文章目录
- llama2
- 体验地址
- 模型下载
- 下载步骤
- 准备工作
- 什么是Git LFS
- 下载huggingface模型
- 模型运行代码
llama2
Meta最新语言模型LLaMA解读,LLaMA是Facebook AI Research团队于2023年发布的一种语言模型,这是一个基础语言模型的集合。
体验地址
- 体验地址
模型下载
- 模型下载地址
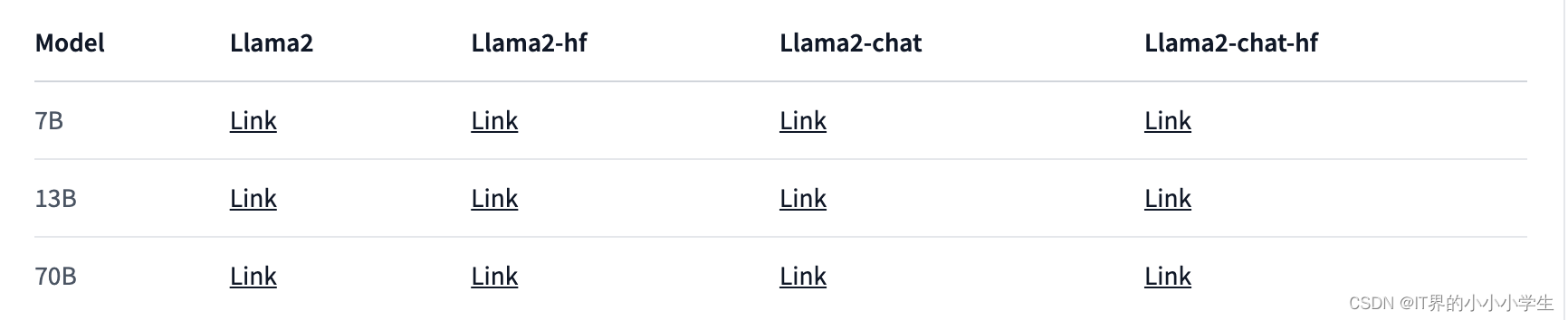
下载步骤
准备工作
- 先注册登录
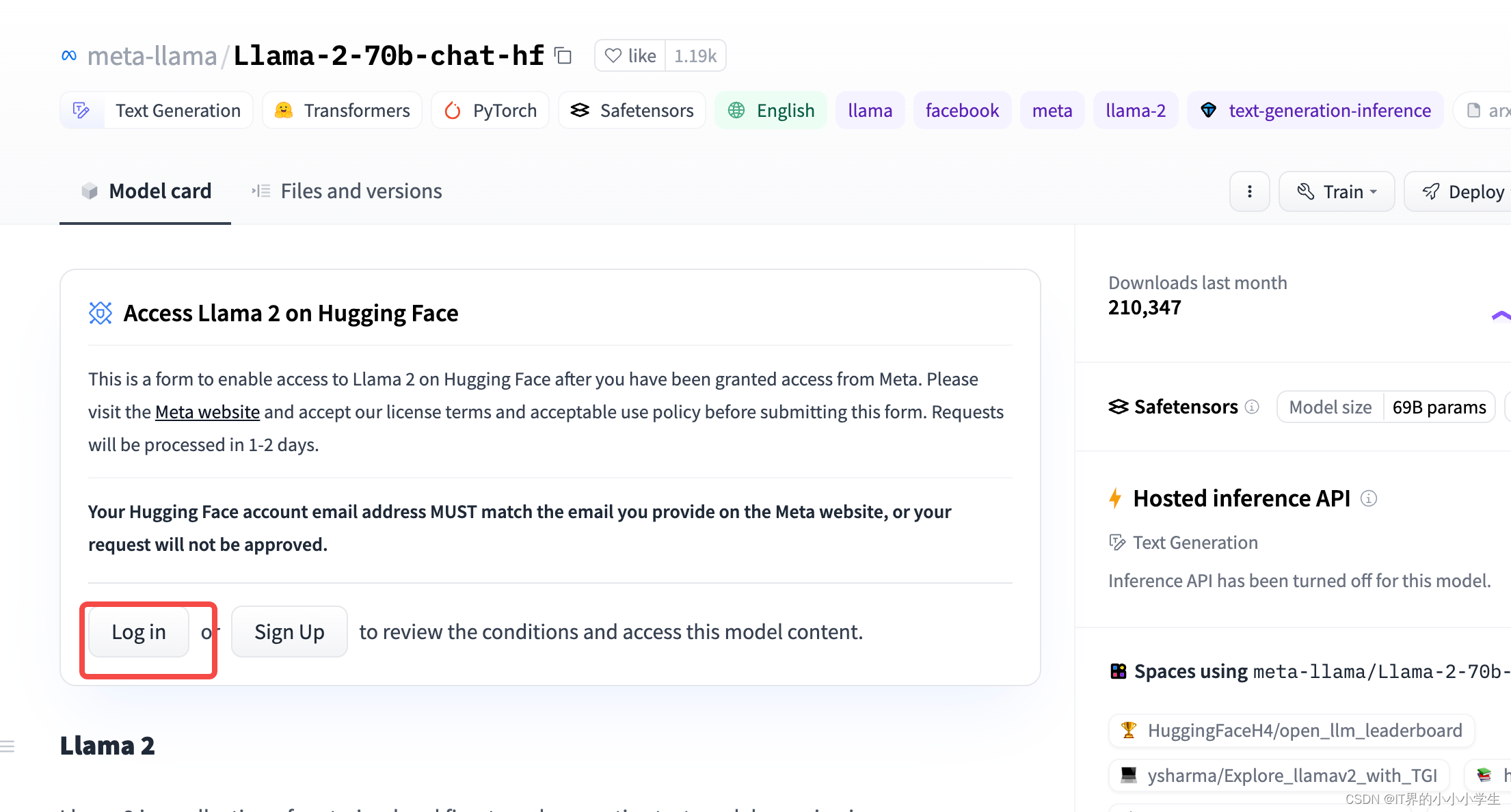
- 授权,需要一段时间,
- 需要使用gls
什么是Git LFS
git是程序员开发程序不可或缺的工具,有效的使用git能够极大的加快程序人员的开发效率。
在开发比较轻量化的代码时,开发的速度不会受到git上传下载速度的影响,但是随着系统的复杂度增加,代码中关联到的文件越来越多,其中二进制文件发生变化时,git需要存储每次提交的变动,导致本地git仓库越来越大,上传下载速度也受到了很大影响。
Git LFS的出现解决了这一问题,LFS全称Large File
Storge,即大文件存储,可以帮助我们管理比较大的文件,对于二进制文件来说,git lfs对于需要追踪的文件只会保存一个指向该文件的指针,而不是在本地仓库中保存每次提交的版本,这解答的节省了本地磁盘空间,同时也缩小的git的传输时间。其核心是把需要进行版本控制,但是占用很大空间的文件独立于git仓库进行管理,进而加快git速度。
- Git LFS 的使用方法
- 安装 git lfs
windows
下载安装 windows installer
运行 windows installer
git lfs install
mac
安装 homebrew
brew install git-lfs
git lfs install
linux
Centos
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash
sudo yum install git-lfs
git lfs install
Ubuntu
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
git lfs install
关于使用这里不在赘述了。
下载huggingface模型
通过git clone批量下载huggingface模型和数据集
操作步骤:
首先打开huggingface官网:https://huggingface.co/
进入官网之后,点击“Models",如下图:
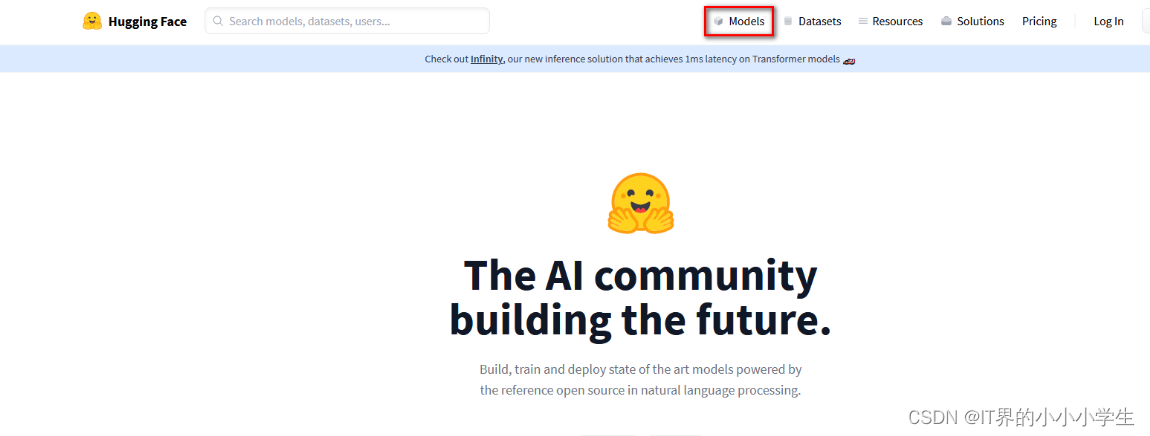
如果想要下载数据集,则同样的操作方法,点击”Datasets“.
进入”Models“,之后,在搜索框,输入想要download的模型名称。比如:Llama-2-7b-chat-hf
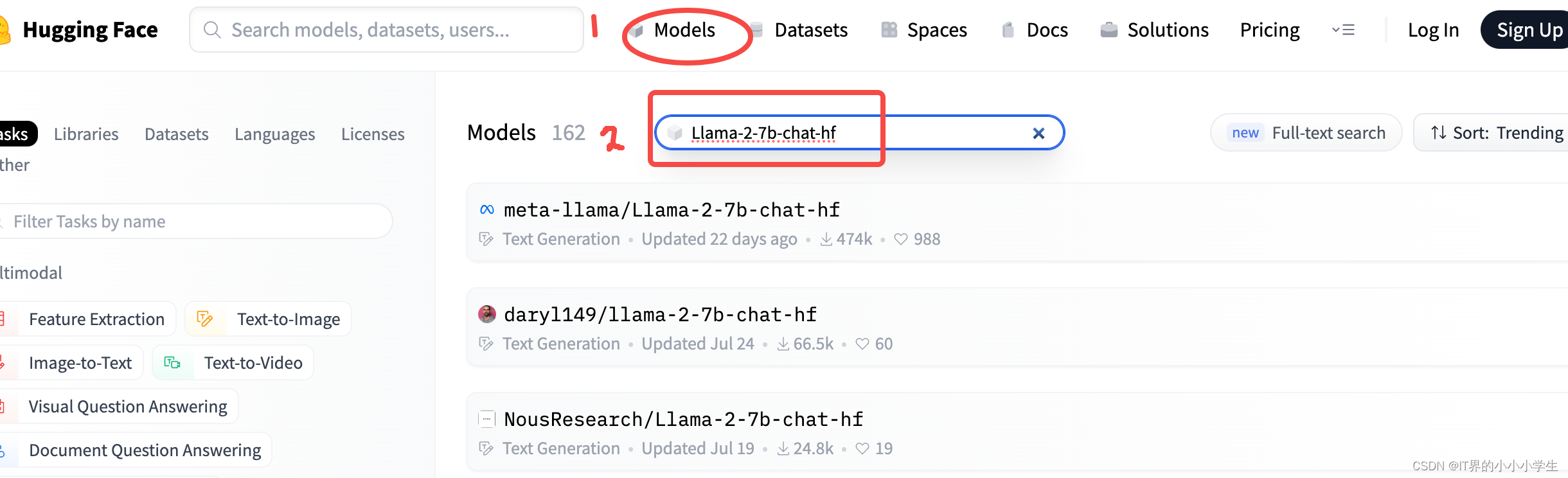
找到想要下载的模型,点击进入,出现下面的画面:
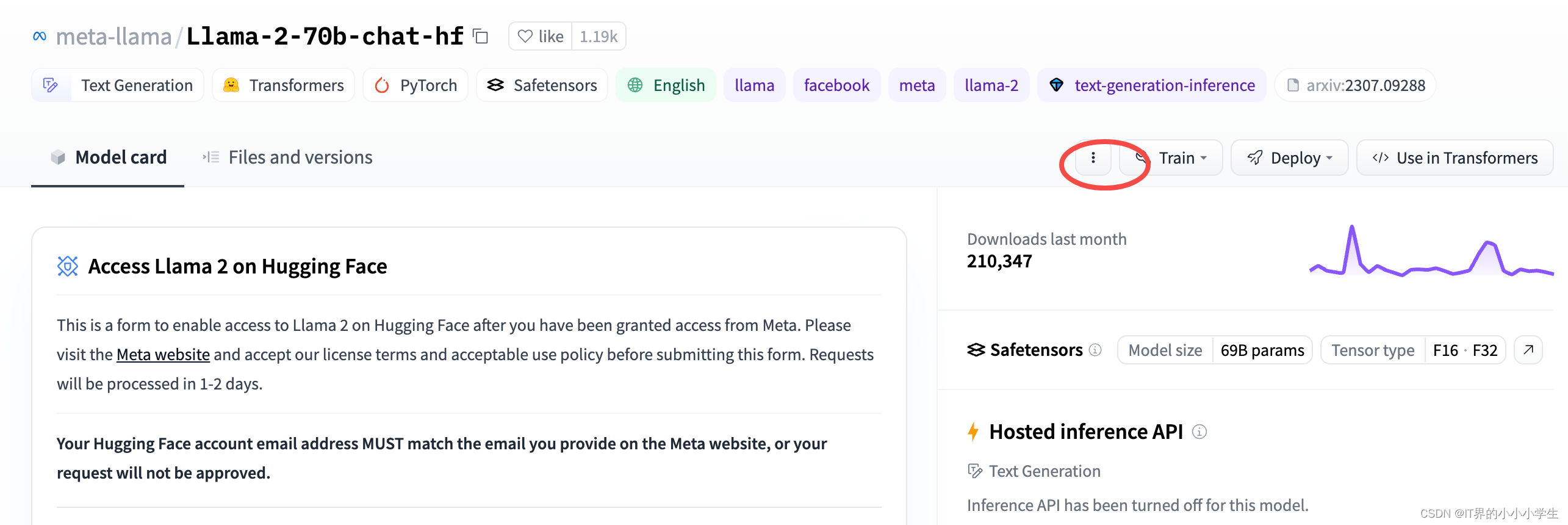
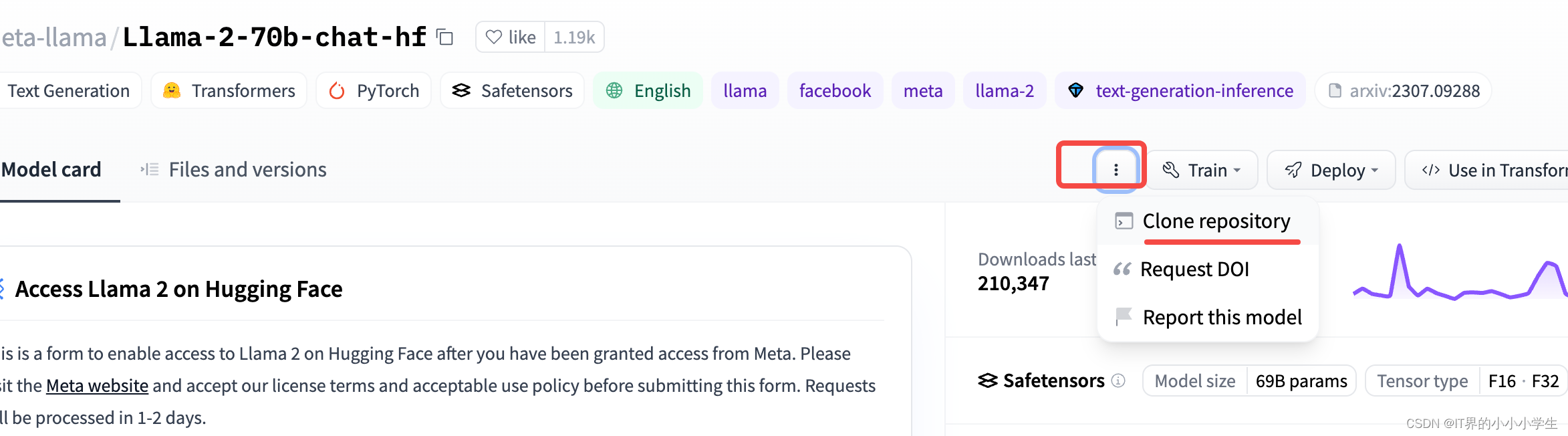
之后按照代码流程进行clone就行
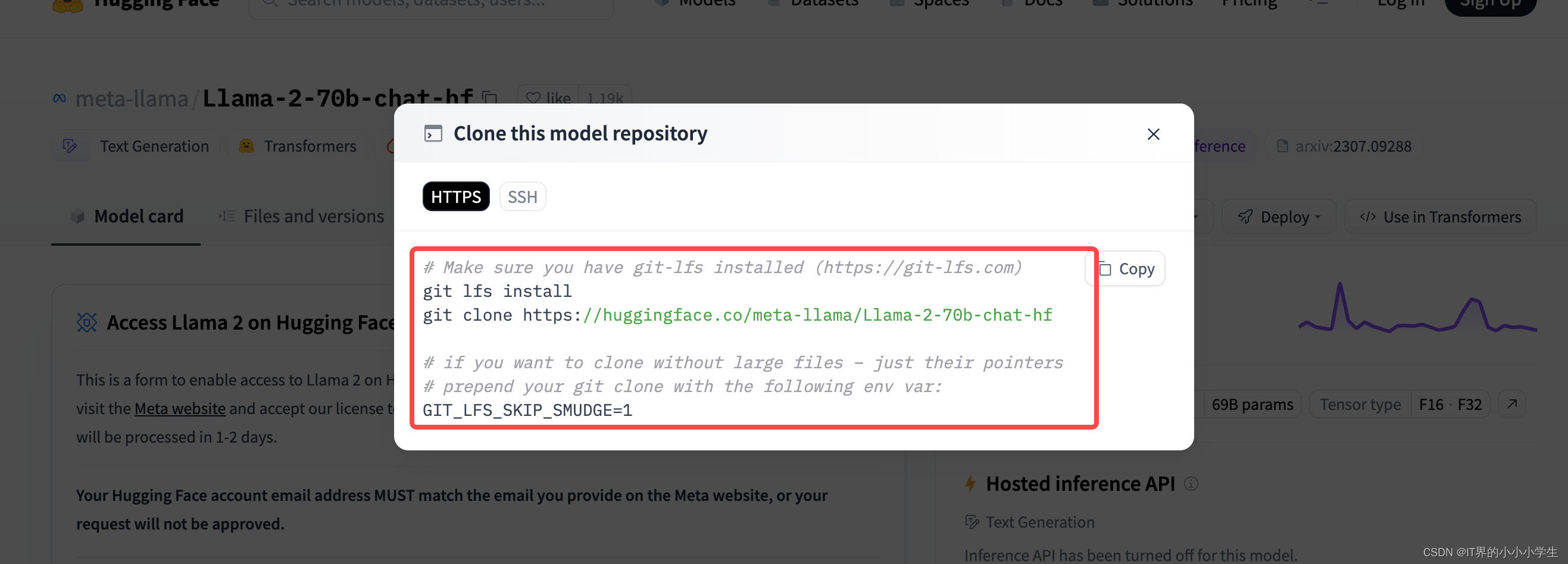
模型运行代码
模型下载完成后,找到对应模型的目录进行运行
from transformers import AutoTokenizer
import transformers
import torchmodel = "./lla2/Llama-2-7b-chat-hf"
local_rank = 3
## set device
torch.cuda.set_device(local_rank)
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline("text-generation",model=model,torch_dtype=torch.float16,device_map=torch.device("cuda", local_rank),
)
## 示例1
sequences = pipeline('I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?\n',do_sample=True,top_k=10,num_return_sequences=1,eos_token_id=tokenizer.eos_token_id,max_length=200,
)
for seq in sequences:print(f"Result: {seq['generated_text']}")
## 示例2
text2= "Is Beijing the capital of China?"
sequences = pipeline(text2,do_sample=True,top_k=10,num_return_sequences=1,eos_token_id=tokenizer.eos_token_id,max_length=200,
)
for seq in sequences:print(f"Question: {seq['generated_text']}")
Output: