文章目录
- 一:什么是自动装配
- 二、springboot的启动流程
- 1.调用SpringApplication()的构造方法
- 2.执行核心run方法()
- 3.执行核心prepareContext()
- 4.执行核心refreshContext()
- 5.ConfigurationClassPostProcess
- 三:流程概述
- 四:总结
Spring Boot的核心理念是简化Spring应用的搭建和开发过程,提出了约定大于配置和自动装配的思想。开发Spring项目通常要配置xml文件,当项目变得复杂的时候,xml的配置文件也将变得极其复杂。为了解决这个问题,我们将一些常用的通用的配置先配置好,要用的时候直接装上去,不用的时候卸下来,这些就是Spring Boot框架在Spring框架的基础上要解决的问题。
一:什么是自动装配
在传统的Spring框架中,我们需要手动配置和管理Bean的依赖关系,但在Spring Boot中,大量的配置可以自动完成。这是因为Spring Boot中引入了自动装配的概念。自动装配指的是根据应用程序的依赖关系自动配置Spring Bean,而无需手动配置。
手动装配
比如在下面代码中,我创建了一个cat和一个dog。然后通过手动方式把他注入到people类的属性cat和dog中。
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd"><bean id="cat" class="com.kuang.pojo.Cat"/><bean id="dog" class="com.kuang.pojo.Dog"/><bean id="people" class="com.kuang.pojo.Peopel"><property name="name" value="张三"/><property name="cat" ref="cat"/><property name="dog" ref="dog"/></bean></beans>自动装配
spring中实现自动装配的方式有两种,一种是通过xml文件、一种是通过注解的方式。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beanshttps://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/contexthttps://www.springframework.org/schema/context/spring-context.xsd"><context:annotation-config/><bean id="cat" class="com.kuang.pojo.Cat"/><bean id="dog" class="com.kuang.pojo.Dog"/><bean id="people" class="com.kuang.pojo.Peopel"><property name="name" value="张三"/></bean>
</beans>通过@Autowired注解就可以直接完成我们cat和dog的属性注入
public class Peopel {@Autowiredprivate Cat cat;@Autowiredprivate Dog dog;private String name;setter/getter...
}
提示:以下是本篇文章正文内容,下面案例可供参考
二、springboot的启动流程
在上面回忆了下什么是自动装配后,我们先来探索下springboot 的启动流程,看看springboot是在哪一步完成自动装配的。
这是一个启动springboot程序的启动类
@SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })
@EnableTransactionManagement
public class RuoYiApplication
{public static void main(String[] args){// System.setProperty("spring.devtools.restart.enabled", "false");SpringApplication.run(RuoYiApplication.class, args);System.out.println("(♥◠‿◠)ノ゙ 若依启动成功 ლ(´ڡ`ლ)゙ \n" +" .-------. ____ __ \n" +" | _ _ \\ \\ \\ / / \n" +" | ( ' ) | \\ _. / ' \n" +" |(_ o _) / _( )_ .' \n" +" | (_,_).' __ ___(_ o _)' \n" +" | |\\ \\ | || |(_,_)' \n" +" | | \\ `' /| `-' / \n" +" | | \\ / \\ / \n" +" ''-' `'-' `-..-' ");}
}
1.调用SpringApplication()的构造方法
在执行run方法之前,会调用SpringApplication()的构造方法
public static ConfigurableApplicationContext run(Class<?> primarySource, String... args) {return run(new Class<?>[] { primarySource }, args);}public static ConfigurableApplicationContext run(Class<?>[] primarySources, String[] args) {return new SpringApplication(primarySources).run(args);}
SpringApplication的构造方法,这里主要做几件事
第一件事:确定应用程序类型,看看当前程序是servlet,还是NONE 和 REACTIVE (响应式编程);
第二件事:将启动类设置为Sources(也就是RuoYiApplication)
第三件事:设置初始化器
第四件事:设置监听器
第五件事:程序运行的主类
public SpringApplication(ResourceLoader resourceLoader, Class<?>... primarySources) {this.resourceLoader = resourceLoader;Assert.notNull(primarySources, "PrimarySources must not be null");// 将启动类设置为Sources(也就是RuoYiApplication)this.primarySources = new LinkedHashSet<>(Arrays.asList(primarySources));// 确定应用程序的类型this.webApplicationType = WebApplicationType.deduceFromClasspath();this.bootstrapRegistryInitializers = getBootstrapRegistryInitializersFromSpringFactories();// 设置初始化器setInitializers((Collection) getSpringFactoriesInstances(ApplicationContextInitializer.class));// 设置监听器setListeners((Collection) getSpringFactoriesInstances(ApplicationListener.class));// 程序运行的主类this.mainApplicationClass = deduceMainApplicationClass();}
