一、单表查询
1.1 二级索引为null
不论是普通的二级索引,还是唯一二级索引,它们的索引列对包含 NULL 值的数量并不限制,所以我们采用key IS NULL 这种形式的搜索条件最多只能使用 ref 的访问方法,而不是 const 的访问方法
1.2 const,ref,ref_or_null,range,index,all,使用索引场景介绍
1.2.1 const等值匹配
1.2.2 ref 二级索引等值匹配
1.2.3 ref_or_null 二级索引+null等值匹配
1.2.4 index
***查询列能完美匹配联合索引列,条件不符合最左原则,也可以使用索引列***
SELECT key_part1, key_part2, key_part3 FROM single_table WHERE key_part2 = 'abc';
查询条件key_part1, key_part2, key_part3是联合索引的全部列,遍历联合索引idx_key_part,然后再找到key_part2 = ‘abc’ 的值这样也能使用索引;索引类型为index;
二、连接查询
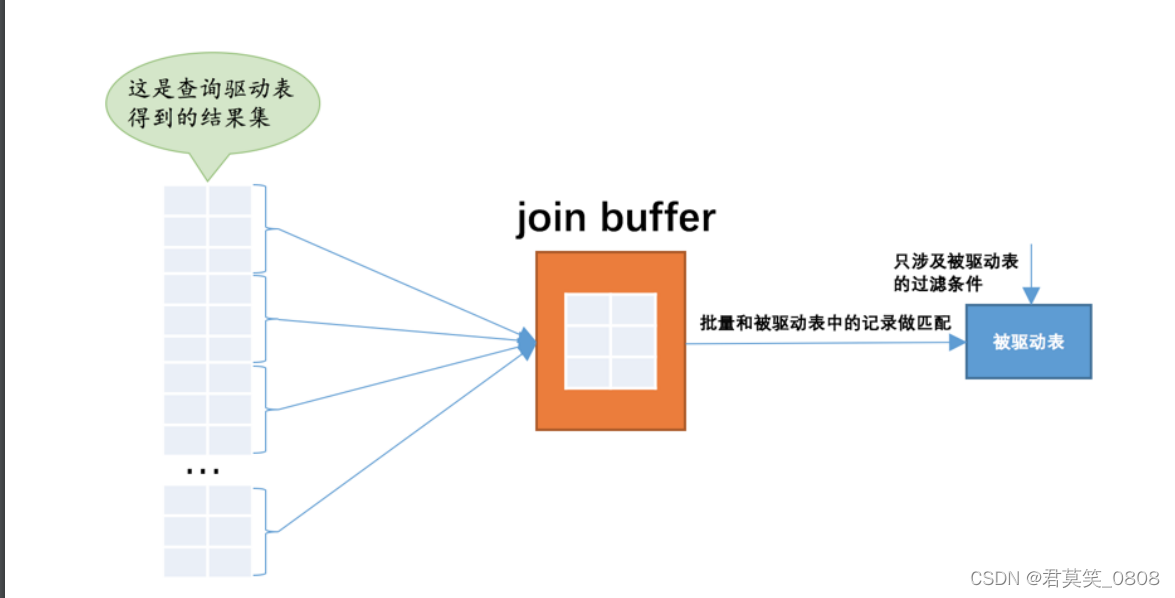
2.1 join buffer
join buffer 就是执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个 join buffer 中,然后开始扫描被驱动表,每一条被驱动表的记录一次性和 join buffer 中的多条驱动表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的 I/0 代价。使用 join buffer 的过程如下图所示:
2.2 连表查询成本
*** 在连接查询的执行计划中,出现在前边的表表示驱动表,出现在后边的表表示被驱动表 ***
连接查询总成本 = 单次访问驱动表的成本 + 驱动表扇出数 * 单次访问被驱动表的成本
2.3 物化表
子查询结果集中的记录保存到临时表的过程称之为 物化 (英文名:Materialize )。为了方便起见,我们就把那人存储子查询结果集的临时表称之为 物化表 。正因为物化表中的记录都建立了索引(基于内存的物化表有哈希索引,基于磁盘的有B+树索引),通过索引执行 IN 语句判断某人操作数在不在子查询结果集中变得非常快,从而提升了子查询语句的性能。
从表s1看,用s1的列匹配物化表中的列,相等则返回
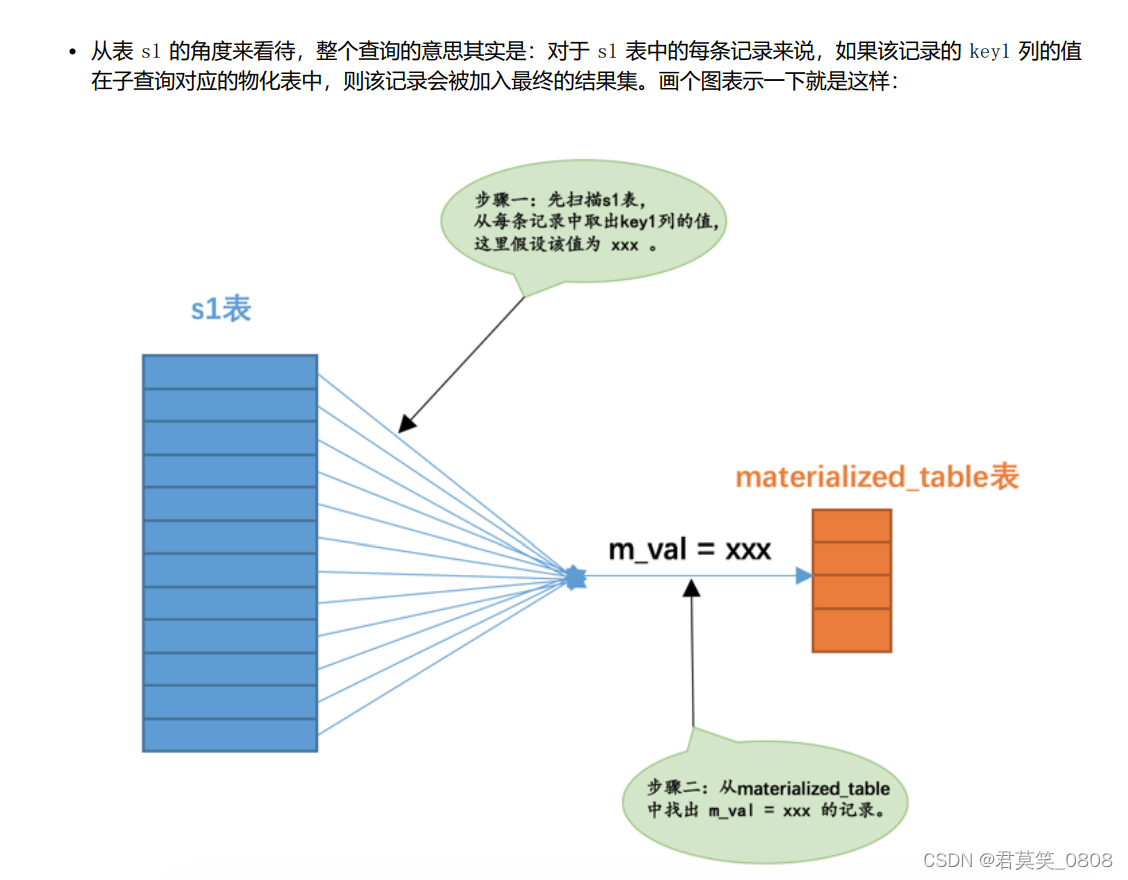
物化表成本
如果使用 s1 表作为驱动表的话
物化子查询时需要的成本
扫描 s1 表时的成本
s1表中的记录数量x通过 m_val = xxx 对 materialized table 表单表访问的成本(我们前边说过物化表中的记录是不重复的,并目为物化表中的列建立了索引,所以这个步骤显然是非常快的)。
如果使用 materialized table 表作为驱动表的话,总查询成本由下边几个部分组成:
物化子查询时需要的成本
扫描物化表时的成本
物化表中的记录数量x通过 key1 = xxx 对 sl 表进行单表访的成本( ey1 列上建立了索引,所以这个步骤是非常快的)。
1、半连接
2、先将子查询物化之后再执行查询 执行 IN to EXISTS 转换。
三 explain关键字
3.1 特殊注意点
**possible_keys列中的值并不是越多越好,可能使用的索引越多,查询优化器计算查询成本时就得花费更长时间,所以如果可以的话,尽量删除那些用不到的索引**
3.2
由于 key1 列的类型是 VARCHAR(100),所以该列实际最多占用的存储空间就是 300 字节,又因为该列允许存储NULL 值,所以 key_len 需要加 1,又因为该列是可变长度列,所以 key_len 需要加 2,所以最后 ken len 的值就是 303。
有的同学可能有疑问:你在前边唠叨 InnoDB 行格式的时候不是说,存储变长字段的实际长度不是可能占用1个字节或者2个字节么? 为什么现在不管三七二十一都用了 2个字节? 这里需要强调的一点是,执行计划的生成是在MySQL server 层中的功能,并不是针对具体某个存储引擎的功能,设计 MySQL 的大叔在执行计划中输出key len 列主要是为了让我们区分某个使用联合索引的查询具体用了几个索引列,而不是为了准确的说明针对某个具体存储引擎存储变长字段的实际长度占用的空间到底是占用1个字节还是2个字节。比方说下边这个使用到联合索引 idx key_part 的查询: