Redis 基础类型
String
应用场景
缓存功能:string 最常用的就是缓存功能,会将一些更新不频繁但是查询频繁的数据缓存起来,以此来减轻 DB 的压力。
底层实现
- 如果字符串对象保存的是一个字符串值, 并且这个字符串值的长度大于 44 字节, 那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串值, 并将对象的编码设置为 raw。
- 如果字符串对象保存的是一个字符串值, 并且这个字符串值的长度小于等于 44 字节, 那么字符串对象将使用 embstr 编码的方式来保存这个字符串值。
SDS 与 C 字符串的区别

struct sdshdr { int len; // buf 中已占用空间的长度 int free; // buf 中剩余可用空间的长度char buf[]; // 数据空间
};
SDS 相比C 字符串的优势:
- SDS保存了字符串的长度,而C字符串不保存长度,需要遍历整个数组(找到’\0’为止)才能取到字符串长度。
- 修改SDS时,检查给定SDS空间是否足够,如果不够会先拓展SDS 的空间,防止缓冲区溢出。
- SDS预分配空间的机制,可以减少为字符串重新分配空间的次数。
Hash类型
Hash对象的实现方式有两种分别是ziplist、hashtable,其中hashtable的存储方式key是String类型的,value也是以key value的形式进行存储。
应用场景
- 购物车场景:可以以用户的id为key,商品的id 为存储的field,商品数量为键值对的value,这样就构成了购物车的三个要素。
- 分布式生成唯一ID:
return redisUtil.increment(key, hashKey, offset);
hashtable – 渐进式rehash
若是rehashindex 表示为-1表示没有rehash操作,当rehash操作开始时会将该值改成0
「更新、删除、查询会在ht[0]和ht[1]中都进行」
「ht[0]只减不增,直到最后的某一个时刻变成空表」
ziplist
压缩列表(ziplist)是一组连续内存块组成的顺序的数据结构,压缩列表能够节省空间,压缩列表中使用多个节点来存储数据。
ziplist类似于双向链表,但是它不存储上一个节点和下一个节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,来换取高效的内存空间利用率,节约内存。
List类型
应用场景
Redis中的列表可以实现「阻塞队列」
底层实现
- ziplist
- linkedlist
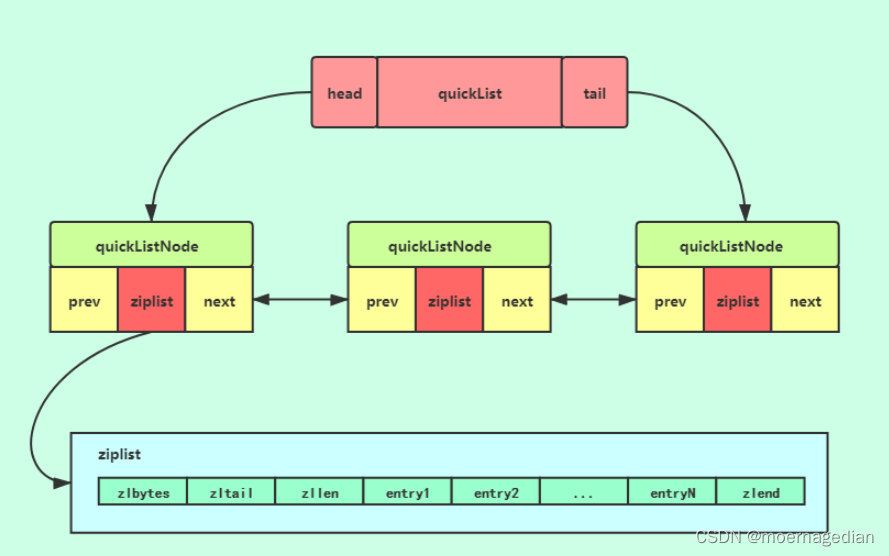
- quicklist
linkedlist是一个双向链表,他和普通的链表一样都是由指向前后节点的指针。
quickList 是 zipList 和 linkedList 的混合体,它将 linkedList 按段切分,每一段使用 zipList 来紧凑存储,多个 zipList 之间使用双向指针串接起来。
Set集合
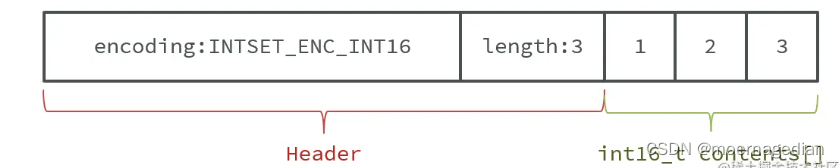
hashtable 以及 intset
typedef struct intset {uint32_t encoding; /* 编码方式,支持存放16位、32位、64位整数*/uint32_t length; /* 元素个数 */int8_t contents[]; /* 整数数组,保存集合数据*/
} intset;
升级原理
- 1、IntSet升级编码为INTSET_ENC_INT32, 每个整数占4字节,并按照新的编码方式及元素个数扩容数组
- 2、倒序依次将数组中的元素拷贝到扩容后的正确位置
- 3、将待添加的元素50000放入数组末尾
- 4、最后,将inset的encoding属性改为INTSET_ENC_INT32,将length属性改为4
ZSet集合
应用场景
排行榜
限流策略
--KEYS[1]:该次限流对应的key
--ARGV[1]:一分钟之前的时间戳
--ARGV[2]:此时此刻的时间戳
--ARGV[3]:允许通过的最大数量
--ARGV[4]:member名称(随机生成)
// 删除一分钟之前所有时间戳
redis.call('zremrangeByScore', KEYS[1], 0, ARGV[1])
// 获取集合的成员数量
local res = redis.call('zcard', KEYS[1])
if (res == nil) or (res < tonumber(ARGV[3])) thenredis.call('zadd', KEYS[1], ARGV[2], ARGV[4])return 0
else return 1 end底层实现
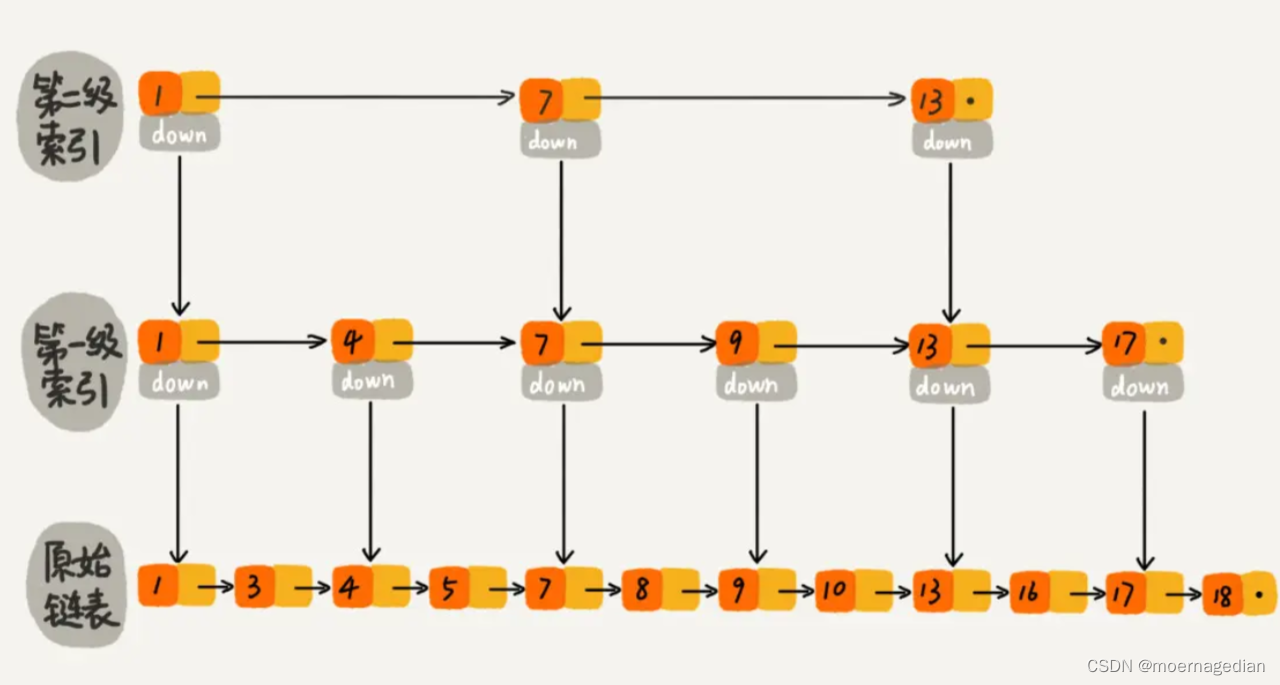
跳表