在设置初始化器和监听器过程中,会调用getSpringFactoriesInstances()这个方法。该方法主要做的事情就是读取我们META-INF/spring.factories下的文件,并存入缓存cache中。到这里大家就会好奇spring.factories是什么样的文件,有什么作用。
private static Map<String, List<String>> loadSpringFactories(ClassLoader classLoader) {Map<String, List<String>> result = (Map)cache.get(classLoader);if (result != null) {return result;} else {Map<String, List<String>> result = new HashMap();try {Enumeration<URL> urls = classLoader.getResources("META-INF/spring.factories");while(urls.hasMoreElements()) {.......}.......cache.put(classLoader, result);return result;} catch (IOException var14) {throw new IllegalArgumentException("Unable to load factories from location [META-INF/spring.factories]", var14);}}}
spring.factories 文件用于在 Spring Boot 项目中配置自动配置项。它包含了一系列 key-value 对,key 是自动配置类的全限定名,value 是这些配置类对应的条件类。

其实也可以理解为,比如我们自己写的类都加了@Componet注解,或者扫描我们自己需要的路径加上@ComponetScan注解。但是有一些我们引入的jar包,它里面的类我们要怎么注入到我们的spring容器中呢。这时候就需要spring.factories,我们只需在这个文件配置全限定名,然后spring去扫描spring.factories文件最后加入到我们容器即可。
2.执行核心run方法()
run()方法中最主要的是prepareContext() 和refreshContext()这两个方法。其他细节我就不在概述了,主要还是以这两个方法为主。
// 核心方法准备上下文
prepareContext(bootstrapContext, context, environment, listeners, applicationArguments, printedBanner);// 刷新上下文
refreshContext(context);
public ConfigurableApplicationContext run(String... args) {// 开启计时器StopWatch stopWatch = new StopWatch();stopWatch.start();DefaultBootstrapContext bootstrapContext = createBootstrapContext();ConfigurableApplicationContext context = null;configureHeadlessProperty();SpringApplicationRunListeners listeners = getRunListeners(args);// 启用监听器listeners.starting(bootstrapContext, this.mainApplicationClass);try {ApplicationArguments applicationArguments = new DefaultApplicationArguments(args);// 准备环境变量ConfigurableEnvironment environment = prepareEnvironment(listeners, bootstrapContext, applicationArguments);configureIgnoreBeanInfo(environment);// 打印beanner信息Banner printedBanner = printBanner(environment);// 创建上下文context = createApplicationContext();context.setApplicationStartup(this.applicationStartup);// 核心方法准备上下文prepareContext(bootstrapContext, context, environment, listeners, applicationArguments, printedBanner);// 核心刷新上下文refreshContext(context);afterRefresh(context, applicationArguments);stopWatch.stop();if (this.logStartupInfo) {new StartupInfoLogger(this.mainApplicationClass).logStarted(getApplicationLog(), stopWatch);}listeners.started(context);callRunners(context, applicationArguments);}catch (Throwable ex) {handleRunFailure(context, ex, listeners);throw new IllegalStateException(ex);}try {listeners.running(context);}catch (Throwable ex) {handleRunFailure(context, ex, null);throw new IllegalStateException(ex);}return context;}
3.执行核心prepareContext()
刷新应用上下文前的准备阶段。也就是prepareContext()方法。
Set sources = getAllSources();还记得前面我们在实例化SpringApplication时,将启动类设置为了sources,在这里我们就获取到了sources,进行load加载。
private void prepareContext(ConfigurableApplicationContext context,ConfigurableEnvironment environment, SpringApplicationRunListeners listeners,ApplicationArguments applicationArguments, Banner printedBanner) {//设置容器环境context.setEnvironment(environment);//执行容器后置处理postProcessApplicationContext(context);//执行容器中的 ApplicationContextInitializer 包括spring.factories和通过三种方式自定义的applyInitializers(context);//向各个监听器发送容器已经准备好的事件listeners.contextPrepared(context);if (this.logStartupInfo) {logStartupInfo(context.getParent() == null);logStartupProfileInfo(context);}// Add boot specific singleton beans//将main函数中的args参数封装成单例Bean,注册进容器context.getBeanFactory().registerSingleton("springApplicationArguments",applicationArguments);//将 printedBanner 也封装成单例,注册进容器if (printedBanner != null) {context.getBeanFactory().registerSingleton("springBootBanner", printedBanner);}// Load the sourcesSet<Object> sources = getAllSources();Assert.notEmpty(sources, "Sources must not be empty");//加载我们的启动类,将启动类注入容器load(context, sources.toArray(new Object[0]));//发布容器已加载事件listeners.contextLoaded(context);
}在load方法中,通过createBeanDefinitionLoader()方法为我们创建了一个启动类的BeanDefinition。
protected void load(ApplicationContext context, Object[] sources) {if (logger.isDebugEnabled()) {logger.debug("Loading source " + StringUtils.arrayToCommaDelimitedString(sources));}//创建 BeanDefinitionLoaderBeanDefinitionLoader loader = createBeanDefinitionLoader(getBeanDefinitionRegistry(context), sources);if (this.beanNameGenerator != null) {loader.setBeanNameGenerator(this.beanNameGenerator);}if (this.resourceLoader != null) {loader.setResourceLoader(this.resourceLoader);}if (this.environment != null) {loader.setEnvironment(this.environment);}loader.load();
}
在 this.annotatedReader.register(source)方法中,会将我们的启动类注入到我们的BeanDefinition容器中。
private void load(Class<?> source) {if (isGroovyPresent() && GroovyBeanDefinitionSource.class.isAssignableFrom(source)) {// Any GroovyLoaders added in beans{} DSL can contribute beans hereGroovyBeanDefinitionSource loader = BeanUtils.instantiateClass(source, GroovyBeanDefinitionSource.class);((GroovyBeanDefinitionReader) this.groovyReader).beans(loader.getBeans());}if (isEligible(source)) {this.annotatedReader.register(source);}}
4.执行核心refreshContext()
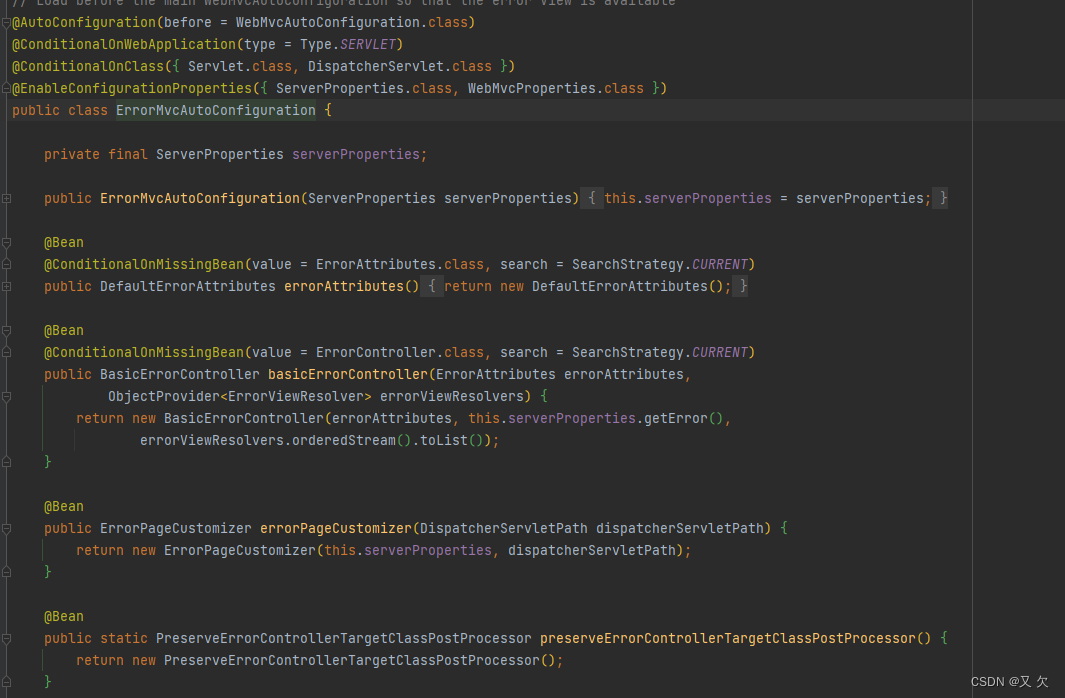
public void refresh() throws BeansException, IllegalStateException {synchronized (this.startupShutdownMonitor) {// Prepare this context for refreshing.// 初始化前的准备工作,主要是一些系统属性、环境变量的校验,比如Spring启动需要某些环境变量,可以在这个地方进行设置和校验prepareRefresh();// Tell the subclass to refresh the internal bean factory.// 获取bean工厂,ConfigurableListableBeanFactory是默认的容器,在这一步会完成工厂的创建以及beanDefinition的读取ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();// Prepare the bean factory for use in this context.// 进入prepareBeanFactory前spring以及完成了对配置的解析,Spring的拓展从这里开始prepareBeanFactory(beanFactory);try {// Allows post-processing of the bean factory in context subclasses.// 留给子类覆盖做拓展,这里一般不做任何处理postProcessBeanFactory(beanFactory);// Invoke factory processors registered as beans in the context.// 调用所有的BeanFactoryPostProcessors,将结果存入参数beanFactory中invokeBeanFactoryPostProcessors(beanFactory);// Register bean processors that intercept bean creation.// 注册BeanPostProcessors,这里只是注册,真正的调用是在doGetBean中registerBeanPostProcessors(beanFactory);// Initialize message source for this context.// 初始化消息原,比如国际化initMessageSource();// Initialize event multicaster for this context.// 初始化消息广播器initApplicationEventMulticaster();// Initialize other special beans in specific context subclasses.// 留给子类类初始化其他的beanonRefresh();// Check for listener beans and register them.// 注册监听器registerListeners();// Instantiate all remaining (non-lazy-init) singletons.// 初始化剩下的单例bean,在这里才开始真正的对bean进行实例化和初始化finishBeanFactoryInitialization(beanFactory);// Last step: publish corresponding event.// 完成刷新,通知生命周期处理器刷新过程。finishRefresh();}}}核心方法 invokeBeanFactoryPostProcessors
