为什么非监督式学习一直是机器学习研究人员长期追求的目标。
3. RLHF之预训练语言模型
大模型是使用不同参数的各种模型进行预训练的,并且可以针对特定任务进行微调。这又如何与 RLHF 相关呢?
生成数据以训练奖励模型是将人类偏好整合到系统中所必需的。然而,由于 RLHF 训练中各种选择的设计空间没有得到充分的探索,对于哪种模式最适合开始 RLHF 训练还没有明确的答案。下图像显示了预训练语言模型的内部工作原理以及用 RLHF 进一步进行微调的可选路径。
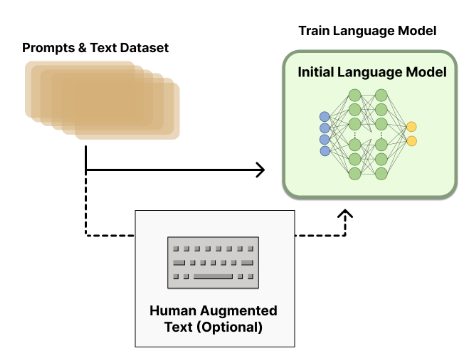
大模型的参数范围从100亿到2800亿不等,但目前还没有关于大模型最佳尺寸的答案。可以付钱让人撰写对现有提示的回应,然后这些数据可以用于训练,但会变得成本昂贵。
4. RLHF之训练奖励模型
RLHF 的最重要任务是生成一个奖励模型 (RM),它可以根据人的偏好为输入文本分配一个标量奖励。奖励模型可以是端到端的语言模型或模块化系统,并使用提示对数据集进行训练。下图展示了奖励模型是如何工作的:
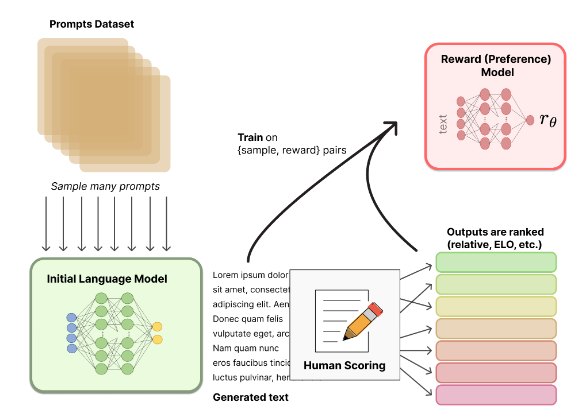
可以看到,目标是希望得到一个模型,它可以将某个输入文本序列映射到标量奖励值。众所周知,增强学习采用单个标量值,并通过其环境随着时间的推移对其进行优化。
奖励模型的训练也是从一个数据集开始的,但要注意它与用于大型模型预训练的数据集不同。这里的数据集侧重于特定的首选项,是一个提示输入数据集。它包含模型将用于的特定用例的提示,以及与提示示例相关联的预期奖励,例如 $(prompt, reward)$ pairs。数据集通常比预先训练的数据集小得多。因此,输出是文本示例的排名/奖励。
通常情况下,可以使用一个大型的“teacher”模型集合来减轻偏见,增加排名的多样性,或让人工对排名参与这些模型的循环。例如,当使用 ChatGPT 时,它有一个向上或向下的图标。这允许模型通过众包学习它的排名输出。
5. 用增强学习对大模型进行微调
下图解释了奖励模型微调的工作原理。
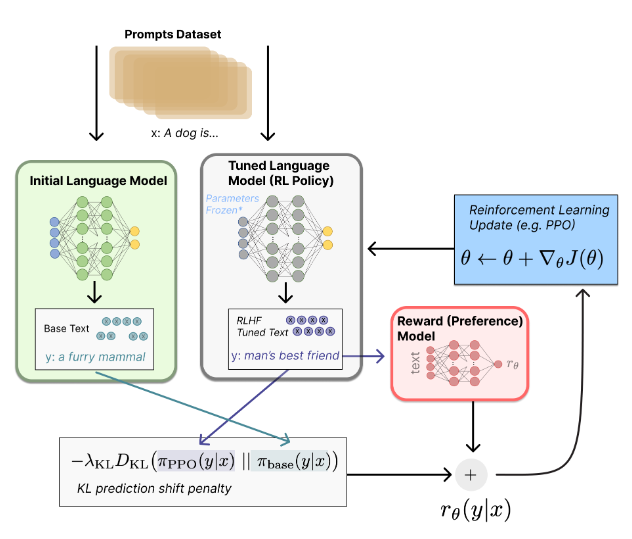
首先,获取提示数据集,即用户所说的内容或者我们希望模型能够很好生成的内容。然后,它被发送到增强学习的策略中,这是一个调优的语言模型,以根据提示生成适当的输出。随着初始大语言模型的输出,这被传递到生成标量奖励值的奖励模型中。
这是在一个反馈循环中完成的,基于它接受训练的人工标注,奖励模型可以分配奖励,在资源允许的情况下尽可能多地使用样本,因此,它会随着时间的推移而更新。
Kullback-Leibler(KL)是两个概率分布之间差异的度量,可以用来度量初始大模型输出与调优后的大模型输出。因此,使用 RLHF,KL 可以用来比较当前策略的概率分布和代表期望行为的参考分布。
此外,RLHF 可以对最近的政策优化微调。近似策略优化(PPO)是一种流行的强化学习算法,由于其能够在具有高维状态和行为空间的复杂环境中有效地优化策略,因此经常用于RLHF的微调过程中。PPO 有效地平衡了训练过程中的探索和开发,这对于必须从人类反馈和试错探索中学习的 RLHF Agent来说非常重要。在 RLHF 中使用 PPO 可以导致更快和更强大的学习,因为智能 Agent 能够从人类反馈和强化学习中学习。
在一定程度上,这个过程阻止了语言模型产生胡言乱语。换句话说,它驱使模型专注于高回报,从而最终导致它产生一个准确的文本结果。
6. RLHF之偏差考量及缓解策略
大型模型已经被部署在各种应用程序中,从搜索引擎(Bing Chat,Google’s Bard)到文本文档(Microsoft Office co-Pilot、Google Docs、Notion)等。那么,RLHF 能否给模型增加偏差呢?
