微服务(rpc)
- 微服务必备的模块
- 生产者
- 消费者
- 管理平台
- 流量控制
- 集群情况下如何做到流量监控
- 负载均衡
- 服务发现和治理
- 序列化传输
- 序列化和反序列化
微服务是一种架构风格,将一个应用程序拆分为一组小型、独立的服务,每个服务都可以独立开发、部署和扩展。每个服务都有自己的业务逻辑和数据存储,并通过轻量级的通信机制来进行互相通信。
微服务必备的模块
生产者
生产者的实现原理参考了Tomcat
消费者
消费者的实现原理参考了mybatis
管理平台
消费者和生产者在管理平台上注册信息,便于管理。每一个信息都要加上详细说明。管理平台中还应该有调用关系,说明谁调用了谁。
流量控制
当超过限制的流量访问微服务时,会造成瘫痪,此时造成的损失应由生产者承担。当设置流量控制后,超过流量的访问将会被禁止。
流量控制由消费者去做,当消费者发送请求后自己进行计数,当发现流量达到一定程度时,消费者自己就会进行拦截
集群情况下如何做到流量监控
假设有两台消费者访问四台生产者,一分钟不能超过一万次的流量,那么如何安排两台消费者的访问流量
负载均衡
不是用nigx做的,微服务属于内网调用,不对外网公布。内网之间的调用没有那么复杂,例如不会使用http协议。会使用自定义协议,在这种条件下,Tomcat和nigx不能够正常使用。(dobbo使用的就是自定义协议)
服务发现和治理
当生产者的服务器发生变化时(宕机或者有新服务器增加)
服务器增加:生产者和消费者就会自动向管理平台注册信息,为了区分不同的生产者和消费者,所以在申请时,会在平台上自动生成唯一的标记,同时标记会被存放放到指定的位置上,当生产者和消费者在次发送请求时,管理平台就可以根据标记来区分不同的生产消费者
服务器宕机:每台服务器都会定时向管理平台发送信息让管理平台确认自己的运行状态是否正常,当连续多次不在管理平台发送信息时,管理平台就可以及时发现服务器不能正常使用并及时进行销毁
当服务器发生变动后,管理平台会向所有调用变动生产者的消费者发送通知,以确保消费者可以及时了解生产者的消息。
由于存在延迟,当一台服务器多次不在向管理平台发送心跳期间,若有大量消费者的请求涌入,会造成损失。所以当消费者在第一次得不到生产者的回应后,会尝试第二次访问,当再次得不到回应时,消费者会及时将生产者IP进行上报并及时切换其他生产者进行请求。当管理平台接收到消费者的故障请求时,就会向其他消费者发送通知告知生产者故障
当消费者首次调用生产者IP时,会询问管理平台生产者的IP并以hashmap的方式存入缓存中存储到缓存中,下次直接进行访问,也正是因为这样,使得得知生产者故障的IP较晚。当消费者得知生产者故障时,会及时更新自己的缓存
序列化传输
通常情况下,序列化和反序列化会用到反射机制,而序列化传输使用的是probuffer,全程没用使用到任何反射机制,极大提高了效率。
springcloud性能比较慢,但是许多核心模块都是现成的,不需要自己进行开发
dobbo传输性能特别快,核心为生产者和消费者,其他模块内容需要自己去手写一份。
序列化和反序列化
序列化就是把对象转成流的形式,反序列化就是把流转为对象。序列化和反序列是毫秒级别的操作,之所以慢是因为应用到了反射,反射需要将内存都遍历一遍,导致速递很慢。
在序列化传输中,序列化和反序列化追求的都是无反射。
我们定义两个类,那么这两个类进行传输时,需要通过反射来遍历一遍类中的内容,那么如何做到无反射呢。
首先我们在WW类中加入注解标记他为需要特殊处理的类,给类中字段加入注解标记顺位和最大长度。那么这个类就进行了进化,生成了伴生类,但是在使用时是不会受到任何影响的。
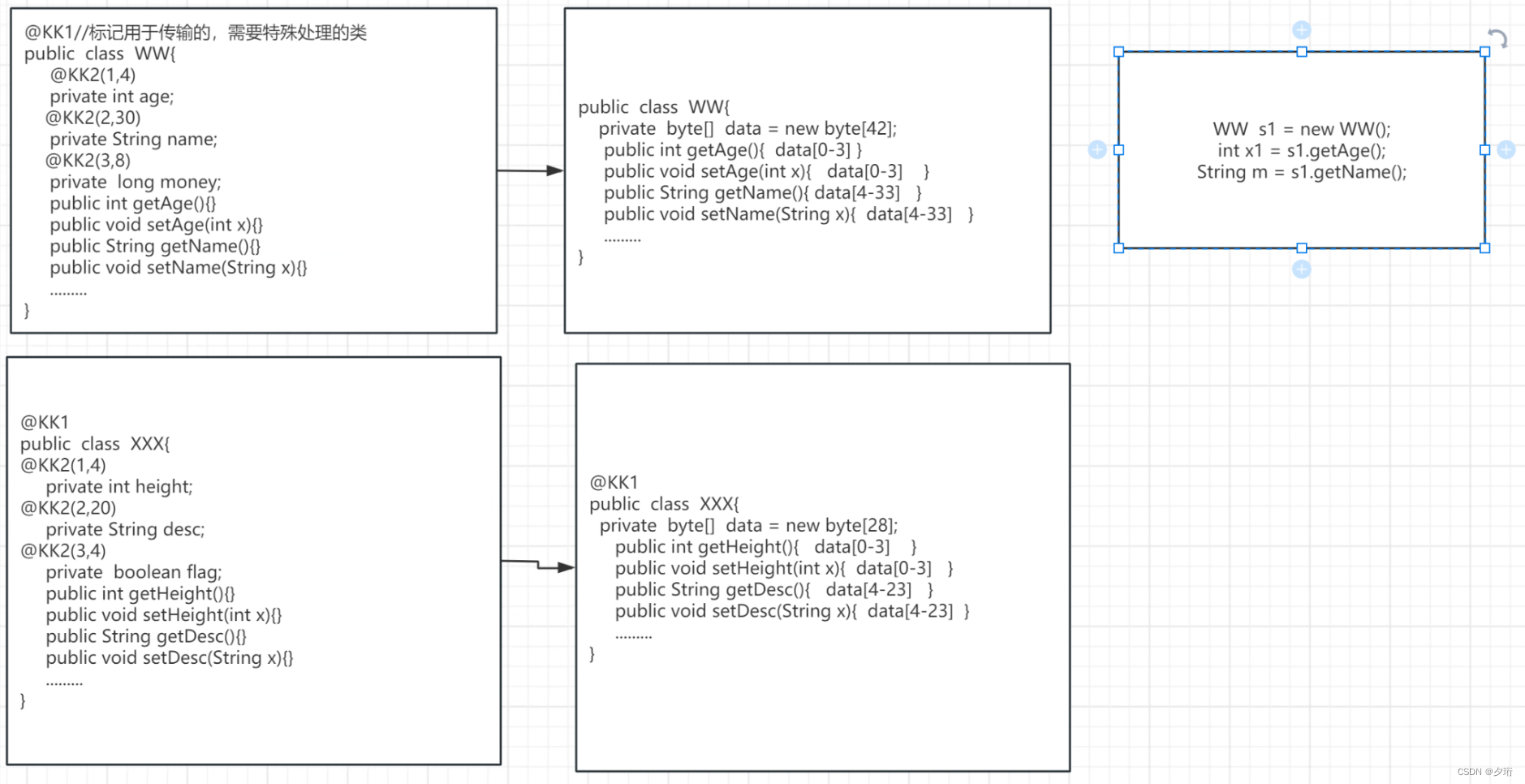
我们如果要发送一个XX对象,消费者会有一个负责发送的send方法,里面包含了参数的url,类型等数据。也就是说,通过多态直接调用send中的data就可以完成发送。只有在启动生成伴生类时使用了反射,其他时候就不在使用反射。
反射类继承了多态,消费者调用send方法通过socket进行发送,生产者就会接收到,同时创建一个对象来储存接收到的信息,生产者对数据进行处理后返回给消费者。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ChagKUHC-1692870508702)(C:\Users\沧翎\AppData\Roaming\Typora\typora-user-images\image-20230824164549223.png)]](https://img-blog.csdnimg.cn/7b683faacda6440f82531c2a8e25c60f.png)
这使得整个过程不存在反射,极大提高了速度。
附上原图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t9XWQdLg-1692870508703)(C:\Users\沧翎\Documents\Tencent Files\3139086691\FileRecv\未命名文件.png)]](https://img-blog.csdnimg.cn/c6aaad73b8d24bfe977d61bc4c58da5a.png)
缺陷:
-
字符串的存储我们需要自己写一个常量池
-
在嵌套的情况下,我们需要知道嵌套的类有多大,所以不建议嵌套原生的类,最好是嵌套同样带注解的类。
缺陷: -
字符串的存储我们需要自己写一个常量池
-
在嵌套的情况下,我们需要知道嵌套的类有多大,所以不建议嵌套原生的类,最好是嵌套同样带注解的类。