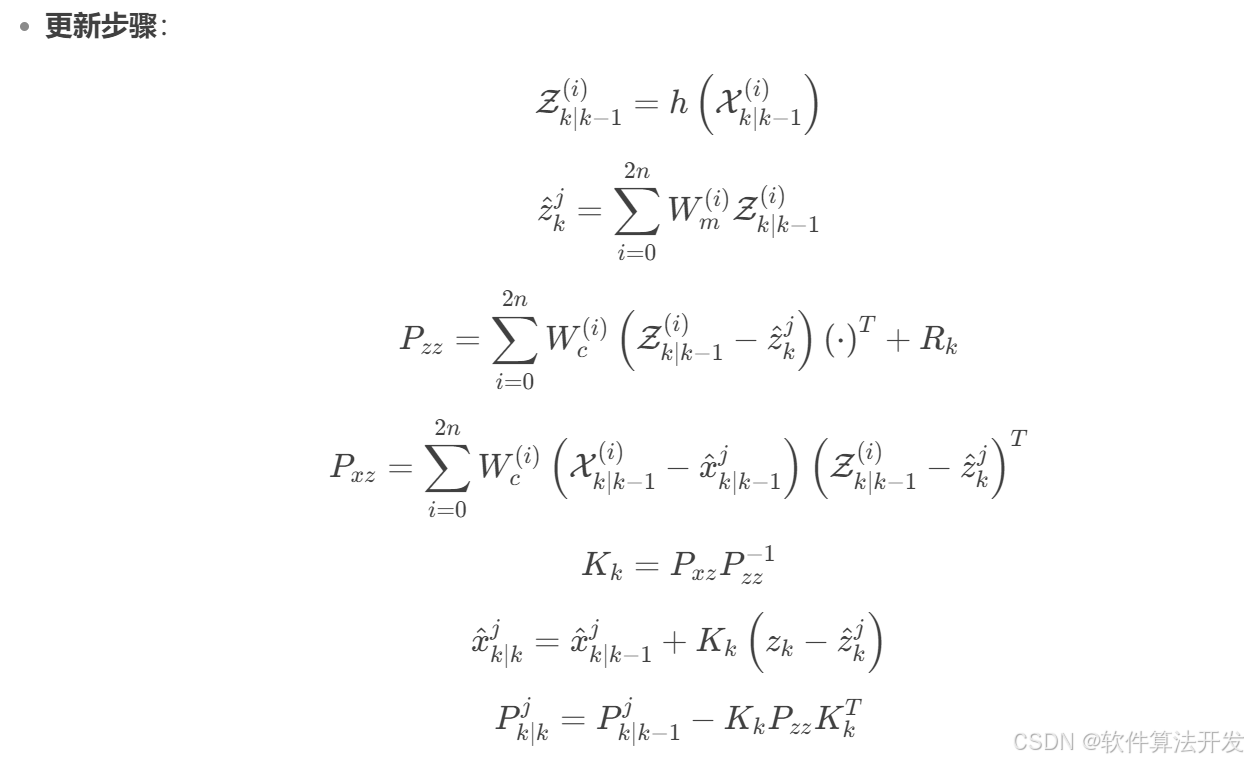- arxiv链接
- 自监督训练用到了SimMIM 论文链接。我觉得,SimMIM与MAE的区别在于,前者只是一个1-layer的prediction head,而后者是多层transformer结构的decoder。
- 可参考Swin Transformer V2(CVPR 2022)论文与代码解读。
总结

图中展示了三个创新,从左到右有三处红色结构,分别代表: 1. Continuous relative position bias和Log-spaced coordinates,2. Scaled cosine attention,3. Post normalization。
本文的主要创新如下:
- 针对"3.2. Scaling Up Model Capacity"的需求,本文提出两个改进:Post normalization和Scaled cosine attention。
- 针对"3.3. Scaling Up Window Resolu





![[权限提升] Wdinwos 提权 维持 — 系统错误配置提权 - Trusted Service Paths 提权](https://i-blog.csdnimg.cn/direct/a72a333483134a1d98c5e68e64756ac7.jpeg)