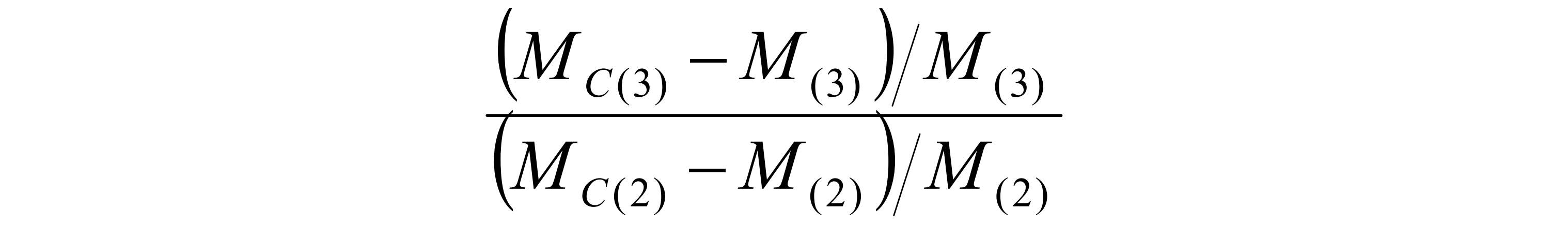本地部署 CodeLlama 并在 VSCode 中使用 CodeLlama
- 1. CodeLlama 是什么
- 2. CodeLlama Github 地址
- 3. 下载 CodeLlama 模型
- 4. 部署 CodeLlama
- 5. 在 VSCode 中使用 CodeLlama
- 6. 使用WSGI启动服务
- 7. 创建 `start.sh` 启动脚本
1. CodeLlama 是什么
Code Llama 是一个基于 Llama 2 的大型代码语言模型系列,在开放模型、填充功能、对大输入上下文的支持以及编程任务的零样本指令跟踪能力中提供最先进的性能。我们提供多种风格来覆盖广泛的应用:基础模型 (Code Llama)、Python 专业化 (Code Llama - Python) 和指令跟随模型 (Code Llama - Instruct),每个模型都有 7B、13B 和 34B 参数。所有模型均在 16k 个标记序列上进行训练,并在最多 100k 个标记的输入上显示出改进。 7B 和 13B Code Llama 和 Code Llama - 指令变体支持基于周围内容的填充。 Code Llama 是通过使用更高的代码采样对 Llama 2 进行微调而开发的。
2. CodeLlama Github 地址
https://github.com/facebookresearch/codellama
3. 下载 CodeLlama 模型
要下载模型权重和标记器,请访问 Meta AI 网站并接受他们的许可证。
一旦您的请求获得批准,您将通过电子邮件收到签名的 URL。然后运行 download.sh 脚本,并在提示开始下载时传递提供的 URL。确保复制 URL 文本本身,右键单击 URL 时不要使用“复制链接地址”选项。如果复制的 URL 文本以:https://download.llamameta.net 开头,则您复制正确。如果复制的 URL 文本以:https://l.facebook.com 开头,则您复制的方式错误。
4. 部署 CodeLlama
创建虚拟环境,
conda create -n codellama python==3.10 -y
conda activate codellama
克隆代码,
git clone https://github.com/facebookresearch/codellama.git; cd codellama
安装依赖,
pip install -e .
5. 在 VSCode 中使用 CodeLlama
下载 llamacpp_mock_api.py,
cd codellama
wget https://raw.githubusercontent.com/xNul/code-llama-for-vscode/main/llamacpp_mock_api.py
启动 llamacpp_mock_api.py,
torchrun --nproc_per_node 1 llamacpp_mock_api.py \--ckpt_dir CodeLlama-7b-Instruct/ \--tokenizer_path CodeLlama-7b-Instruct/tokenizer.model \--max_seq_len 512 --max_batch_size 4
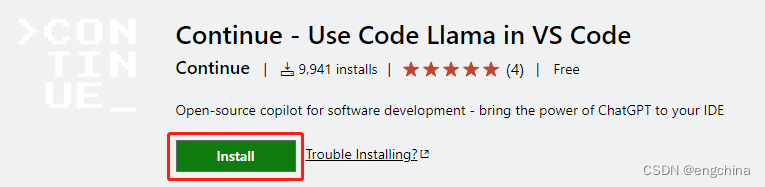
VSCode 安装 Continue 插件,使用浏览器打开 Continue VSCode extension,单击 Install,
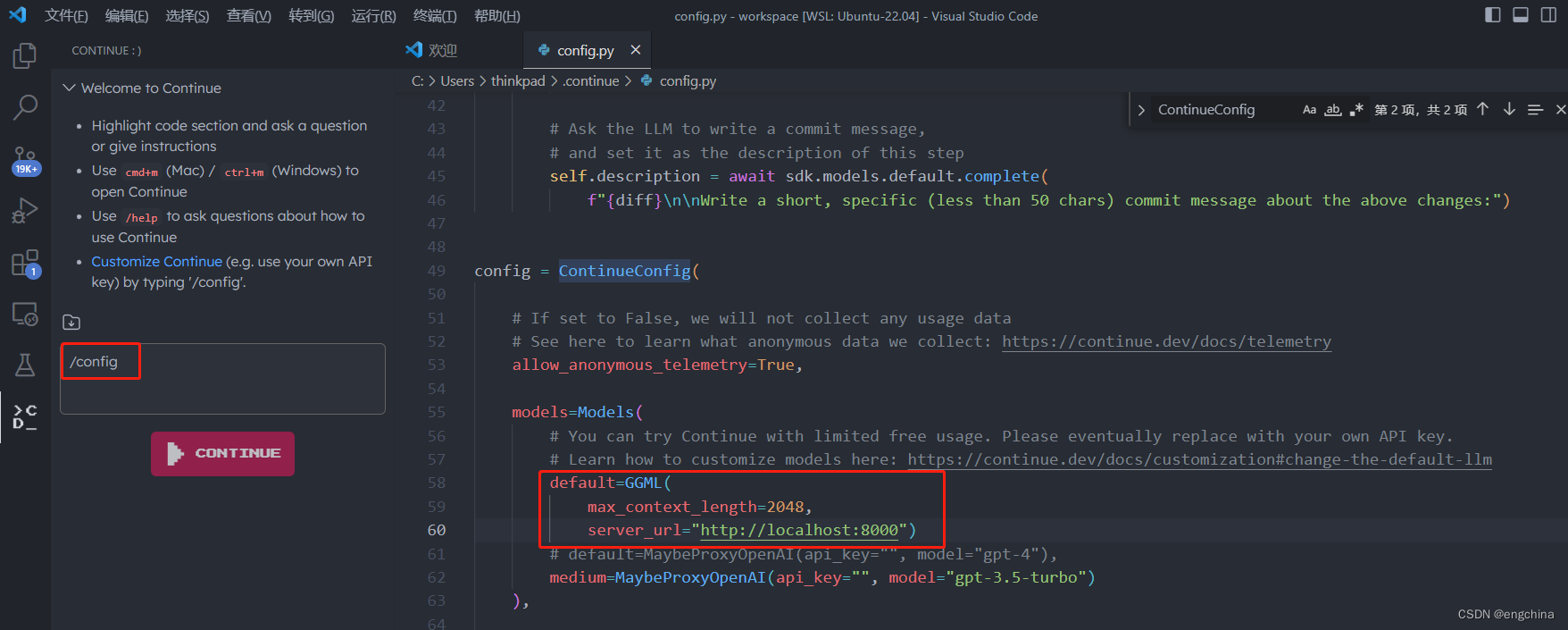
VSCode 中打开 Continue,输入 /config,修改 models 的配置如下,
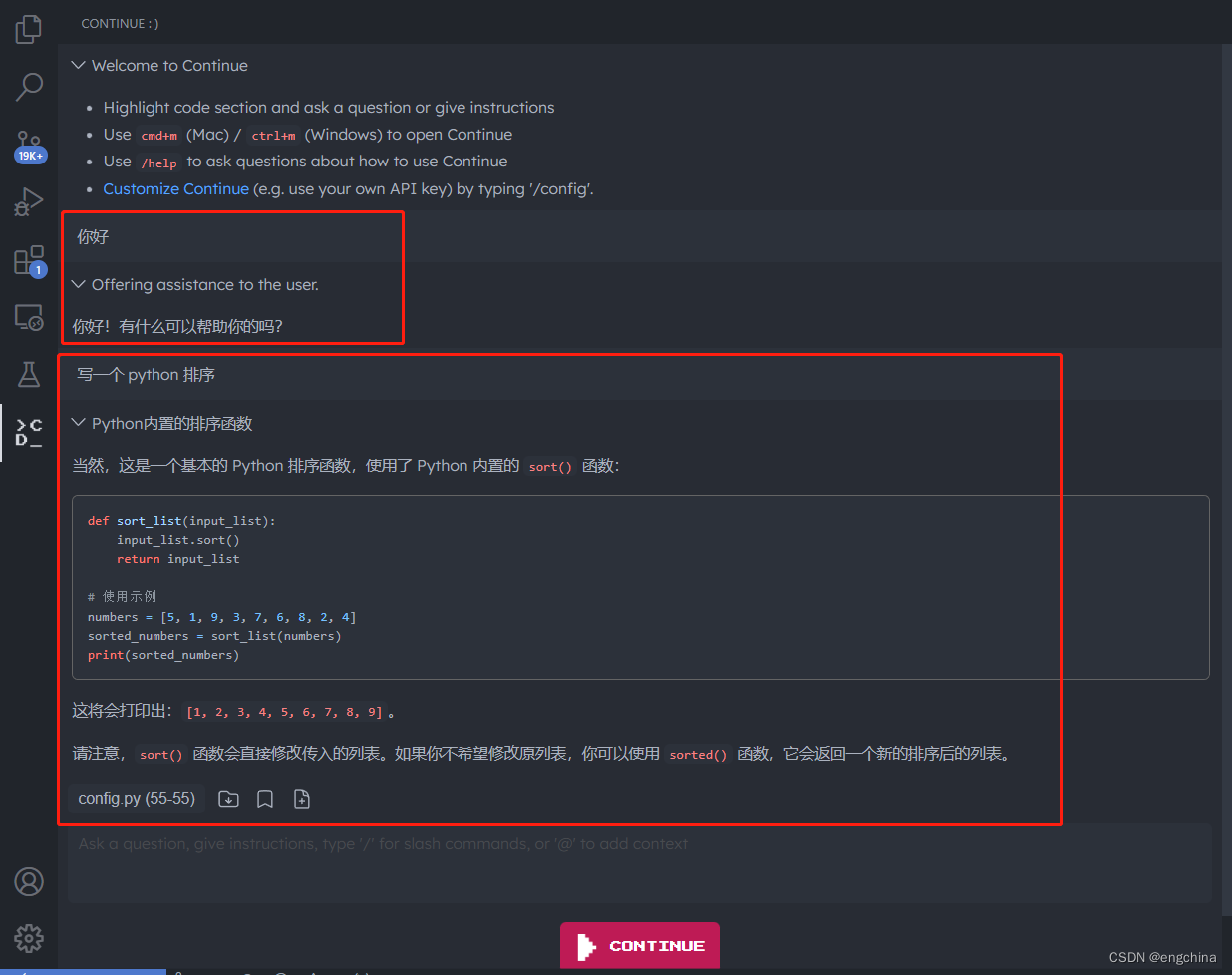
然后就可以在 Continue 的对话框和 CodeLlama 对话了,
6. 使用WSGI启动服务
安装 gevent 库,
pip install gevent
修改代码,
vi llamacpp_mock_api.py---# Run the Flask API server.# app.run(port=port)server = pywsgi.WSGIServer(('0.0.0.0', port), app)server.serve_forever()
---
7. 创建 start.sh 启动脚本
创建 start.sh 启动脚本,
cat << "EOF" > start.sh
eval "$(conda shell.bash hook)"
conda activate codellama
torchrun --nproc_per_node 1 llamacpp_mock_api.py \--ckpt_dir CodeLlama-7b-Instruct/ \--tokenizer_path CodeLlama-7b-Instruct/tokenizer.model \--max_seq_len 512 --max_batch_size 4
EOF
运行 start.sh 启动脚本,
chmod +x ./start.sh
./start.sh
完结!