public static void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {// Invoke BeanDefinitionRegistryPostProcessors first, if any.Set<String> processedBeans = new HashSet<String>();// 1.判断beanFactory是否为BeanDefinitionRegistry,beanFactory为DefaultListableBeanFactory,// 而DefaultListableBeanFactory实现了BeanDefinitionRegistry接口,因此这边为trueif (beanFactory instanceof BeanDefinitionRegistry) {BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;// 用于存放普通的BeanFactoryPostProcessorList<BeanFactoryPostProcessor> regularPostProcessors = new LinkedList<BeanFactoryPostProcessor>();// 用于存放BeanDefinitionRegistryPostProcessorList<BeanDefinitionRegistryPostProcessor> registryProcessors = new LinkedList<BeanDefinitionRegistryPostProcessor>();// 2.首先处理入参中的beanFactoryPostProcessors// 遍历所有的beanFactoryPostProcessors, 将BeanDefinitionRegistryPostProcessor和普通BeanFactoryPostProcessor区分开for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {// 2.1 如果是BeanDefinitionRegistryPostProcessorBeanDefinitionRegistryPostProcessor registryProcessor =(BeanDefinitionRegistryPostProcessor) postProcessor;// 2.1.1 直接执行BeanDefinitionRegistryPostProcessor接口的postProcessBeanDefinitionRegistry方法registryProcessor.postProcessBeanDefinitionRegistry(registry);// 2.1.2 添加到registryProcessors(用于最后执行postProcessBeanFactory方法)registryProcessors.add(registryProcessor);} else {// 2.2 否则,只是普通的BeanFactoryPostProcessor// 2.2.1 添加到regularPostProcessors(用于最后执行postProcessBeanFactory方法)regularPostProcessors.add(postProcessor);}}// Do not initialize FactoryBeans here: We need to leave all regular beans// uninitialized to let the bean factory post-processors apply to them!// Separate between BeanDefinitionRegistryPostProcessors that implement// PriorityOrdered, Ordered, and the rest.// 用于保存本次要执行的BeanDefinitionRegistryPostProcessorList<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<BeanDefinitionRegistryPostProcessor>();// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.// 3.调用所有实现PriorityOrdered接口的BeanDefinitionRegistryPostProcessor实现类// 3.1 找出所有实现BeanDefinitionRegistryPostProcessor接口的Bean的beanNameString[] postProcessorNames =beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);// 3.2 遍历postProcessorNamesfor (String ppName : postProcessorNames) {// 3.3 校验是否实现了PriorityOrdered接口if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {// 3.4 获取ppName对应的bean实例, 添加到currentRegistryProcessors中,// beanFactory.getBean: 这边getBean方法会触发创建ppName对应的bean对象, 目前暂不深入解析currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));// 3.5 将要被执行的加入processedBeans,避免后续重复执行processedBeans.add(ppName);}}// 3.6 进行排序(根据是否实现PriorityOrdered、Ordered接口和order值来排序)sortPostProcessors(currentRegistryProcessors, beanFactory);// 3.7 添加到registryProcessors(用于最后执行postProcessBeanFactory方法)registryProcessors.addAll(currentRegistryProcessors);// 3.8 遍历currentRegistryProcessors, 执行postProcessBeanDefinitionRegistry方法invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);// 3.9 执行完毕后, 清空currentRegistryProcessorscurrentRegistryProcessors.clear();}
和自动装配相关的还是这一段代码
// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.// 3.调用所有实现PriorityOrdered接口的BeanDefinitionRegistryPostProcessor实现类// 3.1 找出所有实现BeanDefinitionRegistryPostProcessor接口的Bean的beanNameString[] postProcessorNames =beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);// 3.2 遍历postProcessorNamesfor (String ppName : postProcessorNames) {// 3.3 校验是否实现了PriorityOrdered接口if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {// 3.4 获取ppName对应的bean实例, 添加到currentRegistryProcessors中,// beanFactory.getBean: 这边getBean方法会触发创建ppName对应的bean对象, 目前暂不深入解析currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));// 3.5 将要被执行的加入processedBeans,避免后续重复执行processedBeans.add(ppName);}}// 3.6 进行排序(根据是否实现PriorityOrdered、Ordered接口和order值来排序)sortPostProcessors(currentRegistryProcessors, beanFactory);// 3.7 添加到registryProcessors(用于最后执行postProcessBeanFactory方法)registryProcessors.addAll(currentRegistryProcessors);// 3.8 遍历currentRegistryProcessors, 执行postProcessBeanDefinitionRegistry方法invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
首先从我们的BeanDefintionMap中获取是BeanDefinitionRegistryPostProcessor.class的实现类,而ConfigurationClassPostProcess是一个后置处理器的类,主要功能是参与BeanFactory的建造,主要功能如下:
1.解析加了@Configuration的配置类
2.解析@ComponentScan扫描的包
3.解析@ComponentScans扫描的包
4.解析@Import注解

5.ConfigurationClassPostProcess

ConfigurationClassPostProcessor 实现了 BeanDefinitionRegistryPostProcessor 接口,而 BeanDefinitionRegistryPostProcessor 接口继承了 BeanFactoryPostProcessor 接口,所以 ConfigurationClassPostProcessor 中需要重写 postProcessBeanDefinitionRegistry() 方法和 postProcessBeanFactory() 方法。
postProcessBeanDefinitionRegistry()方法:定位、加载、解析、注册相关注解。
postProcessBeanFactory()方法:添加CGLIB增强处理及ImportAwareBeanPostProcessor后置处理类。
我们先来看看ConfigurationClassPostProcessor 的postProcessBeanDefinitionRegistry()方法是怎么做的
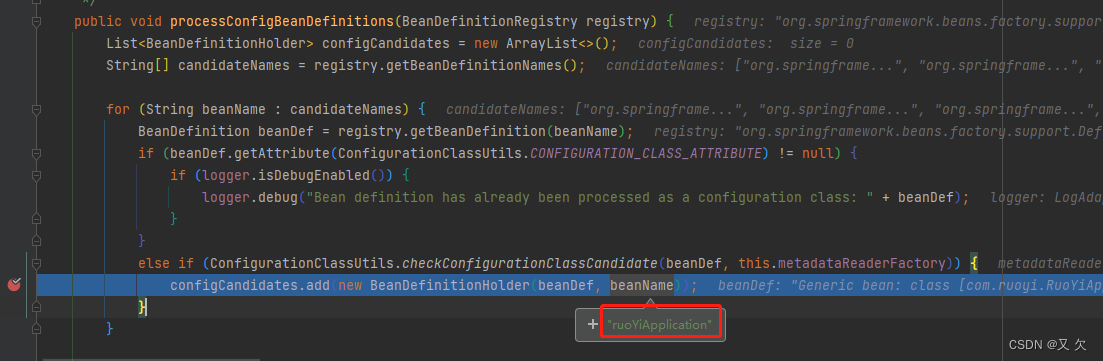
public class ConfigurationClassPostProcessor implements BeanDefinitionRegistryPostProcessor,PriorityOrdered, ResourceLoaderAware, BeanClassLoaderAware, EnvironmentAware {/*** 构建和验证一个类是否被@Configuration修饰,并做相关的解析工作* 如果你对此方法了解清楚了,那么springboot的自动装配原理就清楚了*/public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {// 创建存放BeanDefinitionHolder的对象集合List<BeanDefinitionHolder> configCandidates = new ArrayList<>();// 当前registry就是DefaultListableBeanFactory,获取所有已经注册的BeanDefinition的beanNameString[] candidateNames = registry.getBeanDefinitionNames();//----------------第一步-----------------// 遍历所有要处理的beanDefinition的名称,筛选对应的被注解修饰的beanDefinitionfor (String beanName : candidateNames) {// 获取指定名称的BeanDefinition对象BeanDefinition beanDef = registry.getBeanDefinition(beanName);// 判断当前BeanDefinition是否是一个配置类,并为BeanDefinition设置属性为lite或者full,此处设置属性值是为了后续进行调用// 如果Configuration配置proxyBeanMethods代理为true则为full// 如果加了@Bean、@Component、@ComponentScan、@Import、@ImportResource注解,则设置为lite// 如果配置类上被@Order注解标注,则设置BeanDefinition的order属性值else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {// 添加到对应的集合对象中configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));}}
}第一步是遍历所有要处理的beanDefinition的名称,筛选对应的被注解修饰的beanDefinition,做这一步的目的是什么,从开始到现在我们也没有去执行解析启动类上的注解,也没有进行bean的扫描和定义。在前面过程中,我们只是把我们的启动类加入到了beanDefinition的Map中,现在我们是不是该把启动类给取出来,进行注解的解析。
第二步那肯定是要去解析扫描,启动类上的注解了
//----------------第二步-----------------// 存放相关的BeanDefinitionHolder对象Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);// 存放扫描包下的所有beanSet<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());do {// 解析带有@Controller、@Import、@ImportResource、@ComponentScan、@ComponentScans、@Bean的BeanDefinitionparser.parse(candidates);// 将解析完的Configuration配置类进行校验,1、配置类不能是final,2、@Bean修饰的方法必须可以重写以支持CGLIBparser.validate();// 获取所有的bean,包括扫描的bean对象,@Import导入的bean对象Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());// 清除掉已经解析处理过的配置类configClasses.removeAll(alreadyParsed);// Read the model and create bean definitions based on its content// 判断读取器是否为空,如果为空的话,就创建完全填充好的ConfigurationClass实例的读取器if (this.reader == null) {this.reader = new ConfigurationClassBeanDefinitionReader(registry, this.sourceExtractor, this.resourceLoader, this.environment,this.importBeanNameGenerator, parser.getImportRegistry());}while (!candidates.isEmpty());
parse()方法会解析配置类上的注解(ComponentScan扫描出的类,@Import注册的类,以及@Bean方法定义的类),解析完以后(解析成ConfigurationClass类),会将解析出的结果放入到parser的configurationClasses这个属性中(这个属性是个Map)。parse会将@Import注解要注册的类解析为BeanDefinition,但是不会把解析出来的BeanDefinition放入到BeanDefinitionMap中,真正放入到map中是在这一行代码实现的:
public void parse(Set<BeanDefinitionHolder> configCandidates) {this.deferredImportSelectors = new LinkedList<>();// 根据BeanDefinition类型的不同,调用parse()不同的重载方法// 实际上最终都是调用processConfigurationClass()方法for (BeanDefinitionHolder holder : configCandidates) {BeanDefinition bd = holder.getBeanDefinition();try {if (bd instanceof AnnotatedBeanDefinition) {parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName());}else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) {parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName());}else {parse(bd.getBeanClassName(), holder.getBeanName());}}}// 处理延迟importSelectorprocessDeferredImportSelectors();
}processConfigurationClass()方法中最核心的就是doProcessConfigurationClass方法,在该方法会去处理我们的注解逻辑
protected void processConfigurationClass(ConfigurationClass configClass) throws IOException {// 处理配置类,由于配置类可能存在父类(若父类的全类名是以java开头的,则除外),所有需要将configClass变成sourceClass去解析,然后返回sourceClass的父类。// 如果此时父类为空,则不会进行while循环去解析,如果父类不为空,则会循环的去解析父类// SourceClass的意义:简单的包装类,目的是为了以统一的方式去处理带有注解的类,不管这些类是如何加载的// 如果无法理解,可以把它当做一个黑盒,不会影响看spring源码的主流程SourceClass sourceClass = asSourceClass(configClass);do {// 核心处理逻辑sourceClass = doProcessConfigurationClass(configClass, sourceClass);}while (sourceClass != null);// 将解析的配置类存储起来,这样回到parse()方法时,能取到值this.configurationClasses.put(configClass, configClass);
}@Component注解,先判断该配置类是否含有@Component注解(isAnnotated方法会找当前类标识的注解,包括注解内部的元注解),
if (configClass.getMetadata().isAnnotated(Component.class.getName())) {// Recursively process any member (nested) classes firstprocessMemberClasses(configClass, sourceClass, filter);}@PropertySource注解 ,接着解析配置类的@PropertySource,解析配置文件并加载到容器环境中
// Process any @PropertySource annotationsfor (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(sourceClass.getMetadata(), PropertySources.class,org.springframework.context.annotation.PropertySource.class)) {if (this.propertySourceRegistry != null) {this.propertySourceRegistry.processPropertySource(propertySource);}else {logger.info("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +"]. Reason: Environment must implement ConfigurableEnvironment");}}解析@ComponentScan组件,首先解析出类上的@ComponentScan和@ComponentScans注解,然后根据配置的扫描包路径,利用ASM技术(ASM技术是一种操作字节码的技术,有兴趣的朋友可以去网上了解下)扫描出所有需要交给Spring管理的类,由于扫描出的类中可能也被加了@ComponentScan和@ComponentScans注解,因此需要进行递归解析,直到所有加了这两个注解的类被解析完成。
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);if (!componentScans.isEmpty() &&!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {for (AnnotationAttributes componentScan : componentScans) {// The config class is annotated with @ComponentScan -> perform the scan immediatelySet<BeanDefinitionHolder> scannedBeanDefinitions =this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());// Check the set of scanned definitions for any further config classes and parse recursively if neededfor (BeanDefinitionHolder holder : scannedBeanDefinitions) {BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();if (bdCand == null) {bdCand = holder.getBeanDefinition();}if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {// 注意这里会继续调用parse方法,加载扫描有compent注解的类,继续走该方法逻辑加入到我们的BeanDefiantio的map中parse(bdCand.getBeanClassName(), holder.getBeanName());}}}
解析@Import注解
@Import:用来向ioc容器注册组件。
注意:@Import只是向容器注册添加组件的相关信息,组件还未实例化,后续由容器进行实例化
如果不理解@Import注解可以看看这篇文章@Import的作用
processImports(configClass, sourceClass, getImports(sourceClass), filter, true);// 在getImports方法中,会调用collectImports方法,该方法会对我们启动类上的注解进行层层解析。把@import注解获取的类最后加入到Set<SourceClass> imports这个set集合中
private void collectImports(SourceClass sourceClass, Set<SourceClass> imports, Set<SourceClass> visited)throws IOException {if (visited.add(sourceClass)) {for (SourceClass annotation : sourceClass.getAnnotations()) {String annName = annotation.getMetadata().getClassName();if (!annName.equals(Import.class.getName())) {collectImports(annotation, imports, visited);}}imports.addAll(sourceClass.getAnnotationAttributes(Import.class.getName(), "value"));}}
解析@ImportResource注解
// Process any @ImportResource annotationsAnnotationAttributes importResource =AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);if (importResource != null) {String[] resources = importResource.getStringArray("locations");Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");for (String resource : resources) {String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);configClass.addImportedResource(resolvedResource, readerClass);}}
解析@Bean注解
// Process individual @Bean methodsSet<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);for (MethodMetadata methodMetadata : beanMethods) {configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));}
至此,通过解析将容器中的所有配置类、通过解析注解得到的beanDefinition都被保存到容器的beanDefinitions集合中。
可是现在还有一个问题。就是我们的beanDefinition的Map中目前注入的只有我们自己所加载定义的Bean,而前面spring.factories获取的类,包括我们@import注解获取需要的类或组件什么时候加入到beanDefinition的map中呢?
这里我就长话短说了。
public void parse(Set<BeanDefinitionHolder> configCandidates) {for (BeanDefinitionHolder holder : configCandidates) {BeanDefinition bd = holder.getBeanDefinition();try {if (bd instanceof AnnotatedBeanDefinition annotatedBeanDef) {parse(annotatedBeanDef.getMetadata(), holder.getBeanName());}}// 处理延迟importSelectorthis.deferredImportSelectorHandler.process();}// 底层会调用这个方法protected AutoConfigurationEntry getAutoConfigurationEntry(AnnotationMetadata annotationMetadata) {if (!isEnabled(annotationMetadata)) {return EMPTY_ENTRY;}AnnotationAttributes attributes = getAttributes(annotationMetadata);// 从启动类的@import上获取到了AutoConfigurationImportSelector,// 该类是ImportSelect接口的实现类,它重写了接口中的selectImports()方法,//得到一个String类型的数组。该数组是通过底层加载配置文件 META-INF/spring.factories得到的,// 该配置文件中定义了大量的配置类List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes);configurations = removeDuplicates(configurations);Set<String> exclusions = getExclusions(annotationMetadata, attributes);checkExcludedClasses(configurations, exclusions);// 在我调试过程中,configurations 是有146条数据configurations.removeAll(exclusions);// 在这一步会给你做删除,只保留当前对本项目需要的依赖,去除后只有27条数据// 底层会根据条件化注解进行筛选configurations = getConfigurationClassFilter().filter(configurations);fireAutoConfigurationImportEvents(configurations, exclusions);return new AutoConfigurationEntry(configurations, exclusions);}自动配置中使用的条件化注解
