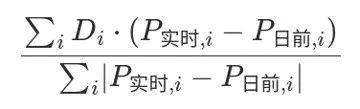一、项目需求
1.用户行为数据采集平台搭建
2.业务数据采集平台搭建
3.数仓维度建模
4.统计指标
5.即席查询工具,随时进行指标分析
6.对集群性能进行监控,发生异常时报警(第三方信息)
7.元数据管理
8.质量监控
9.权限管理(表级别、字段级别)
二、技术选型
数据量大小、业务需求、行内经验、技术成熟度、开发维护成本、总成本预算
数据采集传输:Flume、Kafka、Sqoop、Logstash(日志采集)、DataX
数据存储:MySQL(ADS层)、HDFS、HBase、Redis、MongoDB
数据计算:Hive、Tez、Spark、Flink、Storm
数据查询:Presto、Kylin、Impala、Druid、ClickHouse、Doris
数据可视化:ECharts、Superset(开源免费)、QuickBI(离线)、DATAV(实时)(阿里产品)
任务调度:Azkaban、Oozie、DolphinScheduler、Airflow
集群监控:Zabbix(离线)、Prometheus(实时)
元数据管理:Atlas
权限管理:Ranger、Sentry(Apache已将其除名)
三、系统数据流程处理
Nginx:负载均衡,主要负责使每个服务器上面的数据保持平衡
主要分为业务数据 和用户行为数据
业务数据存储在MySQL,通过Sqoop将数据同步到集群
用户行为数据主要来源于前端埋点,数据以文件的形式存放,通过Flume将日志文件采集到Kafka(避免直接采集,防止数据量过大,消峰),再通过Flume将数据同步到集群,通过HIVE On Spark对数据进行存储、清洗、转换等操作,将数据分为ODS数据原始层、DWD数据明细层、DWS数据服务层、DWT数据主题层、ADS数据应用层
ADS层数据再通过Sqoop同步到MySQL进行可视化分析展示(Superset)
在计算过程中可通过Presto对DWD,DWS,DWT层数据进行即席查询
通过Kylin可对DWD层数据进行多维分析,结果可存储到HBase
定时任务调度工具可使用Azkaban
元数据管理使用Atlas
权限管理使用Ranger
数据质量管理使用Python+Shell
集群监控使用Zabbix

四、框架发行版本选择以及集群规模
Apache 开源免费
云服务器:阿里云EMR
亚马逊云EMR
腾讯云EMR
华为云EMR
物理机或者云服务器的选择主要根据公司需求来选择
物理机:场地、电费、机器维护,后期服务器运维等费用高,安全性也相对高
云服务器:成本高,但后期维护比较省事,安全性相对物理机来说低
如何购买服务器?
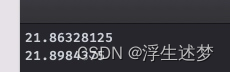
日活 100万 * 一人平均100条 * 日志大小1K * 半年不扩容 * 180 * 三个副本3 * 预留20%~30%Buf = 77T
再考虑到数仓分层,数据压缩等
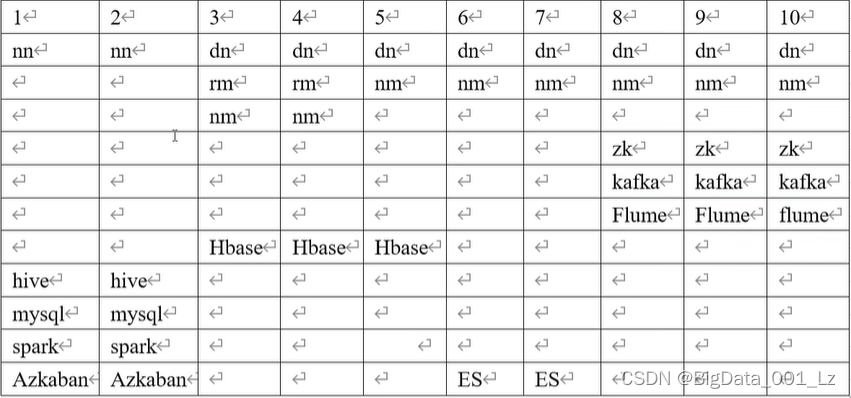
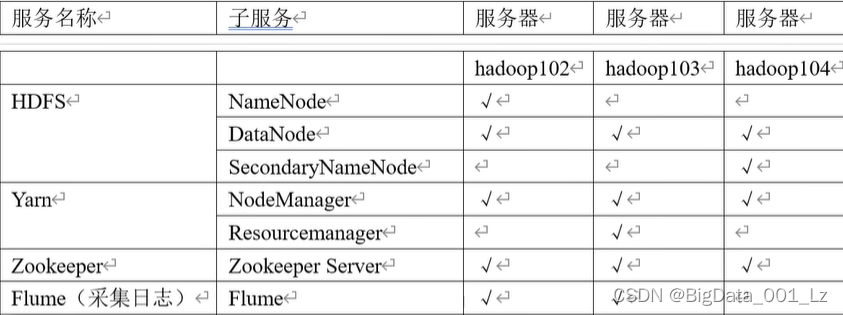
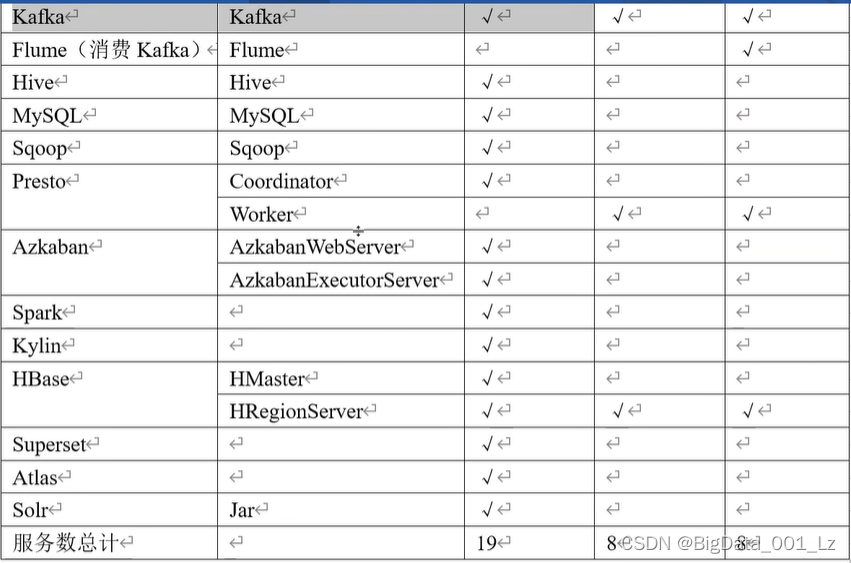
集群资源规划设计
生产集群 原则:
消耗内存的分开
数据传输紧密地放在一起
客户端尽量放在一台服务器上,方便外部访问(数据安全性)
有依赖关系的尽量放在一台服务器上
测试集群: