前言
虽然不经常用到协程,但是也不能谈虎色变。同时,在有些场景,协程会起到一种不可比拟的作用。所以,了解它,对于一些功能,也会有独特的思路和想法。
协程
概念
关于进程和线程的概念就不多说。
那么从多线程的角度来看,协程和线程有点类似:拥有自己的栈,局部变量和指令指针,又和其他协程共享全局变量等一切资源。
主要的区别在:一个多线程程序可以并行运行多个线程,而协程却要彼此协作运行。
什么是协作运行?
也就是任意指定的时刻,只能有一个协程运行。
很懵对不对?
层级调用和中断调用
所有的语言中,都存在层级调用,比如A调用了B,B在执行过程中又去调用C,C执行之后,返回到B,B执行完毕之后,返回到A,最后A执行完毕。
这个过程就像栈一样,先进后出,依次从栈顶执行。所以,它也叫调用栈。
层级调用的方式是通过栈来实现的。
中断调用,就是我在A函数中可以中断去调用B函数,函数B中可以中断去调用A。
比如
function A()print(1)print(2)print(3)
endfunction B()print("a")print("b")print("c")
end
那么如果是中断调用,就可能输出: 1 a b 2 3
协程的优势
其实一句话总结。
拿着多线程百分之一的价钱,干着多线程的事情,还效率贼高。
这样的员工谁不喜欢?
这也是Go语言高并发的原因之一。
怎么理解协程?
左手画圆,右手画方,两个手同时操作,这个叫并行,线程就是干这个事情的。
左手画一笔,切换到右手画一笔,来回交替,最后完成,这叫并发,协程就是为了并发而生。
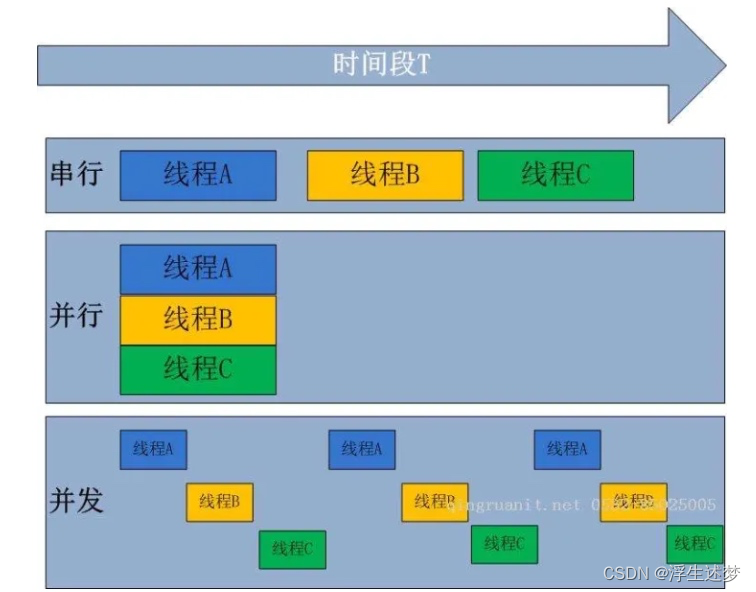
那么线程不能完成协程的事情?
举个例子,一个作业,可以交给两个人完成,这叫并行。创建两个线程就可以了。
那么其中一个人在做事情的时候,突然有人要插入一个比较紧急的事情,这个人就必须停下手中的事情,去处理那个紧急的事情。停下叫阻塞。线程本身是支持阻塞的。
但是这里就有一个问题,不管是创建线程还是切换线程,所带来的成本远远大于用阻塞的方式实现并发,要考虑两个线程之间的数据同步,加锁解锁,临界问题等等。而协程并不需要来回切换。所以,并发的线程越多,使用协程来代替的性能优势就越明显。
所以,可以知道协程不是线程,它的资源是共享的,不需要如同多线程一样加锁来避免读写冲突。
比如创建一个线程栈需要1M,那么协程栈只需要几K,或者几十K。
协程的缺点
协程本质上是单线程,所以它吃不到多核CPU的福利,需要与进程配合才能办到。
然后协程也不是那么好控制,需要写一些代码进行手动控制它的中断调用。
Lua的协程
Lua的协程是非对称协程。
简单来说,非对称就是需要两个函数来控制协程的执行。
Go的协程是对称协程,有兴趣可以去了解下。
再说简单一点就是,非对称协程,需要yield函数来挂起,resum函数来恢复,同时,哪里挂起,就恢复到哪里去。
对称协程,只需要yield一个操作。
简单的例子
理解完这个,就很容易理解Lua的协程代码。即在哪里yield,下次调用resum,就恢复到yield那里,继续执行。
local co = coroutine.create(function()print(1)coroutine.yield()print(2)coroutine.yield()print(3)
end)coroutine.resume(co)
coroutine.resume(co)
coroutine.resume(co)
第一次resume,就是执行协程函数co ,print(1)
第二次resume,就是print(2)
第三次resume,就是print(3)
四种状态
一个协程有四种状态:
- 挂起(suspended)
- 运行(running)
- 正常(normal)
- 死亡(dead)
可以通过函数**coroutine.status(co)**来进行检查协程的状态。
当一个协程创建的时候,它处于一个挂起状态,也就是说,协程被创建,不会自动运行,需要调用函数**coroutine.resume(co)**用来启动或者再启动一个协程的执行,将挂起状态改成运行状态。
当协程中执行到最后的时候,整个协程就停止了,变成了死亡状态。
协程报错
由于协程resume在保护模式下,所有错误都会返回给它,即哪怕协程处于死亡状态,调用coroutine.resume(co),也不会出现任何错误。
同时协程中的错误不容易被发现,所以需要使用xpcall来进行抛出。
lua5.1需要封装一层来达到这个目的
--协程,Lua5.1无法挂C函数,这样进行处理,协程中出问题,会抛出错误
local coroutCanTrowError = function()xpcall(showGetSpecialCollect,__G__TRACKBACK__)
end
self.m_showGetSpecialRune = coroutine.create(coroutCanTrowError)
coroutine.resume(self.m_showGetSpecialRune)
xpcall函数,异常处理函数,是lua强大的异常处理函数,这个以后做分享。
交换数据
lua的协程主要是通过resume-yield来进行数据交换的。
即第一个resume函数会把所有的额外参数传递给协程的主函数。
什么意思呢?
local co = coroutine.create(function(a,b,c)print("co",a,b,c)end)coroutine.resume(co,1,2,3)
resum函数会把参数都传递给协程的主函数。所以这里输出co 1 2 3
local co = coroutine.create(function(a,b,c)print("co",a,b,c)coroutine.yield(a + b,a - b , c + 2)end)print(coroutine.resume(co,1,2,3))
输出就是
co 1 2 3
true 3 -1 5
在yield的时候,会把参数都返回给resume,这里有点拗口。
可以这么理解,yield中的参数就是resum的返回值。当然这里要注意的是,resume的返回值第一个是resume是否成功的标志。
这种类似于
local co = coroutine.create(function(a,b,c)return a - bend)print(coroutine.resume(co,1,2,3))输出 true,-1
也就是协程主函数的返回值都会变成resume的返回值。
是不是觉得有无限可能了?
但是,值得注意的是,虽然这种机制会带来很大的灵活性,但是,使用不好,可能会导致代码的可读性降低。
著名的生产者和消费者
这是协程最经典的例子。
即一个生产函数(从文件读数据),一个消费函数(将读出来的值写入另一个文件)。
function producer()while true do local x = 1send(x)end
endfunction consumer()while true do local x = receive()print(x)end
endlocal list = {}
function send(x)table.insert(list,x)
endfunction receive()if #list > 0 then local a = table.remove(list)return aend
endproducer()
consumer()
会发生什么?
当然,也可以将两个放到不同的线程中去处理,但是这样对于数据量大的时候来说就是个灾难。
协程怎么去实现?感兴趣的可以去了解下。
function eceive (prod) local status, value = coroutine esume(prod)return value
end function send (x) cooutine.yield(x)
end
function poducer()return coroutine.c eate(function () while true do local x = io.read () send (x) end end)
end
function filter(prod)return coroutine.ceate(func () for line= 1, math.huge do local x = receive (prod) x = string.format(%s ”, line, x)send(x)end end )
end function conrumer(prod)while true do local x = receivee(prod) io. write (x ,”\n”) end
end
conrumer(filter(poducer()))
不用担心性能问题,因为是协程,所以任务开销很小,基本上消费者和生产者是携手同行。
应用场景
首先,再重复一遍,协程是并发,不是并行。
有个需求,和我们相关的。
棋盘有4种bonus,停轮之后,每个bouns的效果不一样,比如翻转,比如收集等等,效果执行完毕之后,再进行下一个,直到结束。
这个是很简单的需求,可以用for循环执行。
如果加上,bonus在执行效果中,会有部分等待,或者延迟效果?那么for循环就不能满足,因为在延迟的时候,函数就返回,执行下一个for循环了。
再比如加上,bonus在执行效果中,会牵涉到另外一堆逻辑。
等等。
然后,有人会说,递归也可以实现。
但是,首先得明白一点,递归是个思想,而协程是个机制。两个本质上不是一个东西,更何况,递归会涉及到其他东西。这个等下会说。
递归
递归的含义是:在调用一个函数的过程中,直接或者间接调用了函数本身。
一个很简单的递归就是:
local a = nil
a = function(n)if n == 1 then return 1endprint("a "..n)n = n * a(n - 1)print("b "..n)return n
end
print(a(5))
请问输出什么。
输出
a 5
a 4
a 3
a 2
b 2
b 6
b 24
b 120
120
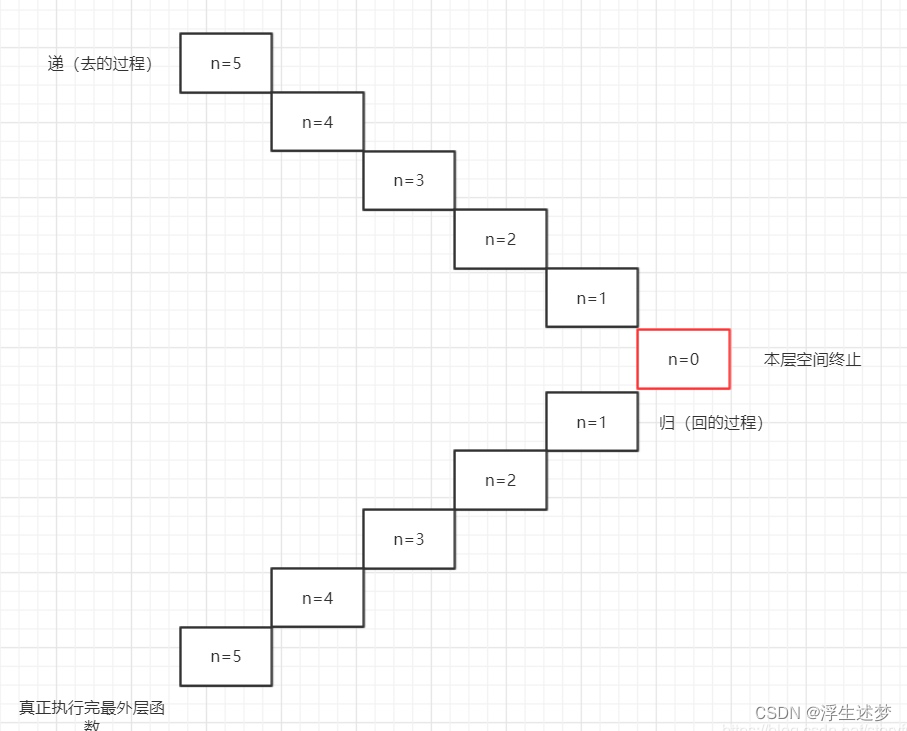
再来温习下递归的特点:
- 原来的基础上不断“向下/向内”开辟新的内存空间。(即每一次的调用都会增加一层栈,每当函数返回的时候,就减少一层栈。)所以,对于递归来说,递归的层次越多,很容易导致栈溢出。这也决定了递归本身的效率不高。
- 递归是暂停阻塞,什么是暂停阻塞呢?也就是递归调用函数的以下部分是不会被执行的,只有返回之后才能执行。
说到这里,不得不说lua这个语言有一个非常不错的优化——尾调用。
尾调用
什么是尾调用呢?
一个函数返回您一个函数的返回值。
是不是有点拗口。
我们看下代码。
function A(x)return B(x)
end
通俗的来说,就是当一个函数调用是另一个函数的最后一个动作的时候,该调用才能算上尾调用。
上面例子中,A调用完B之后,就没有任何逻辑了。这个时候,Lua程序不需要返回函数A所有在得函数,那么程序自然而然就不需要保存任何有关于函数A的栈(stack)信息。
该特性叫“尾调用消除”。
别小看这个特性。
通常,函数在调用的时候,会在内存中形成一个“调用记录”,它保存了调用位置和内部变量等信息。
例如
function A(x)local a = 1local b = B(x)local c = 2return a + b + c
end
在程序运行到调用函数B的时候,会在A的调用记录上方,形成B的调用记录,等到B返回之后,B的调用记录才会消失。那么调用的函数越多,就如同栈一样,依次放到A、B等等的上面,所有的调用记录就形成了调用栈。
那么想象一下,函数A调用B,B调用C,C调用D…会发生什么。
是栈溢出。
栈和堆不一样,栈是系统分配的,也可以说栈是系统预设的空间,堆是自己申请的。所以,当我们的函数调用层次太深,导致保存调用记录的空间大于了系统分配的栈,那么就会导致栈溢出。然后各种莫名其妙的Bug就出现了,比如递归不返回了;比如调用函数不返回了等等。
这个时候,Lua的尾调用消除就起到了关键性作用。它是函数最后一步操作,所以不需要保存外层函数的调用记录,它里面的所有内部变量等信息都不会再用到了,所以就不需要栈空间去保存这些信息。
那么,可能会有人说,那么我在函数尾部调用另一个函数不就可以了么?
并不是。
function A(x)return 1 + B(x)
endfunction C(x)return true and D(x)
end
上面的两个函数就不是尾调用。
函数A中,最后一步不是B函数,而是+运算符
函数C中,最后一步不是D,而是and 运算符
function A(x)if x > 0 then return B(x)endreturn C(x)
end
这样的函数B和函数C才是尾调用。
可能这样觉得没啥,我们做个实验。
function A(x)return 1 + B(x)
end function B(x)return x * 2
endprint(collectgarbage("count"))
for i = 1,1000000 do
--print(A(i))A(i)
end
print(collectgarbage("count"))
输出
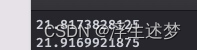
相差:0.09960
那么看下尾调用
function A(x)return B(x,1)
endfunction B(x,y)return x * 2 + y
endprint(collectgarbage("count"))
for i = 1,1000000 do
--print(A(i))A(i)
end
print(collectgarbage("count"))
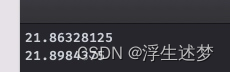
相差是0.035
接近3倍。
可能有人会说,这点性能应该没啥吧。我想说的是,这里只是一个简单的计算,本来保存的数据都不大,如果是实际开发中,需要保存的东西更大了。
尾递归
理解了尾调用,那么我们来看看尾递归
前面也说了,递归依赖栈,非常消耗内存。还有,别以为有些功能就递归几次,就没有什么性能消耗。那谁又能保证在递归的函数中有大量的其他函数调用或者数据处理呢?
毕竟有时候很容易写出,递归函数中调用其他函数,其他函数又调用一堆其他函数这种套娃的代码。
例如,最开始的代码
local a = nil
a = function(n)if n == 1 then return 1endreturn n * a(n - 1)
end
a(5)
这就是一个“不合格”的递归函数。
那么尾递归怎么写呢?
local a = nil
a = function(n,m)if n == 1 then return mendreturn a(n - 1,n * m)
enda(5,1)
回调
通常会拿协程同回调也就是callback比较。因为两者都可以实现异步通信。
比如:
bob.walkto(jane)
bob.say("hello")
jane.say("hello")
当然,不可能这样运行,那么会导致一起出现。所以有下面的方式。
bob.walto(function ( )bob.say(function ( )jane.say("hello")end,"hello")
end, jane)
如果再多一些呢?
再结合上面说的调用记录的说法,可能层次深了,发现咋不回调了。
如果用协程来实现就是:
function runAsyncFunc( func, ... )local current = coroutine.runningfunc(function ( )coroutine.resume(current)end, ...)coroutine.yield()
endcoroutine.create(function ( )runAsyncFunc(bob.walkto, jane)runAsyncFunc(bob.say, "hello")jane.say("hello")
end)coroutine.resume(co)