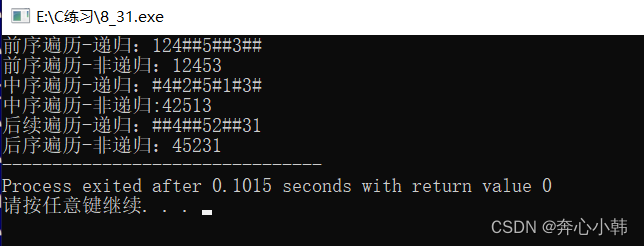
目录
集成学习
一、bagging
二、boosting
Bagging VS Boosting
1.1 集成学习是什么?
Bagging
Boosting
Stacking
总结
集成学习
好比人做出一个决策时,会从不同方面,不同角度,不同层次去思考(多个自我,多个价值观),这就会有多个决策结果产生,最终我们会选一种决策作为最终决策。
集成学习(Ensemble Learning):
-
通常一个集成学习器的分类性能会好于单个分类器,将多个分类方法聚集在一起,以提高分类的准确率。
-
集成学习并不算是一种学习器,而是一种学习器结合的方法。
-
集成学习法由训练数据构建一组基学习器,然后通过对每个基学习器的预测进行投票来产生最终预测。
-
集成学习中需要有效地生成多样性大的基学习器,即多样性增强(增强泛化特性,减小一次预测的方差):即对样本、特征,学习器进行扰动。
特点
集成方法是一种将几种机器学习技术组合成一个预测模型的元算法,以减小方差(bagging),偏差(boosting),或者改进预测(stacking)。
稳定学习器的集成不太有利,因为这样的集成并不会提升泛化特性。例如,决策树集成相对于kNN集成达到了较高的准确率。kNN对训练样本的扰动不敏感,因此也被称为稳定学习器(stable learner)。
集成方式
-
同构集成:大多数集成方法使用一个基学习算法来产生多个同构基学习器,即相同类型的学习器,这就是同构集成(homogeneous ensembles)。
-
异构集成:也有一些方法使用的是异构学习器,即不同类型的学习器,这就是异构集成(heterogeneousensembles)。为了使集成方法能够比任何构成它的单独的方法更准确,基学习器必须尽可能的准确和多样。
学习模式
-
串行:个体学习器之间存在强依赖关系,必须串行生成的序列化方法
-
并行:个体学习器不存在强依赖关系,可以同时生成的并行化方法
集成学习又分为两大类
一、bagging
bagging为bootstrap aggregating简写,即套袋法,过程如下,
-
抽取多组训练集:每个样本集都是从原始样本集中有放回的抽取n次,组成训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行m轮,得到m个训练集,训练集之间相互独立。
-
基学习器:每次使用一个训练集得到一个模型,m个训练集共得到m个模型。
-
投票:分类问题:将上步得到的m个模型采用投票的方式得到分类结果;回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
bagging本质
对一个样本空间,随机有放回的抽样出若干独立的训练样本,以此来增加样本扰动,多轮次抽样训练后形成多个估计,然后平均多个估计,达到降低一个估计的方差,也就是增强学习器的泛化特性。
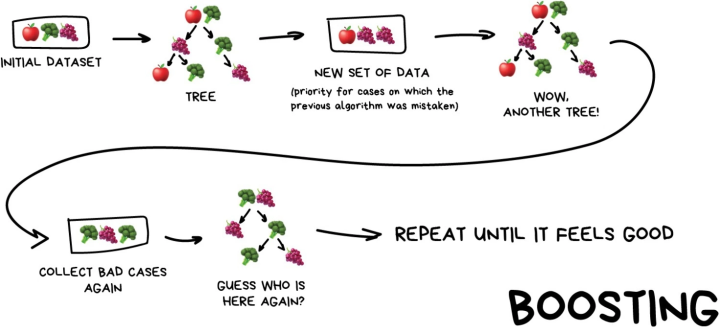
二、boosting
其主要思想是将弱分类器组装成一个强分类器。在PAC(概率近似正确)学习框架下,则一定可以将弱分类器组装成一个强分类器。
Adaboost
Adaboost是一种基于boost思想的一种自适应的迭代式算法。通过在同一个训练数据集上训练多个弱分类器(weak classifier),然后把这一组弱分类器集成起来,产生一个强分类器(strong classifier)。
特点
(1) 每次迭代改变的是样本的分布,而不是重复采样
(2) 样本分布的改变取决于样本是否被正确分类:总是分类正确的样本权值低,总是分类错误的样本权值高(通常是边界附近的样本)
(3) 最终的结果是弱分类器的加权组合
Bagging VS Boosting
(1) 样本选择上
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
(2) 样例权重
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
(3) 预测函数
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
(4) 计算方式
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
1.1 集成学习是什么?
集成学习(Ensemble Learning)是集合多个学习算法以提高模型的效果,是机器学习中重要的一类方法。很多高阶机器学习模型(随机森林、XGBoost)和深度学习都包含了集成学习思想。

那么集成学习到底是什么呢?集成学习其实是一类机器学习的算法,你可以把它理解为一种训练思路,而并不是某一个单独的算法。集成学习的一个关键点就在于它集合了多个学习算法。如果我们有了多个模型,每个模型有它各自的多样性,通过集成学习,我们能够得到一个更好的精度。
1.2 集成学习有哪些分支?
集成学习在我们的日常生活是十分常见的,比如投票选班长或者通过多次摇骰子来进行投票,其实都体现了集成学习的思想。常见的集成学习类型有 Bagging、Boosting、Stacking 三种。这里会逐一为大家介绍这三种集成学习的类型。
Bagging
我们在学习机器学习基础的时候,在教材中,比如周志华的西瓜书,都会讲到 Bagging 这种集成学习的类型。Bagging 基于“民主”的集成思路,并行训练多个模型。这里的“民主”是什么意思呢?是每个机学习器都是相互平等的。而正是由于我们的机器学习的平等独立的特性,才使得 Bagging 能够进行并行的训练,不需要做串行的训练。Bagging 的用法是在训练过程中训练多个模型,然后对预测结果进行集成。Bagging 的优点是可以减少误差中的方差项(variance),它能够降低模型预测结果的误差。它的缺点是增加了时间的开销,且需要模型具备多样性,由于是并行训练,它需要有较大的计算资源,而如果我们的模型不具备多样性的话,最终得到的结果也会不尽如人意。
关键点:多个模型如何保证多样性?
方法1:每次采样得到参与训练的样本(行采样)
方法2:每次采样得到参与训练的字段(列采样)
方法3:每次对模型的超参数进行修改
Boosting
Boosting 基于“精英”筛选的思路,串行训练多个模型。“精英”指它不是一个“民主”的,而是一个筛选的过程,类似于进化的过程。Boosting 在其训练过程中,它的模型是基于上一轮的模型进行继续拟合的,模型与模型之间是串行的过程,它们之间是相互依赖的。Boosting 的优点是可以减少偏差(bias),它主要是减少误差中的偏差项。而由于在它在进行训练的过程中,是不断的学习上一轮模型的残差的,所以 Boosting 其实是容易过拟合的。
关键点:如何基于上一轮模型进行继续学习?
方法1:对错误样本调整权重
方法2:拟合上一轮模型预测值的误差
Stacking
Stacking 是基于“标签”学习的思路,堆叠多个模型。Stacking 通过交叉验证的方法对训练集进行训练和预测,并以此进行二次学习。它的优点是能够结合不同类型的模型来完成学习,它的缺点是它的时间开销是非常大的,并且非常容易过拟合。
关键点:模型如何利用交叉验证训练?
什么是交叉验证呢?交叉验证(Cross Validation)是在竞赛的过程中经常会用到的一种操作。在竞赛的过程中,具体的数据集有 train set 和 test set,在 train set 上构建一个模型,在 test set 上做一个预测,然后去提交打分。原始的数据集可能只有这两部分。但是在进行训练的过程中,我们可能还会划分一部分出来,我们会把 train set 再拆分成一个 training set 和一个 validation set,也就是说我们会划分出一个验证集出来,因为有了验证集我们就可以做一个 Stacking。无论是竞赛的过程中,还是在机器学习的学习过程中,一个关键点是验证集应该如何划分。验证集主要有两种划分方法。第一种是 hold out 流出法,或者称为按照比例进行划分的流出法,比如说 75% 的比例进行训练,25% 的比例进行验证。第二种是 KFold,KFold 是指我们在进行具体的数据划分的时候,可以把数据集划分成 k 份。比如我们将数据集划分成 5 份,我们首先将第 1 份看作验证集,其他 4 份看作训练集,记作 fold 1,然后将第 2 份看作验证集,其他 4 份看作训练集,记作 fold 2,以此类推,我们可以循环 5 次,最终得到 5 个模型。
那么我们来看一看如图所示的 Stacking 的思路,它与我们的交叉验证有什么样的共同点和区别呢?
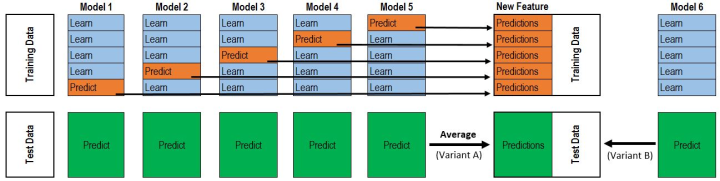
5 折交叉验证
在此模型进行训练的过程中,仍是将我们的数据集划分成 5 份,蓝色部分是训练集,橙色部分是验证集。训练了一个模型之后,我们可以对它的验证集进行预测。当训练完全部的五个模型之后,我们可以将模型预测的结果进行拼接。也就是说,一个模型的具体的预测结果是可以拆分成两部分的,一部分是对验证集的预测结果,另一部分是对测试集的预测结果,我们可以将验证集的预测结果拼接到一起,这个拼接到一起的预测结果与我们的原始训练集的维度是一样大的,这个特征叫做 out-of-fold 特征,它是可以当做一个新的特征的。在具体的操作过程中,我们可以得到模型对训练集的预测结果,以及对测试集的预测结果,这样就相当于是新增加了一类的特征,这一类的特征我们是可以用来做新的建模的。一个模型通过 5 折交叉验证可以增加一个特征,如果是 n 个模型,就可以增加 n 个特征。那么我们在进行二次学习的时候,就可以用我们的新的模型去将我们的 n 个特征和我们的真实标签再去进行一个二次学习。这就是一个基础的 Stacking 的思路。
总结
Bagging 是从数据的角度得到多样性。

Boosting 是一个串行的过程,也就是串行的迭代。
Stacking 就是做一个二次学习,我们将 K-NN,Decision Tree 以及 SVM 的预测结果进行一个二次学习,再用一个模型对它的预测结果进行具体的学习。