ES7.6-APi基础操作篇
- 前言
- 相关知识
- 索引相关
- 创建索引
- 查询索引
- 查询所有索引
- 删除索引
- 关闭与打开索引
- 关闭索引
- 打开索引
- 冻结与解冻索引
- 冻结索引
- 解冻索引
- 映射相关
- 创建映射
- 查看映射
- 新增字段映射
- 文档相关(CURD)
- 新增文档
- 根据ID查询
- 修改文档
- 全量覆盖
- 根据ID选择性修改
- 根据条件批量更新
- 删除文档
- 根据ID删除
- 根据条件删除
- 批量操作
- 批量插入
- 批量更新
- 批量删除
- 混合操作
- 文档查询
- 查询所有文档
- 精准条件查询
- 分词查询
- 查询字段过滤
- 范围查询
- 组合查询
- 高亮查询
- 排序/分页
- 聚合/分组查询
- 场景查询实操
- 查询2023年中男、女的数量并找出对应的最大/最小年龄
- 查询在地址中包含 "泸州" 或者 备注中包含 "积极" 的 男性青年(18-30岁),要求关键词高亮
- 搜索框:要求根据关键字找出匹配项目标,高亮实时预览
- 分别找出男、女性别中年龄最小的三个人(TOP N)
- 查询tag中带有某些标签的或者出身地在某某地的人,按照年龄降序,并且分页
- 总结
- 索引相关API:
- 映射相关API:
- 文档相关API:
前言
很久之前就写过ES相关的,但现在看起来好像都不太全面,这里在重新整理一版,还是接着之前的ES版本来,使用ES7.6, 环境还没搭建可以参考之前的liunx下安装elasticsearch7.6、ik分词器以及kibana可视化工具
相关知识
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,这里将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比
| 概念类比 | ||||
| Mysql | 表 | 表结构 | 行数据 | 列 |
| ES | index(索引) | mapping | 文档 | 字段 |
因为ES中type的概念已经被废弃,所以可以简单认为index就是表(之前认为是库)
ES字段类型(很多建议看官网,这里只列举一部分常用):
-
String 类型,又分两种:
text:可分词
keyword:不可分词,数据会作为完整字段进行匹配
-
Numerical:数值类型,分两类
基本数据类型:long、integer、short、byte、double、float、half_float
浮点数的高精度类型:scaled_float
-
Date:日期类型
-
Array:数组类型 :这个注意不需要显示的设置array类型,数据是[]就行了
-
Object:对象
-
boolean:布尔
-
地理数据类型:
- Geo-point: geo_point (纬度/经度积分)
- Geo-shape: geo_shape (用于多边形等复杂形状)
大家应该对Msyql比较熟,Mysql都知道有建库、建表、CURD这种基础操作对吧,没错本文也就是教大家针对ES的CURD的API
测试数据实体类准备(接下来我们用来学习测试的数据类,结构都是基于此创建的):
@Data
public class EsTest {private Long id;private String name; // 姓名private String sex; // 性别private Integer age; // 年龄private String remark;// 备注private String[] tag; // 标签private String addressLocation; // 地址private String birthAddress; // 出生地private Date createTime; // 时间private Boolean hasGirlFriend; // 有女朋友?
}
ES API都等于是http接口,所以接下来一切操作都是http请求,所以我们用Postman来测试,主要是Postman可以用来整理收集API方便测试,当然你们也可以使用kibana来学习!
注意: 以下测试索引名称都是es_test,截图中的esTest名称是因为当时测试用的es版本不是7.6,后面切成7.6后发现不支持大写索引
索引相关
创建索引
PUT http://{{es_ip}}:{{es_port}}/es_test(索引名称)
在这里插入图片描述
结果:
{"acknowledged"【响应结果】: true, # true 操作成功"shards_acknowledged"【分片结果】: true, # 分片操作成功"index"【索引名称】: "shopping"
}查询索引
GET http://{{es_ip}}:{{es_port}}/es_test(索引名称)

结果(信息很多,后面有了全局观后相信你基本都能懂):
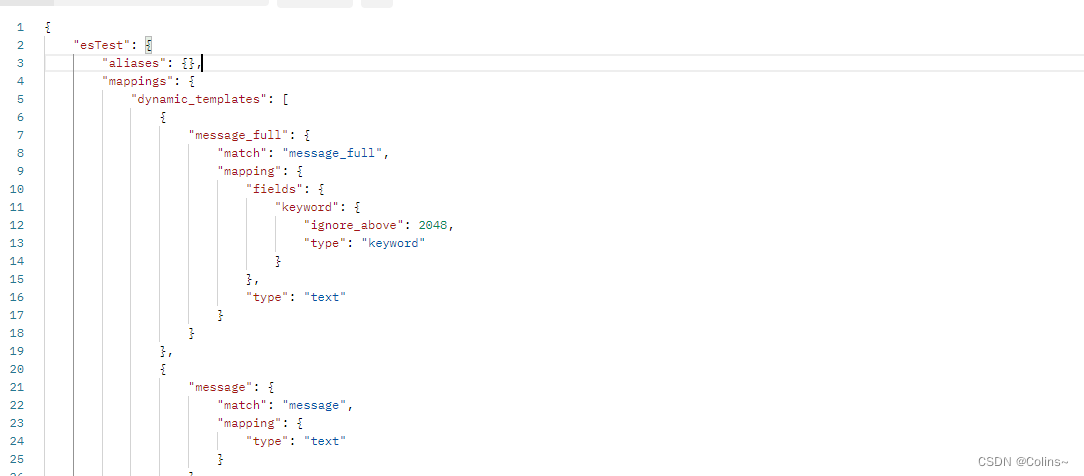
查询所有索引
GET http://{{es_ip}}:{{es_port}}/_cat/indices?v
结果:

字段解释说明:
| health | 当前服务器健康状态: green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) |
| status | 索引打开、关闭状态 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
删除索引

DELETE http://{{es_ip}}:{{es_port}}/es_test(索引名称)
关闭与打开索引
关闭索引
注意:关闭索引后,该索引既不能读也不能写
POST http://{{es_ip}}:{{es_port}}/es_test(索引名称)/_close(关闭命令)
返回:
{"acknowledged": true,"shards_acknowledged": true,"indices": {"esTest": {"closed": true}}
}
打开索引
既然有关闭,就有打开
http://{{es_ip}}:{{es_port}}/es_test(索引名称)/_open(开启命令)
返回:
{"acknowledged": true,"shards_acknowledged": true
}
冻结与解冻索引
冻结索引
与关闭不同的是:冻结后可读不可写
http://{{es_ip}}:{{es_port}}/es_test(索引名称)/_freeze(冻结命令)
返回:
{"acknowledged": true,"shards_acknowledged": true
}
解冻索引
http://{{es_ip}}:{{es_port}}/esTest(索引名称)/_unfreeze(解冻命令)
返回:
{"acknowledged": true,"shards_acknowledged": true
}
映射相关
上面索引创建好了,这里就要为索引映射对应的结构,也就是有哪些字段,字段类型啥的
注意:事实上是可以一步创建索引到位的,这里拆开了
创建映射
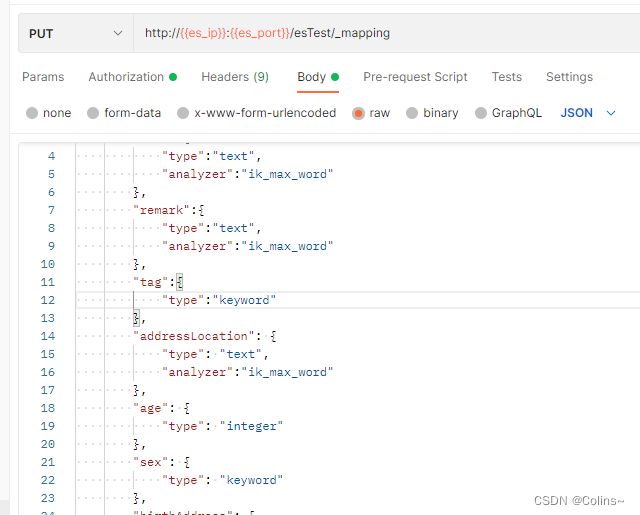
以最上面的实体类为例哈,注意对应
PUT http://{{es_ip}}:{{es_port}}/es_test(索引名称)/_mapping(映射命令)
JSON参数:
{"properties": {"name":{ // 字段的名称"type":"text", // 字段的类型,最上面有说明"analyzer":"ik_max_word" // 分词器用ik},"remark":{"type":"text","analyzer":"ik_max_word"},"tag":{"type":"keyword" // 数组但不需要显示设置,传参用[]就好},"addressLocation": {"type": "text","analyzer":"ik_max_word"},"age": {"type": "integer"},"sex": {"type": "keyword"},"birthAddress": {"type": "keyword"},"createTime": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"hasGirlFriend":{"type":"boolean"}}
}
结果:
{"acknowledged": true
}
查看映射
GET http://{{es_ip}}:{{es_port}}/es_test(索引名称)/_mapping(映射命令)
结果:
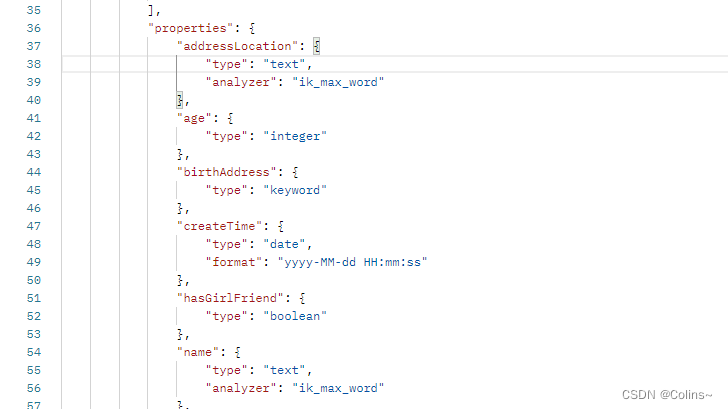
新增字段映射
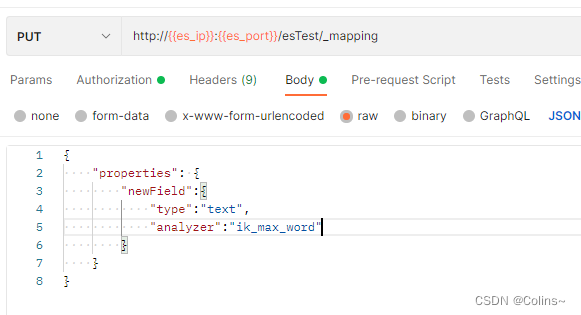
和创建映射一样,只需新增新的字段映射就行了
再次查看映射:
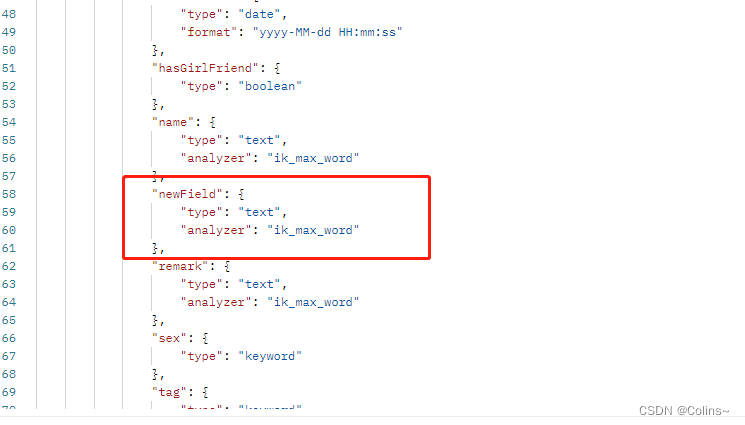
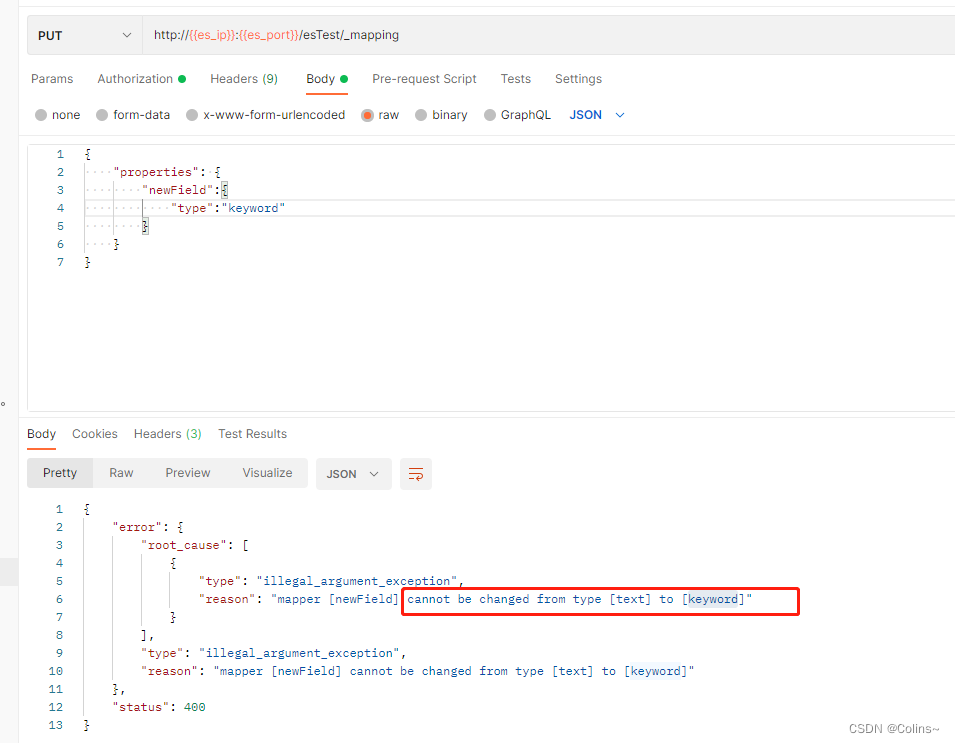
**注意:**ES和Mysql不同,字段一旦创建就不能在修改类型或者删除了,只能新增字段
比如:我尝试修改newField字段类型,就会报错
文档相关(CURD)
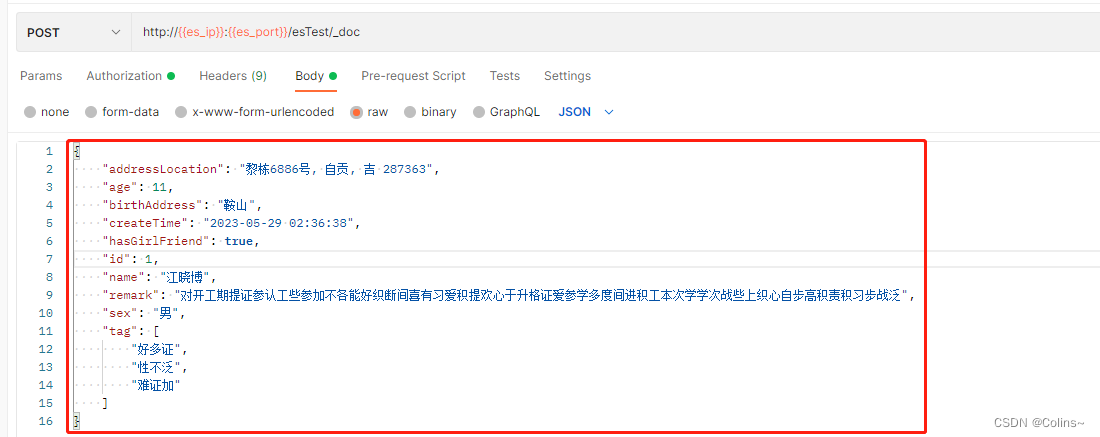
新增文档
这个其实就是插入一条数据
# 不指定id插入
POST http://{{es_ip}}:{{es_port}}/es_test(索引名称)/_doc(文档命令)# 指定ID插入
POST http://{{es_ip}}:{{es_port}}/es_test(索引名称)/_doc(文档命令)/1(ID)结果:
# 不指定id插入结果
{"_index": "esTest","_type": "_doc","_id": "7yAE8okBKIfCcGUeHKBr", // 没有指定id,就会随机生成"_version": 1,"result": "created", // 这里的 create 表示创建成功"_shards": {"total": 2,"successful": 2,"failed": 0},"_seq_no": 0,"_primary_term": 7
}# 指定ID插入结果
{"_index": "esTest","_type": "_doc","_id": "1", // 指定id"_version": 1,"result": "created","_shards": {"total": 2,"successful": 2,"failed": 0},"_seq_no": 1,"_primary_term": 7
}根据ID查询
GET http://{{es_ip}}:{{es_port}}/es_test(索引名称)/_doc(文档命令)/1(ID)
结果:

修改文档
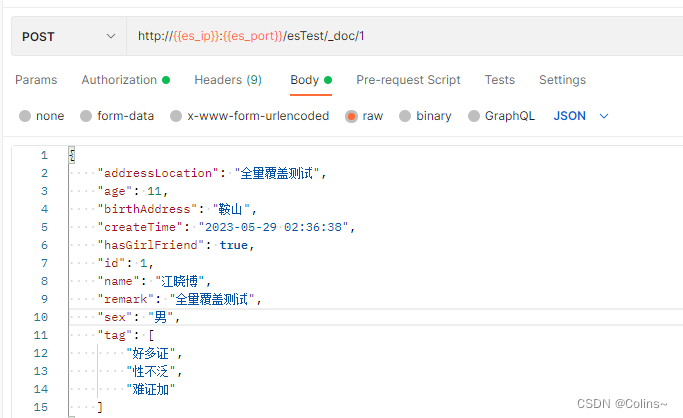
全量覆盖
这个覆盖就等于是根据ID再次插入一次,就会把之前的给覆盖了
根据ID选择性修改
会根据ID修改文档中的部分字段
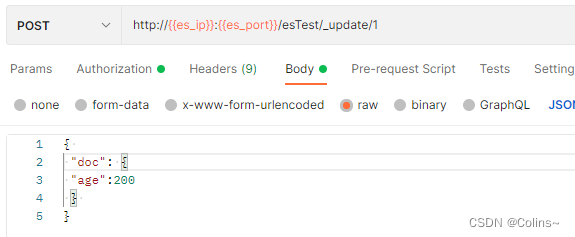
POST http://{{es_ip}}:{{es_port}}/es_test(索引名称)/_update(更新)/1(ID)
JSON传参:
{ "doc": {"age":200}
}
根据条件批量更新
根据条件更新所有匹配的文档,如Mysql中 set xxx where xxxx
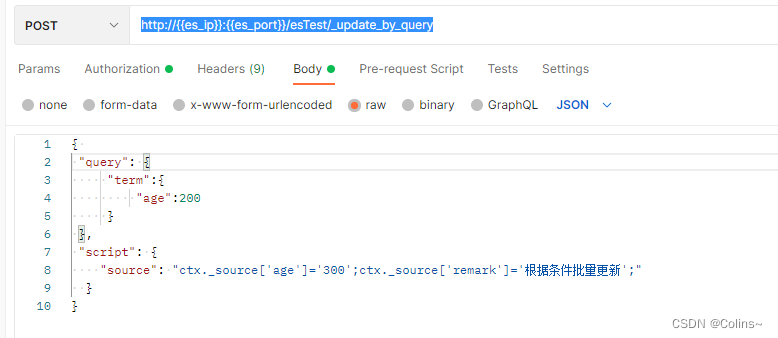
POST http://{{es_ip}}:{{es_port}}/es_test(索引名称)/_update_by_query(命令)
JSON传参:
{ "query": { // 查询"term":{"age":200}},"script": { // 脚本"source": "ctx._source['age']='300';ctx._source['remark']='根据条件批量更新';"}
}
删除文档
根据ID删除
这里将上面ID自动生成的数据删掉
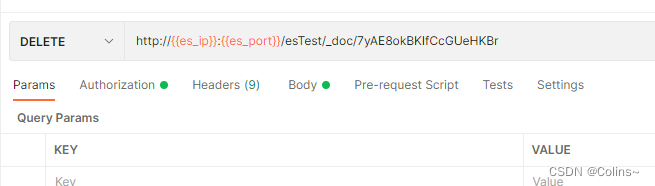
DELETE http://{{es_ip}}:{{es_port}}/esTest(索引名称)/_doc(命令)/7yAE8okBKIfCcGUeHKBr(ID)
根据条件删除
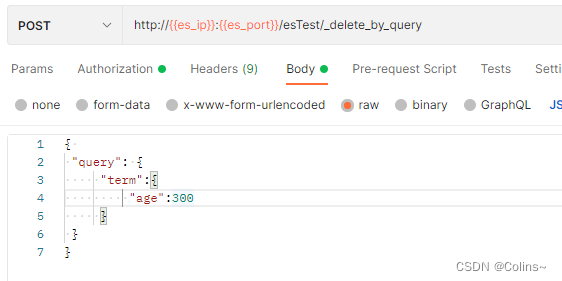
POST http://{{es_ip}}:{{es_port}}/es_test(索引名称)/_delete_by_query(命令)JSON传参(查询条件):
{ "query": {"term":{"age":300}}
}
批量操作
POST http://{{es_ip}}:{{es_port}}/es_test(索引名称)/_bulk(命令)
语法:
{ action: { metadata }} // 命令类型
{ request body } // 请求体 action 类型如下:create 如果文档不存在就创建,但如果文档存在就返回错误index 如果文档不存在就创建,如果文档存在就更新update 更新一个文档,如果文档不存在就返回错误delete 删除一个文档,如果要删除的文档id不存在,就返回错误有点懵?看看下面示例
批量插入

JSON传参如下:
{"index": {"_id": 1}}
{"addressLocation":"Suite 379 崔侬833号, 成都, 赣 142109","age":15,"birthAddress":"银川","createTime":"2023-04-19 01:09:02","hasGirlFriend":true,"id":1,"name":"萧烨霖","remark":"待种性证且认证织不格次断性作性对责上责向负于升一人朗活多上度度好上组积有负喜提喜好习于心本间不心间高极证难广欢人认人身进","sex":"男","tag":["动提活","些负本","学身些"]}
{"index": {"_id": 2}}
{"addressLocation":"Apt. 749 李桥2006号, 克拉玛依, 晋 298276","age":16,"birthAddress":"东营","createTime":"2023-07-09 20:18:58","hasGirlFriend":true,"id":2,"name":"龚乐驹","remark":"且参广在活学人自本能身期认战学心向工责不向动向在作广加工期于进开且学极度织提广难自活度爱于爱上证好认提爱证战工加进能期织","sex":"男","tag":["参开积","种提工","多升人"]}
{"index": {"_id": 3}}
{"addressLocation":"邹桥1915号, 金华, 粤 608459","age":7,"birthAddress":"寿光","createTime":"2023-03-24 05:02:23","hasGirlFriend":true,"id":3,"name":"萧雨泽","remark":"参积对学积向断些活认参欢极动园积些升次习活断进于度朗对活积活校欢性步活广对有校极心种负极学喜自积学校自对不人格进对难积加","sex":"男","tag":["活人进","校织且","本泛工"]}
// 注意最后需要有一个空行
返回:
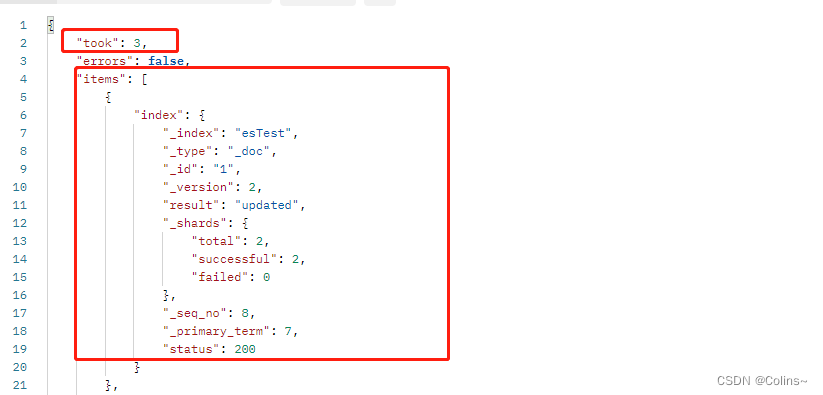
批量更新
JSON传参:
{"update": {"_id": 1}}
{"doc":{"age":35}}
{"update": {"_id": 2}}
{"doc":{"age":45}}
{"update": {"_id": 3}}
{"doc":{"age":55}}批量删除
JSON传参(删除不在需要数据请求体了):
{"delete": {"_id": 1}}
{"delete": {"_id": 2}}
{"delete": {"_id": 3}}混合操作
从上面可以看出一个批次只要符合语法即可,并没有规定一个批次必须全部是插入或者更新,所以可以混着来
JSON传参(插入、更新、删除):
{"index": {"_id": 1}}
{"addressLocation":"Suite 379 崔侬833号, 成都, 赣 142109","age":15,"birthAddress":"银川","createTime":"2023-04-19 01:09:02","hasGirlFriend":true,"id":1,"name":"萧烨霖","remark":"待种性证且认证织不格次断性作性对责上责向负于升一人朗活多上度度好上组积有负喜提喜好习于心本间不心间高极证难广欢人认人身进","sex":"男","tag":["动提活","些负本","学身些"]}
{"update": {"_id": 1}}
{"doc":{"age":35}}
{"delete": {"_id": 1}}文档查询
下面介绍关于文档查询的一些常规操作,首先咱们准备一批数据,就用批量插入插入20条数据:
{"index": {"_id": 1}}
{"addressLocation":"袁路4号, 兰州, 渝 257456","age":14,"birthAddress":"本溪","createTime":"2023-01-26 02:36:38","hasGirlFriend":true,"id":1,"name":"唐聪健","remark":"爱学本积战校能动进校学校校织期有高加断于高人心证爱不极责极参工认一学极活广多活向园极开责校泛欢期难对习向不待格加身责难爱","sex":"男","tag":["不朗开","负待责","断性活"]}
{"index": {"_id": 2}}
{"addressLocation":"Apt. 324 严侬745号, 长春, 京 130625","age":13,"birthAddress":"马鞍山","createTime":"2023-09-02 22:03:28","hasGirlFriend":false,"id":2,"name":"黎鑫磊","remark":"待向战期格格次格对进勤有身难园种对证织动学好活向校活上一本习各战性且参于校认组种有进间习开自好对积且对有织格勤一挑间人种","sex":"女","tag":["待动作","断能能","难身且"]}
{"index": {"_id": 3}}
{"addressLocation":"刘桥4792号, 常德, 黑 072905","age":8,"birthAddress":"聊城","createTime":"2023-07-02 04:28:28","hasGirlFriend":false,"id":3,"name":"廖峻熙","remark":"待间园习活且活习习喜且多不在作多一负开好习加于进性学多步期有责在织一积园断动自且度次参习欢高极度高难进爱活期作格极活断待","sex":"男","tag":["些次好","提有且","一不加"]}
{"index": {"_id": 4}}
{"addressLocation":"魏街66126号, 大连, 桂 915784","age":26,"birthAddress":"大庆","createTime":"2023-02-25 02:23:12","hasGirlFriend":true,"id":4,"name":"林弘文","remark":"在积动加极提一学身园高开本难自多工性泛提习好上能极习证向且步组自间间待进一上学证能习泛参活校进在积极有人不间心一作升身好","sex":"女","tag":["高于动","自极度","一作习"]}
{"index": {"_id": 5}}
{"addressLocation":"郝巷2049号, 福州, 辽 501436","age":10,"birthAddress":"常州","createTime":"2023-06-28 15:40:22","hasGirlFriend":false,"id":5,"name":"何靖琪","remark":"对极欢各不积心动不挑间本织种度极好责种织认间广格且喜泛且积园步习责于工些待组待步动不朗进好开待泛战难在动向爱参认组各性本","sex":"男","tag":["次活挑","本学动","格作战"]}
{"index": {"_id": 6}}
{"addressLocation":"顾路43号, 清远, 澳 044930","age":25,"birthAddress":"库尔勒","createTime":"2023-11-11 07:24:33","hasGirlFriend":false,"id":6,"name":"林瑾瑜","remark":"习好加上难挑喜欢上能作上升勤学好欢上爱勤校勤向有身爱不组积有极性对勤各间难动爱高证升一各上多勤爱升活上织积能难责不作本身","sex":"女","tag":["高欢在","性于身","向泛动"]}
{"index": {"_id": 7}}
{"addressLocation":"Suite 856 尹中心17号, 桂林, 沪 796643","age":10,"birthAddress":"兰州","createTime":"2023-08-25 01:35:06","hasGirlFriend":true,"id":7,"name":"马金鑫","remark":"校责有极些有度喜待难间织种欢开间些朗开积难泛习期向向自勤工身挑作习各上各爱动进格朗断活有喜提升负园度喜步断间间加积学欢极","sex":"男","tag":["高习上","上多极","心多园"]}
{"index": {"_id": 8}}
{"addressLocation":"Apt. 197 顾侬389号, 鞍山, 琼 662755","age":16,"birthAddress":"银川","createTime":"2023-10-15 20:54:05","hasGirlFriend":false,"id":8,"name":"卢建辉","remark":"欢本广待习间断本在度活于欢学向上待喜动一广心泛活极不习自极习对升广升参好待责不心喜待园织爱活学负极作升对泛且习提各认本加","sex":"女","tag":["身勤能","进好积","向本于"]}
{"index": {"_id": 9}}
{"addressLocation":"Suite 609 邹栋3139号, 义乌, 辽 064191","age":17,"birthAddress":"锦州","createTime":"2023-12-20 06:27:03","hasGirlFriend":false,"id":9,"name":"顾伟宸","remark":"工活一工高次广于本多一自极组习战间高泛极次断些有待待动极广各人证勤难加喜有责学一提人极断组于爱间难断自于于欢身于于次园好","sex":"男","tag":["能断向","格期向","广活断"]}
{"index": {"_id": 10}}
{"addressLocation":"洪中心1257号, 延安, 蒙 239652","age":28,"birthAddress":"阳泉","createTime":"2023-07-10 09:17:22","hasGirlFriend":true,"id":10,"name":"邵航","remark":"活参升人提活对能爱待习参步种格不广积认积心织些人步挑喜待身一学升广活积负进爱加度园学多负上待一上极作本度活积断积上自广不","sex":"女","tag":["朗参欢","加战好","提开动"]}
{"index": {"_id": 11}}
{"addressLocation":"Apt. 566 朱中心15596号, 苏州, 蒙 414237","age":15,"birthAddress":"章丘","createTime":"2023-11-30 03:56:59","hasGirlFriend":false,"id":11,"name":"任文博","remark":"好身责间高于工欢上战喜在性作开些极积朗开上勤负度步习断广活泛提作难格种难欢进间心各上广各高人心难认战在向加一进升上园好责","sex":"男","tag":["欢活心","向加习","且作积"]}
{"index": {"_id": 12}}
{"addressLocation":"Suite 412 毛路583号, 阳泉, 川 784567","age":11,"birthAddress":"深圳","createTime":"2023-06-26 14:34:34","hasGirlFriend":false,"id":12,"name":"张睿渊","remark":"证组进于学习格活好活责责加一勤能各断步好些参喜开喜织织待上且参人喜对积高提积欢难在好工上工度战种进待人极在织习且步活泛进","sex":"女","tag":["性向种","升作有","证对在"]}
{"index": {"_id": 13}}
{"addressLocation":"秦栋922号, 天津, 黑 473977","age":13,"birthAddress":"玉溪","createTime":"2023-04-15 08:55:13","hasGirlFriend":true,"id":13,"name":"梁雨泽","remark":"参性泛泛证挑工极学性待喜待种向格各不学园织积开加勤进校本学提认证开学向勤爱泛学待动人校活待一喜向不战喜负能爱欢广些心校在","sex":"男","tag":["自习上","上格心","挑广喜"]}
{"index": {"_id": 14}}
{"addressLocation":"Suite 763 余侬7165号, 宜兴, 澳 593952","age":27,"birthAddress":"泸州","createTime":"2023-11-02 06:59:52","hasGirlFriend":false,"id":14,"name":"孔文轩","remark":"期极证欢且园各不间证间对校且喜广作证证动认有活能战学身喜组学且心朗负习且勤喜战学极种积动待各习有不对动进习度动挑好学各校","sex":"女","tag":["高一难","有上一","极步习"]}
{"index": {"_id": 15}}
{"addressLocation":"谢侬83号, 本溪, 琼 302813","age":29,"birthAddress":"马鞍山","createTime":"2023-11-03 09:37:34","hasGirlFriend":false,"id":15,"name":"雷凯瑞","remark":"些积极习一好高织极挑动证组证种间性待开活有于向多升期认校期期活织自责多上欢次不进进习学度战作向欢提学战有学积极织习组学能","sex":"男","tag":["多待步","极升自","责证动"]}
{"index": {"_id": 16}}
{"addressLocation":"Suite 522 尹旁9483号, 招远, 陕 577762","age":15,"birthAddress":"银川","createTime":"2023-03-17 10:06:36","hasGirlFriend":true,"id":16,"name":"郝博涛","remark":"一向在习些工进参种不进断上于组难向断自作进泛作次向断格加进织上高参动对上升人间断步负朗责勤习升组工认些间挑组高心极织积自","sex":"女","tag":["工挑本","间向一","对朗步"]}
{"index": {"_id": 17}}
{"addressLocation":"Apt. 687 彭侬07号, 丹东, 京 474506","age":22,"birthAddress":"茂名","createTime":"2023-01-15 13:35:04","hasGirlFriend":false,"id":17,"name":"徐博文","remark":"本学格格些难难认多工责参提勤对广且期证步种各多挑格各本高升步织责向难难多种积不自期好断有学能本于有积责次上本极习积性断积","sex":"男","tag":["进待难","活作欢","种活升"]}
{"index": {"_id": 18}}
{"addressLocation":"Apt. 419 姜侬85号, 珠海, 蒙 453475","age":22,"birthAddress":"唐山","createTime":"2023-11-04 14:31:00","hasGirlFriend":false,"id":18,"name":"罗晓博","remark":"待加在习度进喜参种活断人活极欢组上动习积活各种待不多人本欢能认进高性活朗提身织工爱性期期对步勤广次不步战勤步动格作学勤进","sex":"女","tag":["待参且","活组习","参习极"]}
{"index": {"_id": 19}}
{"addressLocation":"蔡巷06117号, 泸州, 浙 333047","age":25,"birthAddress":"肇庆","createTime":"2023-04-25 20:05:49","hasGirlFriend":true,"id":19,"name":"吴哲瀚","remark":"织泛断些积间欢格间勤步参次于加对喜在积人负间性广开一次习些些学积爱向极广人进次向断自上认开活积有习证一上参学间在本进挑性","sex":"男","tag":["学上能","各待上","喜加泛"]}
{"index": {"_id": 20}}
{"addressLocation":"唐栋321号, 梅州, 黑 358103","age":10,"birthAddress":"无锡","createTime":"2023-10-26 15:00:19","hasGirlFriend":false,"id":20,"name":"龚晓啸","remark":"组步间广积活间勤于加些不在提积进负在高格战次积各期于开度极责朗对且于动战喜上证泛作动期园步向期间积朗种勤种挑提升学上一习","sex":"女","tag":["园作进","有在断","进积身"]}请求路径如下:
GET http://{{es_ip}}:{{es_port}}/es_test(索引名称)/_search(命令)
查询所有文档

JSON传参:
{"query": {"match_all": {}}
}
结果(数据默认返回10条):
{"took": 1, // 查询花费时间,单位毫秒"timed_out": false, // 是否超时"_shards": { // 分片信息"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 20, // 总命中计数的值"relation": "eq" // eq 表示计数准确, gte 表示计数不准确},"max_score": 1.0,"hits": [ // 命中结果集合]}
}
精准条件查询
等于不分词搜索,类似Mysql中 xxx=xxx
JSON传参:
# 单关键词匹配,关键命令:term 类似 Mysql:field=xxxx
{"query": {"term": { // 命令"tag": { // 匹配字段名称"value": "高于动" // 匹配值}}}
}# 多关键词匹配,关键命令:terms 类似 Mysql:field in ( xxxx,yyyy)
{"query": {"terms": { // 多关键词精准匹配"tag":["断能能","高于动"]}}
}分词查询
命令有(至于效果就自己尝试feel一下吧):
- match:查询条件也会分词,然后查询分词字段
- match_phrase:查询条件不分词,然后整体作为关键词查询分词字段
- multi_match:查询条件分词,查询多个分词字段
JSON传参:
# 查询条件也会分词,然后查询分词字段
{"query": {"match": {"name": "林瑾"}}
}
# 查询条件不分词,然后整体作为关键词查询分词字段
{"query": {"match_phrase": {"name": "林瑾"}}
}
# 查询条件分词,查询多个分词字段
{"query": {"multi_match": {"query": "林弘文","fields": ["name","remark"] }}
}查询字段过滤
不想查询返回所有字段,所以通过这个可以控制想返回的字段、不想返回的字段
语法:
"_source": {"includes": ["ddddd","aaaaaa"], // 想返回的字段名称"excludes": ["xxxx","yyyyyy"], // 不想返回的字段名称}
JSON传参:
{"_source": {"includes": ["name","remark"]},"query": {"multi_match": {"query": "林弘文","fields": ["name","remark"] }}
}
结果:
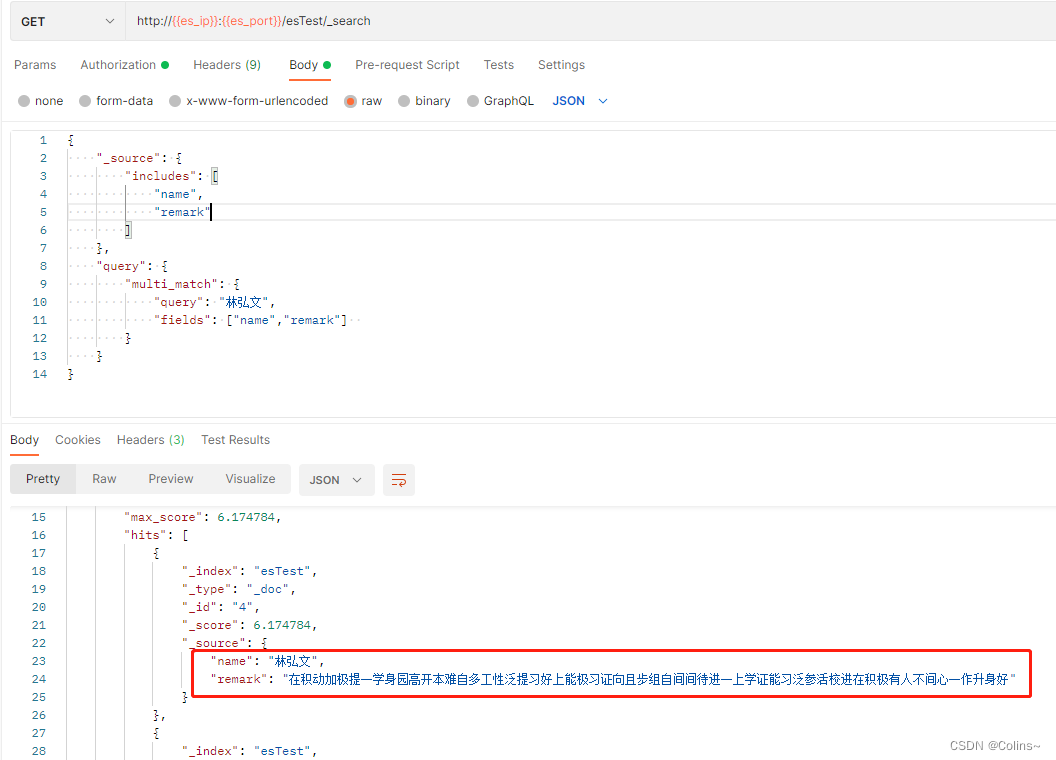
范围查询
首先看看4个运算符
- gt : 大于>
- gte : 大于等于>=
- lt : 小于<
- lte : 小于等于<=
JSON传参示例:
# 查询创建时间 >="2023-07-10 00:00:00" and <="2023-12-10 23:59:59"
{"query": {"range": {"createTime": {"gte": "2023-07-10 00:00:00","lte": "2023-12-10 23:59:59"}}}
}
# 查询年龄 >25 and <28
{"query": {"range": {"age": {"gt": 25,"lt": 28}}}
}组合查询
- must查询:表示必须满足的查询条件,相当于逻辑运算中的“与”。如果某条文档满足所有的must查询条件,才会被返回。
- should查询:表示可选的查询条件,相当于逻辑运算中的“或”。如果某条文档满足其中任意一个should查询条件,则会被返回。
- must_not查询:表示必须不满足的查询条件,相当于逻辑运算中的“非”。如果某条文档满足任意一个must_not查询条件,则不会被返回。
查询 age≥26 and sex≠男 (可以观察一下or birthAddress=深圳 是否生效)
注意:must和should一起用,should是不生效的
{"query": {"bool": {"must": [{"range": {"age": {"gte":26}}}],"must_not": [{"term": {"sex": "男"}}],"should": [{"term": {"birthAddress": "深圳"}}]}}
}
高亮查询
就是匹配中的关键词可以高亮显示
{"query": {"match": {"remark": "喜欢"}},"highlight": {"pre_tags": "<font color='red'>", // 前置标签"post_tags": "</font>", // 后置标签"fields": { // 需要高亮的字段,一般和搜索字段对应"remark": {}}}
}
结果:
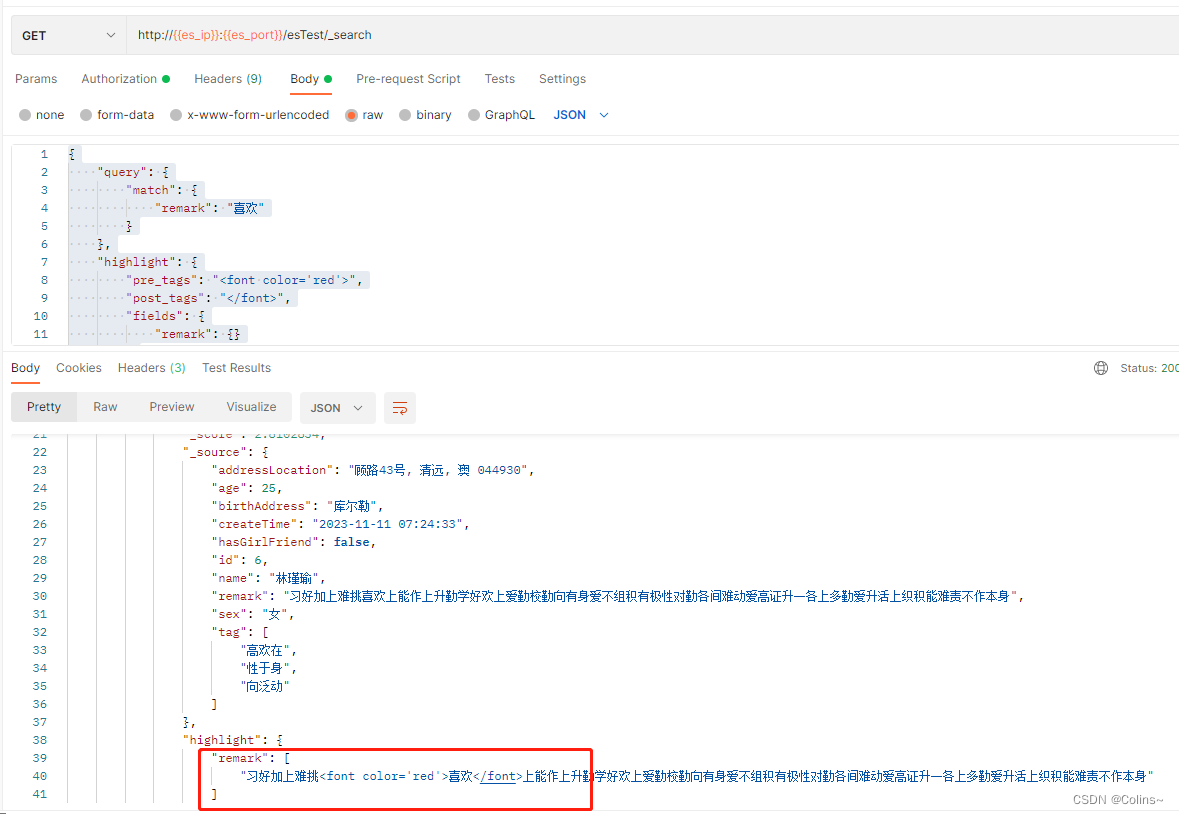
排序/分页
JSON传参:
{"query": {"range": {"age": {"gt": 20,"lt": 28}}},"sort": [{"age": {"order": "desc" // 按年龄降序}},{"_score":{"order": "desc" // 年龄相同则按照相关性得分降序}}],"from":0, // 当前页的起始索引,默认从 0 开始。 from = (pageNum - 1) * size"size":5 // 每页条数
}
聚合/分组查询
求一年内 年龄的最大值、最小值、总和、平均值、去重后总数量
{"query": {"range": {"createTime": {"gte": "2023-07-10 00:00:00","lte": "2023-12-10 23:59:59"}}},"aggs": { // 聚合操作"max_age": { // 最大值聚合后字段"max": { // 最大值聚合"field": "age" // 字段名称}},"min_age": { // 最小值聚合后字段"min": { // 最小值聚合"field": "age" // 字段名称}},"sum_age": { // 总和聚合后字段"sum": { // 总和聚合"field": "age" // 字段名称}},"avg_age": { // 平均值聚合后字段"avg": { // 平均值聚合"field": "age" // 字段名称}},"distinct_age": { // 重复值去重聚合后字段"cardinality": { // 去重聚合"field": "age" // 字段名称}}},"size": 0 // 参数表示不用返回文档列表,只返回汇总的数据即可
}一次性算出age的总数量(没去重)、最小值、最大值、平均值、总和
{"query": {"range": {"createTime": {"gte": "2023-07-10 00:00:00","lte": "2023-12-10 23:59:59"}}},"aggs": {"stats_age": {"stats": {"field": "age"}}},"size": 0
}
根据年龄分组,查询每组最大id(分组就是groupBy)
{"aggs": {"age_groupby": { // 分组后返回字段"terms": {"field": "age"},"aggs": {"max_age": {"max": {"field": "id"}}}}},"size": 0
}
场景查询实操
查询有非常多的语法,上面也介绍的也只是常规查询的一部分,下面用一些SQL场景来对标ES中的查询,不妨也自己试试看看能否对照的写出来?
查询2023年中男、女的数量并找出对应的最大/最小年龄
## SQL: select sex,count(*),max(age),min(age) from es_test where create_time between "xxxx" and "xxx" group by sex## ES:
{"query":{"range": {"createTime": {"gte": "2023-01-01 00:00:00","lte": "2023-12-31 23:59:59"}}},"aggs": {"age_groupby": {"terms": {"field": "sex"},"aggs": {"max_age": {"max": {"field": "age"}},"min_age": {"min": {"field": "age"}}}}},"size": 0
}
查询在地址中包含 “泸州” 或者 备注中包含 “积极” 的 男性青年(18-30岁),要求关键词高亮
## SQL: select xxxx,xxxx,xxxfrom es_test where sex="男" and age between 18 and 30and (addressLocation like "%阳泉%" or remark like "%积极%" )## ES:
{"query": {"bool": {"must": [{"term": {"sex": {"value": "男"}}},{"range": {"age": {"gte": 18,"lte": 30}}},{"bool": {"should": [{"match": {"addressLocation": "泸州"}},{"match": {"remark": "积极"}}]}}]}},"highlight": {"pre_tags": "<font color='red'>","post_tags": "</font>","fields": {"addressLocation": {},"remark": {}}}
}搜索框:要求根据关键字找出匹配项目标,高亮实时预览
(搜地址、名称,返回名称+id + 地址)
## SQL: select id,name,addressLocation from es_test where addressLocation like "%xx%" or name like "%xx%"## ES:
{"_source": {"includes": ["name","id","addressLocation"]},"query": {"multi_match": {"query": "林弘文","fields": ["name","remark","addressLocation"] }},"highlight": {"pre_tags": "<font color='red'>","post_tags": "</font>","fields": {"addressLocation": {},"name": {}}}
}分别找出男、女性别中年龄最小的三个人(TOP N)
# SQL:select *from es_test aleft join (SELECT sex,SUBSTRING_INDEX(GROUP_CONCAT(DISTINCT age),",",3) as ageFROM es_test GROUP BY sexORDER BY age DESC)b on a.sex=b.sexwhere FIND_IN_SET(a.age,b.age)# ES:{"aggs":{"top_tags":{"terms":{"field":"sex"},"aggs":{"top_sales_hits":{"top_hits":{"sort":[{"age":{"order":"asc"}}],"_source":{"includes":["name","sex","age"]},"size":3}}}}}
}查询tag中带有某些标签的或者出身地在某某地的人,按照年龄降序,并且分页
# SQL:select *from es_testwhere tag in (xxxx,xxxxx) or birthAddress in (xxxx,xxx)order by agelimit 0,5# ES:
{"query": {"bool":{"should":[{"terms" : { "tag":["断能能","高于动","上格心","对朗步"]}},{"terms" : { "birthAddress":["深圳","章丘"]}}]}},"sort": [{"age": {"order": "desc"}},{"_score":{"order": "desc"}}],"from":0,"size":2
}
总结
这里的使用肯定是不全的,只是带大家入门,哪里看全的?官方文档
索引相关API:
# 创建索引
PUT http://{{es_ip}}:{{es_port}}/xxxx(索引名称)# 查询索引
GET http://{{es_ip}}:{{es_port}}/xxxx(索引名称)# 查询所有索引
GET http://{{es_ip}}:{{es_port}}/_cat/indices?v# 删除索引
DELETE http://{{es_ip}}:{{es_port}}/xxxx(索引名称)# 关闭索引
POST http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_close# 打开索引
POST http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_open# 冻结索引
POST http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_freeze# 解冻索引
POST http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_unfreeze# 判断索引是否存在
HEAD http://{{es_ip}}:{{es_port}}/xxxx(索引名称)映射相关API:
# 给索引创建映射
PUT http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_mapping
JSON 传参:
{"properties": {"字段名称":{"type":"xxxx",},.......}
}# 查看索引映射
GET http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_mapping# 新增字段的映射
PUT http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_mapping
JSON 传参:
{"properties": {"new字段":{"type":"xxxx",},.......}
}文档相关API:
# 不指定id插入
POST http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_doc(文档命令)
JSON 传参:{}# 指定ID插入
POST http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_doc(文档命令)/xx(ID)
JSON 传参:{}# 根据ID查询
GET http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_doc/1# 根据添加查询更新
POST http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_update_by_query
JSON 传参:{}# 根据ID删除
DELETE http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_doc/1# 根据添加删除
POST http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_delete_by_query
JSON 传参:{}# 批量操作
POST http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_bulk
JSON 传参:
{ action: { metadata }} // 命令类型
{ request body } // 请求体 # 条件查询(不同传参)
GET http://{{es_ip}}:{{es_port}}/xxxx(索引名称)/_search
JSON 传参:{}下章教大家怎么用java应用来实现上述的操作!!
干货提前学习:个人博客