===============================================================================================================
条件化注解 配置生效条件
===============================================================================================================
@ConditionalOnBean 配置了某个特定Bean
@ConditionalOnMissingBean 没有配置特定的Bean
@ConditionalOnClass Classpath里有指定的类
@ConditionalOnMissingClass Classpath里缺少指定的类
@ConditionalOnExpression 给定的Spring Expression Language(SpEL)表达式计算结果为true
@ConditionalOnJava Java的版本匹配特定值或者一个范围值
@ConditionalOnJndi 参数中给定的JNDI位置必须存在一个,如果没有给参数,则要有JNDI InitialContext
@ConditionalOnProperty 指定的配置属性要有一个明确的值
@ConditionalOnResource Classpath里有指定的资源
@ConditionalOnWebApplication 这是一个Web应用程序
@ConditionalOnNotWebApplication 这不是一个Web应用程序
===============================================================================================================// 最后调用这个方法将所有类包括配置类都注入到beanDefinitionMap中public void loadBeanDefinitions(Set<ConfigurationClass> configurationModel) {TrackedConditionEvaluator trackedConditionEvaluator = new TrackedConditionEvaluator();for (ConfigurationClass configClass : configurationModel) {loadBeanDefinitionsForConfigurationClass(configClass, trackedConditionEvaluator);}}执行之前beanDefinitionMap只有15条数据

这里是其中的一个Spring所依赖的类,在这个类中也有其他@Bean相关注解的类,所以在这个过程中。spring也会去做扫描,并把它加入到我们的beanDefinitionMap中。(该类有@ConditionalOnClass注解,表示当前类是可以使用的类)
至此,不管是我们配置的类。还是springboot中@import注解所添加的类,还是我们@ComponetScan注解扫描以外的类,都已经添加到我们的beanDefinitionMap中了,后续我们只需要进行bean的实例化即可。

三:流程概述
1、在springboot启动的时候会创建一个SpringApplication对象,在对象的构造方法里面会进行一些参数的初始化工作,最主要的是判断当前应用程序的类型以及设置初始化器以及监听器,并在这个过程中会加载整个应用程序的spring.factories文件,将文件中的内容放到缓存当中,方便后续获取;
2、SpringApplication对象创建完成之后会执行run()方法来完成整个应用程序的启动,启动的过程中有两个最主要的方法prepareContext()和refreshContext(),在这两个方法中完成了自动装配的核心功能,在run()方法里还执行了一些包括上下文对象的创建,打印banner图,异常报告期的准备等各个准备工作,方便后续进行调用;
3、在prepareContext()中主要完成的是对上下文对象的初始化操作,包括属性的设置,比如设置环境变量。在整个过程中有一个load()方法,它主要是完成一件事,那就是将启动类作为一个beanDefinition注册到registry,方便后续在进行BeanFactoryPostProcessor调用执行的时候,可以找到对应执行的主类,来完成对@SpringBootApplication、@EnableAutoConfiguration等注解的解析工作;
4、在refreshContext()方法中会进行整个容器的刷新过程,会调用spring中的refresh()方法,refresh()方法中有13个非常关键的方法,来完成整个应用程序的启动。而在自动装配过程中,会调用的关键的一个方法就是invokeBeanFactoryPostProcessors()方法,在这个方法中主要是对ConfigurationClassPostProcessor类的处理,这个类是BFPP(BeanFactoryPostProcessor)的子类,因为实现了BDRPP(BeanDefinitionRegistryPostProcessor)接口,在调用的时候会先调用BDRPP中的postProcessBeanDefinitionRegistry()方法,然后再调用BFPP中的postProcessBeanFactory()方法,在执行postProcessBeanDefinitionRegistry()方法的时候会解析处理各种的注解,包含@PropertySource、@ComponentScan、@Bean、@Import等注解,最主要的是对@Import注解的解析;
5、在解析@Import注解的时候,会有一个getImport()方法,从主类开始递归解析注解,把所有包含@Import的注解都解析到,然后在processImport()方法中对import的类进行分类,例如AutoConfigurationImportSelect归属于ImportSelect的子类,在后续的过程中会调用AutoConfigurationImportSelector类里面的process方法,来完成整个EnableAutoConfiguration的加载。
四:总结
Spring 和 Spring Boot的最大的区别在于Spring Boot的自动装配原理:
比如:
我们使用Spring创建Web程序时需要导入几个Maven依赖,而Spring Boot只需要一个Maven依赖来创建Web程序,并且Spring Boot还把我们最常用的依赖都放到了一起,现在的我们只需要spring-boot-starter-web这一个依赖就可以完成一个简单的Web应用。
以前用Spring的时候需要XML文件配置开启一些功能,现在Spring Boot不用XML配置了,只需要写一个配置类(@Configuration和继承对应的接口)就可以继续配置。
Spring Boot会通过启动器开启自动装配功能以@EnableAutoConfiguration扫描在spring.factories中的配置,然后通过@EnableAutoConfiguration进行扫描和配置所需要的Bean,自动的扫描SpringBoot项目引入的Maven依赖,只有用到的才会被创建成Bean,然后放到IOC容器内。