答案是肯定的。就像任何有人工输入的机器学习方法一样,RLHF 有可能引入偏差。RLHF 可能引入不同形式的偏差如下:
选择偏差:RLHF 依赖于人类评估者的反馈,他们可能有自己的偏见和偏好,可以限制他们的反馈到他们可以涉及的主题或情况。因此,Agent 可能不会接触到它在现实世界中将会遇到的真实行为和结果的范围。
确认偏差:人类评估者可能更有可能提供反馈,确认他们现有的信念或期望,而不是提供客观的反馈。这可能导致代理因为某些行为或结果而得到加强,而这些行为或结果在长期来看可能不是最理想的结果。
评分者之间的差异:不同的人类评价者可能对 Agent 的响应质量有不同的意见或判断,从而导致 Agent 收到的反馈不一致。这可能使得有效训练 Agent 变得困难,并且可能导致性能不理想。
有限的反馈:人工评估者可能无法提供关于 Agent 所有方面的反馈,从而导致 Agent 的学习差距和在某些情况下潜在的次优结果。
针对RLHF可能存在的不同类型偏差,缓解策略如下:
选择不同的评估者:选择具有不同背景和观点的评估者可以帮助减少反馈中的偏见。可以通过招募来自不同人口群体、地区或行业的评估人员来实现。
共识评价:使用共识评价,即多个评价者就同一项任务提供反馈,有助于减少个别偏见的影响,并提高反馈的可靠性。这几乎就像是评估中的“规范化”。
校正评估者:通过向评价者提供关于如何提供反馈的培训和指导来校准评价者,可有助于提高反馈的质量和一致性。
评价反馈过程:定期评价反馈过程,包括反馈的质量和训练过程的有效性,可有助于查明和解决可能存在的偏差。
评估Agent的表现:定期评估Agent在各种任务和不同环境中的表现,可以帮助确保它不会过于适合特定的示例,并能够推广到新的情况。
平衡反馈:在人工评价者的反馈与其他反馈来源(如专家反馈)之间取得平衡,有助于减少反馈中偏差的影响,并提高训练数据的整体质量。
7. 强化学习与监督式学习中微调的对比
下图描述了强化学习与监督式学习中微调的主要区别:

既然增强学习需要人工反馈提供的标签,那为什么我们不只是把这些标签和监督式学习本身一起使用呢?
监督式学习的重点是缩小真实标签和模型输出之间的差距。在这里,它意味着模型只是记住等级,并可能产生胡言乱语的输出,因为它的重点是最大限度地提高它的等级。这就是 RL 中奖励模型所做的,是 KL 差异可以提供帮助的地方。在这种情况下,如果联合训练两个损失函数,一个用于排名,一个用于输出。那么,这个场景就只适用于问答任务,而不适用于 ChatGPT 或其他会话模型的每种会话模式。
GPT 使用交叉熵损失函数对下一个词进行预测。然而,RLHF 不使用标准损失函数,而是使用客观函数来帮助模型更好地服务于使用 RLHF 的任务,例如信任和安全。此外,因为否定一个词可以完全改变文本的意思,它在这里不是用武之地。根据经验,RLHF 的性能往往优于监督式学习。监督式学习使用标注级损失,例如可以在文本段落中求和或取平均值,而 RL 将整个文本段落作为一个整体来考虑。
最后,二者不是互斥的,可以首先使用 SL 进行微调,然后使用 RLHF 进行更新。
8. RHLF之潜在演进方向——RLAIF
Anthroic 的对话助手 Claude 采用了一种不同的方法来处理 RLHF,即从人工智能反馈 (RLAIF) 中创建 RLHF V2,并去掉了人工反馈。
RLAIF 利用人工智能系统协助监管其他人工智能的可能性,以及提高监管的可扩展性。通过减少回避式响应,减少有益和无害之间的紧张关系,并鼓励 AI 解释对有害请求的反对意见,从而改进对无害 AI 助手的训练,使控制人工智能行为的原则及其实现更加透明。通过消除在改变目标时收集新的人工反馈标签的需要,来减少迭代时间。
RLAIF 允许模型解释为什么它拒绝提供一个答案,这是基于它的思维链推理能力。这使我们能够洞察模型的推理过程。使用 RLAIF,不需要人工标签,它大大降低了成本和人力。它允许 LLM “反映”通过坚持一组原则或章程而产生的输出。人工智能将审查自己的响应,并确保他们遵守基本原则。
具体实现包括两个步骤:监督式学习阶段和 RLAIF 阶段,系统参考架构如下:
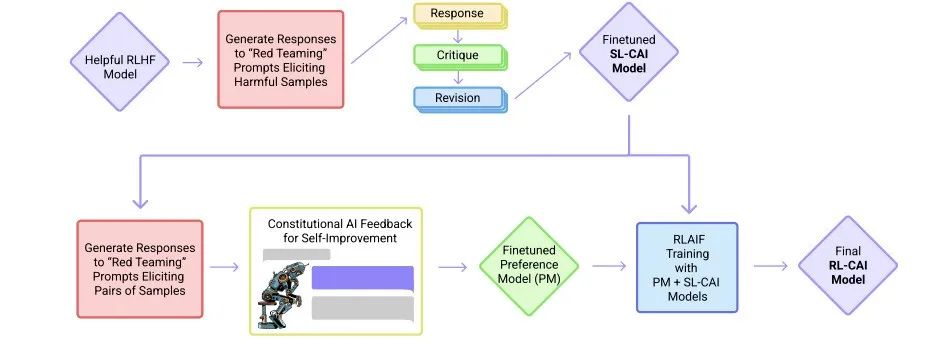
在监督式学习阶段,AI系统首先采用一套自我完善的规则,包括AI对各种大范围提示的答复,然后修订这些关于原型的初步答复。首先,检索预先训练LLM模型的响应,其中模型的响应可能包含有害元素。随后,要求模型使用一套既定的原则来评估自己的响应。然后,提示模型根据其提供的评估修改其响应。这两个步骤也称为“批评和修订”管道,将在n次迭代中重复执行。最后,使用由有害提示生成的修订响应的所有迭代对预先训练好的LLM进行微调。
此外,重要的是要包括一组有用的提示和它们各自的响应,以确保经过微调的模型仍然是有用的,也就是这个阶段的“监督”性质。这个修改后的模型被称为监督式学习AI宪章(SL-CAI)模型。
在强化学习阶段,需要AI系统探索对成千上万个提示的可能反应,并使用思维链推理来确定最符合宪章原则的行为。首先,利用前一阶段开发的SL-CAI模型为有害提示生成响应对。然后,引入一个反馈模型,它本质上是一个预训练的语言模型,用于评估一对反馈,并根据已建立的原则选择危害较小的反馈。反馈模型的归一化对数概率用于训练偏好模型或奖励模型。最后,使用这一奖励模型作为奖励函数,使用近似策略优化(PPO)训练SL-CAI模型。这就产生了最终的强化学习人工智能宪章(RL-CAI)模型。
9. 小结
RLHF的主要任务是生成奖励模型,通过人类偏好为输入文本分配标量奖励,并使用增强学习对大型语言模型进行微调。同时,RLHF可能会产生偏差,需要使用相应的缓解策略。通过强化学习和监督式学习中微调的对比,可以了解到二者结合使用的可能性,也就是RLHF的一个潜在发展方向——RLAIF。
【参考资料与关联阅读】
“Deep reinforcement learning from human preferences” by OpenAI (2017),https://arxiv.org/abs/1706.03741
Reinforcement Learning from Human Feedback,https://openai.com/blog/deep-reinforcement-learning-from-human-preferences/
Learning to summarize from human feedback by OpenAI (2020),https://arxiv.org/abs/2009.01325
Illustrating Reinforcement Learning from Human Feedback (RLHF)
https://www.linkedin.com/posts/sebastianraschka_ai-deeplearning-machinelearning-activity-7036333477658599424-rkSL
解读Toolformer
解读TaskMatrix.AI
一文读懂“语言模型”
知识图谱的5G追溯
图计算的学习与思考
AI系统中的偏差与偏见
面向AI 的数据生态系统
机器学习与微分方程的浅析
神经网络中常见的激活函数
老码农眼中的大模型(LLM)
《深入浅出Embedding》随笔
机器学习系统架构的10个要素
清单管理?面向机器学习中的数据集
DuerOS 应用实战示例——机器狗DIY
《基于混合方法的自然语言处理》译者序